Python爬虫:利用JS逆向抓取携程网景点评论区图片的下载链接
- 1. 前言
- 2. 实现过程
- 3. 运行结果
1. 前言
文章内容可能存在版权问题,为此,小编不提供相关实现代码,只是从js逆向说一说到底怎样实现这个的过程,希望能够帮助到那些正在做js逆向相关操作的读者,需要代码的读者单独私信我吧!不过,需要注意的是:代码仅供学习,不能用于商业活动,望读者切记。。
2. 实现过程
说到js逆向,那么表明要抓取的数据不是来自一个静态页面,也就是说用requests访问这个页面,你得不到你想要的那些数据,那么,怎样得到那些数据呢?找相关链接接口,这通常涉及到ajax技术。因为有的接口上一些相关请求参数你是无法理解到其中的意义,所以需要通过js逆向,明白这些请求参数具体意义(当然有的也无法理解,但是可以明白的是这个参数值是怎样组成或者可以从哪里找到)。
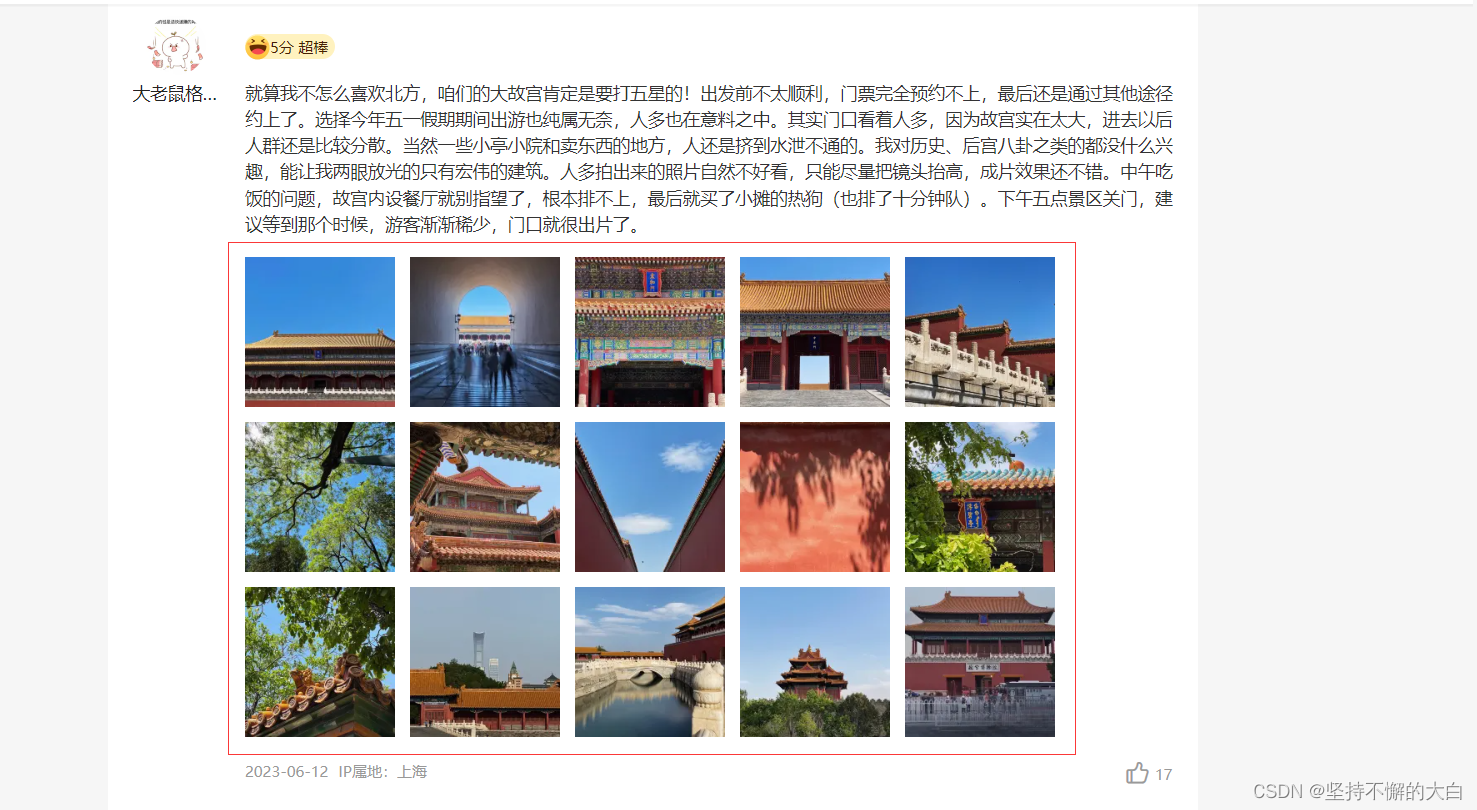
既然是获取评论区的图片下载链接,当然也可以得到评论的相关数据,这些数据都来自这个接口,如下:
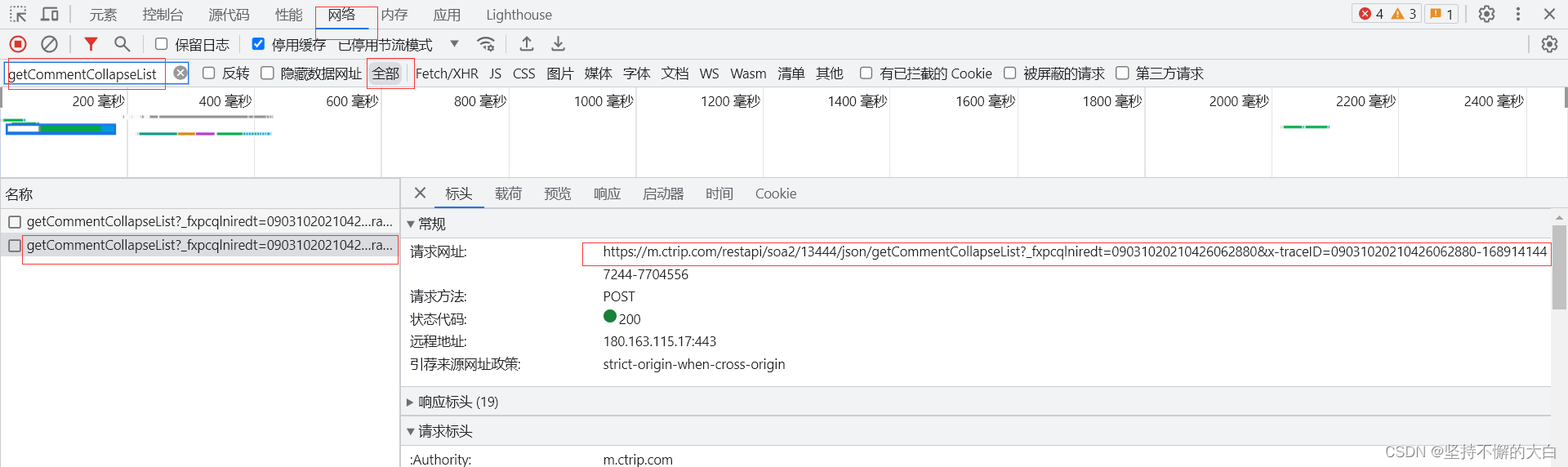
请求参数为:
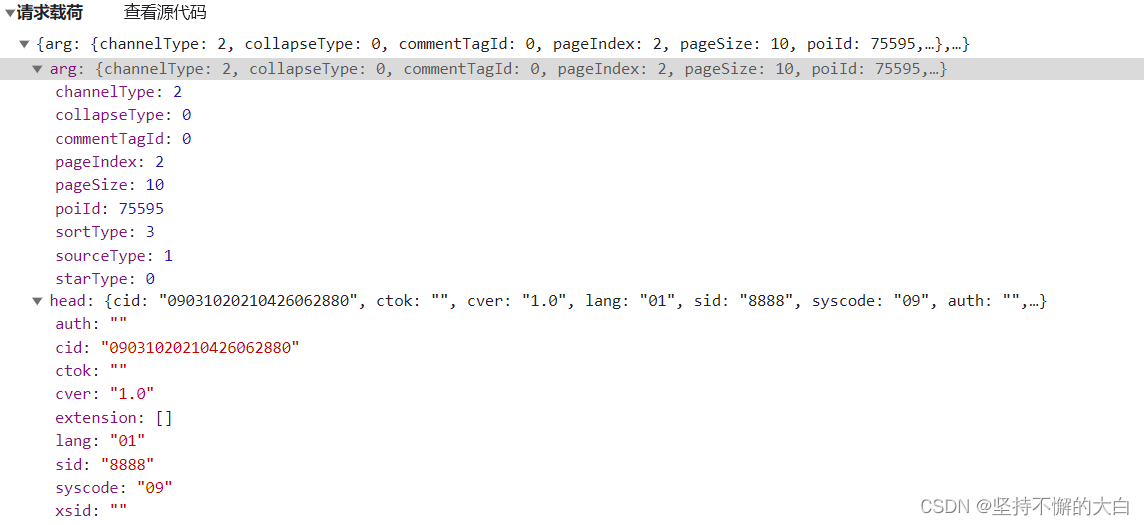
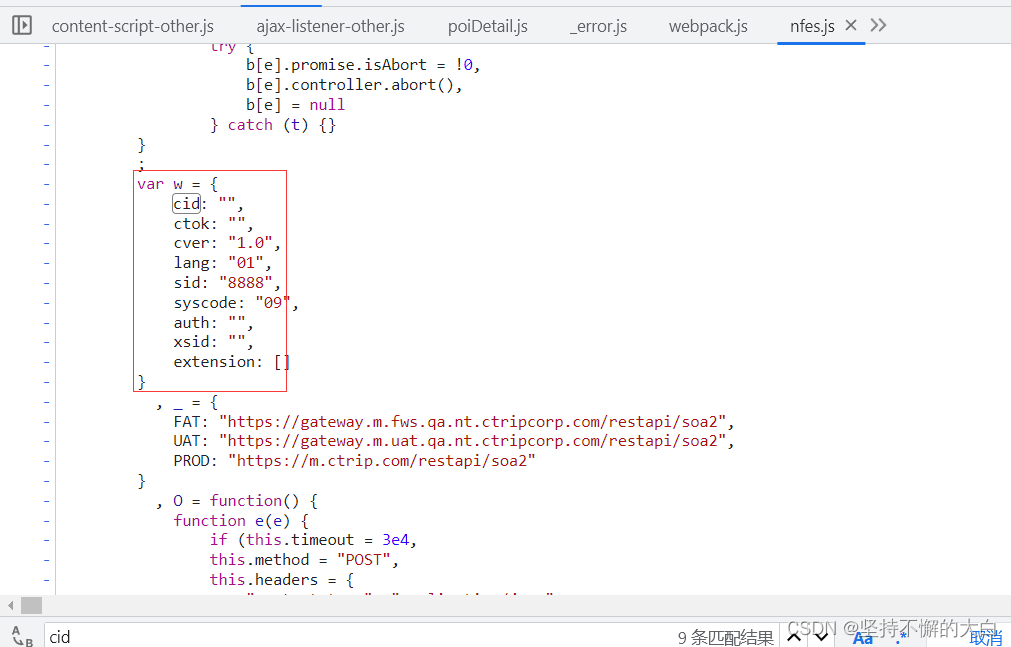
可以看到请求参数中有两个键,分别为arg和head,通过这个接口后的启动器,找到相关js代码实现的过程,可以发现这个键head对应的字典的中键对应的值除了cid之外,其他的均为固定值,而cid值也可以说是固定的吧!(它这个值来自cookie中相关键的值,如下:)
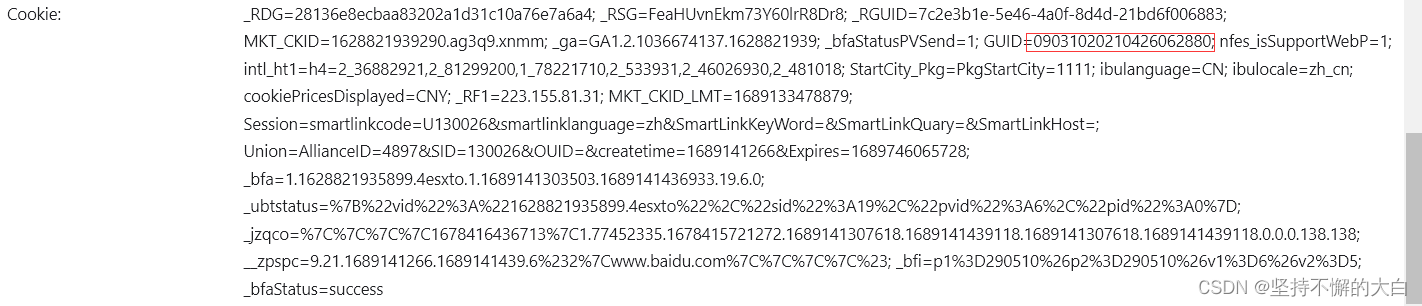
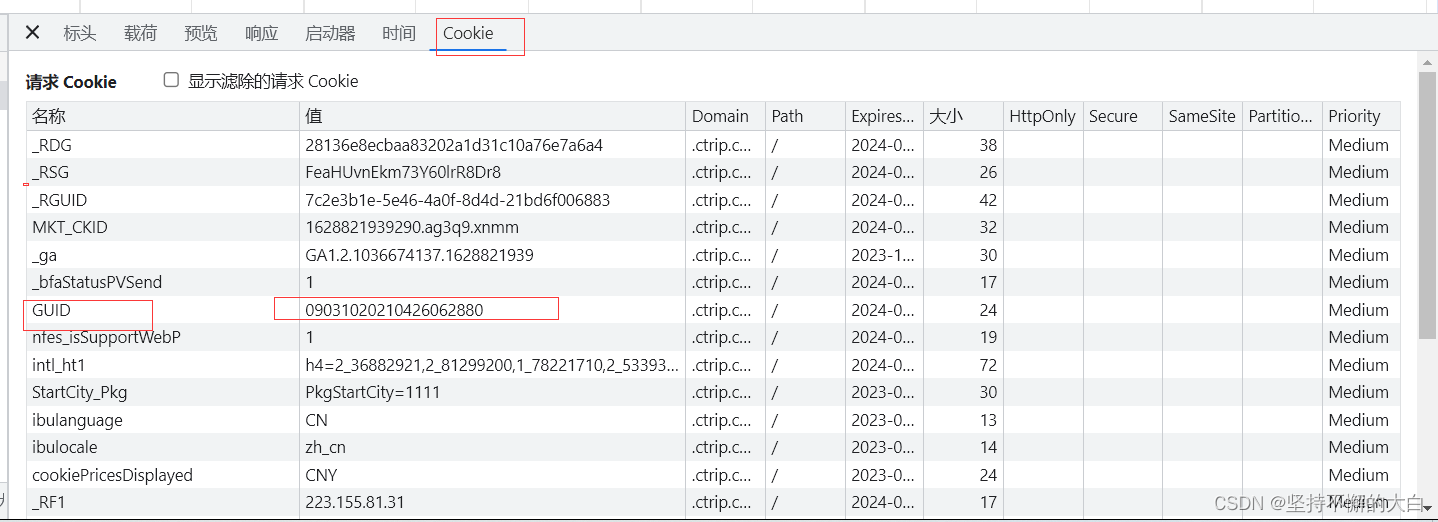
至于arg这个字典里的键值,pageIndex值是和页数相匹配的;pageSize是每页的数量,;sortType为排序方式,有两种吧!一种是时间排序,另外一种为智能排序,默认情况下为智能排序;poiId应该是景点的id编号(这个值可以通过当前界面的script内部一个json数据中得到)。其他可以说基本上是固定的吧!如下:
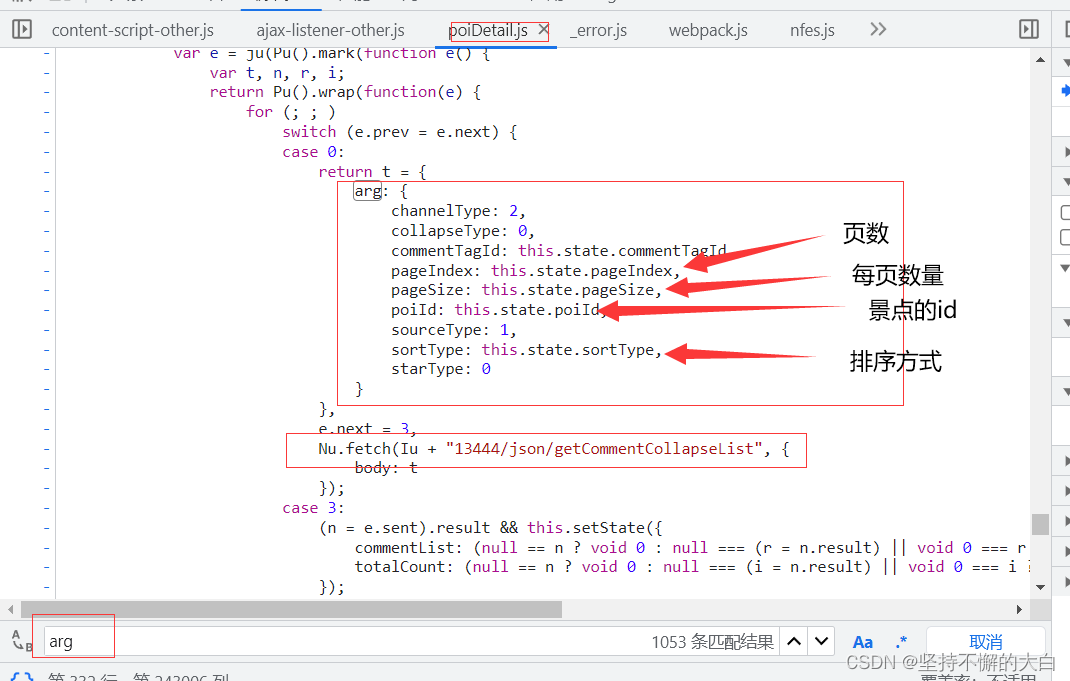
poiId来自这个script标签下的json数据里边哈!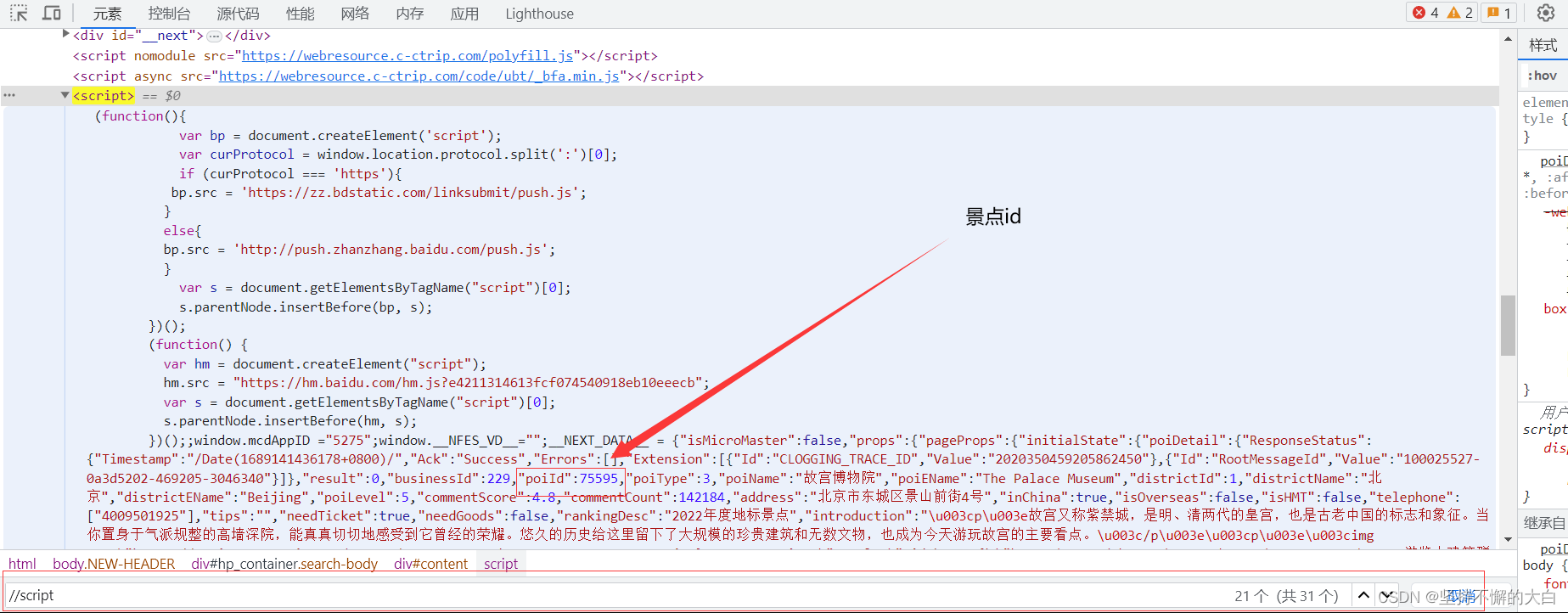 这个commentTagId参数值应该是指这个吧!(不一定对哈!)
这个commentTagId参数值应该是指这个吧!(不一定对哈!)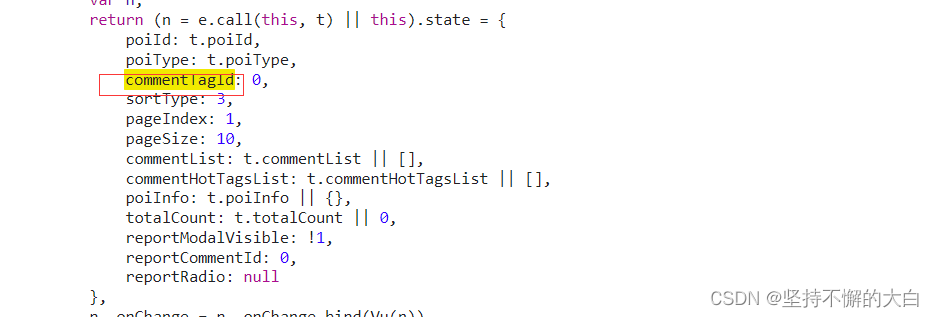
至于
https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031020210426062880&x-traceID=09031020210426062880-1689141447244-7704556
问号后面的参数,可以从这一段js代码中明白其组成原理,如下:
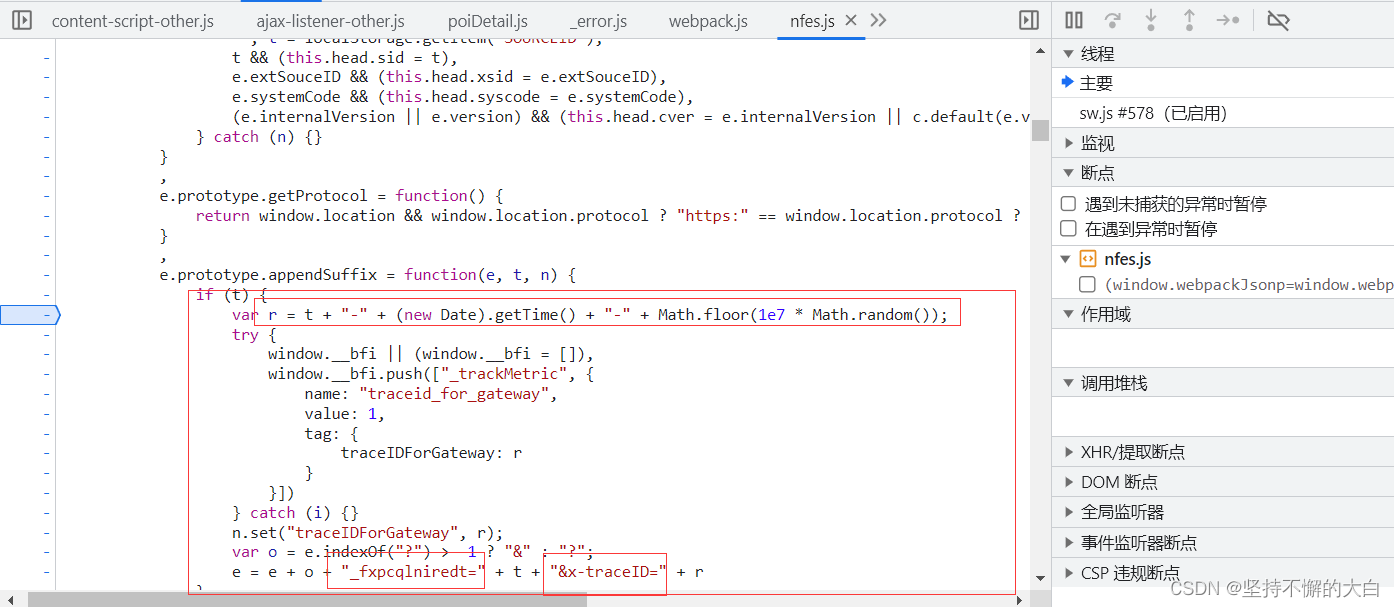
通过和上述图片中相关数据比较,读者应该可以发现图片中js代码中的t就是09031020210426062880,也就是cookie中那个键guid的值。
3. 运行结果
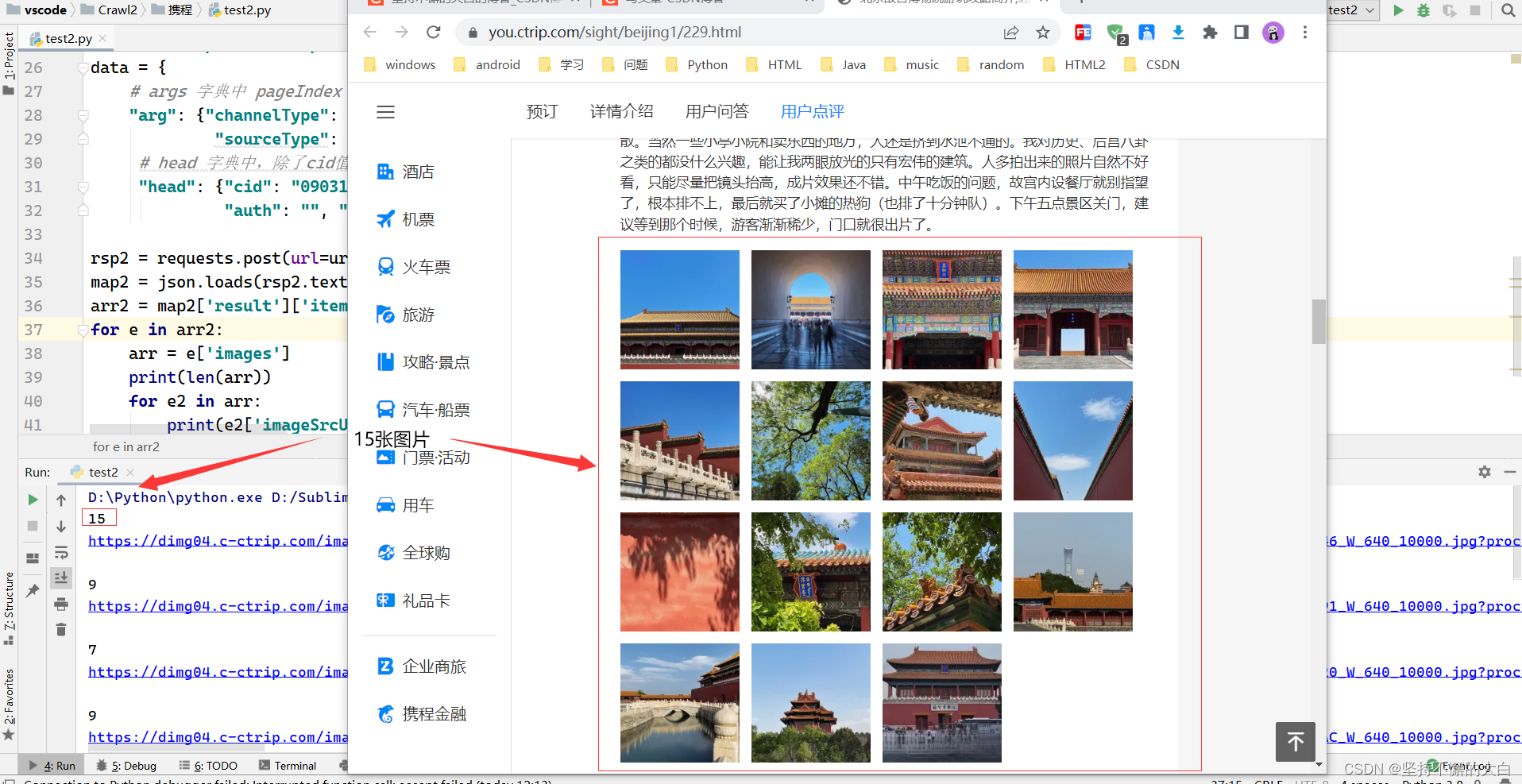
第1页的数据
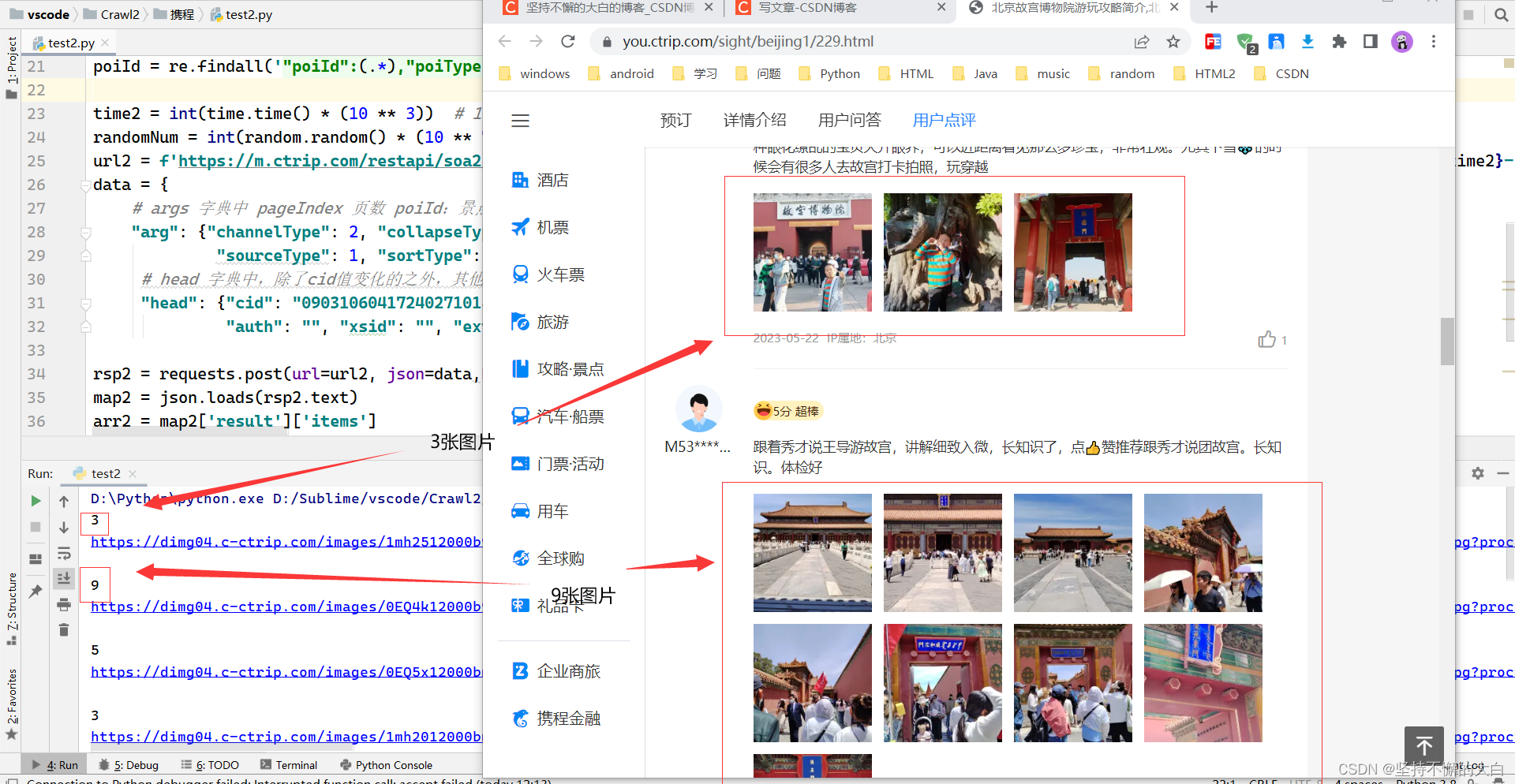
第2页的数据
小编我也不知道能不能发表成功!所以在上述过程中,一些js逆向操作并没有说的很详细,希望读者理解。