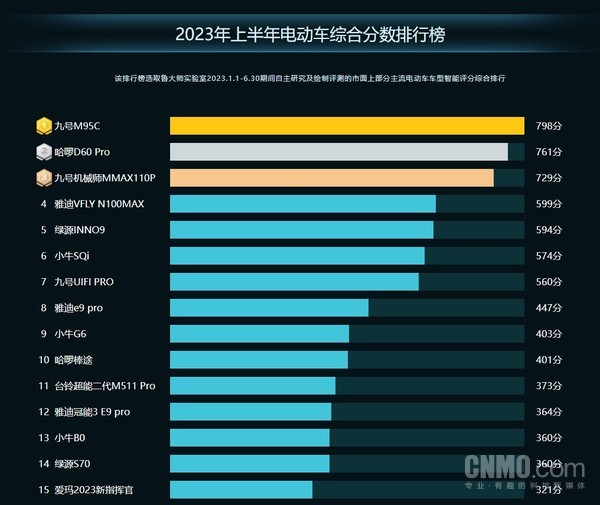
文章目录
- 视觉算法知识荟萃
- 视觉算法八股
- 手写卷积
- Delta K
- Abs Rel
- RMSE
- Silog
- VNL
- SoftMax
- CrossEntropy
- Swin-Transformer
- Transformer
- Adam,SGD
- 如何修改SGD,使其不陷入局部最小值
- NMS
- SoftNMS
- 边缘检测算法
- Sobel
- Laplacian
- Canny
- Pooling Layer
- 手写 Pooling Layer
- Pooling Layer 传播方式
- 可分离卷积
- BN 层的作用,BN 层有多少参数
- 过拟合
- 欠拟合
- 训练出现NaN
- 目标检测
- 两阶段检测模型
- R-CNN
- Fast R-CNN
- Faster R-CNN
- Unsniffer
- 单阶段检测模型
- YOLO
- SSD (Single Shot multibox Detector)
- 运动控制
- PID
- KCF
- 单目深度估计
- SM4Depth
- SimMIM 预训练
- PST
- Bin-based Depth Estimation
- Depth Distribution 如何计算
- 训练集
- 轻量级单目深度估计
- CVPR 2022 WorkShop
- DANet
- 双目深度估计
- 视差转深度的公式推导
- TFLite 配置流程
视觉算法知识荟萃
视觉算法八股
手写卷积
Delta K
Abs Rel
RMSE
Silog
VNL
SoftMax
CrossEntropy
Swin-Transformer
Transformer
Adam,SGD
如何修改SGD,使其不陷入局部最小值
NMS
SoftNMS
边缘检测算法
Sobel
Laplacian
Canny
Pooling Layer
手写 Pooling Layer
Pooling Layer 传播方式
可分离卷积
BN 层的作用,BN 层有多少参数
beta和gamma都是C维的向量,所以是2C
过拟合
过拟合是指训练误差和测试误差之间的差距太大。模型在训练集上表现很好,但在测试集上却表现很差,也就是泛化能力差。引起的原因有 ①训练数据集样本单一,样本不足 ②训练数据中噪声干扰过大 ③模型过于复杂。防止过拟合的几种方法:
- 增加更多的训练集或者数据增强(根本上解决问题)
- 采用更简单点的模型(奥卡姆剃刀准则,简单的就是正确的)
- 正则化(L1,L2),p范数: ∣ ∣ x ∣ ∣ p = ( ∣ x 1 ∣ p + ∣ x 2 ∣ p + … + ∣ x n ∣ p ) 1 / p ||x||_p = (|x_1|^p+|x_2|^p+…+|x_n|^p)^{1/p} ∣∣x∣∣p=(∣x1∣p+∣x2∣p+…+∣xn∣p)1/p,在最后的 loss 函数中加一个正则项,将模型的权重 W 作为参数传入范数中,为的就是防止模型参数过大,这样可以防止过拟合发生。
- 可以减少不必要的特征或使用较少的特征组合
欠拟合
欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。防止欠拟合的几种方法:
- 采用更大的模型
- 采用更强的特征
训练出现NaN
目标检测
两阶段检测模型
使用相应的Region Proposal算法从输入图片中生成建议目标候选区域,将所有的候选区域送入分类器进行分类。
R-CNN
contribution:
1.使用CNN进行基于区域的定位和物体分割
2.监督训练样本数紧缺时,在额外的输入上需训练的模型经过fine-tuning可以获得很好的效果。
Pipeline:
1.基于图片提出若干Region Proposal,文中使用的是Selective Serach算法。该算法将图片划分为多个patch,每个patch之间计算颜色相似性,纹理相似性,相近的patch进行合并。
2.训练N个SVM分类器来判断框是否属于这个类别,SVM是二分类的,输出True表示属于这个类别,输出False表示不属于这个类别
3.使用NMS去除相交的多余的框。NMS中会对每个类别的框分别进行类内的NMS,在这一类中,首先挑选置信度最大的框,然后把这个框和与这个框IoU过大的框都从候选框中删除,重复上一过程直到没有候选框。最后把置信度小于一定阈值的框删除,得到最后的结果。
4.最后预测框的偏移量,对这些框进行回归修正。
Fast R-CNN
将基础网络在图片整体上运行(共享了大部分计算)后,再传入R-CNN子网络。
Faster R-CNN
提出了RPN网络使得目标检测任务端到端地完成。RPN中使用多个anchor提出目标框。
Unsniffer
1.使用GOC得分抑制包围过大的框,部分包围的框,提升全包围的框
2.使用ncut对簇内进行NMS挑选框
3.使用负能量抑制对非物体的框进行抑制
单阶段检测模型
YOLO
网络首先输出 SSchannel 的特征图,其中SS表示输出SS个网格。在此之后每个网格会预测B个框,每个框带有4个坐标值和1个置信度得分,再加上大小为C的类别信息,网络最后的输出为SS(5*B+C)
更快,但是性能不如2-stage的方法。使用全图的信息,把背景错认为物体的情况较少。泛化能力强
SSD (Single Shot multibox Detector)
YOLO是对每个patch进行检测,容易造成漏检测,并且对物体的尺度比较敏感。
改进:
1.使用多尺度的feature map,将vggnet多个尺度的特征值输入回归器中提升了对小物体的检测效率。
2.采用了更多的achor box,并且基于box对物体的类别进行了预测。
选择原因:
1.计算平台:
树莓派缺少GPU,因此首选tflite,而非GPU下的tensorRT,手机端的ncnn。tflite官方推荐的有ssd,yolov5,efficientnetv3,efficientnetv2
2.检测性能:
相同图片下,efficientnetv2无法检测到苹果,yolov5给出的框和置信度不高,ssd和efficientnetv3给出的框较好,且置信度较高。
距离较远的情况下,ssd(输入尺寸小)和efficientnetv3检测能力下降,yolo能勉强框住物体。
3.运行速度:
模型大小ssd,efficientnetv3,yolo为:1:2:3
FPS为:11:7:1
运动控制
PID
比例积分微分控制,p代表相应时间,i代表累计误差,d代表稳定性
KCF
将图像通过滤波器处理,把图像和滤波器的输出通过傅里叶变换,计算相应图,将相应图逆傅里叶变换到空域得到最大响应值的位置,作为目标估计的当前位置
单目深度估计
SM4Depth
SimMIM 预训练
PST
Bin-based Depth Estimation
Depth Distribution 如何计算
训练集
轻量级单目深度估计
CVPR 2022 WorkShop
- TCL
- 类似于UNet的结构,将输入图片下采样到原图的1/4,然后传递给MobileNetV3
- 删除了MobileNetV3的最后一层,来提升网络的速度
- Encoder的输出被送到CLB中,最后x10缩放到原始的大小
- 使用silog作为损失函数
- HIT
- 多种Loss:silog,gradient,vnl
- 知识蒸馏
- 数据增强
- 设计合适的特征融合模块
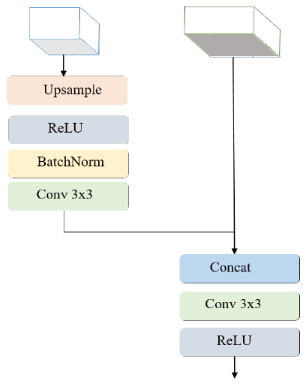 或者
或者
DANet
- EfficientNetb0
- 可分离卷积
- 降低深度分类个数
- 深度图直接x2作为最后输出
双目深度估计
视差转深度的公式推导
TFLite 配置流程
- 安装 TFLite 虚拟环境
- 安装 TFLite 解释器和下载 TFLite 模型