文章目录
- 1 前言
- 1.1 LASSO的介绍
- 1.2 LASSO的应用
- 2. diabetes数据集实战演示
- 2.1 导入函数
- 2.2 导入数据
- 2.3 拟合模型(AIC/BIC)
- 2.4 AIC/BIC可视化
- 2.5 拟合交叉验证模型及可视化
- 3. Hitters数据集实战演示
- 3.1 导入函数
- 3.2 导入数据
- 3.3 数据预处理
- 3.4 定义变量和缩放数据
- 3.5 拟合模型
- 3.6 拟合交叉验证模型
- 4. 讨论
1 前言
1.1 LASSO的介绍
LASSO(Least Absolute Shrinkage and Selection Operator)是一种用于线性回归和特征选择的正则化方法。它的基本原理是在损失函数中引入L1正则化项,通过最小化数据拟合误差和正则化项的和来实现模型参数的稀疏化和特征选择。
这种正则化项以模型参数的绝对值之和乘以一个调节参数alpha的形式出现,促使模型选择少量重要的特征,并将其他特征的系数缩减为零。通过调节alpha的值,我们可以控制模型的复杂度和特征选择的程度。LASSO的优势在于它能够自动进行特征选择,并产生更简洁和解释性强的模型。
优点:
- 特征选择:LASSO回归通过L1正则化项,倾向于将某些回归系数估计为零,从而实现特征选择的效果。它可以帮助自动识别对目标变量具有显著影响的特征,从而简化模型并提高可解释性。
- 处理共线性:LASSO回归在存在共线性(自变量之间高度相关)的情况下,可以有效减小回归系数的大小,并将某些相关变量的系数估计为零。这有助于解决多重共线性问题,提高模型的稳定性和泛化能力。
- 可解释性:由于LASSO回归具有稀疏性,它仅选择了与目标变量相关的特征,使得模型的结果更易解释和理解。
缺点:
- 参数选择:LASSO回归的性能高度依赖正则化参数λ的选择。选择合适的λ值并不容易,需要进行交叉验证或其他优化方法来确定最佳的正则化参数,这增加了使用LASSO回归的复杂性。
- 不稳定性:在自变量之间存在高度相关性的情况下,LASSO回归可能对于数据中微小的变化非常敏感,导致系数估计的不稳定性。这意味着对于不同的训练集,可能会得到不同的结果。
- 随机性:当多个特征高度相关时,LASSO回归倾向于随机选择其中之一,并将其他特征的系数估计为零。这意味着在拟合过程中,具有相似性的特征可能会被选择或排除,具有一定的随机性。
1.2 LASSO的应用
-
特征选择:
在大数据集和探索性数据分析中,LASSO回归非常有用。它可以帮助从大量的特征中鉴别出对目标变量具有重要影响的特征,从而简化分析过程并提高预测模型的可解释性。 -
经济学和金融学:
LASSO回归在经济学和金融学中被广泛应用。它可用于识别对经济或金融指标具有显著影响的因素。例如,可以利用LASSO回归来预测房价、股价或其他经济变量。 -
生物信息学和基因表达分析:
LASSO回归在生物信息学和基因表达分析中扮演重要角色。它可以用于基因选择,帮助确定与生物过程、疾病或其他生物特征相关的基因。 -
医学研究:
LASSO回归可应用于医学研究的数据分析中。例如,可以使用LASSO回归来预测疾病风险、识别生物标志物或预测治疗结果等。 -
图像处理和计算机视觉:
LASSO回归在图像处理和计算机视觉领域中发挥作用。它可用于特征提取和图像恢复问题。通过LASSO回归,我们能够提取图像中的重要特征,并减少图像处理过程中的噪声和冗余。 -
自然语言处理:
LASSO回归也被广泛应用于自然语言处理领域。例如,可以使用LASSO回归来进行文本分类、情感分析和关键词提取等任务。
2. diabetes数据集实战演示
这里介绍两种模型思路:AIC/BIC模型,交叉验证模型
-
**AIC(Akaike Information Criterion)**和 **BIC(Bayesian Information Criterion)**是用于模型选择的准则。它们考虑了模型对数据的拟合程度和模型的复杂度,以平衡这两个因素。
AIC 和 BIC 都是基于信息论的概念,通过对模型的对数似然函数值和模型参数数量的加权组合来衡量模型的质量。较小的 AIC 或 BIC 值表示模型对数据的拟合更好且模型较简单。
使用 AIC 或 BIC 拟合模型时,可以根据准则的值选择最佳的模型。在模型选择过程中,通常会计算不同模型的 AIC 或 BIC 值,并选择具有最小值的模型。 -
交叉验证是一种评估模型性能的技术,用于估计模型在未知数据上的泛化能力。
在交叉验证中,数据集被分成多个子集(通常称为折),其中一部分用于模型的训练,剩余的部分用于模型的验证。这个过程会多次重复,每次使用不同的子集进行训练和验证,以得到对模型性能的更稳定估计。
交叉验证可以帮助评估模型在未知数据上的表现,并选择最合适的模型。常见的交叉验证方法包括k 折交叉验证和留一交叉验证。
2.1 导入函数
import time
import numpy as np
import pandas as pd
from sklearn.linear_model import LassoLarsIC
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
没下载numpy和pandas的同学在终端下载
pip install numpy
pip install pandas
2.2 导入数据
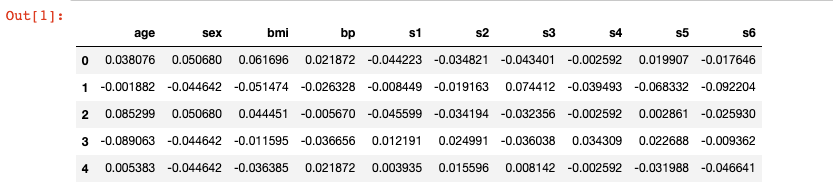
from sklearn.datasets import load_diabetes
X, y = load_diabetes(return_X_y=True, as_frame=True)
X.head()
创建随机特征变量以模拟筛选
rng = np.random.RandomState(42)
n_random_features = 14
X_random = pd.DataFrame(
rng.randn(X.shape[0], n_random_features),
columns=[f"random_{i:02d}" for i in range(n_random_features)],
)
X = pd.concat([X, X_random], axis=1)
X[X.columns[::3]].head()
2.3 拟合模型(AIC/BIC)
使用 LassoLarsIC 来拟合 Lasso 模型,并选择具有最小 AIC 值的模型
start_time = time.time()
lasso_lars_ic = make_pipeline(StandardScaler(), LassoLarsIC(criterion="aic")).fit(X, y)
fit_time = time.time() - start_time
# 保存AIC
results = pd.DataFrame(
{
"alphas": lasso_lars_ic[-1].alphas_,
"AIC criterion": lasso_lars_ic[-1].criterion_,
}
).set_index("alphas")
alpha_aic = lasso_lars_ic[-1].alpha_
以同样标准提取 BIC
lasso_lars_ic.set_params(lassolarsic__criterion="bic").fit(X, y)
results["BIC criterion"] = lasso_lars_ic[-1].criterion_
alpha_bic = lasso_lars_ic[-1].alpha_
整合列表
def highlight_min(x):
x_min = x.min()
return ["font-weight: bold" if v == x_min else "" for v in x]
results.style.apply(highlight_min)

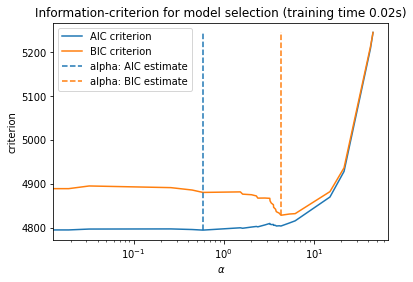
2.4 AIC/BIC可视化
ax = results.plot()
ax.vlines(
alpha_aic,
results["AIC criterion"].min(),
results["AIC criterion"].max(),
label="alpha: AIC estimate",
linestyles="--",
color="tab:blue",
)
ax.vlines(
alpha_bic,
results["BIC criterion"].min(),
results["BIC criterion"].max(),
label="alpha: BIC estimate",
linestyle="--",
color="tab:orange",
)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel("criterion")
ax.set_xscale("log")
ax.legend()
_ = ax.set_title(
f"Information-criterion for model selection (training time {fit_time:.2f}s)"
)
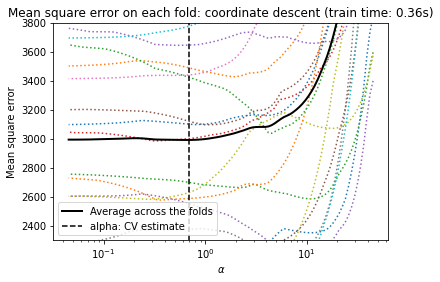
2.5 拟合交叉验证模型及可视化
from sklearn.linear_model import LassoCV
start_time = time.time()
model = make_pipeline(StandardScaler(), LassoCV(cv=20)).fit(X, y)
fit_time = time.time() - start_time
import matplotlib.pyplot as plt
ymin, ymax = 2300, 3800
lasso = model[-1]
plt.semilogx(lasso.alphas_, lasso.mse_path_, linestyle=":")
plt.plot(
lasso.alphas_,
lasso.mse_path_.mean(axis=-1),
color="black",
label="Average across the folds",
linewidth=2,
)
plt.axvline(lasso.alpha_, linestyle="--", color="black", label="alpha: CV estimate")
plt.ylim(ymin, ymax)
plt.xlabel(r"$\alpha$")
plt.ylabel("Mean square error")
plt.legend()
_ = plt.title(
f"Mean square error on each fold: coordinate descent (train time: {fit_time:.2f}s)"
)
3. Hitters数据集实战演示
该数据框架包含 20 个变量和 322 个大联盟球员的观察结果,根据上一年表现相关的各种统计数据用LASSO模型来预测棒球运动员的薪水
3.1 导入函数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso, LassoCV
from sklearn.metrics import mean_squared_error
3.2 导入数据
df = pd.read_csv("Hitters.csv")
df.head()
3.3 数据预处理
print(df.info())
#检查缺失行
print(df.isnull().sum())
# 删除缺失行
df = df.dropna()
# 对分类变量进行One-hot编码
dummies = pd.get_dummies(df[['League', 'Division', 'NewLeague']])
print(dummies.info())
print(dummies.head())
# 显示更新后的数据框
print(df)
print(df.dtypes)
3.4 定义变量和缩放数据
# 删除第一列
df = df.drop(df.columns[0], axis=1)
# 定义变量
y = df['Salary']
X_numerical = df.drop(['Salary', 'League', 'Division', 'NewLeague'], axis=1).astype('float64')
list_numerical = X_numerical.columns
# 创建全部特征
X = pd.concat([X_numerical, dummies[['League_N', 'Division_W', 'NewLeague_N']]], axis=1)
X.info()
# 数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
# 特征缩放
scaler = StandardScaler().fit(X_train[list_numerical])
X_train[list_numerical] = scaler.transform(X_train[list_numerical])
X_test[list_numerical] = scaler.transform(X_test[list_numerical])

3.5 拟合模型
# 模型训练和评估
reg = Lasso(alpha=1)
reg.fit(X_train, y_train)
# 训练集性能
pred_train = reg.predict(X_train)
mse_train = mean_squared_error(y_train, pred_train)
print('训练集MSE:', round(mse_train, 2))
print('训练集R方:', round(reg.score(X_train, y_train) * 100, 2))
# 测试集性能
pred_test = reg.predict(X_test)
mse_test = mean_squared_error(y_test, pred_test)
print('测试集MSE:', round(mse_test, 2))
print('测试集R方:', round(reg.score(X_test, y_test) * 100, 2))
# Lasso系数可视化
alphas = np.linspace(0.01, 500, 100)
lasso = Lasso(max_iter=10000)
coefs = []
for a in alphas:
lasso.set_params(alpha=a)
lasso.fit(X_train, y_train)
coefs.append(lasso.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
plt.axis('tight')
plt.xlabel('alpha')
plt.ylabel('Standardized Coefficients')
plt.title('Lasso coefficients as a function of alpha');
# 训练集MSE: 80571.73
# 训练集R方: 60.43
# 测试集MSE: 134426.33
# 测试集R方: 33.01

3.6 拟合交叉验证模型
这里为了缩短时间,用的五折交叉,一般可以用十折交叉验证
# 使用交叉验证的Lasso模型
model = LassoCV(cv=5, random_state=0, max_iter=10000)
model.fit(X_train, y_train)
lasso_best = Lasso(alpha=model.alpha_)
lasso_best.fit(X_train, y_train)
# 显示特征系数
print(list(zip(lasso_best.coef_, X.columns)))
print('训练集R方:', round(lasso_best.score(X_train, y_train) * 100, 2))
print('测试集R方:', round(lasso_best.score(X_test, y_test) * 100, 2))
# 最佳模型的均方误差
mse_best = mean_squared_error(y_test, lasso_best.predict(X_test))
print('测试集MSE:', round(mse_best, 2))
# 绘制每个折叠上的均方误差
plt.semilogx(model.alphas_, model.mse_path_, ":")
plt.plot(
model.alphas_,
model.mse_path_.mean(axis=-1),
"k",
label="Average across the folds",
linewidth=2,
)
plt.axvline(
model.alpha_, linestyle="--", color="k", label="alpha: CV estimate"
)
plt.legend()
plt.xlabel("alphas")
plt.ylabel("Mean square error")
plt.title("Mean square error on each fold")
plt.axis("tight")
plt.ylim(50000, 250000)

4. 讨论
Lasso回归是一种用于特征选择和稀疏性建模的线性回归方法。它通过加入L1正则化项来推动部分特征的系数稀疏化为零,从而实现对数据中最重要特征的选择和解释。Lasso回归在高维数据集和具有大量特征的情况下,可以提供简洁且解释性强的模型,并有助于减少过拟合问题。埋个预告,下篇整理L2正则化!