前言:目前我在做一个callback函数,需要将数据重复的读取、写入,再供使用,并且数据量比较大,所以需要使用一个读写速度快的存储方式,不太考虑占用的磁盘空间
直接看结果
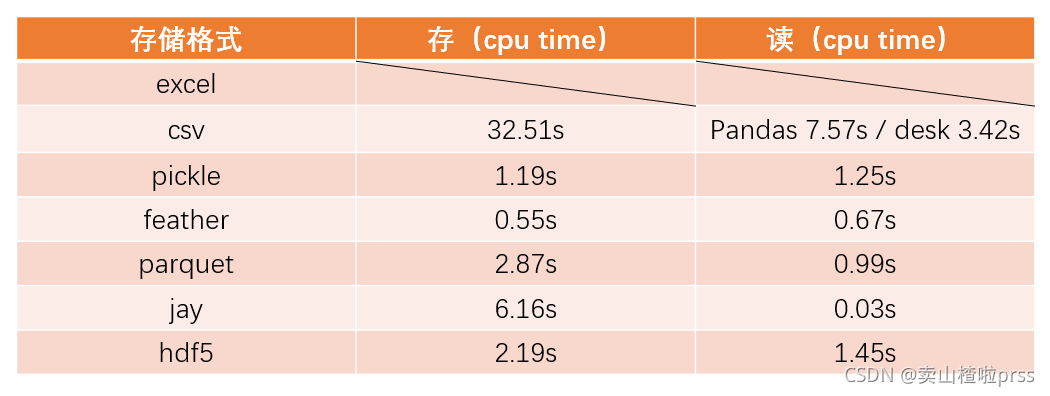
-
csv的文件存储,在读取的时候是最为消耗时间的;如果数据大的话不建议存储为csv形式;
-
jay文件是读取最快的(相较于其他的快了极市上百倍),比csv则快了千万倍;
-
feather在存储速度上是最快的,读取速度也还可以,适用于比较均衡的场景
存储类型:
feather,parquet:有数据冗余排除算法,可节省大量空间,根据数据类型可压缩数千倍(feather可以显著提高了数据集的读取速度、在Hadoop生态系统中,parquet被广泛用作表格数据集的主要文件格式,Parquet使Hadoop生态系统中的任何项目都可以使用压缩的、高效的列数据表示的优势。现在parquet与Spark一起广泛使用。这些年来,它变得更容易获得和更有效,也得到了pandas的支持。)
hdf,SQL: 支持SQL索引(hdf5设计用于快速I/O处理和存储,它是一个高性能的数据管理套件,可以用于存储、管理和处理大型复杂数据。)
csv:纯字符串存储(csv格式是使用最多的一个存储格式,但是其存储和读取的速度会略慢。)
pkl:python object 直接存储到文件(pickle模块实现二进制协议,用于序列化和反序列化Python对象结构。Python对象可以以pickle文件的形式存储,pandas可以直接读取pickle文件。pickle模块不安全。最好只unpickle你信任的数据。)
jay:Datatable使用.jay(二进制)格式,这使得读取数据集的速度非常快。
读取方式:
jay读取(jay文件是读取最快的)
安装 datatable 包
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com datatable存
import datatable as dt
t0=time.time()
t1=time.perf_counter()
dt.Frame(data).to_jay("data.jay")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 6.169269200000599
wall time: 6.168536901473999
'''
读
t0=time.time()
t1=time.perf_counter()
data_jay = dt.fread("./data.jay")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.03480849999959901
wall time: 0.034420013427734375
'''
data_jay.shape
feather读取(feather在存储速度上是最快的)
存
import time
t0=time.time()
t1= time.perf_counter()
data.to_feather("data.feather")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.5462657999996736
wall time: 0.5466225147247314
'''
读
t0=time.time()
t1=time.perf_counter()
data_feather = pd.read_feather("./data.feather")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.6685380999997506
wall time: 0.6682815551757812
'''
hdf5读取
parquet读取
pickle读取
直接看:pkl文件是什么?pickle.dump,pickle.load、为什么使用pkl文件、pickle_pkl.dump_HealthScience的博客-CSDN博客
Python Dataframe之excel、csv、pickle、feather、parquet、jay、hdf5 文件存储格式==》存读效率对比_卖山楂啦prss的博客-CSDN博客
pandas 各种存储格式速度对比[CSV, hdf5,SQL,pickle, feather, parquet] - 知乎
【Python】大数据存储技巧,快出csv文件10000倍!-腾讯云开发者社区-腾讯云