准备数据
将数据格式调整为以下格式:
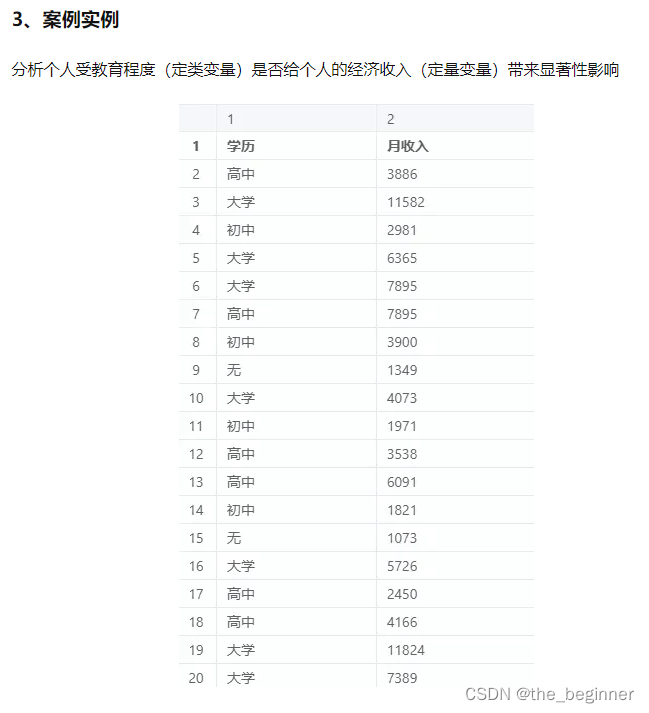
jupyter处理过程
#读取数据
import numpy as np
import pandas as pd
# 创建一个空的DataFrame
t1 = pd.DataFrame()
t2 = pd.DataFrame()
t3 = pd.DataFrame()
T1=pd.read_excel('./数据/抑郁_T1.xlsx')
T1.columns=T1.iloc[0]
T1=T1.drop(T1.index[0])
T1.head(2)
t1['姓名']=T1['姓名:']
t1['抑郁总分']=T1['抑郁总分']
t1.columns=['姓名','T1']
t1.head()
T2=pd.read_excel('./数据/抑郁_T2.xlsx')
T2.columns=T2.iloc[0]
T2=T2.drop(T2.index[0])
T2.head(2)
t2['姓名']=T2['您的姓名:']
t2['抑郁总分']=T2['抑郁总分']
t2.columns=['姓名','T4']
t2.head()
T3=pd.read_excel('./数据/抑郁_T3.xlsx')
T3.columns=T3.iloc[0]
T3=T3.drop(T3.index[0])
T3.head(2)
t3['姓名']=T3['姓名:']
t3['抑郁总分']=T3['抑郁总分']
t3.columns=['姓名','T3']
t3.head()
import pandas as pd
# 假设t1、t2、t3是要拼接的DataFrame
# t1
t11= pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 35]})
# t2
t21 = pd.DataFrame({'姓名': ['赵六', '钱七'],
'年龄': [40, 45]})
# t3
t31 = pd.DataFrame({'姓名': ['孙八'],
'年龄': [50]})
# 使用pd.concat()函数拼接DataFrame
concatenated = pd.concat([t11, t21, t31])
# 打印拼接后的DataFrame
print(concatenated)
# 使用pd.merge()函数合并DataFrame
merged = pd.merge(t1, t2, on='姓名')
merged = pd.merge(merged, t3, on='姓名')
merged.columns=['姓名','T1','T4','T5']
merged
import pandas as pd
# 创建原始数据的DataFrame
df = pd.DataFrame(data)
# 使用melt函数将数据转换为指定的格式
melted = pd.melt(df, var_name='阶段', value_name='总分')
# 打印转换后的DataFrame
print(melted)
处理后的数据:
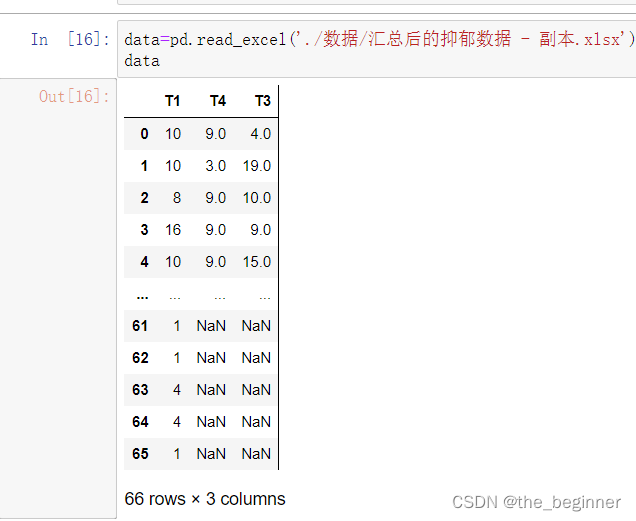
删除空值
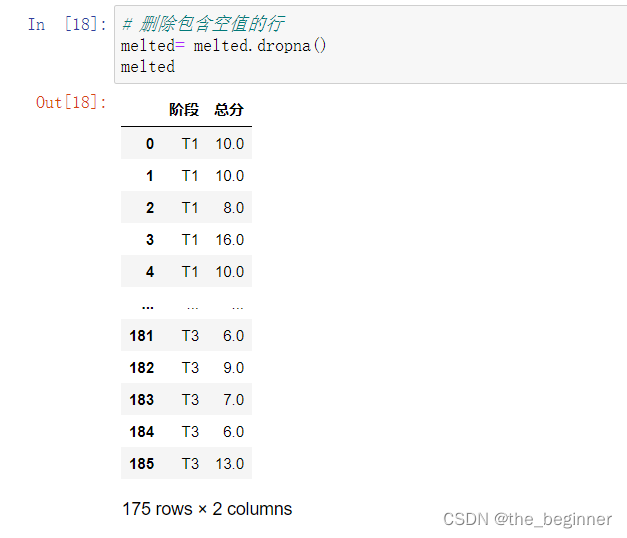
# 删除包含空值的行
df = df.dropna()
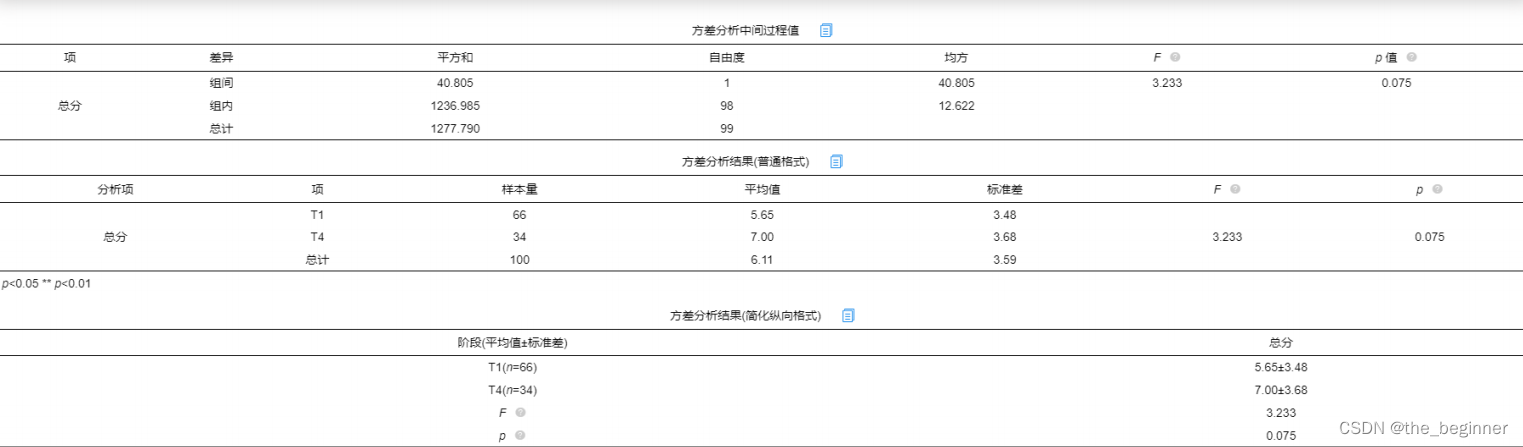
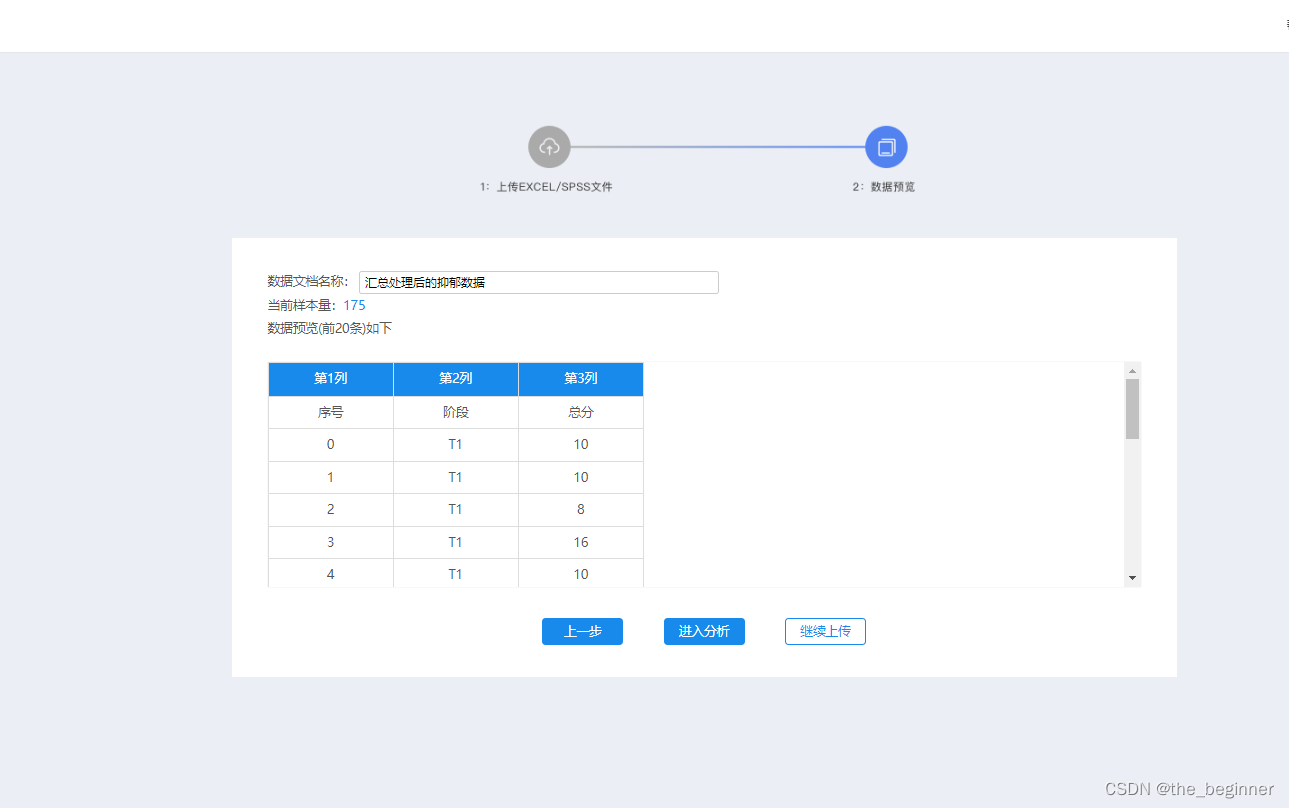
使用SPSSAU进行方差分析
上传数据
选择数据
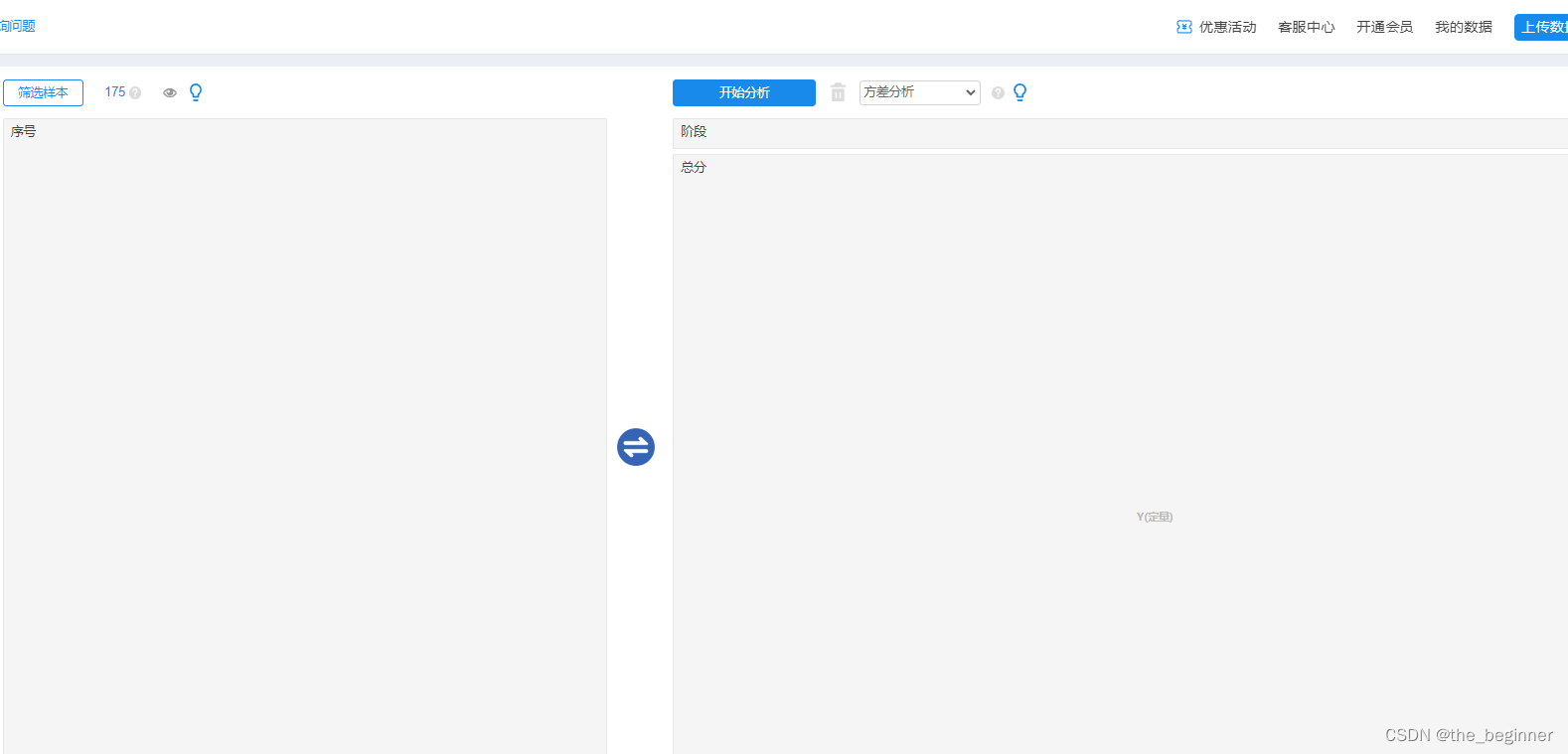
重要提示:没开会员只能分析前100行数据!!!!!!!!!
前100行数据分析结果

其他