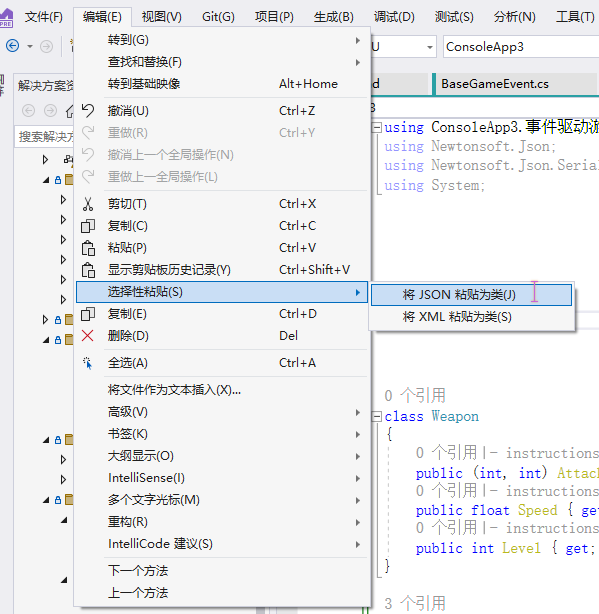
本文为作者内部分享文档,由于不涉敏可以公开,分享本身是课程形式,有什么疑问欢迎在评论区留言。
开场白
人工智能发展到现在,在2个重要领域取得了重大突破,有望达到人类水平:
- 计算机视觉 (Computer Vision, CV)-> 希望机器帮助人类处理图像数据
- 自然语言处理(Natural Language Processing, NLP)-> 希望机器帮助人类处理文本数据
AIGC
- 计算机视觉 (Computer Vision, CV)-> AI作画
- 自然语言处理(Natural Language Processing, NLP)-> 文本生成
自然语言处理在大语言模型(Large Language Model, LLM)被提出之后,再次取得重大突破:
- 以ChatGPT为代表的对话大模型有望重新定义人类使用计算机的方式
- 直接以自然语言让计算机执行任务替代编程语言已具备可能性
- 使用大模型的能力设计开发互联网产品,有望颠覆部分领域产品设计开发模式
- 举个🌰:百度翻译、谷歌翻译
注:
- 关于使用计算机的方式 -> 我们这里讲的是底层的使用方式,应用层来看的话都是通过软件来使用,但软件也是经由编写程序编译之后的产物,归根结底还是通过代码。
- 关于颠覆部分领域 -> 负责任地讲,目前还是有一些领域传统方法效率和结果更好,未来不确定。
接下来我们来从0到1了解一下大语言模型背后的基础知识。
导语
通过本节课程,希望大家能够了解:
- 语言模型的数学基础:概率语言模型 (25分钟)
- 神经网络语言模型的发展历史:即大语言模型是如何发展而来的 (10分钟)
- GPT训练流程:大语言模型是如何训练的 (10分钟)
语言模型 Language Model
根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。
语言模型与语言客观事实之间的关系,如同数学上的抽象直线与具体直线之间的关系。
概率语言模型 Probabilistic Language Model
一说统计语言模型 Statistic Language Model
概率语言模型是一个基于概率的判别式模型,它的输入是一句话即多个单词组成的顺序序列,输出是这句话的概率,即这些单词的联合概率(joint probability)。
compute the probability of a sentence or sequence of words
概率语言模型是一个针对语言进行数学建模的概率模型,它衡量了一句话,也即是多个单词的组成的顺序序列,在语料库(corpus)中实际存在的概率,如果语料库无限大,那么这个概率扩展到这句话实际在自然语言中存在的概率。
注:也可以理解为是也可以理解为它是真实正确的一句话的概率。
I like eating apples. ✅
I prefer coke to soda. ✅
Enjoy basketball playing I. ❌
以上面3个句子为例,前2句是真实句子,在日常生活中可能会被用到,第3句则不是。
N-Gram语言模型
假定一个自然语言句子
W
W
W由
l
l
l个单词组成,记为
w
1
,
w
2
,
.
.
.
,
w
l
w_1,w_2,...,w_l
w1,w2,...,wl,那么:
P
(
W
)
=
P
(
w
1
,
w
2
,
.
.
.
w
l
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
(
w
1
,
w
2
)
)
.
.
.
p
(
w
l
∣
w
1
,
w
2
,
.
.
.
,
w
l
−
1
)
P(W) = P(w_1,w_2,...w_l)=p(w_1)p(w_2|w_1)p(w_3|(w_1,w_2))...p(w_l|w_1,w_2,...,w_{l-1})
P(W)=P(w1,w2,...wl)=p(w1)p(w2∣w1)p(w3∣(w1,w2))...p(wl∣w1,w2,...,wl−1)
条件概率公式:
P ( B ∣ A ) = P ( A B ) / P ( A ) P(B|A) = P(AB)/P(A) P(B∣A)=P(AB)/P(A)
P ( A B ) = P ( A ) ∗ P ( B ∣ A ) P(AB) = P(A)*P(B|A) P(AB)=P(A)∗P(B∣A)
P ( A B C ) = P ( A ) ∗ P ( B ∣ A ) ∗ ∣ P ( C ∣ A B ) P(ABC) = P(A)*P(B|A)*|P(C|AB) P(ABC)=P(A)∗P(B∣A)∗∣P(C∣AB)
这么计算概率有个问题: 0 < p ( w i ) < 1 0<p(w_i)<1 0<p(wi)<1 ,句子越长,参数空间越大,概率越接近0,数据稀疏严重。
引入马尔科夫假设(Markov Assumption),即下一个词的出现仅依赖于它前面的
n
−
1
n-1
n−1个词,我们得到:
p
(
w
i
∣
w
1
,
w
2
,
.
.
.
w
i
−
1
)
=
p
(
w
i
∣
w
i
−
n
,
.
.
.
w
i
−
1
)
p(w_i|w_1,w_2,...w_{i-1})=p(w_i|w_{i-n},...w_{i-1})
p(wi∣w1,w2,...wi−1)=p(wi∣wi−n,...wi−1)
马尔科夫性质:当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。
这里引入马尔科夫假设,认为按从左到右读到的一句话有时间先后的概念,后面的单词仅依赖于它前面的n-1个单词。
n
=
n=
n=表示下一个词的出现不依赖它前面的0个单词,即每个单词条件独立,称为unigram model
P
(
w
1
,
w
2
,
.
.
.
,
w
l
)
=
∏
i
=
1
l
P
(
w
i
)
P(w_1,w_2,...,w_l)=\prod_{i=1}^{l}P(w_i)
P(w1,w2,...,wl)=i=1∏lP(wi)
# English
Questions make difference.
Questions make reality.
Questions begin a quest.
# 中文
我吃苹果。
我吃香蕉。
我喝可乐。
提问:
给定单词“我”,下一个单词是吃的概率是多少?下一个单字是喝的概率是多少?“我吃苹果”整句话的概率是多少?
n
=
2
n=2
n=2表示下一个词的出现只依赖它前面的1个词,称为bigram model
P
(
w
1
,
w
2
,
.
.
.
,
w
l
)
=
∏
i
=
1
l
P
(
w
i
∣
w
i
−
1
)
P(w_1,w_2,...,w_l )=\prod_{i=1}^{l}P(w_i|w_{i-1})
P(w1,w2,...,wl)=i=1∏lP(wi∣wi−1)
n
=
3
n=3
n=3表示下一个词的出现只依赖它前面的2个词,称为trigram model(常用)
P
(
w
1
,
w
2
,
.
.
.
,
w
l
)
=
∏
i
=
1
l
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
P(w_1,w_2,...,w_l )=\prod_{i=1}^{l}P(w_i|w_{i-2}w_{i-1})
P(w1,w2,...,wl)=i=1∏lP(wi∣wi−2wi−1)
以此类推,我们的得到了给定
n
n
n词,输出下一个词概率的语言模型:
P
(
W
)
=
∏
i
=
1
l
p
(
w
i
∣
w
i
−
n
+
1
i
−
1
)
P(W)=\prod_{i=1}^{l}p(w_i|w_{i-n+1}^{i-1})
P(W)=i=1∏lp(wi∣wi−n+1i−1),其中
w
i
j
w_i^j
wij表示单词序列
w
i
,
w
2
,
.
.
.
,
w
j
w_i,w_2,...,w_j
wi,w2,...,wj
构建语言模型可以使用最大似然估计(Maximum Likelihood Estimate)生成每一个条件概率,以unigram为例即:
p
(
w
i
∣
w
i
−
1
)
=
c
o
u
n
t
(
w
i
−
1
,
w
i
)
/
c
o
u
n
t
(
w
i
−
1
)
p(w_i|w_{i-1})=count(w_{i-1},w_i)/count(w_{i-1})
p(wi∣wi−1)=count(wi−1,wi)/count(wi−1)
计算概率语言模型公式的每一个组成元素,再将所有组成元素连乘,即得整个句子的概率。
提问(非常重要):
给定
n
n
n个词,为语料库里面的所有单词依次计算概率,选概率最大的那个单词,作为n+1个单词输出,想想我们在做什么?
给定n+1个单词,求第n+2个单词,…,我们在做文本生成,这就是语言模型最朴素的原理。
这种用法下,我们将n-gram模型作为生成式模型使用。
N-gram语言模型实际效果并不好,能解决的实际问题非常有限,因而自然语言处理在概率语言模型阶段没有产生太大影响力。
神经网络语言模型 (NNLM)
随着深度学习的出现和崛起,我们有了一个强有力的工具:人工神经网络。
神经网络语言模型即使用神经网络来进行语言建模,我们将给定的n个单词作为输入,预测第n+1个单词作为输出,那么可以使用监督学习的方式通过标记数据集让神经网络学习到输入和输出之间的映射关系。
NNLM
NNLM, Neural Network Language Model
A Neural Probabilistic Language Model (2000, 2003)
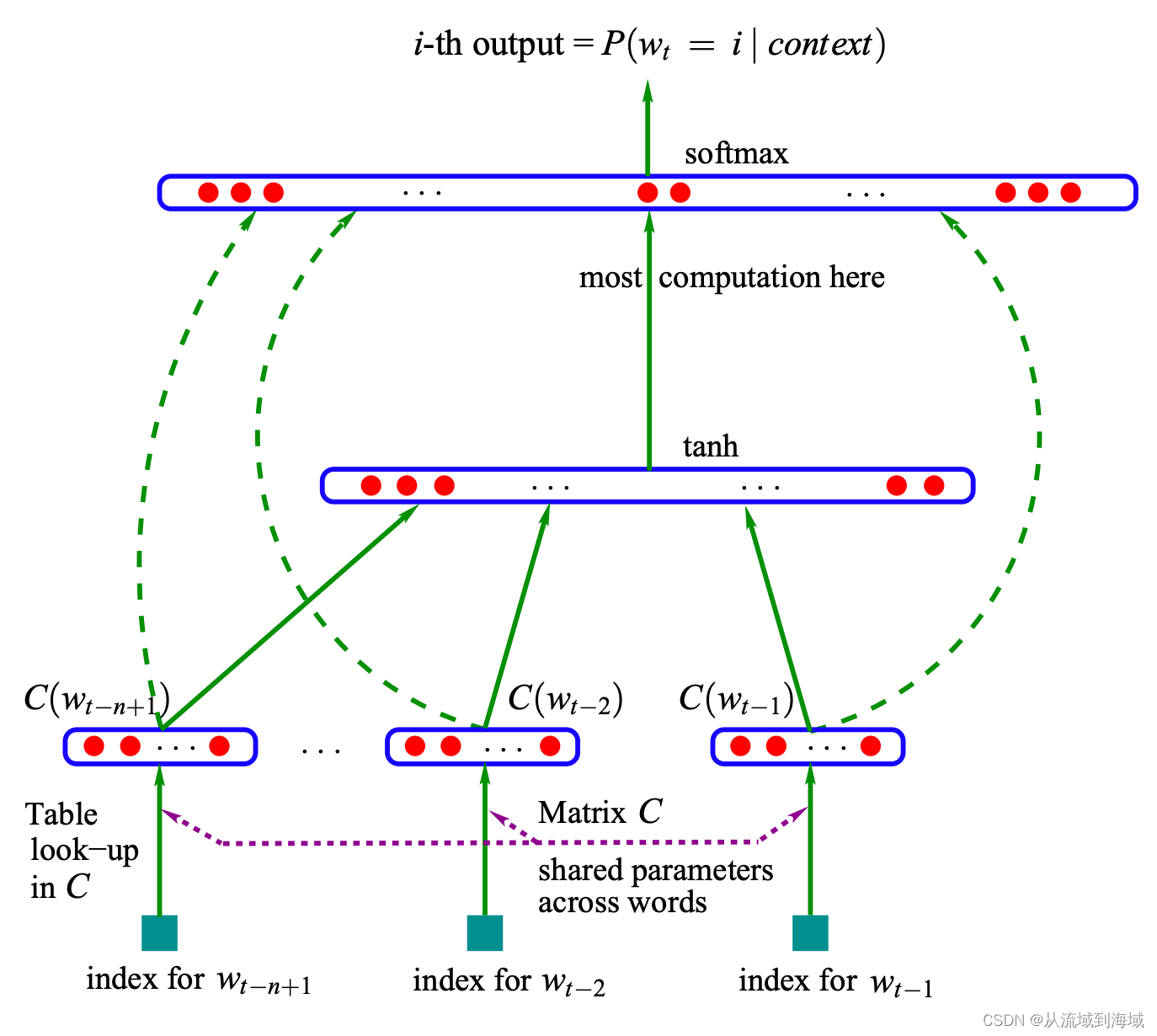
使用一个简单的神经网络来替代概率模型,模型的训练目标定义为给定 n n n个单词作为上下文,预测下一个单词是上下文中的第 i i i个单词,输入层 C C C表示一个共享的矩阵参数,随机初始化, C i C_i Ci表示语料库中第 i i i个单词的特征向量。
提问(非常重要):
输入层的矩阵
C
C
C是什么?
答案:词向量
Word2Vec
Efficient Estimation of Word Representations in Vector Space(2013)
训练神经网络语言模型过程中,将神经网络的权重值作为词向量来使用
现在我们讲的词向量,其实是训练语言模型过程中的副产品
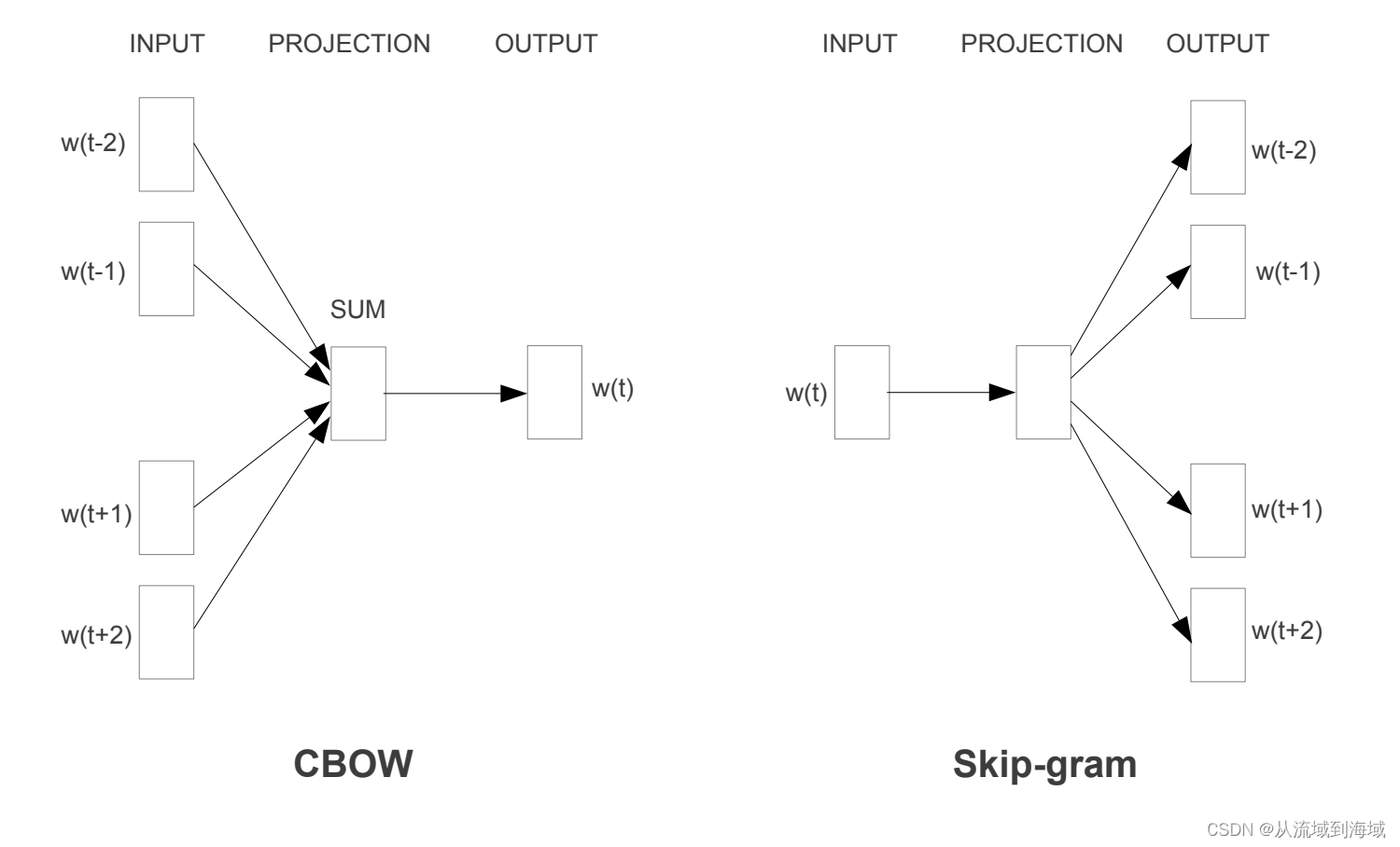
| 项目 | Value |
|---|---|
| CBOW (Continuous Bag-of-Words Model) | Skip-gram |
| CBOW 的基本思想为以上下文作为输入,预测中间词。具体而言,设定一个上下文范围 N,输入为中间词的前 N 个单词和后 N 个单词,输出为中间词的概率分布,训练目标是真实中间词的概率最大(即argmax),也即1次分类过程。 | Skip-gram基本思想为以中间单词作为输入,预测上下文。具体而言,设定一个上下文范围 N,输入为中间词,输出为前 N 个单词和后 N 个单词的概率分布,训练目标是2N次概率输出,每次使得真实上下文词的概率最大(即2N次argmax),也即2N次分类过程。训练过程的参数规模非常巨大,有Hierarchical Softmax、Negative Sampling等方式降低计算复杂度,这里不再展开。 |
神经网络语言模型架构演进
上个小节介绍的NNLM和Word2Vec是一个DNN架构的神经网络语言模型,随着神经网络架构的演进,神经网络语言模型的架构也在不断演进:
大规模语言模型 Large Language Model (LLM
PaLM、LLaMA、GPT 3.5、GPT 4
大规模语言模型(Large Language Model, LLM),即参数规模非常大的神经网络语言模型,由神经网络语言模型随网络架构经长时间发展迭代而来,特点是参数规模达到一定量级(千万~亿)之后,出现了涌现能力,使得模型在各项NLP任务中取得重大突破,接近人类水平。
涌现能力一句话介绍就是模型参数达到一定量级(亿),能力突飞猛进,更多详情,可以参见:
LLM的涌现能力和Scaling
Emergent Abilities of Large Language Models
Scaling Laws for Neural Language Models
神经网络语言模型发展史
nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet)
大模型时代之前 ->2019
预训练模型
NLP范式:Pre-training + fintuning 即预训练 + 下游任务精调
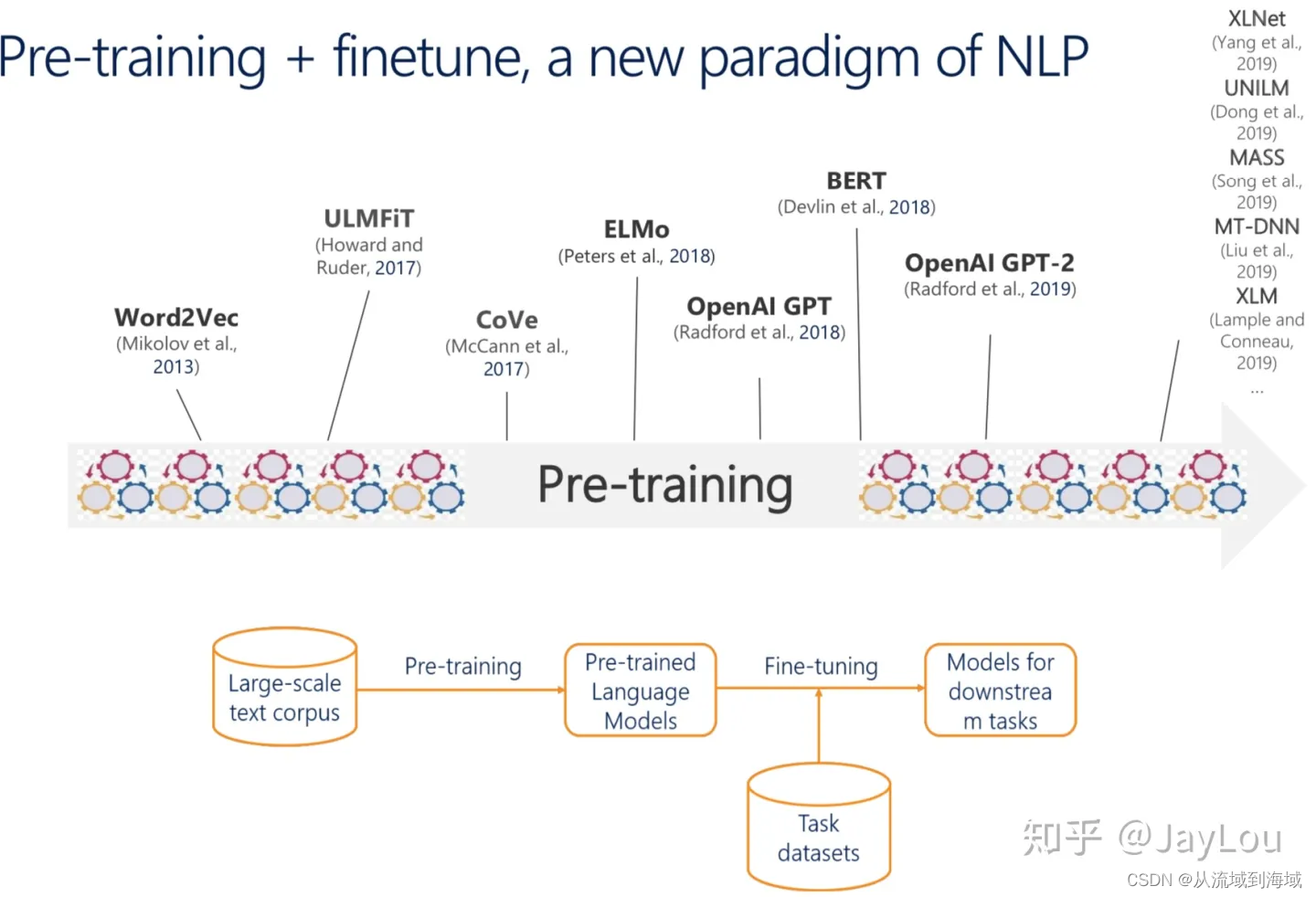
- Pre-training -> 训练通用语言模型 (相当于训练模型认识自然语言)
- Fine-tuning -> 训练下游NLP任务(相当于训练模型执行任务)
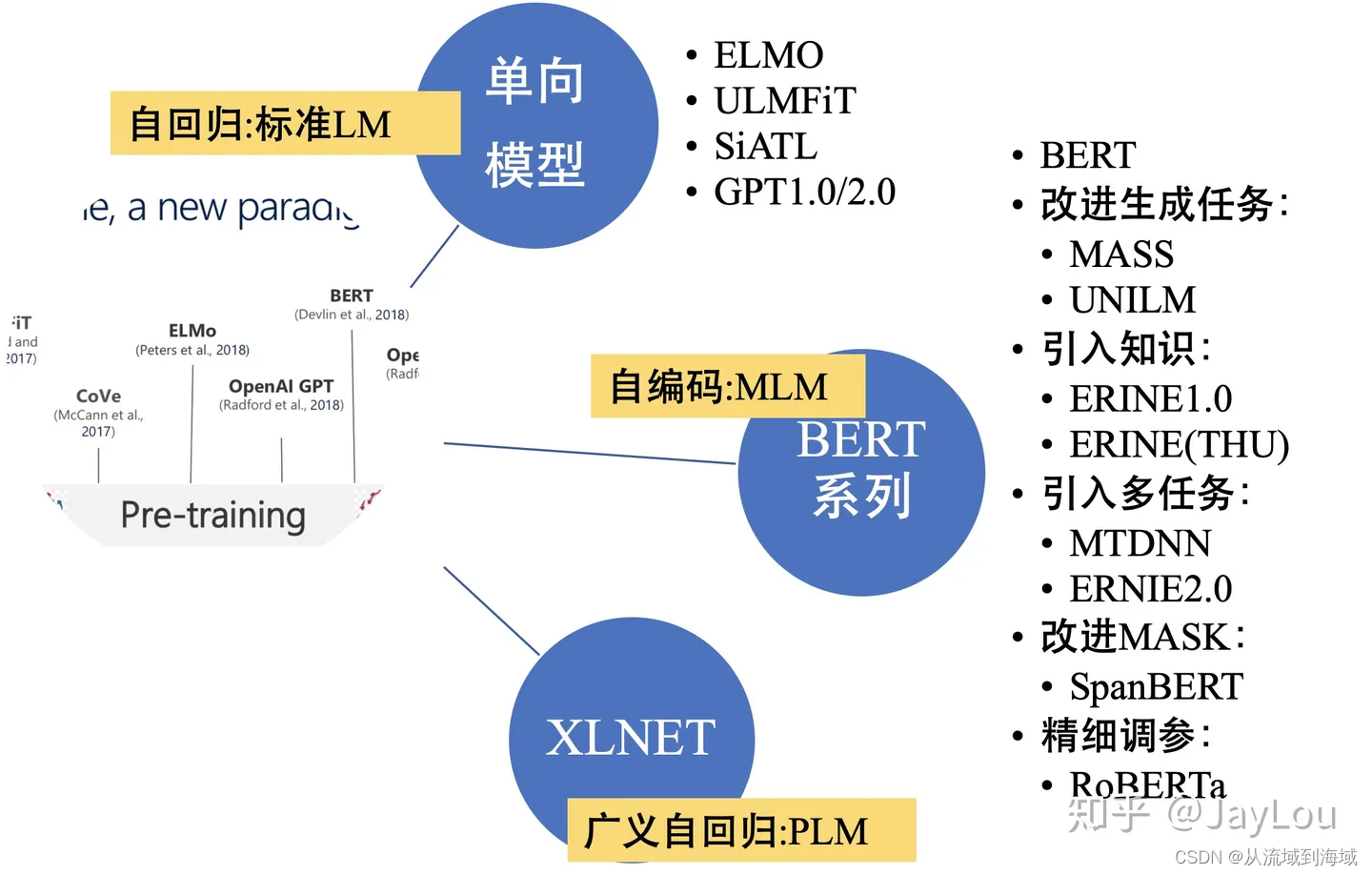
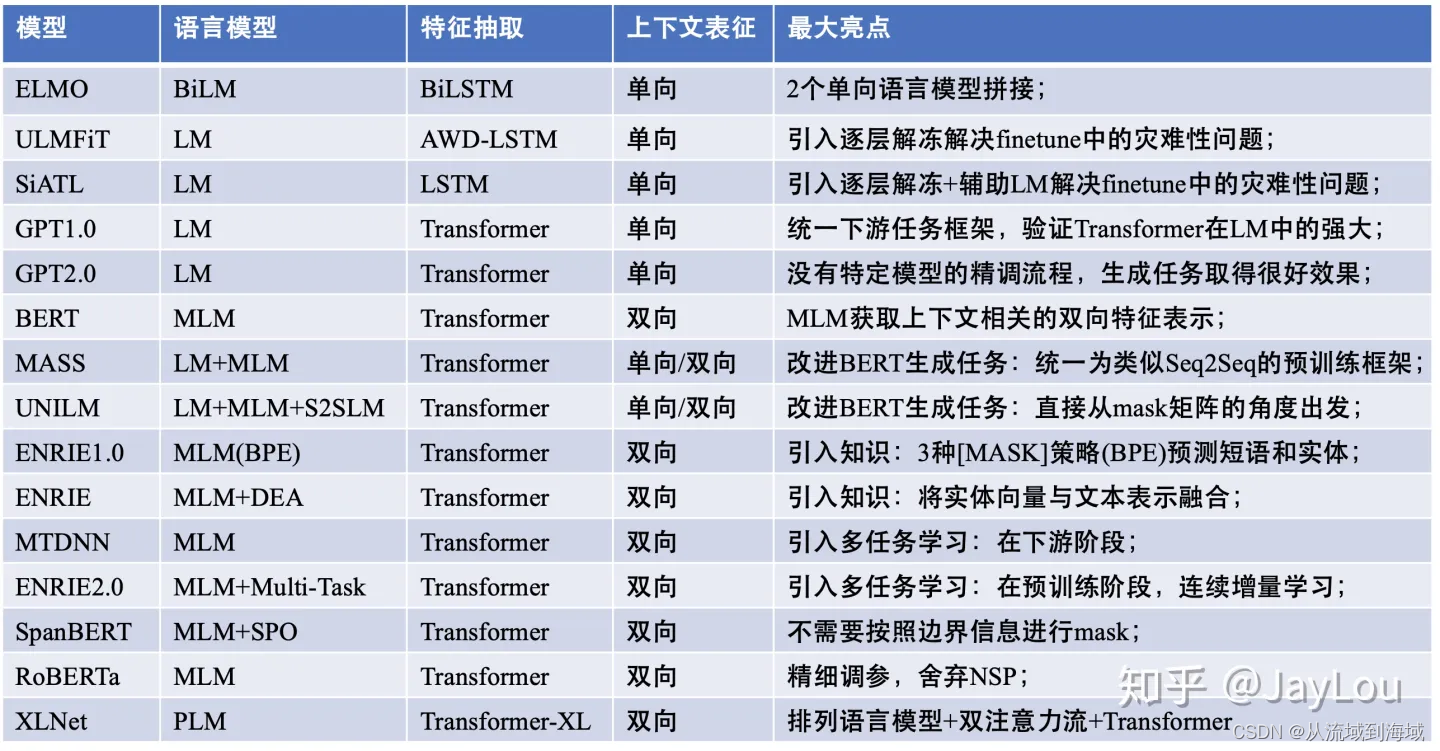
大模型时代 2019->
Pre-training + instruction fintuning + RLHF 即 预训练+指令精调+RLHF
下一节的GPT训练流程部分有详细描述
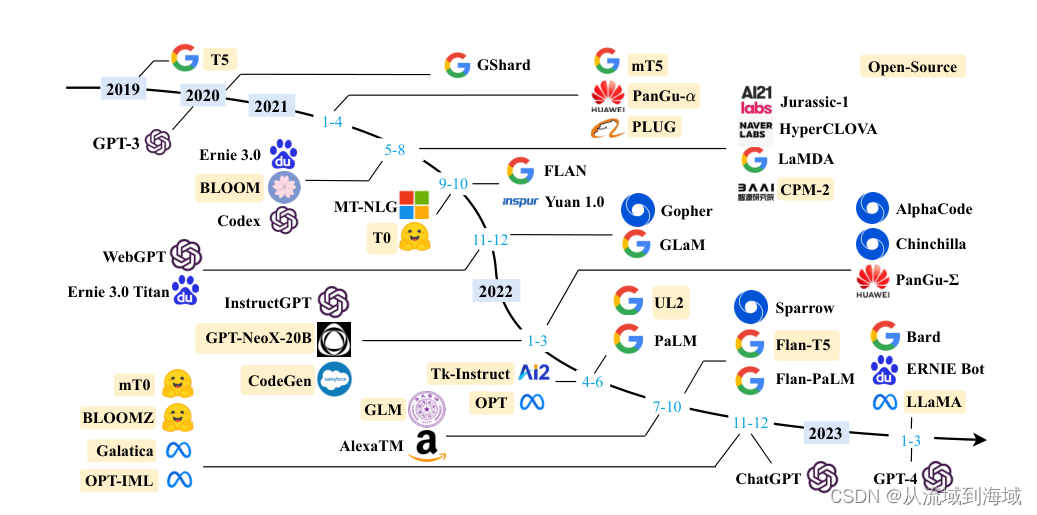
PaLM: https://arxiv.org/pdf/2204.02311
LLaMA: https://arxiv.org/pdf/2302.13971
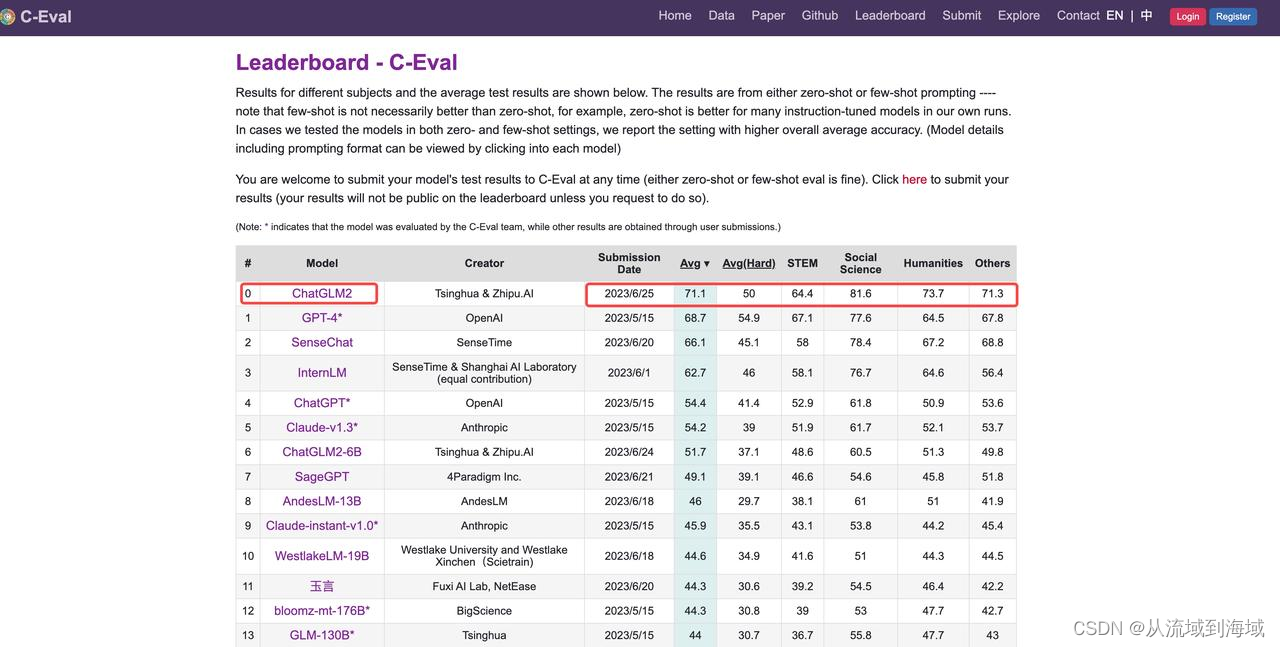
清华提出了ChatGLM系列,并开源了其中的ChatGLM-6B和ChatGLM2-6B,在C-Eval上测试是目前最好的中文大模型:
https://cevalbenchmark.com/static/leaderboard.html
GPT发展史
如果我们单看GPT的话
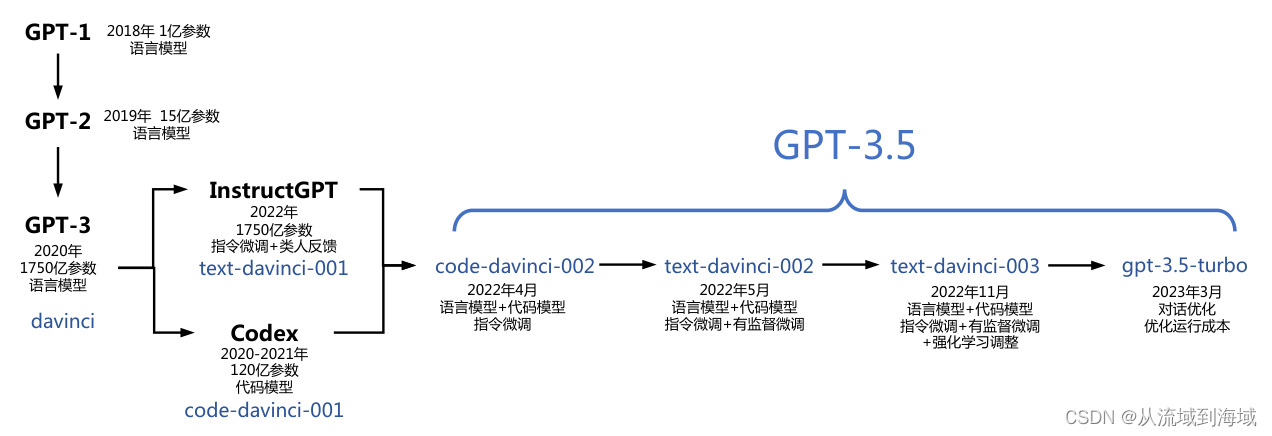 GPT-1: Improving Language Understanding by Generative Pre-Training
GPT-1: Improving Language Understanding by Generative Pre-Training
GPT-2: Language Models are Unsupervised Multitask Learners
GPT-3: Language Models are Few-Shot Learners
ChatGPT训练流程
图源:State of GPT - Microsoft Build

笔者翻译上图如下:
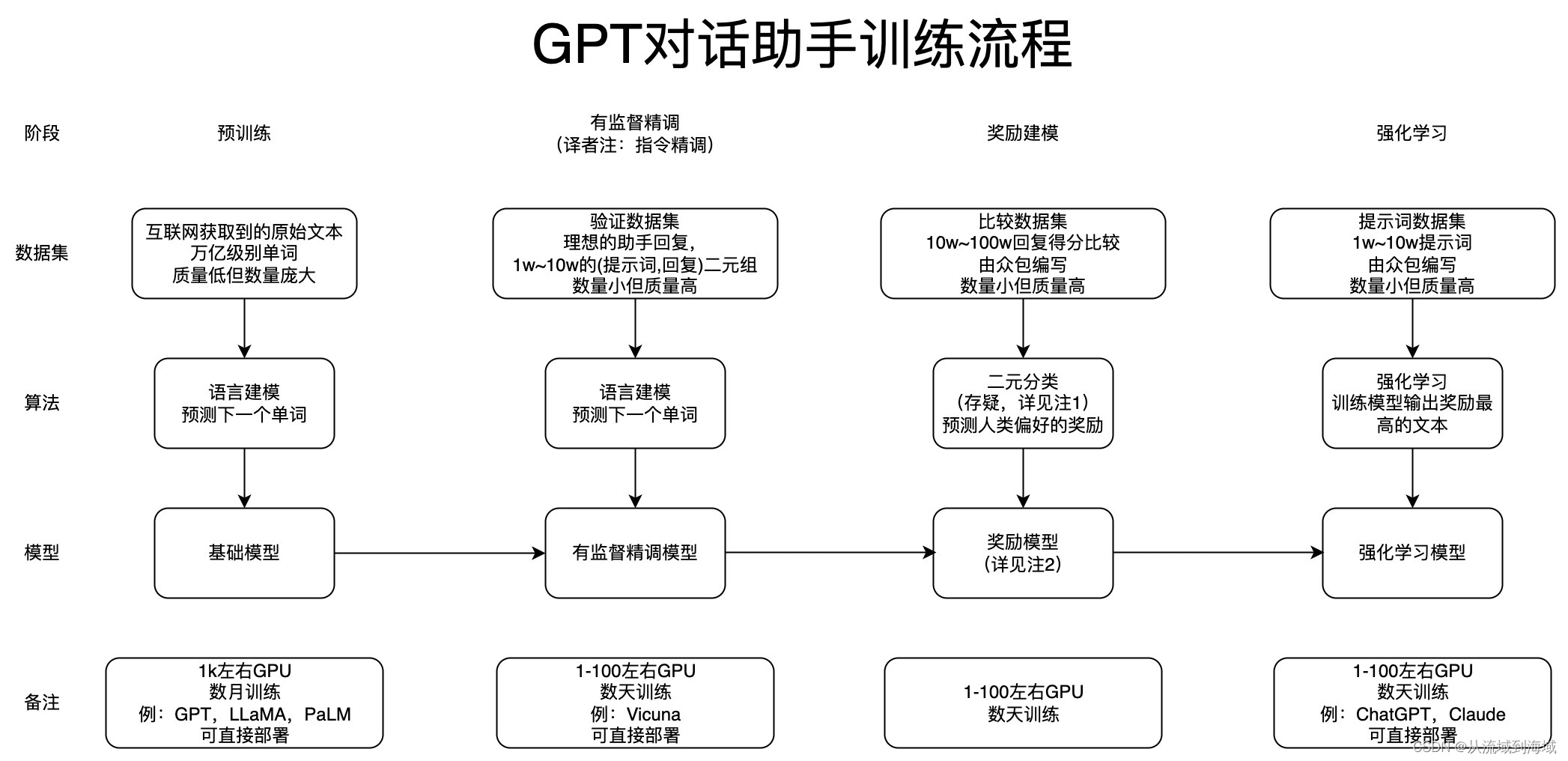
| 阶段 | 子阶段 | 目标 | 备注 |
|---|---|---|---|
| Pre-Training | -------- | 语言建模 | |
| Instruction Finetuning | --------- | 让模型能够理解自然语言指令 | |
| RLHF | Reward Modeling | 奖励建模,用来代替人工打分,降低标注成本 | 奖励模型是用来建模强化学习的一个组件 |
| RLHF | Reinforcement Learning | 强化学习建模,通过强化学习的方式训练模型输出奖励最大的文本,即更符合人类偏好的文本 |
强化学习建模过程如下:
- 将指令精调后的大语言模型作为Agent,agent的action即给定输入文本 i i i进入 S t a t e State State S i S_i Si后的文本 O u t p u t i Output_i Outputi。
- 所有可能输入的文本构成了agent的状态空间
- 所有可能输出的文本构成了agent的动作空间
- 将奖励模型作为Environment对模型输出进行打分,将分数作为奖励。
注:
3. 二元分类说法并不准确,原始目标是希望对两个生成的回复进行打分即两者之间按更符合人类预期进行比较,胜出的回复应该得到更多的分数,亦即获得更大的奖励。或者也可以认为是在两者之间做分类,将更符合人类预期的筛选出来,但前者是更加准确的描述。
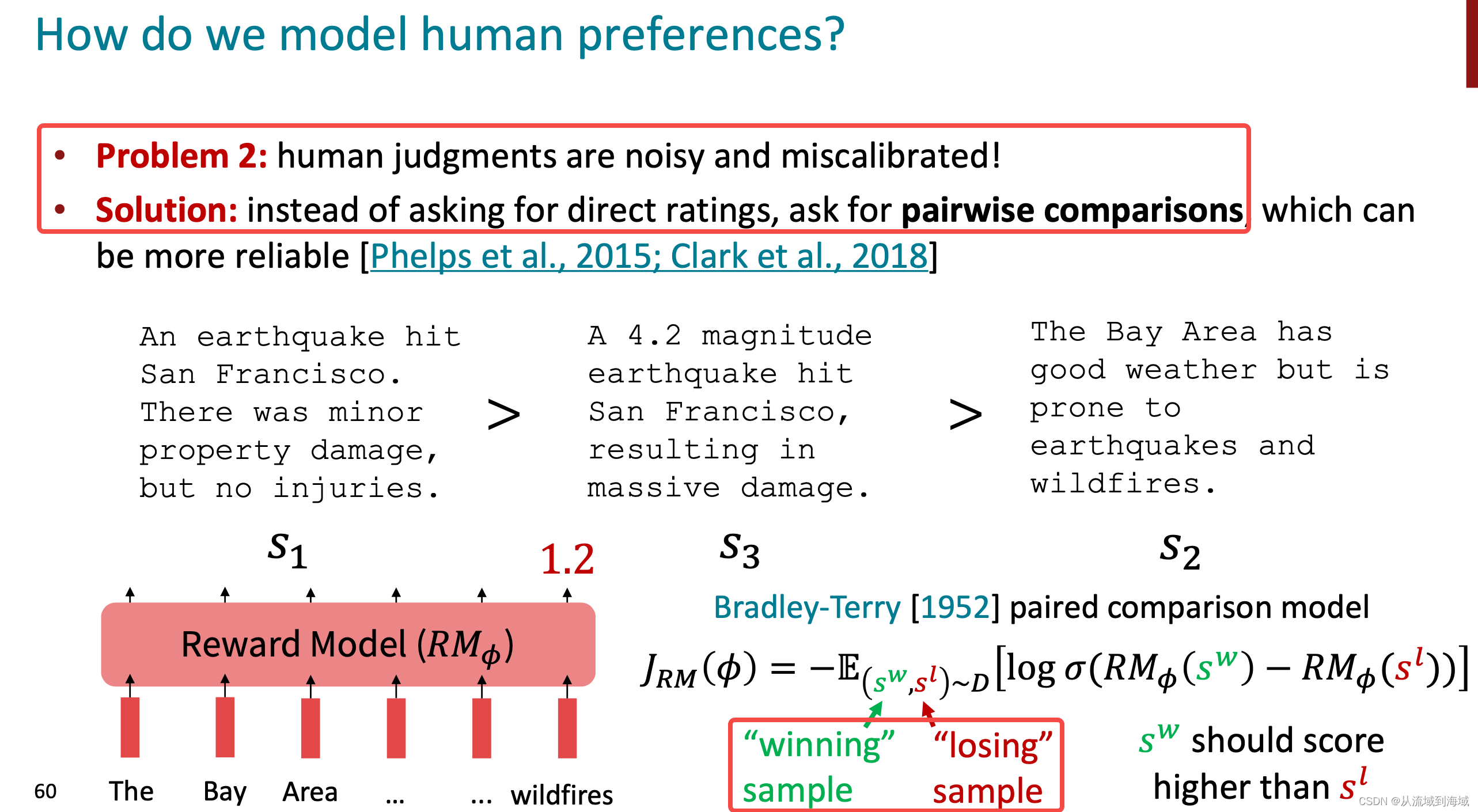
图源:cs224n-2023-lecture11-prompting-rlhf.pdf
- 奖励模型是用来实现强化学习的一个辅助模型,可以理解为强化学习建模中的环境(Environment)**
Key Takeaway
- 概率语言模型设计用于计算一个句话在自然语言中出现的概率
n-gram语言模型是概率语言模型基于条件独立假设的简化,给定n个单词,它可以用来预测第n+1单词 - 语言建模(即训练语言模型的过程):给定n个单词,预测第n+1个单词是什么。神经网络语言模型使用神经网络进行语言建模。
- 神经网络语言模型随着自然语言处理领域不断提出新的网络架构逐步演进,transformer是其中一个标志性里程碑。基于transformer,Google和Open AI分别提出了BERT和GPT 1.0/2.0,开启了自然语言处理pretraining + fintuning(预训练语言模型)的时代,模型参数到达亿级别,大语言模型的雏形出现。
- 随着神经网络语言模型的参数量继续增大到一个千亿级别,开始表现出强大的涌现能力,辅以instruction fituning和RLHF的(大语言模型)训练流程改进,突破性的大语言模型ChatGPT出现,大模型时代来临。