import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#matplotlib 的字体(font)为黑体(SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei', ]
# matplotlib正确显示正负号
plt.rcParams['axes.unicode_minus'] = False
# 图片高清输出
%config InlineBackend.figure_format = 'svg'
#省略掉plt.show()这一步
%matplotlib inline
初级
本文以xxx表示需要处理的数组
一、符号:
&————并且
|————或者
~————否
any————任一
all————全部
@————数组乘
二、方法(默认axis=0,inplace=False)
1.和
xxx.sum()
np.sum(xxx)
2.算术平均
xxx.mean()
np.mean(xxx)
3.中位数和指定位数
np.median(xxx)
np.quantile(xxx,0.5)
4.最大值
xxx.max()
np.amax()
5.最小值
xxx.min()
np.amin(xxx)
6.极差
xxx.ptp()
np.ptp(xxx)
7.方差
xxx.var()
np.var(xxx)
8.标准差
xxx.std()
np.std(xxx)
9.累计和
(每个值是:自己的值+前面所有值)
xxx.cumsum()
10.最大值的索引
xxx.argmax()
11.最小值的索引
xxx.argmin()
12.获取非0元素
xxx[xxx.nonzero()]
xxxx[xxx !=0]
13.排序(升序)
xxx.sort()
np.sort(xxx)
ascending__升序
xxx.sort_values(ascending=False)
xxx.sort_index()
14.转置
xxx.T
xxx.swapaxes(0,1)
xxx.transpose()
15.转列表
xxx.tolist()
16.调整数组的形状
必须与原数组元素个数相同
x.reshape(3,4)
x.reshape(2,2,3) -------(元素个数,行数,列数)
无限制
(不够重复取,够了从头开始取)
np.resize(xxx,(20,3))
np.resize(xxx,(10,3,2))
17.判断空值
判断数字
np.isnan(xxx)
判断所有空值
np.isna(xxx)
判断不是空值的话把is换成not就行
np.notna(xxx)
删除有空值的行
xxx.dropna()
判断没有空值
np.all(xxx.notna())
18.判断极大值
np.ifinf(xxx)
19.堆积数组
竖方向
np.vstack(xxx,xx)
横方向
np.hstack(xxx,xx)
堆积为更高维度的数组
(变成两个元素的数组)
np.stack((xxx,xx))
20.拆分数组
np.split(xxx,分成几组)
expand 是否切成单独列
xxx[列名].str.split(‘切割依据’,expand=True,n=切割次数)
21.追加元素
np.append(xxx,追加的元素)
22.指定元素插入元素
np.insert(xxx,位置,插入的元素)
23.重复元素
np.repeat(xxx,重复个数)
24.条件处理元素
对元素挑选
np.extract(条件,xxx)
按条件处理数据
np.select([条件1,条件2],[处理1,处理2])
对某条件满足或不的处理
np.where(条件,成立处理,不成立处理)
对满足条件的值用指定值替换
np.place(xxx,条件,[指定值])
用指定值替换指定索引元素
np.put(xxx,[索引],[替换值])
向量

1.向量的点积运算
np.dot(xxx,xx)
2.向量的模
np.linalg.norm(xxx)
3.行列式的值
np.linalg.det(xxx)
4.求逆矩阵
np.linalg.inv(xxx)
5.解方程
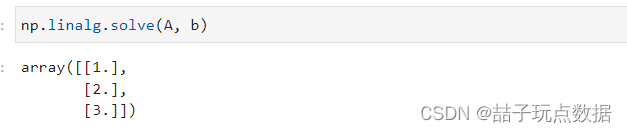
np.linalg.solve(A,b)
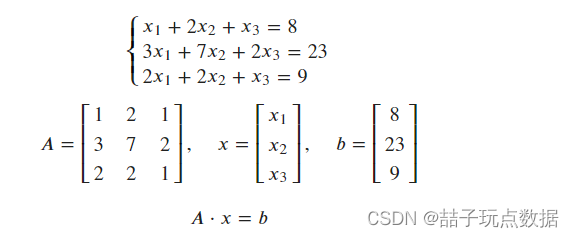
numpy详解
1.读取CSV文件的数据创建DataFrame对象
df = pd.read_csv(
‘数据.csv’,
index_col=‘id’, # 设置索引列(哪个列充当索引)
# encoding=‘utf-8’, # 设置字符编码方式
# usecols=[‘id’, ‘name’, ‘company’, ‘score’], # 设置需要加载的列
# nrows=20, # 设置加载的行数
# skiprows=np.arange(1, 11), # 设置跳过的行
# delimiter=‘,’, # 设置分隔符(默认是逗号)
# sep=‘,’, # 设置分隔符(默认是逗号)
# quotechar=‘"’, # 设置包裹字符串的字符(默认是双引号)
# iterator=True, # 使用迭代器模式(一次只加载一部分数据)
# chunksize=1000, # 每次加载的数据量
)
2.读取Excel文件的数据创建DataFrame对象
Office 2007- —> xls —> xlrd
Office 2007+ —> xlsx —> openpyxl
%pip install xlrd openpyxl
df = pd.read_excel(
‘数据.xlsx’,
sheet_name=‘data’, # 需要读取的表单的名字
# header=1, # 表头在第几行(从0开始计数)
)
3.安装连接MySQL数据库需要的三方库(依赖项)
%pip install -U pymysql cryptography
从数据库服务器中获取数据创建DataFrame对象
import pymysql
conn = pymysql.connect(host=‘xxx’, port=3306,
user=‘niuzi’, password=‘xxx’,
database=‘hrs’, charset=‘utf8mb4’)
df6 = pd.read_sql_query(‘select * from tb_dept’, conn, index_col=‘dno’)
df
4…安装连接MySQL数据库需要的三方库(依赖项)
SQLAlchemy —> ORM —> Object Relational Mapping
URL / URI —> Universal Resource Locator / Identifier
pymysql / mysqlclient
%pip install -U sqlalchemy
from sqlalchemy import create_engine
engine = create_engine(‘mysql+pymysql://niuzi:456789@192.168.75.1:3306/hrs’)
df = pd.read_sql_table(‘tb_dept’, engine, index_col=‘dno’)
处理继续
1.获取DataFrame对象的相关信息
xxx.info()
2.获取前几行数据
xxx.head(获取几行)
xxx[:3]
xxx.nlargest(3,‘销售额’)
3.获取后几行数据
xxx.tail(获取几行)
xxx.nsmallest(3,‘销售额’)
4.通过索引获取指定列
xxx[‘行名’]
xxx.行名
花式获取
xxx[[行名1,行名2,行名3]]
5.通过索引获取指定行
xxx.loc[列索引]
取得到结尾
xxx.loc[列索引:列索引]
xxx.iloc[列下标]
取不到结尾
xxx.iloc[列下标:列下标]
布尔索引
xxx[xxx.条件]
条件例子(选出good列值为5的行):
xxx[xxx.good = 5]
获取指定值
xxx.at[行索引,列索引]
xxx.iat[行下标,列下标]
6.修改单元格的值
即获取值后直接等于值
xxx.at[行索引,列索引] = ‘值’
xxx.iat[行下标,列下标] = ‘值’
7.添加列
xxx[列名]=[值,值,值…]
8.添加行
xxx.loc[索引]=[值,值,值…]
9.删除列
xxx.drop(columns=[‘列名’,‘列名’])
10.删除行
xxx.drop(index=[索引,索引])
删除np.delete(xxx,索引)
11.重置索引(让所有成为普通列)
会自动生成一个新索引(0,1,2,3+…)
xxx.reset_index(inplace=True)
12.指定新的索引
xxx.index.name = ‘新的索引列名’
12.merge表连接
how————连接方式
当两表指定连接字段相同时直接用on指定
如果不一样,用left_on=‘列名’,right_on=‘列名’
左连接
表一.merge(表二,how=‘left’,on=‘dno’)
left_index、right_index是指定表中索引列为连接键(可以写为True,False)
13.concat表连接
pd.concat([表一,表二],ignore_index=True,axis=0)
例子:文件内多个表连接
import os
# 下括号可以换成('res/jobs/'+csv_file)
dfs = [pd.read_csv(os.path.join('jobs', csv_file),
usecols=['company_name', 'salary', 'site', 'year', 'edu', 'job_name', 'job_type'])
for csv_file in os.listdir('jobs')]
all_jobs_df = pd.concat(dfs, ignore_index=True)
all_jobs_df
14.调整索引顺序
函数方法
xxx.reindex(columns=[‘列名一’,‘列名二’,‘列名三’,…])
花式索引法
xxx[[‘列名一’,‘列名二’,‘列名三’,…]]
15.替换值
xxx.replace(需要替换的值 , 替换值 )
16.填充值
xxx.fillna(空值的话填入的值)
空值区域填入上面第一个非空的值
把ffill换成bfill机会换成下面第一个非空的值
xxx.fillna(method=‘ffill’)
指定填充
xxx.fillna({行索引一:替换的值,行索引二:替换的值…})
17.判断重复值
xxx.duplicated()
18.删除有重复值的行
可以添加keep函数(默认first)
-first保留重复值的第一项
-last保留重复值的最后一项
-False重复数据都不保留
xxx.drop_dudplicates(‘列索引’)
19.获取不重复数据的数量
xxx.nunique()
20.获取不重复数据的数组
xxx.unique()
21.获取描述性统计信息
xxx.describe()
22.改行名
xxx.rename(columns={列名一 : 新列名, 列名二:心新列名,…})
23.拆解字段
expand是表示是否把series类型转化为DataFrame类型
xxx.split(分解的依据,expand=True,)
24.挑选字段
xxx.query(‘列名’ ==‘挑选值’…)
25.统一字段拼写方式
统一为首字母大写
xxx.str.title()
全部大写/小写
xxx.str.lower()
xxx.str.upper()
26.判断是否包含
xxx.str.contains(‘包含内容’)
27.对数组数据进行统一功能
xxx.apply(函数)
xxx.map(函数)
xxx.map({原数据:希望变成的元素,原数据:希望变成的元素…})
xxx.applymap(int)
xxx.applymap(lambda x:int(x **2))
28.将字符串处理成为时间类型
pd.to_datetime(xxx.日期列名)
29.拆解时间
年
xxx.时间列名.dt.year
季度
xxx.时间列名.dt.quarter
月份
xxx.时间列名.dt.month
星期
周一————0
周二————1
…
周日————6
xxx.时间列名.dt.weekend
天
xxx.时间列名.dt.days
30.数据分段
right是左闭右开的意思
xxx.cut(切割的列名,bins=np.arange(初始值 ,末尾值 ,间隔 ), right=False)
31.统计信息
xxx.groupby(统计的列名)[[根据的行名].count()]
32.聚合
xxx.groupby(统计的列)[[列1,列2]].agg({列1:处理方式,列2,[处理方式1,处理方式2]})
sales_df.groupby(sales_df.日期.dt.month)[[‘销售额’, ‘数量’]].agg({‘销售额’: ‘sum’, ‘数量’: [‘max’, ‘min’]})
33.上个月数据
整体数据向下移,首行变为空值
xxx.列名.shift(1)
34.窄表
pd.pivot(xxx,index=根据的行,columns=根据的列,values=值)
35.创建透视表(根据A统计B)
pd.pivot_table(
sales_df,
index=‘销售城市’, columns=‘月份’, # A
values=‘销售额’, # B
aggfunc=‘sum’, # 聚合方式(默认是mean)
margins=True, # 显示总计
margins_name=‘总计’ # 总计列的名字
)