目录
一、JVM内存结构
1. 虚拟机栈(JVM Stacks)
1)定义
2)栈内存溢出
3) 线程运行诊断
案例1:CPU占用过高
案例2:程序运行很长时间没有结果编辑
2. 本地方法栈(Native Method Stacks)
3. 堆(Heap)
1)定义
2)特点
3)堆内存溢出
4)堆内存诊断
5)案例:垃圾回收后,内存占用仍然很高
4. 方法区
1)定义
2)组成
3)方法区内存溢出
4)运行时常量池
5)StringTable
5.1 常量池和串池(StringTable)的关系
5.2 StringTable 特性
例1:第14行代码本质分析
例2:常量字符串拼接的底层原理
例3:intern() 方法
例4:面试题解答
5.3 StringTable 位置
5.4 StringTable 垃圾回收
5.5 StringTable 性能调优
5. 直接内存(Direct Memory)
1)定义
2)使用直接内存的好处
3)演示直接内存溢出
4)直接内存回收原理
一些文章:
- JVM参数设置_徒步凉城-Jasper的博客-CSDN博客
- JVM常用内存参数配置_如何设置jvm启动配置参数在那文件夹中_mars-kobe的博客-CSDN博客
- jvm参数设置方法(win10)_-xmx2048m -dfile.encoding=gb2312_还好,还好的博客-CSDN博客
- Java8-jvm运行时数据区(权威解析) - 知乎
- 方法区和永久区/元空间之间的关系 - 简书
- https://www.cnblogs.com/lanqingzhou/p/12374544.html
学习黑马视频:01_什么是jvm_哔哩哔哩_bilibili
笔记参考文章:
- JVM 学习笔记(一)内存结构_codeali csdn jvm内存结构_CodeAli的博客-CSDN博客
- 【JVM】内存结构_jvm结构图_ΘLLΘ的博客-CSDN博客
一、JVM内存结构
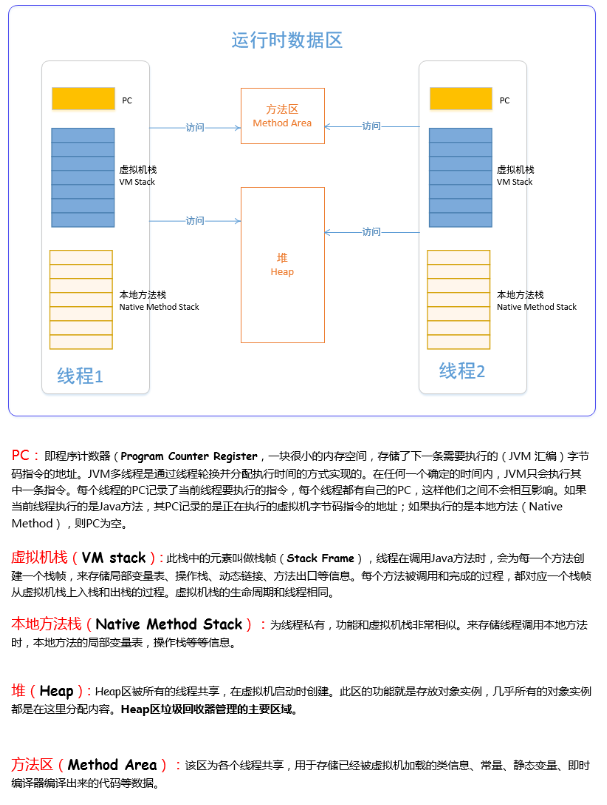
程序计数器
虚拟机栈
本地方法栈
堆
方法区
程序计数器、栈、本地方法栈,都是线程私有的。堆、方法区是线程共享的区域。
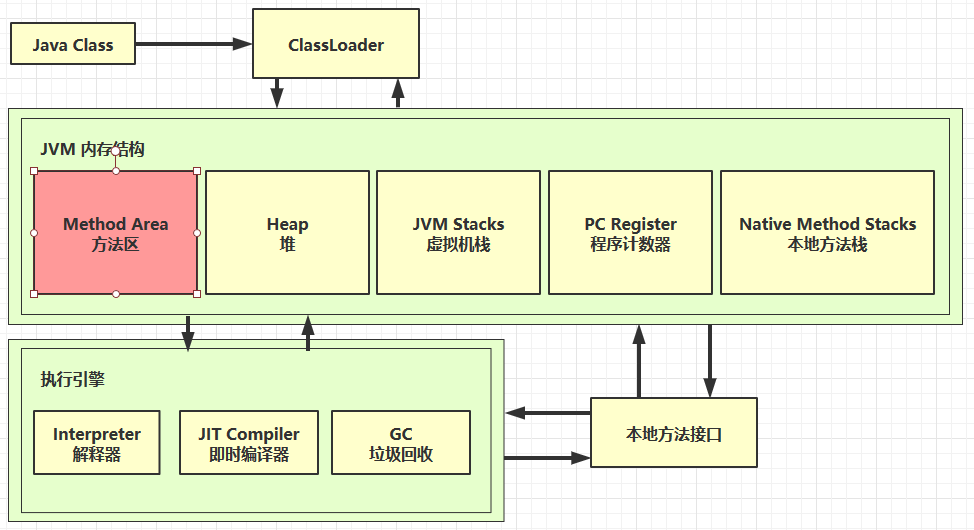
下图来源:https://www.cnblogs.com/lanqingzhou/p/12374544.html
1. 虚拟机栈(JVM Stacks)
1)定义
- 每个线程运行时所需要的内存,称为虚拟机栈
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
问题辨析
1. 垃圾回收是否涉及栈内存?
不会。栈内存是方法调用产生的,方法调用结束后会弹出栈。
2. 栈内存分配越大越好吗?
不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
3. 方法内的局部变量是否线程安全
- 如果方法内部的变量没有逃离方法的作用访问,它是线程安全的;(如果是对象,才需要考虑此问题;如果是基本类型变量,是可以保证它是线程安全的)
- 如果是局部变量引用了对象,并逃离了方法的访问,那就要考虑线程安全问题。
总之,如果变量是线程私有的,就不用考虑线程安全问题;如果是共享的,如加了static之后,就需要考虑线程安全问题。
public class main1 {
public static void main(String[] args) {
}
//下面各个方法会不会造成线程安全问题?
//不会
public static void m1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//会,可能会有其他线程使用这个对象
public static void m2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
//会,其他线程可能会拿到这个线程的引用
public static StringBuilder m3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
}
2)栈内存溢出
Java.lang.stackOverflowError 栈内存溢出
导致栈内存溢出的情况:栈帧过大、过多、或者第三方类库操作,都有可能造成栈内存溢出
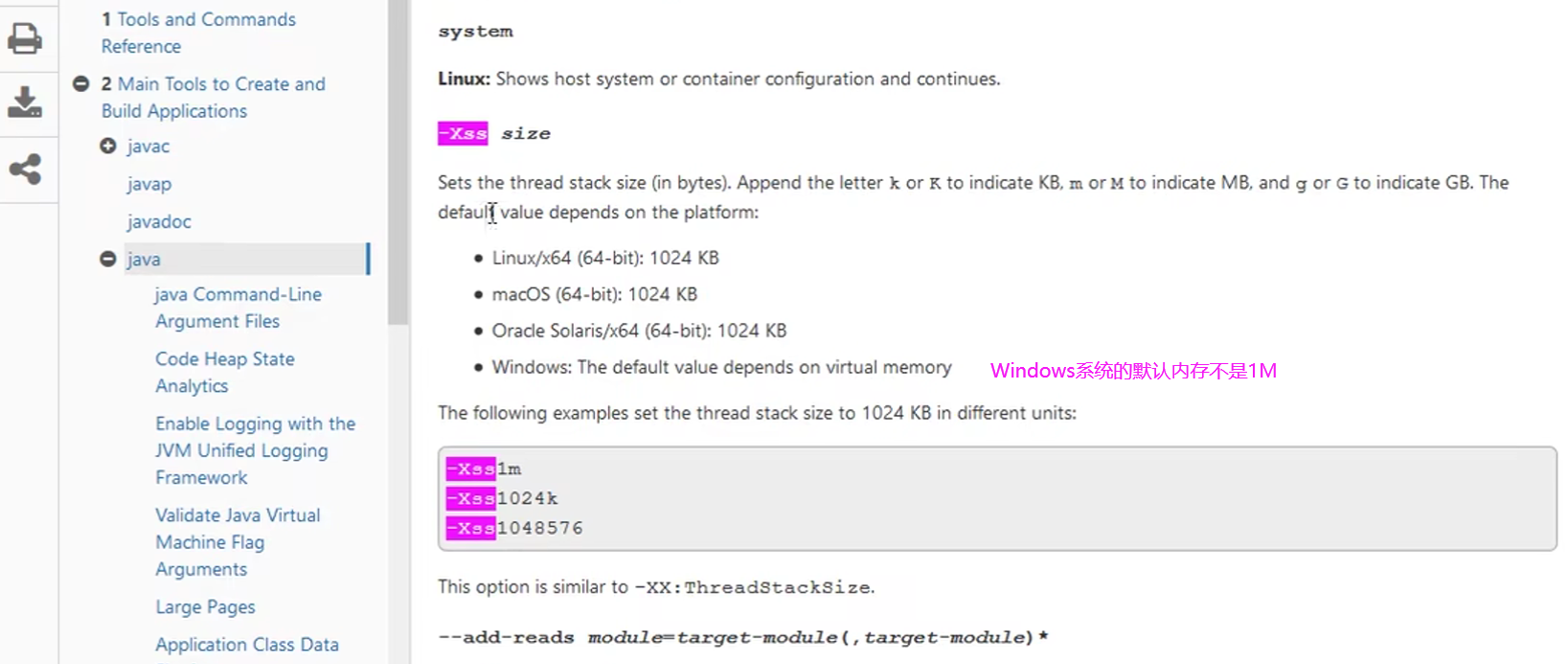
设置虚拟机栈内存大小:
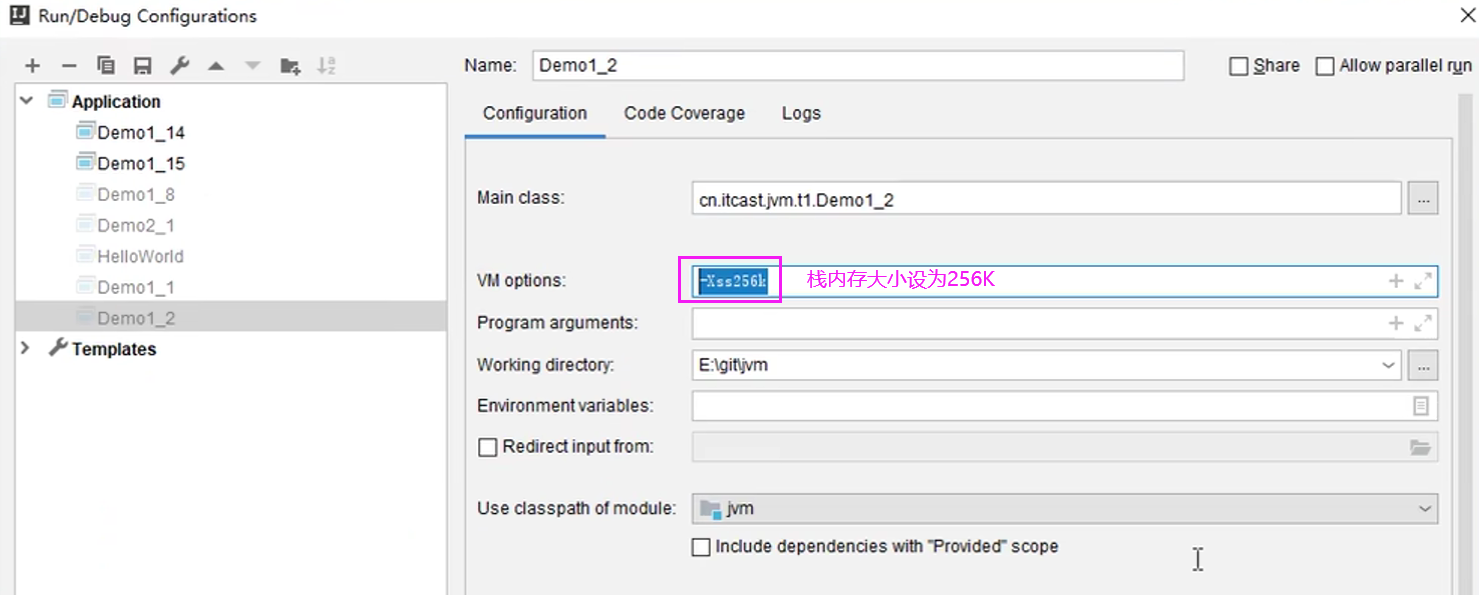
package cn.itcast.jvm.t1.stack;
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.Arrays;
import java.util.List;
/**
* json 数据转换
*/
public class Demo1_19 {
public static void main(String[] args) throws JsonProcessingException {
Dept d = new Dept();
d.setName("Market");
Emp e1 = new Emp();
e1.setName("zhang");
e1.setDept(d);
Emp e2 = new Emp();
e2.setName("li");
e2.setDept(d);
d.setEmps(Arrays.asList(e1, e2));
// { name: 'Market', emps: [{ name:'zhang', dept:{ name:'', emps: [ {}]} },] }
ObjectMapper mapper = new ObjectMapper();
System.out.println(mapper.writeValueAsString(d));
}
}
class Emp {
private String name;
//使用该注解避免循环调用问题,转换时忽略这个属性————只通过部门去关联员工,员工不再关联部门了
@JsonIgnore
private Dept dept;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
}
class Dept {
private String name;
private List<Emp> emps;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
3) 线程运行诊断
案例1:CPU占用过高
Linux环境下运行某些程序的时候,可能导致CPU的占用过高,这时需要定位占用CPU过高的线程。
第一步:用top命令定位哪个进程对cpu的占用过高;
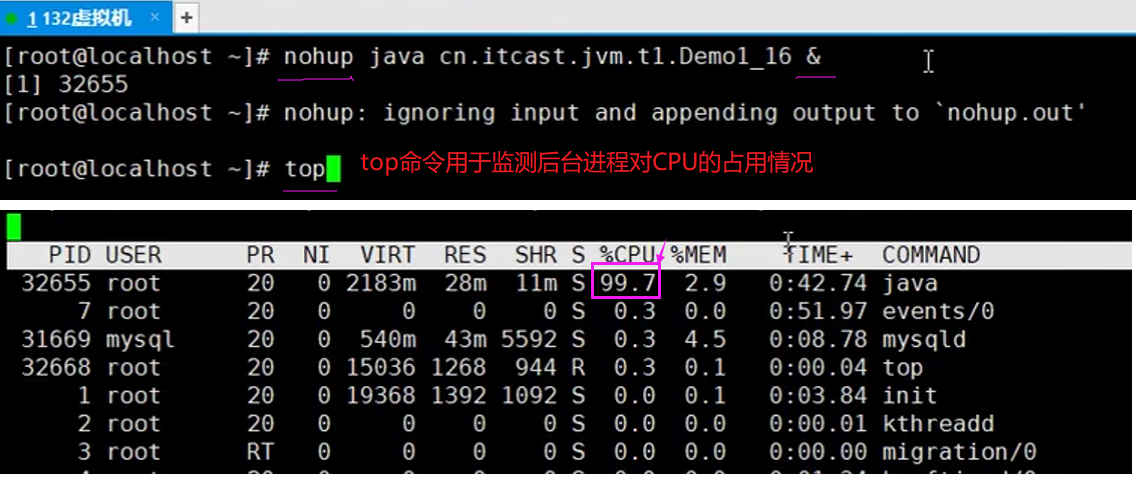
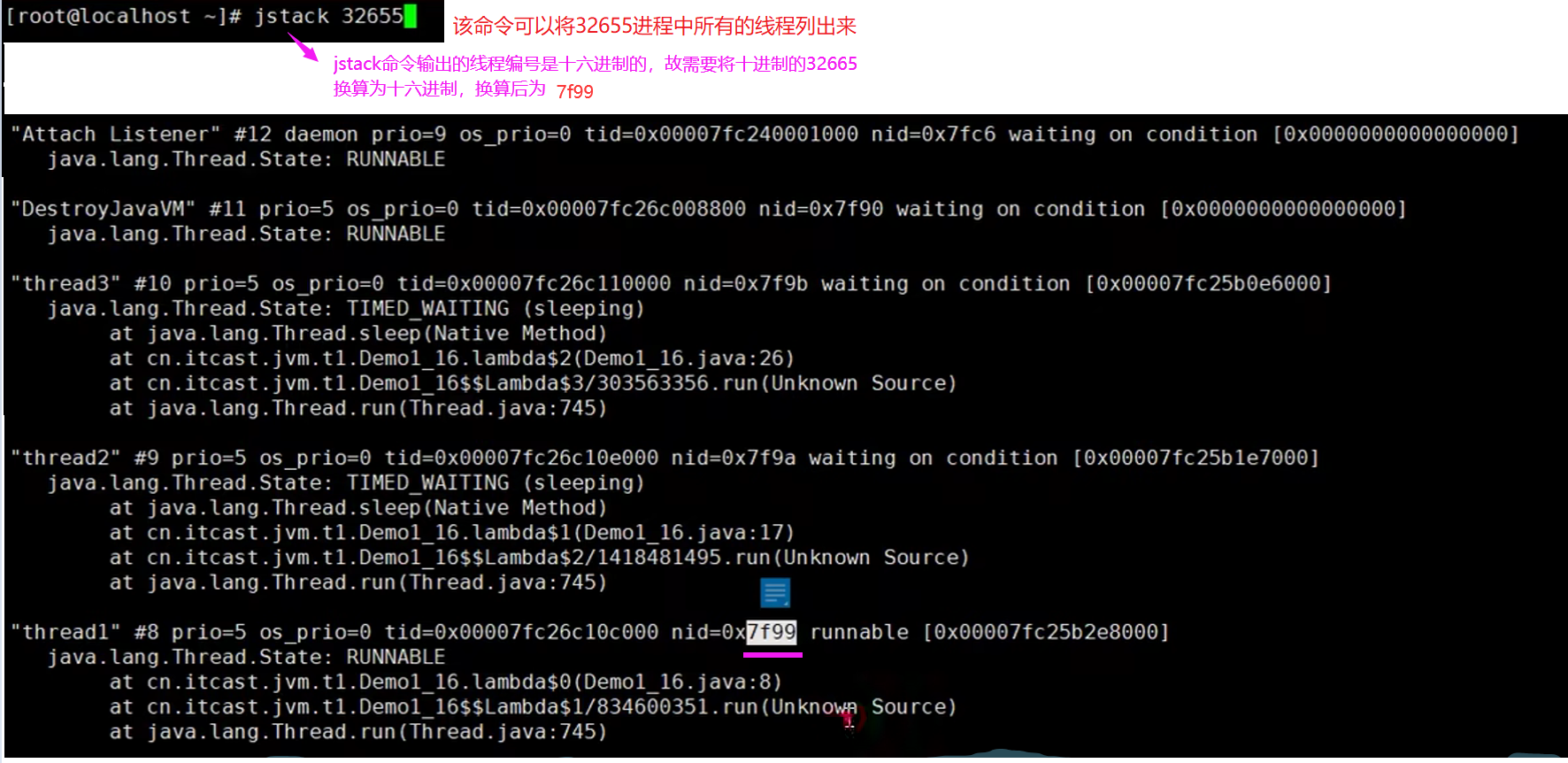
通过top命令可以看到,PID为32655的进程编号占了CPU的99.7%,那如何进一步定位问题呢?
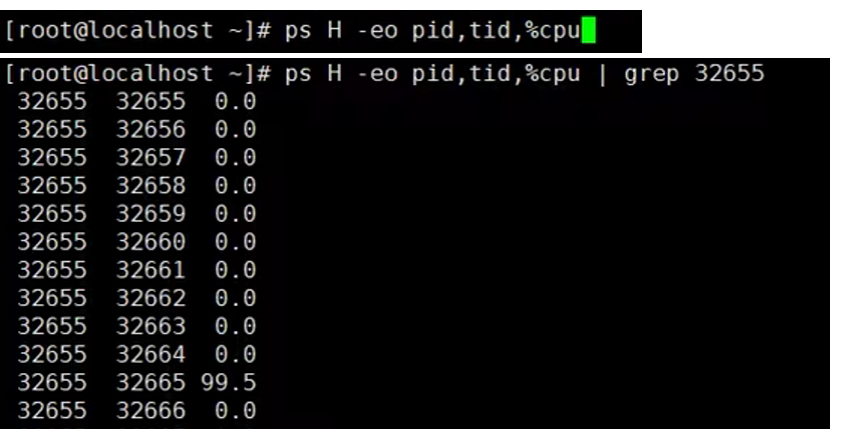
第二步:用ps命令进一步定位是哪个线程引起的cpu占用过高;(如下图,线程32665有问题)
ps H -eo pid,tid,%cpu
ps H -eo pid,tid,%cpu | grep 进程id ,刚才通过top查到的进程号
通过下面这个命令发现占用CPU过高的线程编号为32665,该线程编号为十进制的,换算为十六进制为7f99;
第三步:jstack 进程id,可以根据线程id找到有问题的线程,进一步定位问题代码的源码行号;
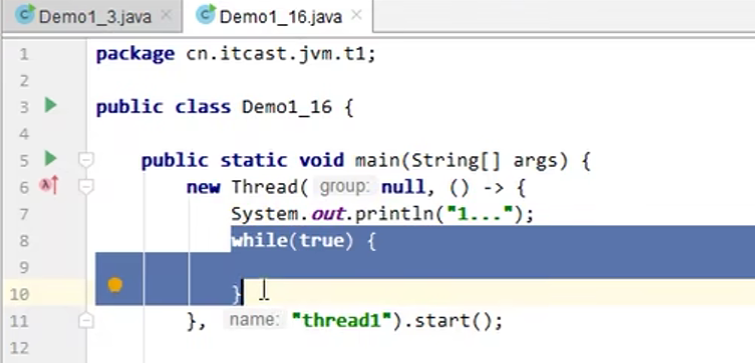
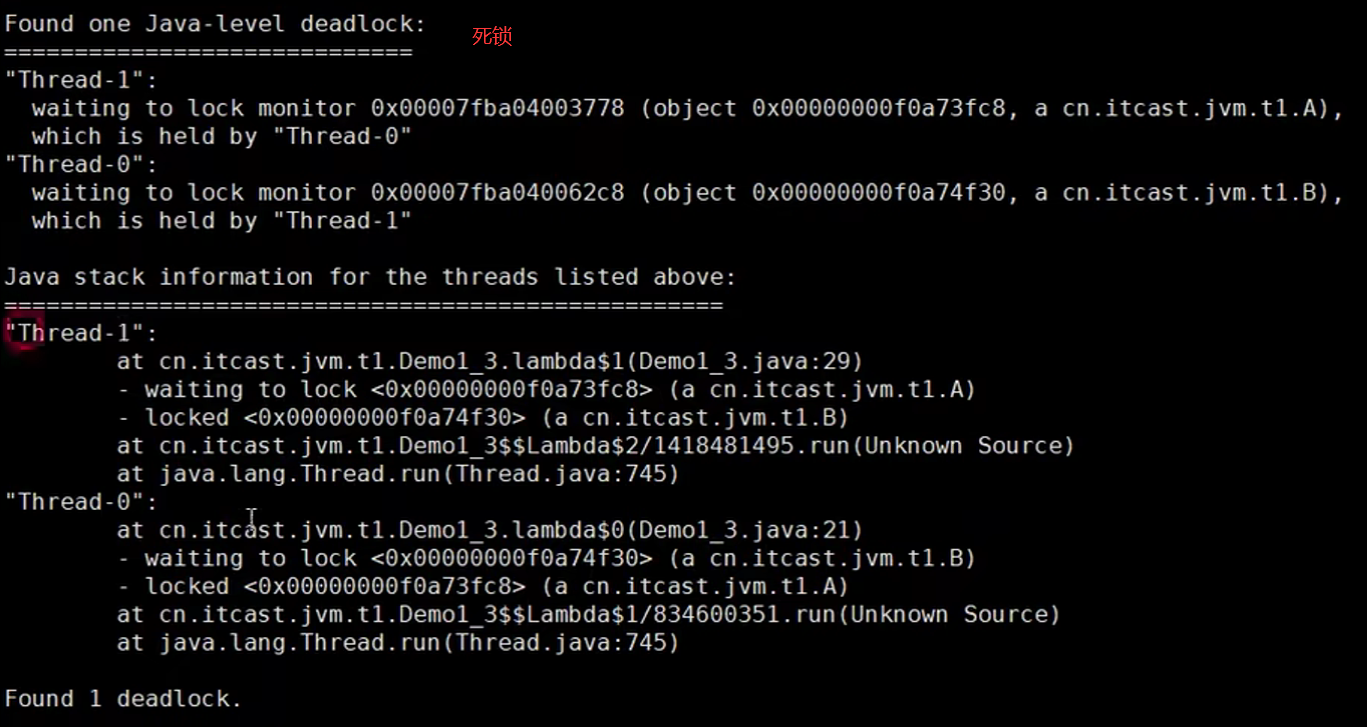
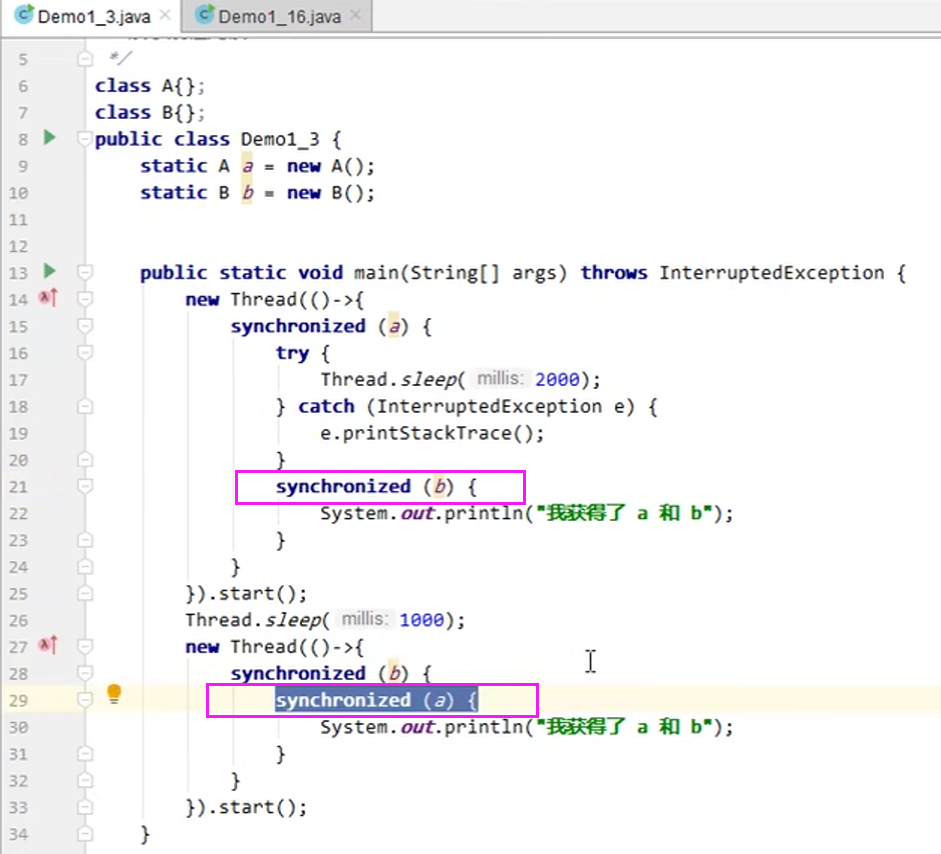
案例2:程序运行很长时间没有结果
2. 本地方法栈(Native Method Stacks)
定义:实际上就是在java虚拟机调用一些本地方法时,需要给这些本地方法提供的内存空间。本地方法运行时,使用的内存就叫本地方法栈。
作用:给本地方法的运行提供内存空间。
本地方法:指那些不是由java代码编写的方法,因为java代码是有一定限制的,有的时候它不能直接与操作系统底层打交道,所以就需要用C或者C++语言编写的本地方法来真正与操作系统打交道。java代码可以间接的通过本地方法来调用到底层的一些功能。
这样的方法多吗?当然!不管是在一些java类库,还是在执行引擎,它们都会去调用这些本地方法。比如,在Object类的方法中,clone()方法是带有native的,这种native方法它是没有方法实现的,方法实现都是通过c或者c++语言编写的,java代码通过间接的去调用c或者c++的方法实现。
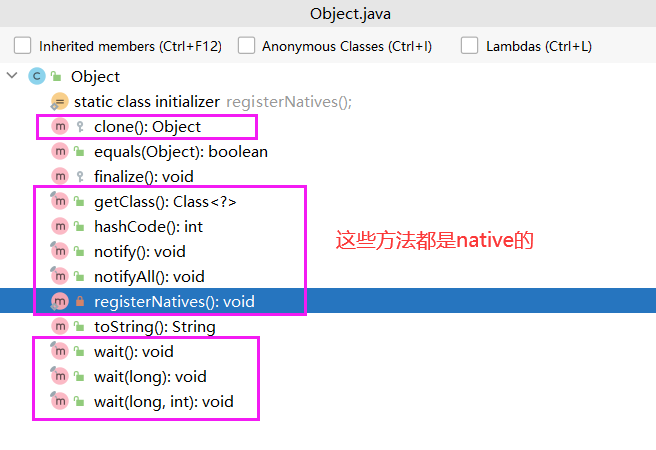
3. 堆(Heap)
前面讲的程序计数器、栈、本地方法栈,都是线程私有的。堆、方法区是线程共享的区域。
1)定义
通过new关键字创建的对象,都会使用堆内存。
2)特点
- 堆中的对象是线程共享的,堆中的对象一般都需要考虑线程安全问题(有例外);(前面说的虚拟机栈中的局部变量只要不逃逸出方法的作用范围,都是线程私有的,都是线程安全的);
- 垃圾回收机制;(Heap中不再被引用的对象,就会被当作垃圾进行回收,以释放堆内存)。
3)堆内存溢出
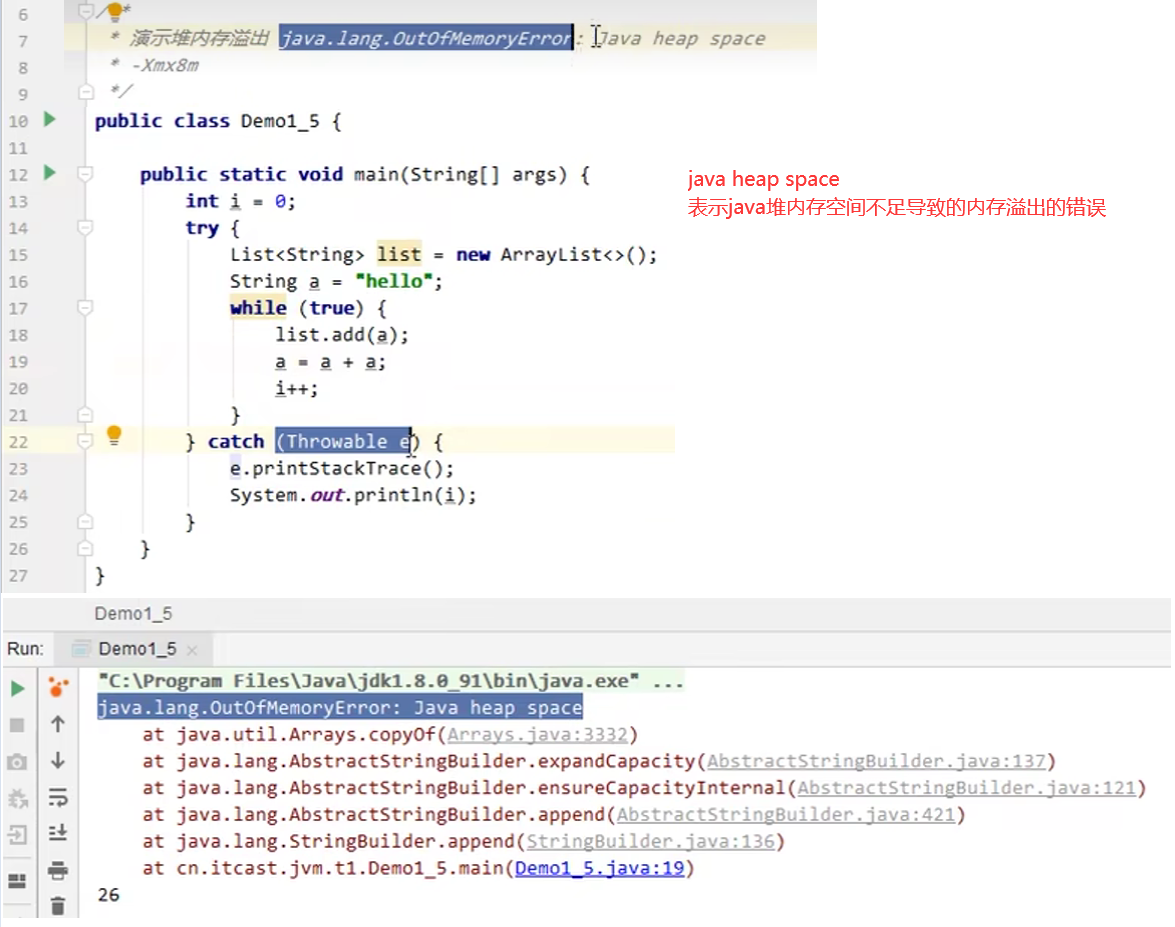
堆空间大小设置:使用-Xmx参数
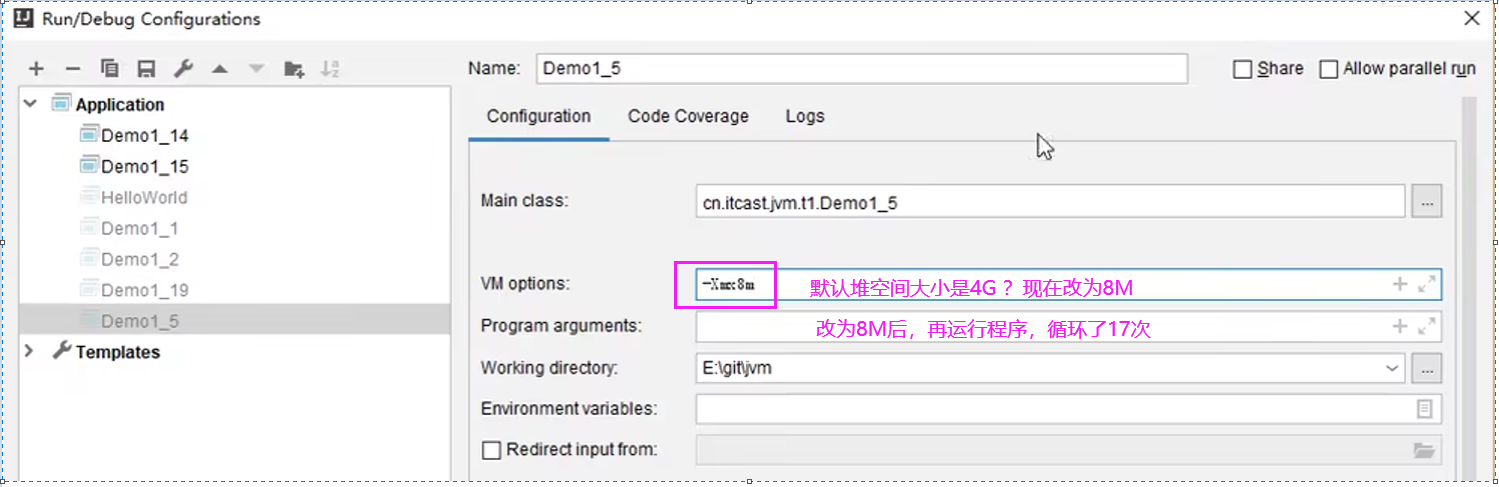 所以,这里需要注意,当内存足够大时不太容易暴露内存溢出的问题,随着时间的累积有可能会导致内存溢出。但是,有可能你运行了很短的一段时间发现它没问题。所以,排查这种堆内存问题,最好把运行内存设的稍微小一些,这样会比较早的暴露堆内存溢出的问题。
所以,这里需要注意,当内存足够大时不太容易暴露内存溢出的问题,随着时间的累积有可能会导致内存溢出。但是,有可能你运行了很短的一段时间发现它没问题。所以,排查这种堆内存问题,最好把运行内存设的稍微小一些,这样会比较早的暴露堆内存溢出的问题。
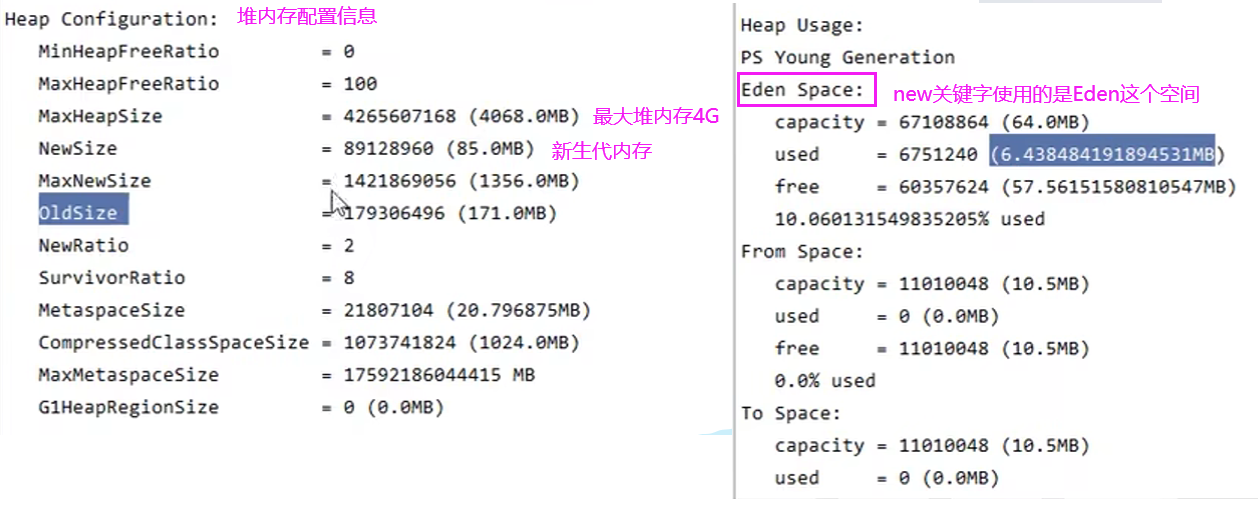
4)堆内存诊断
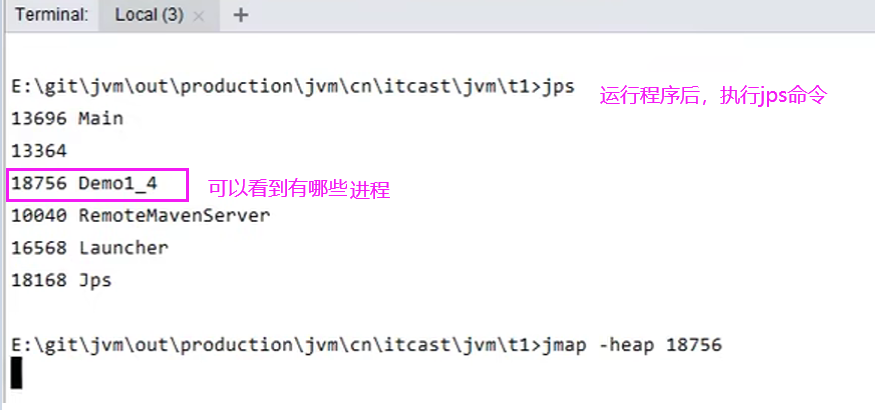
1. jps 工具
查看当前系统中有哪些 java 进程
2. jmap 工具
查看堆内存占用情况 jmap - heap 进程id
注意:它只能查询某个时刻堆内存的使用情况。如果想连续监测,需要使用下面这个工具。
3. jconsole 工具
图形界面的,多功能的监测工具,可以连续监测
除了监测堆内存,还可以监测CPU,线程。
演示上面几个工具的使用:
3.1 演示jmap工具的使用
jmap -heap 进程id ——检查该进程堆内存的占用情况;

3.2 jconsole 工具的使用
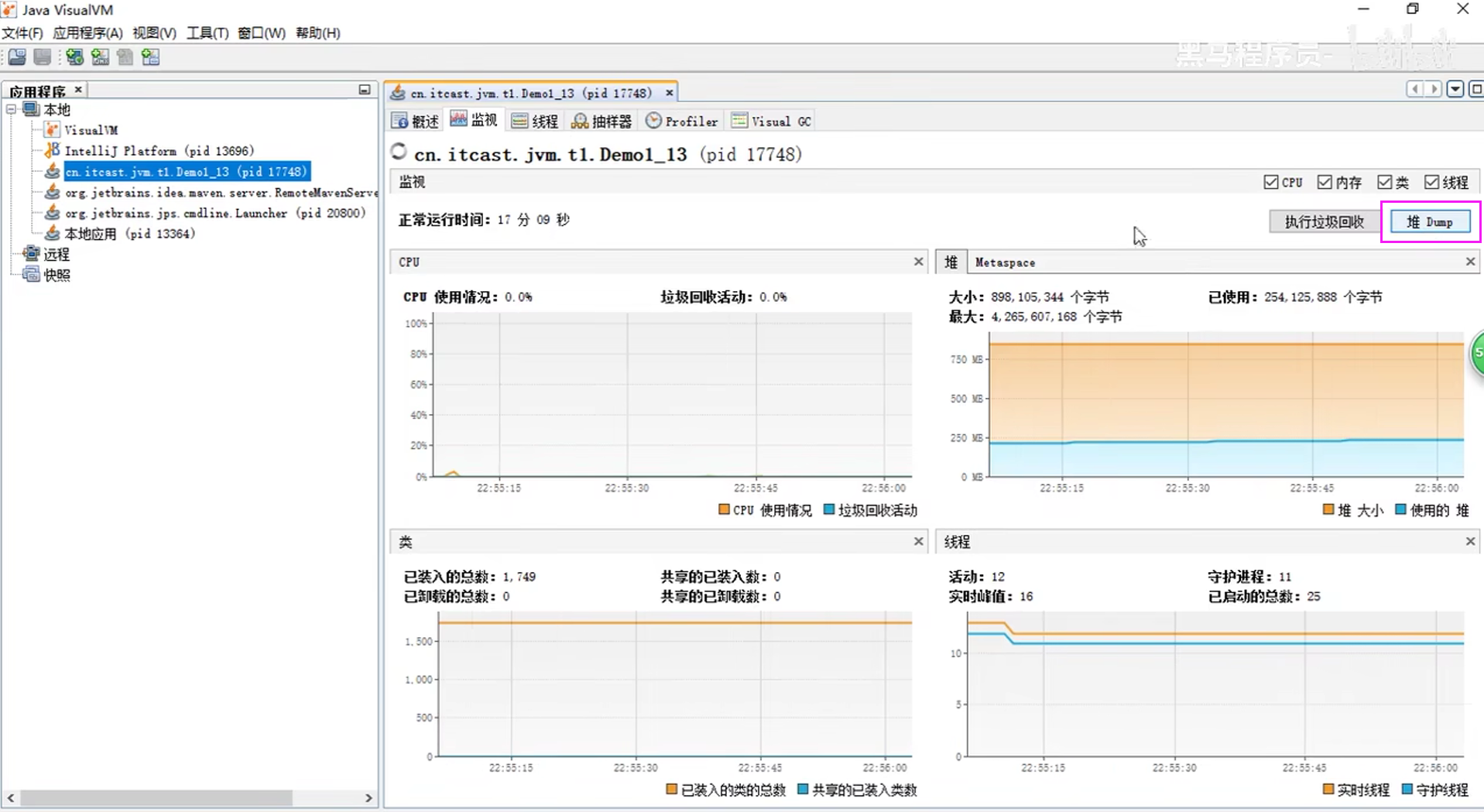
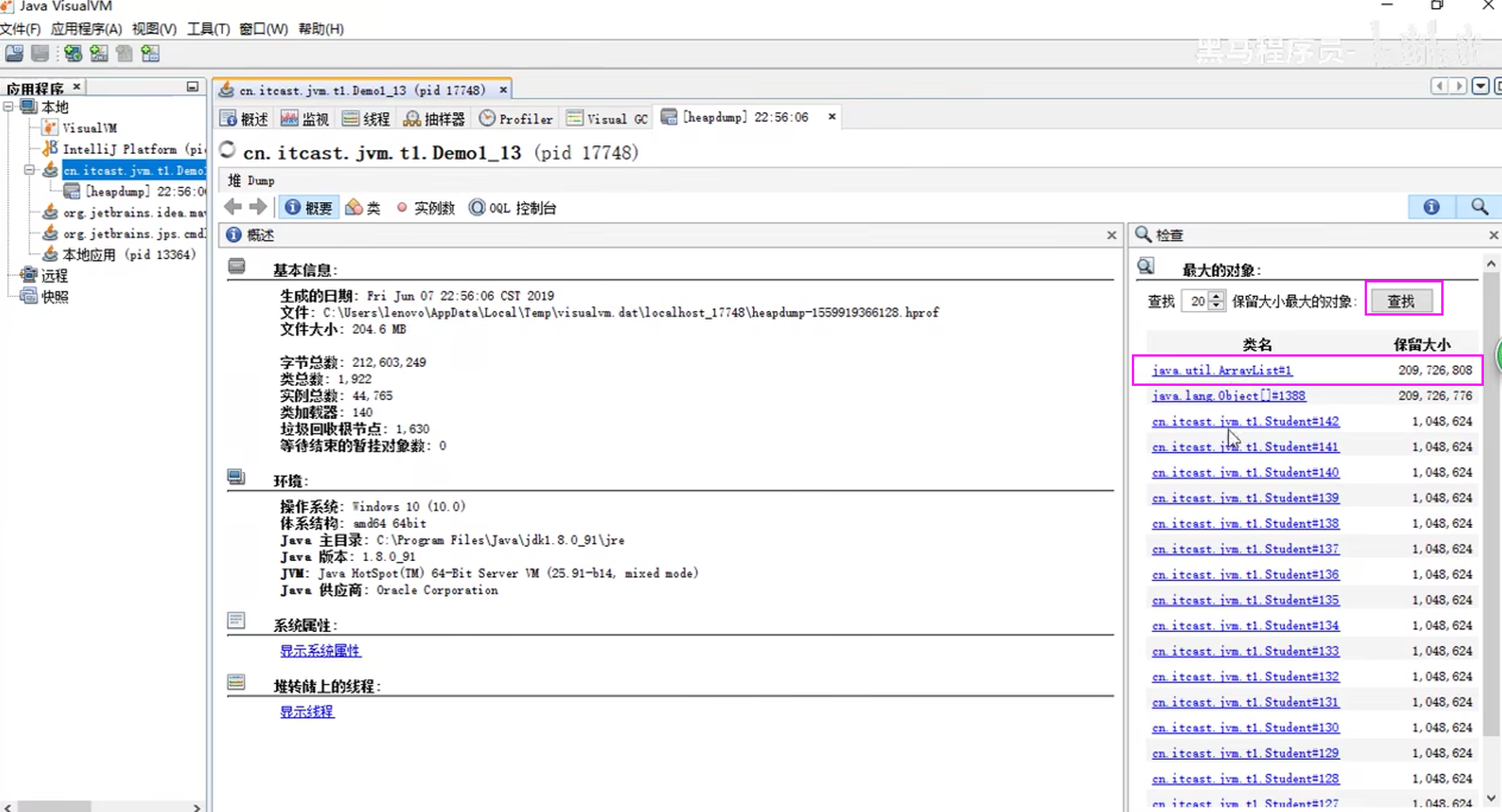
5)案例:垃圾回收后,内存占用仍然很高
jvisualvm可视化工具 (视频21)

4. 方法区
官网地址:Chapter 2. The Structure of the Java Virtual Machine

1)定义
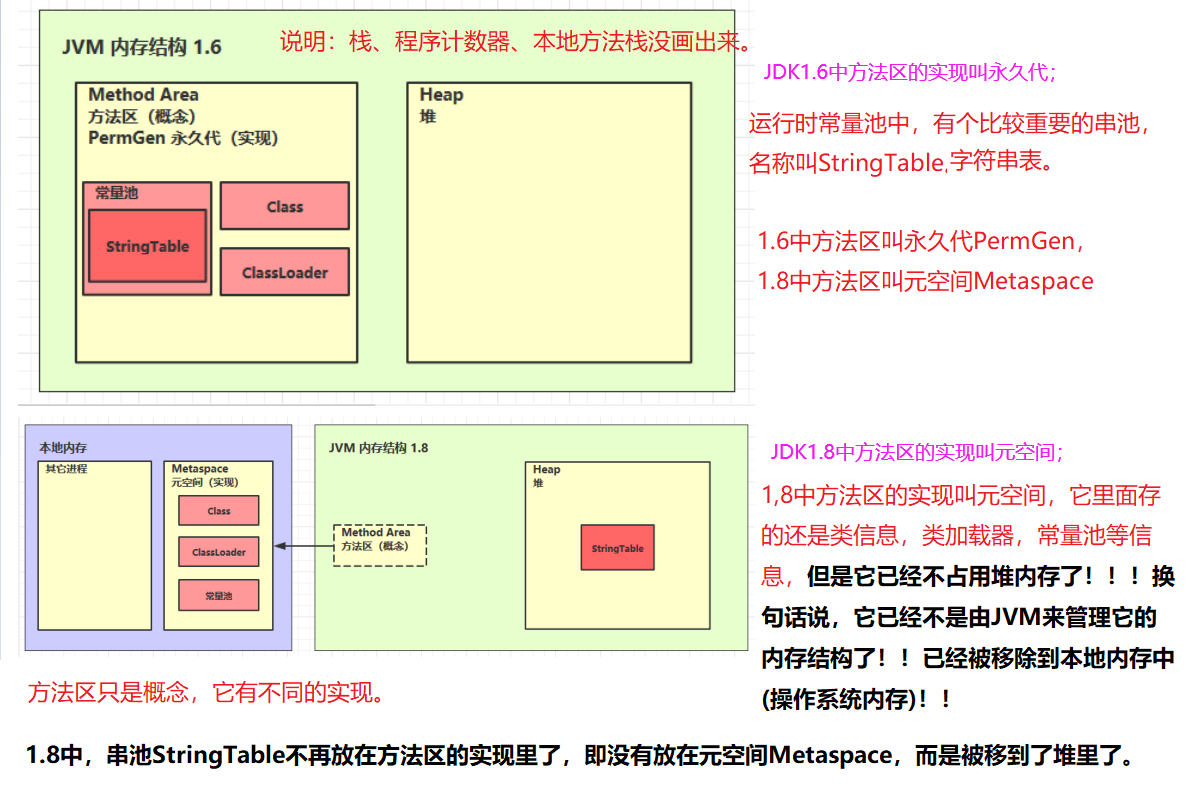
对于 HotSpotJVM 而言,方法区还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
Java 虚拟机有一个在所有 Java 虚拟机线程之间共享的方法区域。方法区域类似于用于传统语言的编译代码的存储区域,或者类似于操作系统进程中的“文本”段。它存储每个类的结构信息,例如运行时常量池、成员变量和方法数据,以及方法和构造函数的代码,包括特殊方法,用于类和实例初始化以及接口初始化。
方法区域是在虚拟机启动时创建的。尽管方法区域在逻辑上是堆的一部分,但简单的实现可能会选择不进行垃圾收集或压缩。此规范不强制指定方法区的位置或用于管理已编译代码的策略。方法区域可以具有固定的大小,或者可以根据计算的需要进行扩展,并且如果不需要更大的方法区域,则可以收缩。方法区域的内存不需要是连续的。
Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it. This specification does not mandate the location of the method area or the policies used to manage compiled code.
可以这样理解:“方法区”在逻辑上是堆的一部分。虽然在概念上定义了“方法区”,但是不同的JVM厂商去实现时,不一定会去遵从JVM逻辑上的定义。规范不强制方法区的位置,比如Oracle的HotSpot虚拟机在JDK1.8以前,它的实现叫做永久代,永久代就是使用了堆的一部分作为方法区;但JDK1.8以后,它把永久代移除了,换了一种实现,这种实现就元空间。元空间用的就不是堆内存,而是本地内存,即操作系统的内存。所以,不同的实现对于方法区所在位置的选择就会有所不同。如果网络上有人提到永久代,它只是HotSpot JDK1.8以前的一个实现而已,方法区是规范,永久代和元空间都只是一种实现而已。
永久区和元空间的区别,参考:https://blog.csdn.net/m0_53284765/article/details/131693910?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22131693910%22%2C%22source%22%3A%22m0_53284765%22%7D
https://blog.csdn.net/m0_53284765/article/details/131693910?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22131693910%22%2C%22source%22%3A%22m0_53284765%22%7D
2)组成
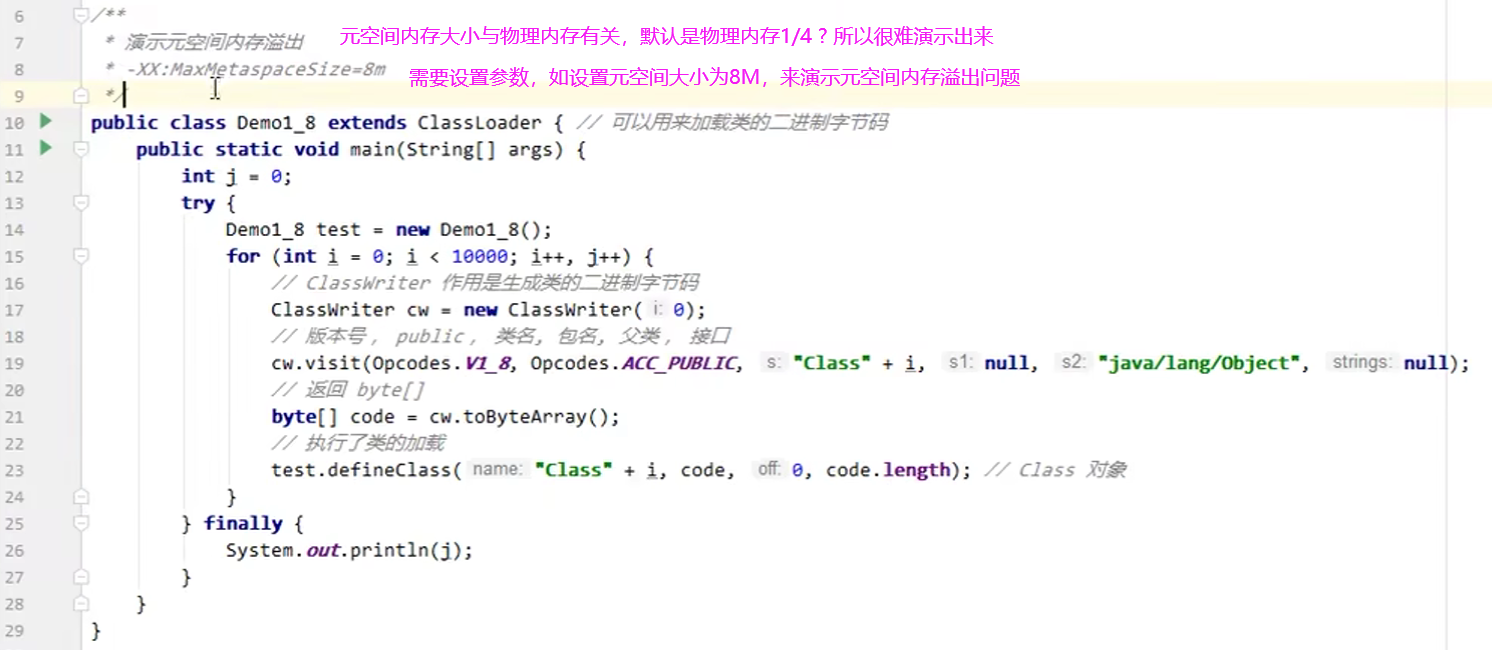
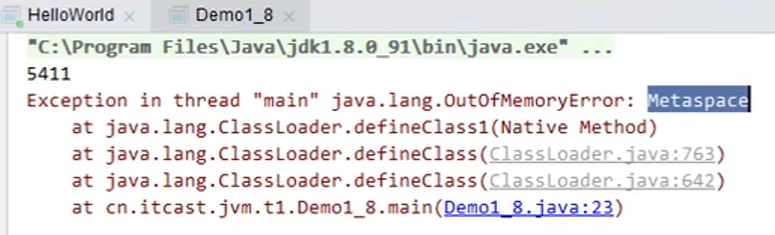
3)方法区内存溢出
- 1.8 之前会导致永久代内存溢出
- 使用 -XX:MaxPermSize=8m 指定永久代内存大小

- 1.8 之后会导致元空间内存溢出
- 使用 -XX:MaxMetaspaceSize=8m 指定元空间大小
场景:Spring、MyBatis等。动态字节码技术。
4)运行时常量池

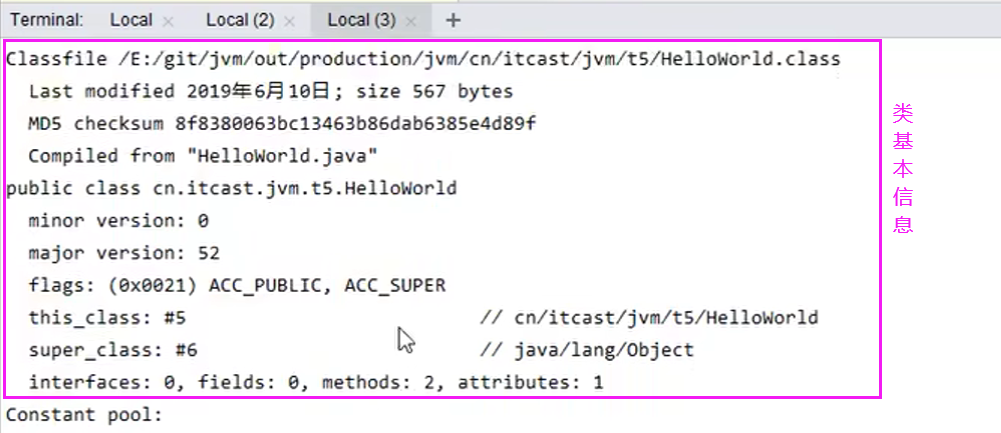 常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量
常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量
等信息;
运行时常量池:常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量
池,并把里面的符号地址变为真实地址。(若不理解再看一遍视频25、26就明白了)
5)StringTable
StringTable是运行时常量池中重要的一个组成部分,即俗称的串池。先看几道面试题:
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);回答上面问题之前,必须知道的常识点:
- ==:对于基本类型,比较的是值是否相等;对于引用类型,比较的是地址是否相等
- equals:比较的是对象是否相等(不能比较基本类型,因为equals是Object超类中的方法,而Object是所有类的父类)
- String是引用类型
5.1 常量池和串池(StringTable)的关系
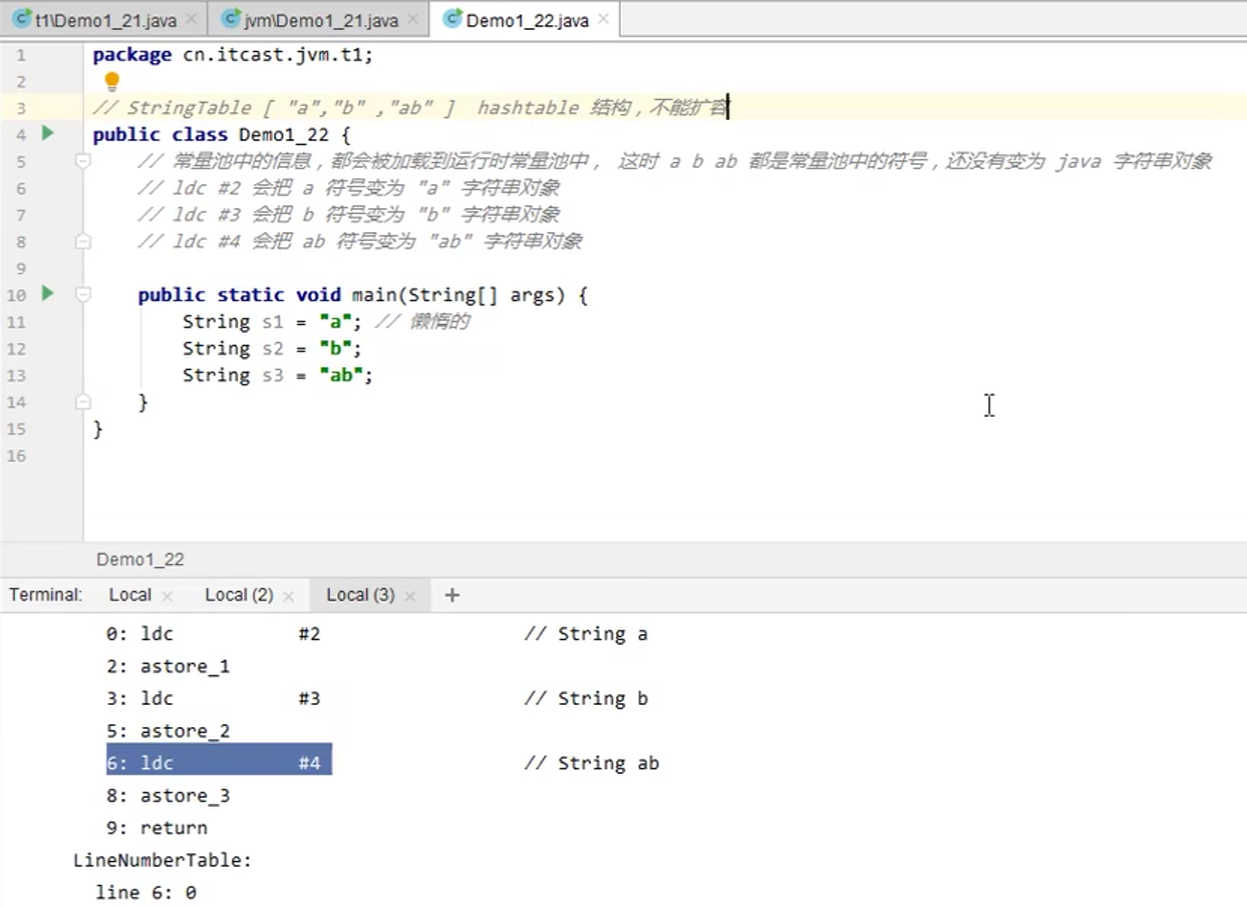
常量池,最初存在于字节码文件中,当它运行的时候就会被加载到运行时常量池,但这时a b ab 仅是常量池中的符号,还没有成为java字符串对象;只有当程序执行到第11行的时候,才会把a符号变为“a”字符串对象,以此类推。(视频28)
5.2 StringTable 特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder (1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
★ 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池。这两种情况都会把串池中的对象返回;
★ 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回;
例1:第14行代码本质分析
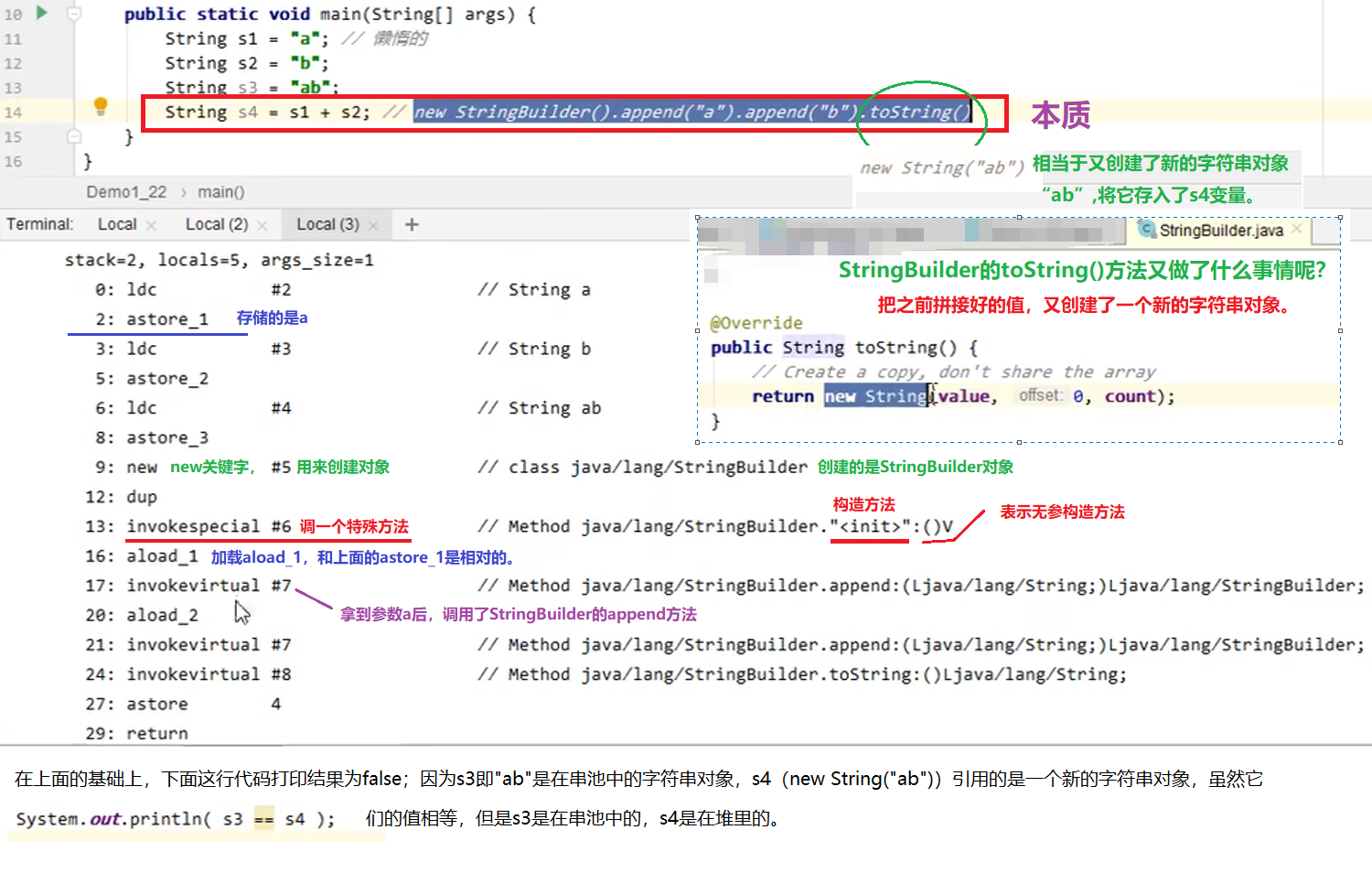
例2:常量字符串拼接的底层原理
编译期会进行优化,因为结果是确定的。

例3:intern() 方法
intern方法 1.8:
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,则放入成功
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
(下图是针对1.8的情况)

intern方法 1.6:
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
(下图是针对1.6的情况) 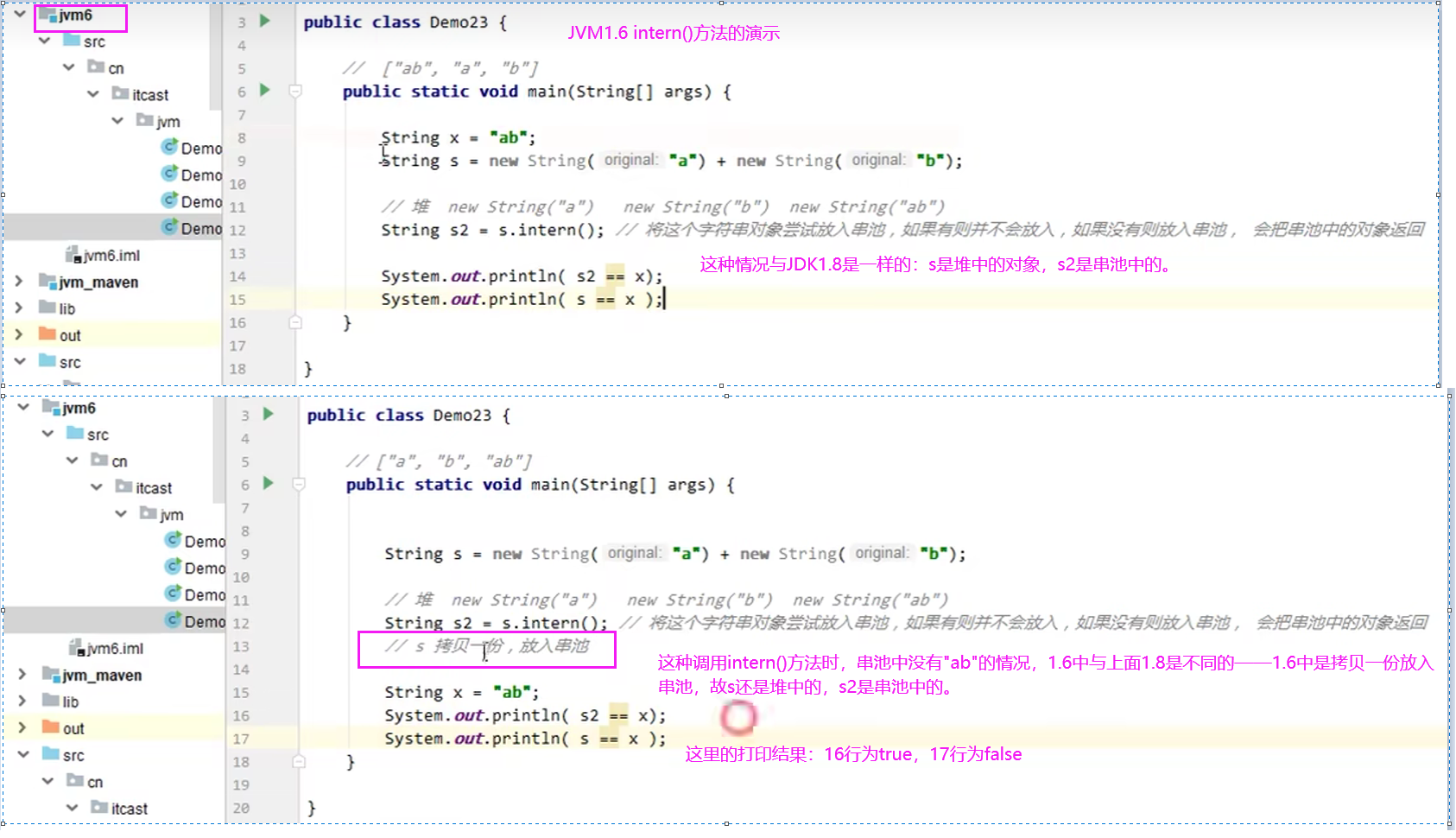
例4:面试题解答

5.3 StringTable 位置
- JDK1.6 时,StringTable是属于常量池的一部分,它随常量池存储在永久代中。
- JDK1.8 以后,StringTable是放在堆中的。
- 下面的案例证明了1.6中是存在于永久代,1.8中是存在于堆空间。
为什么要做这个更改呢?
因为永久代的内存恢复效率很低,永久代是在full GC的时候才会触发永久代的垃圾回收,而full GC要等到老年代的空间不足才会触发,触发的时机有点晚,这就间接导致StringTable的垃圾回收效率并不高。其实StringTable用的非常频繁,一个java应用程序中大量的字符串常量对象都会分配到StringTable里,如果它的回收效率不高的话,就会占用大量的内存,会产生永久代的内存不足。基于这个缺点,从JDK1.7开始,就将StringTable转移到了堆里。
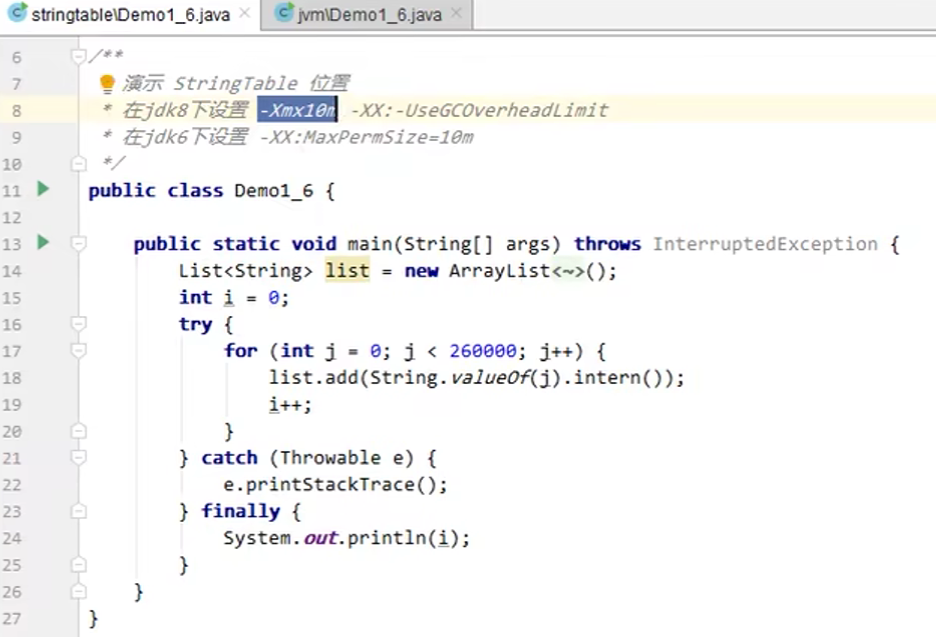

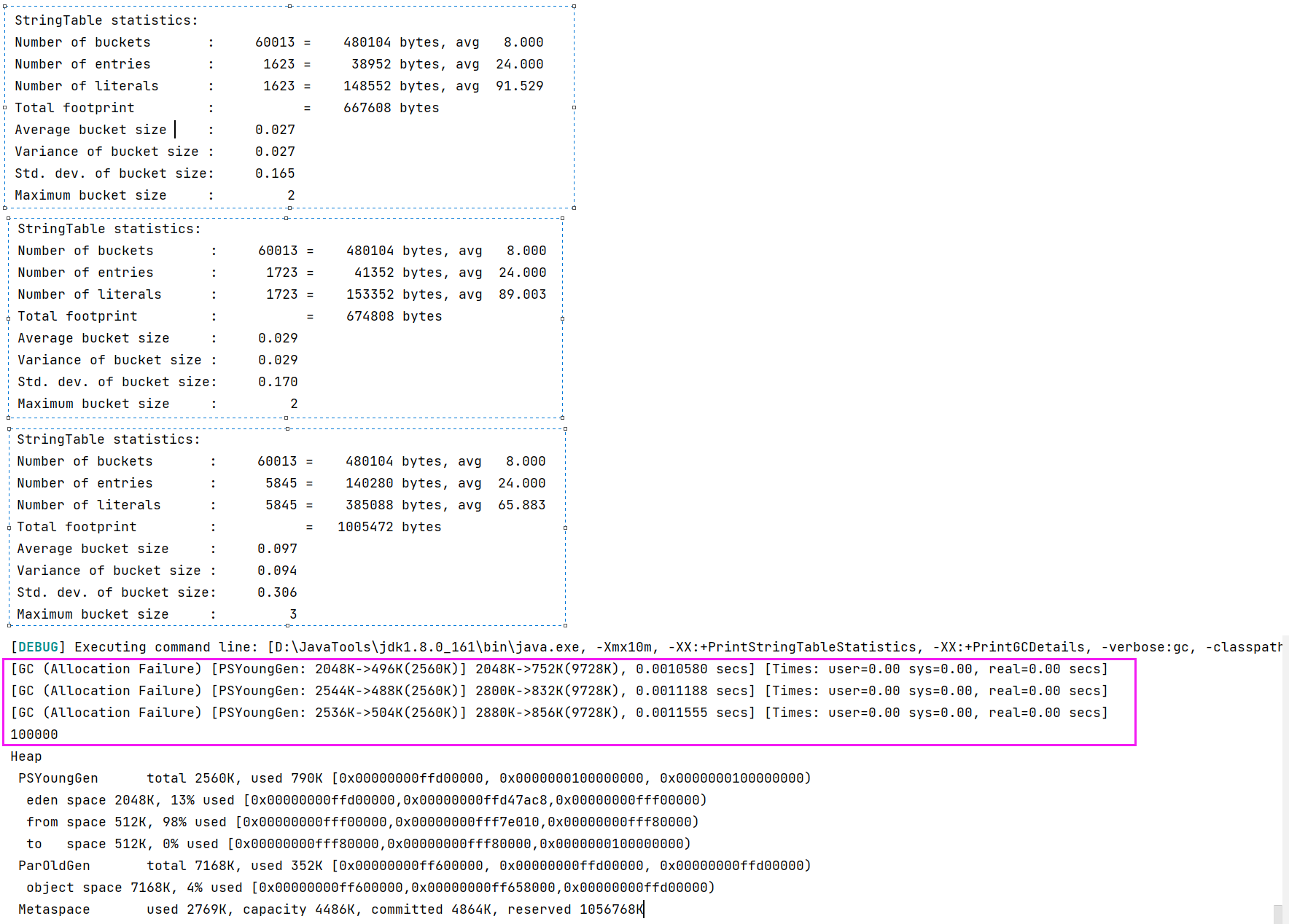
5.4 StringTable 垃圾回收
-Xmx10m 指定堆内存大小
-XX:+PrintStringTableStatistics 打印字符串常量池信息
-XX:+PrintGCDetails
-verbose:gc 打印 gc 的次数,耗费时间等信息
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
*/
public class Code_05_StringTableTest {
public static void main(String[] args) {
int i = 0;
try {
for(int j = 0; j < 10000; j++) { // j = 100, j = 10000
String.valueOf(j).intern();
i++;
}
}catch (Exception e) {
e.printStackTrace();
}finally {
System.out.println(i);
}
}
}
5.5 StringTable 性能调优
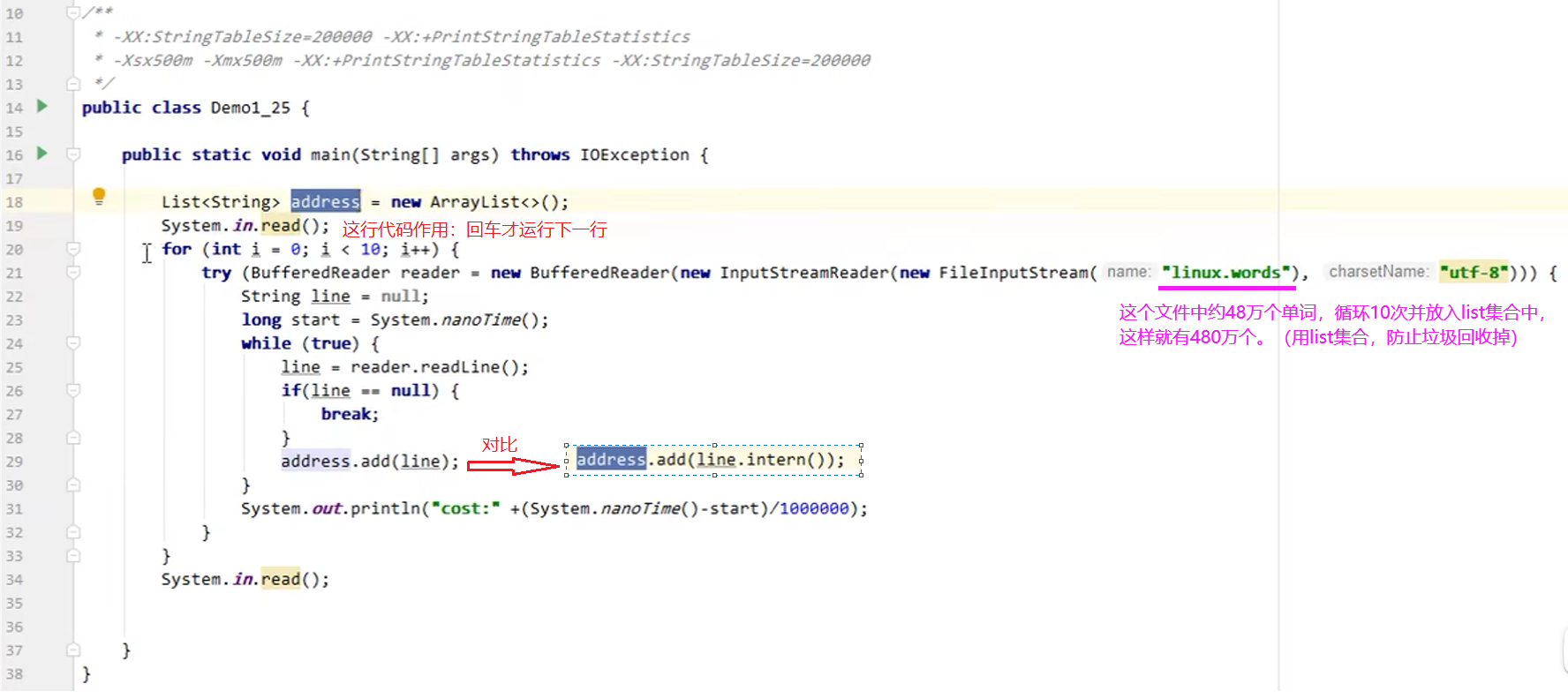
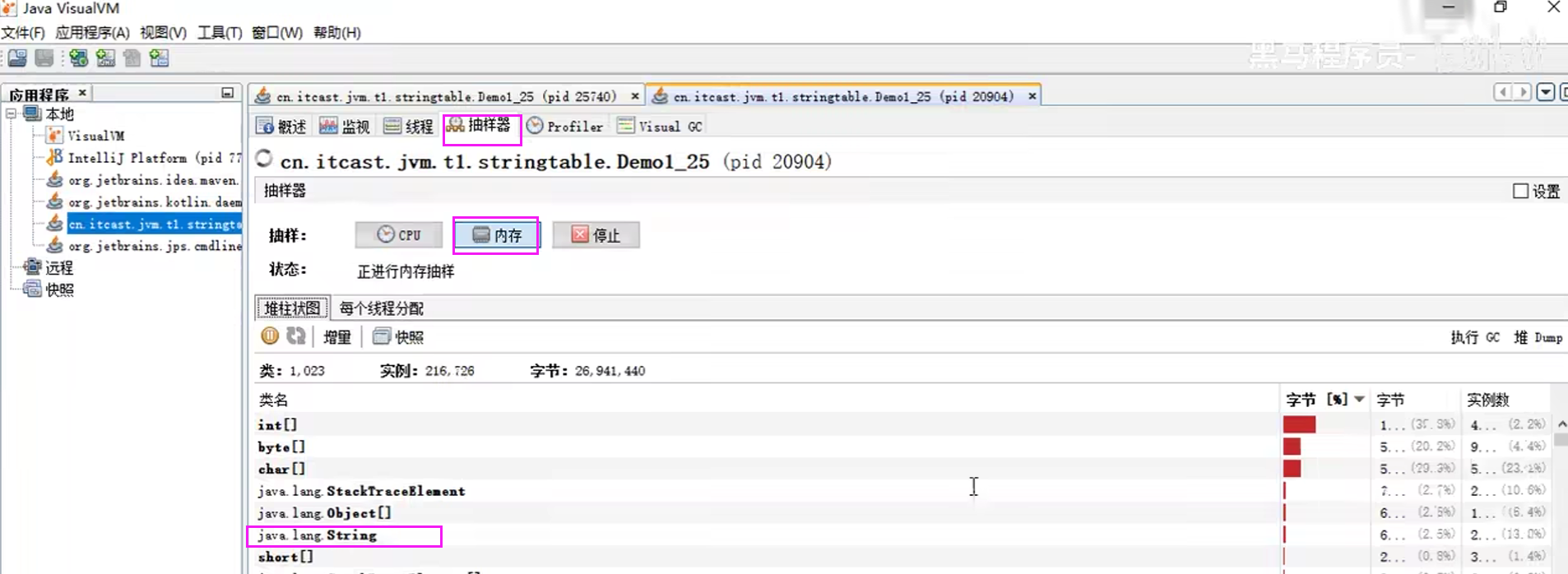
StringTable底层是哈希表,所以它的性能跟哈希表大小是密切相关的。如果哈希表桶的个数比较多,那么元素相对就分散,哈希碰撞的几乎就会减小,查找的速度也会变快;反之,如果桶的个数较少,那么哈希碰撞的几乎就会增高,导致链表较长,查找的速度也会受到影响。
- StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间
![]()
-XX:StringTableSize=xxxx
//最低为1009

- 考虑是否将字符串对象入池
可以通过intern方法减少重复入池,保证相同的地址在StringTable中只存储一份
5. 直接内存(Direct Memory)
1)定义
直接内存,并不属于Java虚拟机的内存管理,而是属于操作系统内存。
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
2)使用直接内存的好处
package cn.itcast.jvm.t1.direct;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "E:\\编程资料\\第三方教学视频\\youtube\\Getting Started with Spring Boot-sbPSjI4tt10.mp4";
static final String TO = "E:\\a.mp4";
static final int _1Mb = 1024 * 1024;
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
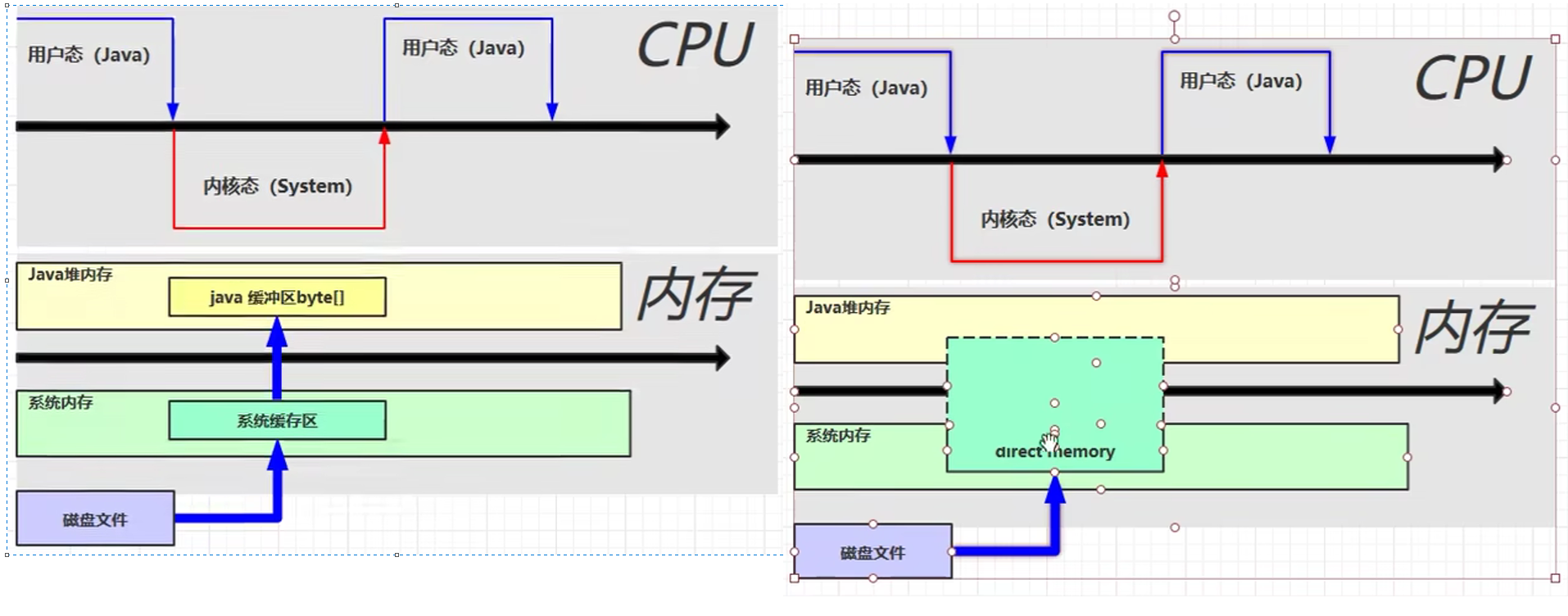
因为 java 不能直接操作文件管理,需要切换到内核态,使用本地方法进行操作,然后读取磁盘文件,会在系统内存中创建一个缓冲区,将数据读到系统缓冲区, 然后在将系统缓冲区数据,复制到 java 堆内存中。缺点是数据存储了两份,在系统内存中有一份,java 堆中有一份,造成了不必要的复制。(原理流程如上面左图)
使用了 DirectBuffer 后文件读取流程,如上面右图。直接内存是操作系统和 Java 代码都可以访问的一块区域,无需将代码从系统内存复制到 Java 堆内存,从而提高了效率。
3)演示直接内存溢出

4)直接内存回收原理
直接内存不受 JVM 内存回收管理,那么它所分配内存会不会被正确回收?底层又是怎么实现的?
public class Code_06_DirectMemoryTest {
public static int _1GB = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException, NoSuchFieldException, IllegalAccessException {
// method();
method1();
}
// 演示 直接内存 是被 unsafe 创建与回收
private static void method1() throws IOException, NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe)field.get(Unsafe.class);
long base = unsafe.allocateMemory(_1GB);
unsafe.setMemory(base,_1GB, (byte)0);
System.in.read();
unsafe.freeMemory(base);
System.in.read();
}
// 演示 直接内存被 释放
private static void method() throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1GB);
System.out.println("分配完毕");
System.in.read();
System.out.println("开始释放");
byteBuffer = null;
System.gc(); // 手动 gc
System.in.read();
}
}
直接内存的回收不是通过 JVM 的垃圾回收来释放的,而是通过unsafe.freeMemory 来手动释放。
第一步:allocateDirect 的实现
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
底层是创建了一个 DirectByteBuffer 对象。
第二步:DirectByteBuffer 类
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); // 申请内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 通过虚引用,来实现直接内存的释放,this为虚引用的实际对象, 第二个参数是一个回调,
//实现了 runnable 接口,run 方法中通过 unsafe 释放内存。
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
这里调用了一个 Cleaner 的 create 方法,且后台线程还会对虚引用的对象监测,如果虚引用的实际对象(这里是 DirectByteBuffer )被回收以后,就会调用 Cleaner 的 clean 方法,来清除直接内存中占用的内存。
public void clean() {
if (remove(this)) {
try {
// 都用函数的 run 方法, 释放内存
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
可以看到关键的一行代码, this.thunk.run(),thunk 是 Runnable 对象。run 方法就是回调 Deallocator 中的 run 方法,
public void run() {
if (address == 0) {
// Paranoia
return;
}
// 释放内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
直接内存的回收机制总结
- 使用了 Unsafe 类来完成直接内存的分配回收,回收需要主动调用freeMemory 方法
- ByteBuffer 的实现内部使用了 Cleaner(虚引用)来检测 ByteBuffer 。一旦ByteBuffer 被垃圾回收,那么会由 ReferenceHandler(守护线程) 来调用 Cleaner 的 clean 方法调用 freeMemory 来释放内存
注意:
/**
* -XX:+DisableExplicitGC 显示的
*/
private static void method() throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1GB);
System.out.println("分配完毕");
System.in.read();
System.out.println("开始释放");
byteBuffer = null;
System.gc(); // 手动 gc 失效
System.in.read();
}
一般用 jvm 调优时,会加上下面的参数:
-XX:+DisableExplicitGC // 静止显示的 GC
意思就是禁止我们手动的 GC,比如手动 System.gc() 无效,它是一种 full gc,会回收新生代、老年代,会造成程序执行的时间比较长。所以我们就通过 unsafe 对象调用 freeMemory 的方式释放内存。