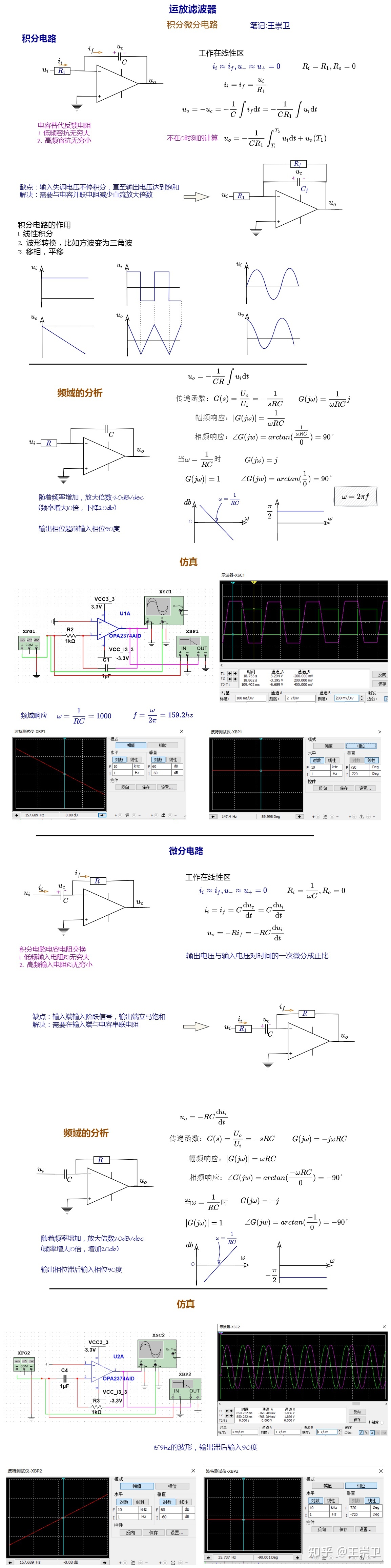
为什么使用Glide?
- 使用简单,链式调用,API简洁。with、load、into三步走就可以加载图片
- 生命周期自动绑定,根据绑定的Activity或者Fragment生命周期管理图片请求
- 高效处理Bitmap。支持bitmap的复用和主动回收,减少系统回收压力。
- 占用内存小(使用RGB565的格式),RGB8888每个像素占的字节会比RGB565多占一倍,所以占用的内存会大一点
- 支持多种图片格式(Gif,Webp,Jpg)
Glide加载流程
Glide的加载过程大致如下:
- Glide.with获取与生命周期绑定的RequestManager
- RequestManager通过load获取对应的RequestBuilder
- into方法中RequestBuilder构建对应的Request,Target。将Request,Target交给RequestManager进行统一管理。
- 调用Request.track开始进行图片请求
- request通过Engine分别尝试从活动缓存,LRU缓存,文件缓存中加载图片,当以上的缓存都不存在对应的图片后,会从网络中获取
- 网络大致可以分成,ModelLoader模型匹配,DataFetcher数据获取,然后经历解码,图片变换,转换。如果能够进行缓存原始数据,还会将解码的数据进行编码缓存到文件。
Glide的生命周期管理
- 创建一个无UI的Fragment(SupportRequestManagerFragment),并绑定到当前Activity,这样Fragment就可以感知Activity的生命周期;
- 在创建Fragment的时候,初始化Lifecycle,LifecycleListener,并且在生命周期的onStart(),onStop(),onDestroy()中调用相关方法
- 在创建RequestManager时传入Lifecycle对象,并且实现了LifecycleListener接口
- 这样当生命周期变化的时候,就可以通过接口回调去通知RequestManager处理请求。
Glide的生命周期主要分为2个部分:
如何感知当前页面的生命周期?
通过创建一个无UI的Fragment来实现;
如何传递生命周期?
RequestManager与Fragment之间通过Lifecycle,LifeCycleListener接口回调的方式来实现
Glide缓存管理
Glide将它的缓存分为2个大部分,一个是内存缓存,一个是硬盘缓存,其中内存缓存又分为2种,弱引用和Lrucache;磁盘缓存就是DiskLrucache,DiskLrucache算法和Lrucache差不多的,所以现在看起来Glide3级缓存的话应该是WeakReference + Lrucache + DiskLrucache。
引入缓存的目的
- 减少流量消耗,加快响应速度
- Bitmap的创建/销毁比较耗内存,可能导致频繁GC;使用缓存的话可以更加高效的加载Bitmap,减少卡顿。
Glide缓存流程
Glide缓存分为:内存缓存和磁盘缓存,其中内存缓存是由弱引用 + Lrucache组成
其中读取数据的顺序是:弱引用 > LruCache > DiskLruCache>网络;
写入缓存的顺序是:网络 --> DiskLruCache–>弱引用–>LruCache
内存缓存原理
1.弱引用
底层数据结构:HashMap维护,key是缓存的key,这个key由图片url、width、height等10个参数来组成;value是图片资源对象的弱引用形式。
Map<Key, ResourceWeakReference> activeEngineResources = new HashMap<>();
2.LruCache
底层数据结构:LinkedHashMap,LRU即最近最少使用,一种常用的置换算法,选择最近最久未使用的对象予以淘汰。LinkedHashMap链表的特性,把最近使用过的文件插入到列表头部,没使用的图片放在尾部。
这是Glide自定义的LruCache:
#LruCache
Map<T, Y> cache = new LinkedHashMap<>(100, 0.75f, true);
3.存取原理
取数据
在内存缓存中有一个概念叫图片引用计数器,具体来说是在EngineResource中定义一个acquired变量来记录图片被引用的次数,调用acquired()方法让变量+1,调用release()方法让变量-1。
获取图片资源是先从弱引用取缓存,拿到的话,引用计数+1;没有的话从LruCache中拿缓存,拿到的话,引用计数也是+1,同时把图片从LruCache缓存转移到弱引用缓存池中;再没有的话就通过EngineJob开启线程池去加载图片,拿到的话,引用计数+1,会把图片放到弱引用。
存数据
很明显,这是加载图片之后的事情,通过EngineJob开启线程池去加载图片,取到数据之后,会回调到主线程,把图片存到弱引用。当图片不再使用的时候,比如说暂停请求或者加载完毕或者清除资源时,就会将其从弱引用中转移到LruCache缓存池中。总结一下,就是正在使用中的图片使用弱引用来进行缓存,暂时不用的图片使用LruCache来进行缓存的功能;同一张图片只会出现在弱引用和LruCache中的一个。
为什么要引入弱引用?
- 分压策略,减少Lrucache中trimToSize的概率。如果正在remove的是张大图,Lrucache正好处在临界点,此时remove操作,将延缓Lrucache的trimToSize操作
- 提高效率:弱引用用的是HashMap,Lrucache用的是LinkedHashMap,从访问效率而言,肯定是HashMap更高
手写Lrucache
手写Lru首先的数据结构是LinkedHashMap
LRU缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。
//采用双向链表+哈希表
public class LRUCache {
class DLinkedNode{
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode(){
}
public DLinkedNode(int _key,int _value){
key=_key;
value=_value;
}
}
private Map<Integer,DLinkedNode> cache=new HashMap<Integer,DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head,tail;
public LRUCache(int capacity) {
this.size=0;
this.capacity=capacity;
//使用伪头部和伪尾部节点
head=new DLinkedNode();
tail=new DLinkedNode();
head.next=tail;
tail.prev=head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node){
node.prev=head;
node.next=head.next;
head.next.prev=node;
head.next=node;
}
private void removeNode(DLinkedNode node){
node.prev.next=node.next;
node.next.prev=node.prev;
}
private void moveToHead(DLinkedNode node){
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail(){
DLinkedNode res= tail.prev;
removeNode(res);
return res;
}
}
这个数据结构长这样
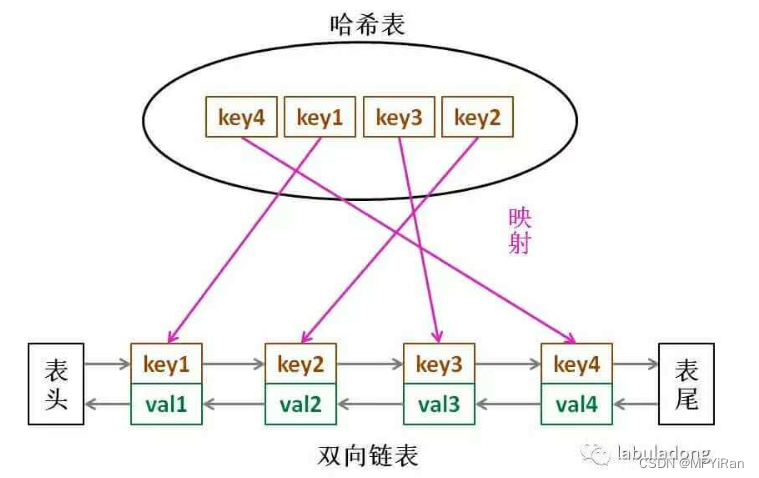
借助这个结构,我们来逐一分析:
1.如果我们每次默认从链表尾部添加元素,那么显然越靠尾部的元素就是最近使用的,越靠头部就是最久未使用的。
2.对于某一个key,我们可以通过哈希表快速定位到链表中的节点,从而取得对应val。
3.链表显然是支持在任意位置快速插入和删除的,改改指针就行。只不过传统的链表无法按照索引快速访问某一个位置的元素,而这里借助哈希表,可以通过 key 快速映射到任意一个链表节点,然后进行插入和删除。
为什么是双向链表?
因为我们需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
磁盘缓存原理(DiskLruCache)
- DiskCacheStrategy.DATA: 只缓存原始图片;
- DiskCacheStrategy.RESOURCE:只缓存转换过后的图片;
- DiskCacheStrategy.ALL:既缓存原始图片,也缓存转换过后的图片;对于远程图片,缓存 DATA和 RESOURCE;对于本地图片,只缓存 RESOURCE;
- DiskCacheStrategy.NONE:不缓存任何内容;
- DiskCacheStrategy.AUTOMATIC:默认策略,尝试对本地和远程图片使用最佳的策略。当下载网络图片时,使用DATA(原因很简单,对本地图片的处理可比网络要容易得多);对于本地图片,使用RESOURCE。
如果在内存缓存中没获取到数据会通过EngineJob开启线程池去加载图片,这里有2个关键类:DecodeJob和EngineJob。EngineJob内部维护了线程池,用来管理资源加载,当资源加载完毕的时候通知回调;DecodeJob是线程池中的一个任务。
磁盘缓存是通过DiskLruCache来管理的,根据缓存策略,会有2种类型的图片,DATA(原始图片)和RESOURCE(转换后的图片)。磁盘缓存依次通过ResourcesCacheGenerator、SourceGenerator、DataCacheGenerator来获取缓存数据。ResourcesCacheGenerator获取的是转换过的缓存数据;SourceGenerator获取的是未经转换的原始的缓存数据;DataCacheGenerator是通过网络获取图片数据再按照按照缓存策略的不同去缓存不同的图片到磁盘上。
Glide内存管理
Glide内存管理分为
- OOM的防治
- 内存抖动
OOM防止
1.Glide图片采样
Glide针对较大的图片,就根据当前UI显示的大小与实际大小的比例,进行采样计算从而减少图片在内存中的占用。一般而言图片的大小=图片宽 * 图片高 * 每个像素占用的字节数
对于资源文件夹下的图片:
图片的高 = 原图高 X (设备的 dpi / 目录对应的 dpi )
图片的宽 = 原图宽 X (设备的 dpi / 目录对应的 dpi )
onlowMemory/onTrimMemory
- 当内存过低的时候会调用onlowMemory,在onlowMemory 中Glide会将一些缓存的内存进行清除,方便进行内存回收,
- 当onTrimMemory被调用的时候,如果level是系统资源紧张,Glide会将Lru缓存和BitMap重用池相关的内容进行回收。
- 其他的原因调用onTrimMemory,Glide会将缓存的内容减小到配置缓存最大内容的1/2。
2.弱引用
Glide通过RequestManager管理图片请求,而RequestManager内部是通过RequestTracker和TargetTracker来完成的。他们持有的方式都是弱引用的。
3.生命周期绑定
减少加载到内存的图片大小,清除不必要的对象引用,从而减少OOM的概率。
内存抖动的处理
1.Glide通过重用池技术,将一些常用的对应进程池化,比如图片加载相关的EngineJob DecodeJob等一下需要大量重复使用创建的对象,通过对象重用池进行对象重
2.BitmapPool对Bitmap进行对象重用。在对图片进行解码的时候通过设置BitmapFactory.Options.inBitmap来达到内存重用的目的。
Glide中的线程和线程池
关于Glide中的线程和线程池有两个方面
1.图片加载回调
Glide有两种图片加载方式into和submit
- 通过into加载的图片会通过Executors的MAIN_THREAD_EXECUTOR回调到主线程。
- 通过submit的进行回调的会通过Executors的DIRECT_EXECUTOR在当前线程进行处理。
2.Glide的线程池配置
线程作为cpu调度的最小单位,每一次创建和回收都会有较大的消耗,通过使用线程池可以
- 降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度:当任务到达时,可以不需要等待线程创建就能立即执行
- 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,监控和调优。
- 有效的控制并发数
Glide中提供了四种线程池配置。
1.DiskCacheExecutor 该线程池只有一个核心线程,没有非核心线程,所有任务在线程池中串行执行。在Glide中常用与从文件中加载图片。
2.SourceExecutor 该线程也只有核心线程没有非核心线程,与DiskCacheExecutor 的不同之处在于核心线程的数量根据CPU的核数来决定。如果cpu核心数超过4则核心线程数为4 如果Cpu核心数小于4那么使用Cpu核心数作为核心线程数量。在Glide中长用来从网络中加载图片。
3.UnlimitedSourceExecutor 没有核心线程,非核心线程数量无限大。这种类型的线程池常用于执行量大且快速结束的任务。在所有任务结束后几乎不消耗资源。
4.AnimationExecutor 没有核心线程,非核心线程数量根据Cpu核心数来决定,当Cpu核心数大于等于4时 非核心线程数为2,否则为1。
Glide如何加载不同类型的资源
Glide通过RequestManager的as方法确定当前请求Target最终需要的资源类型。通过load方法确定需要加载的model资源类型,资源的加载过程经历ModelLoader的model加载匹配,解码器解码,转码器的转换,这几个过程构建成一个LoadPath。而每一个LoadPath又包含很多的DecodePath,DecodePath的主要作用是将ModelLoader加载出来的数据进行解码,转换。Glide会遍历所有可能解析出对应数据的LoadPath直到数据真正解析成功。
Glide如何加载Gif
首先需要区分加载的图片类型,即网络请求拿到输入流后,获取输入流的前3个字节,如果为GIF文件头,则返回图片类型为GIF。
确定为GIF动图后,会构建一个GIF的解码器,它可以从GIF动图中读取每一帧的数据并转换为Bitmap,然后使用Canvas将Bitmap绘制到ImageView上,下一帧则利用Handler发送 一个延迟消息实现连续播放,所有Bitmap绘制完成后又会重新循环,所以就实现了加载GIF动图的效果。
GIF解码成多张图片进行无限轮播,每帧切换都是一次图片加载请求,再加载到新的一帧数据之后会对旧的一帧数据进行清除,然后再继续下一帧数据的加载请求。