题目
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
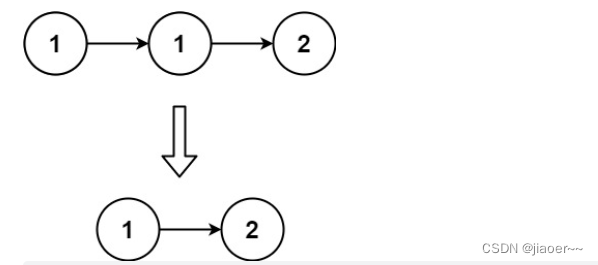
输入:head = [1,1,2]
输出:[1,2]
示例 2:
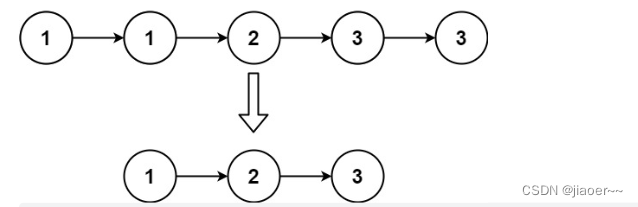
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围 [0, 300] 内
- -100 <= Node.val <= 100
- 题目数据保证链表已经按升序 排列
解题思路
1.设置一个虚拟头节点 dummy,令 dummy.next 指向链表的头节点 head,
2.设置一个 cur 节点令它指向 dummy,再设置一个 var 节点令它指向 head,
3.用 cur 节点和 var 节点对链表进行遍历,结束条件是 var 指向 null,如果 cur 节点的值等于var 节点的值,我们就令 cur 节点的 next 节点为 var 节点的 next 节点,也就是删除 var 节点,令 var 节点向后走一步,而 cur 节点不动(注意这里:如果 cur 节点也向下走一步,我们很有可能会漏删相同的节点),直接进行下一次循环,再次进行判断,若 cur 节点不等于 var 节点则两个节点都向后走一步。直到 while 循环结束,返回 dummy.next 即可。
代码实现
class Solution {
public ListNode deleteDuplicates(ListNode head) {
ListNode dummy = new ListNode(101);
dummy.next = head;
ListNode cur = dummy;
ListNode var = head;
while(var != null){
if(cur.val == var.val){
cur.next = var.next;
}else{
cur = cur.next;
}
var = var.next;
}
return dummy.next;
}
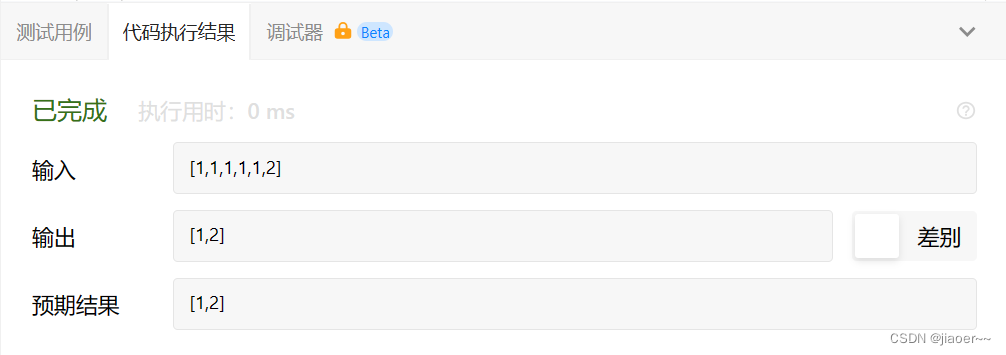
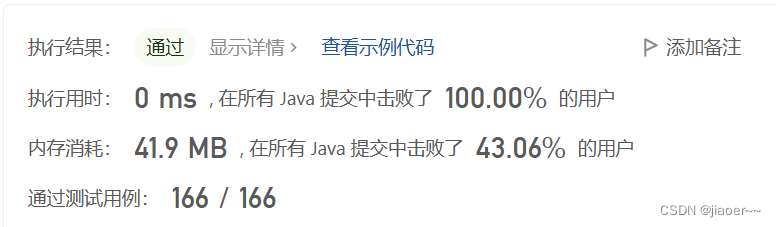
}测试结果


![[linux] ebtables技术](https://img-blog.csdnimg.cn/8bbc59162f49470992a07f40290c7f11.png)