前言
1.PaddleSpeech 是一个简单易用的all-in-one 的语音工具箱,支持语音处理的相关操作,如语音知别,语音合成,声纹识别,声音分类,语音翻译,语音唤醒等多个方向的应用开发。
这里只使用到语音合成与声音克隆,主要由文本前端(Text Frontend) 、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块,模块工作流程如下:
- 通过文本前端模块将原始文本转换为字符/音素。
- 通过声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。
- 通过声码器将声学特征转换为波形。
2.要完成整个项目,大致可以分以下几个步骤:
- 语音数据收集,处理。
- 语音合成与克隆模型微调。
- 模型离线应用部署。
数据集制作
1.如果想训练自己的声音,可以使用录音设备录制自己的声音,发声中英都可以,录制的环境尽量没有杂音,录制时长越多越好。
2.如果使用网络上的声音数据,那么视频与音频都可以。
3.我这里演示使用的是B站上的一个UP主的语音,我剪切大概10段5分钟以上的视频,因为视频的声音带着背景音乐,为了训练效果,这里要去掉背景音乐。去掉背景音乐有很多种方法,专业的做语音处理的人喜欢用Adobe Audition来处理,但学起来太麻烦了。这里可以借助深度学习的魔法来去掉背景音乐。
Ultimate Vocal Remover是一款超好用的伴奏人声提取工具,安装完成之后就可以使用UVR来分离伴奏与人声了,使用说明如下:
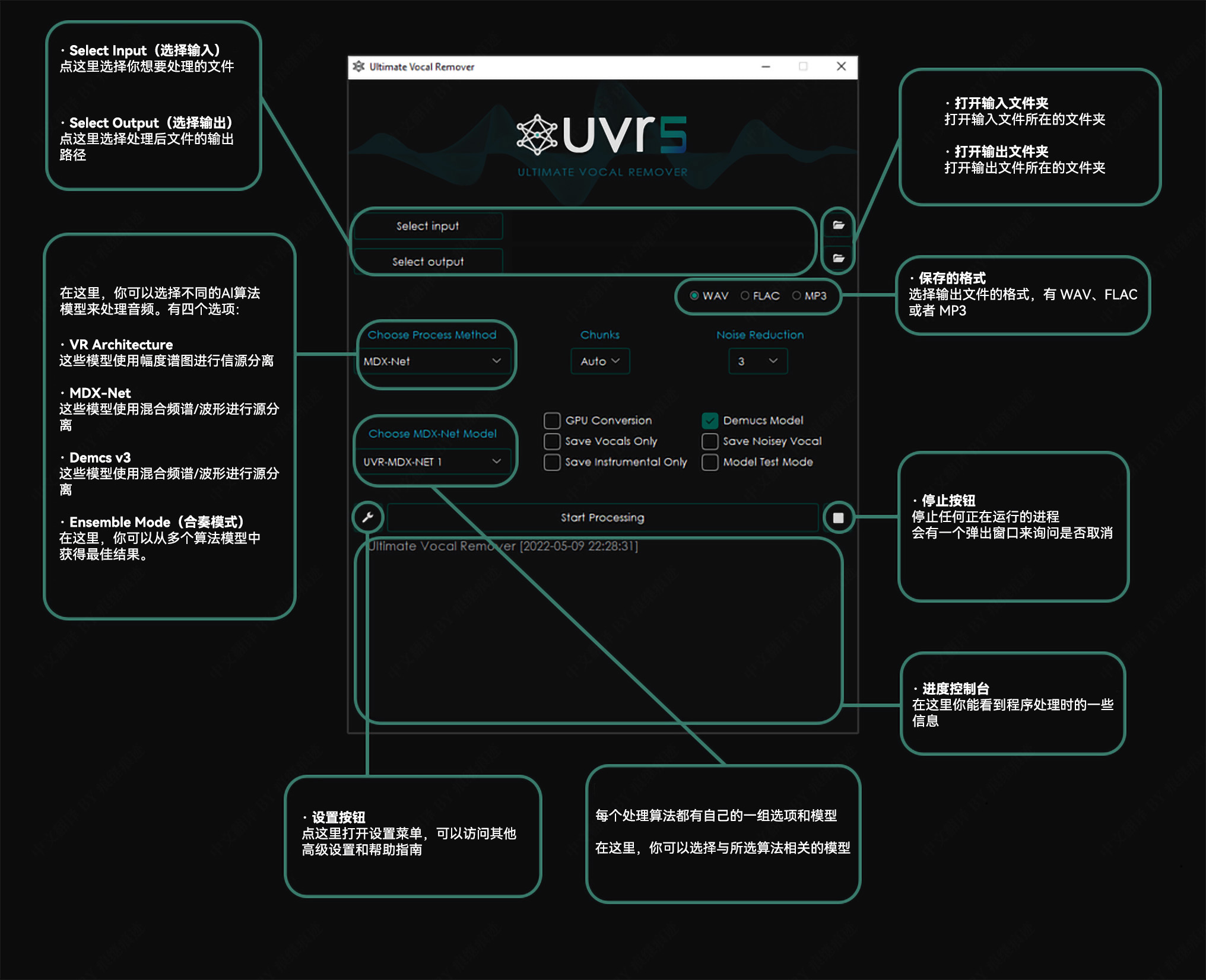
基本选项(不是深度使用者一般都只用到这几个功能)
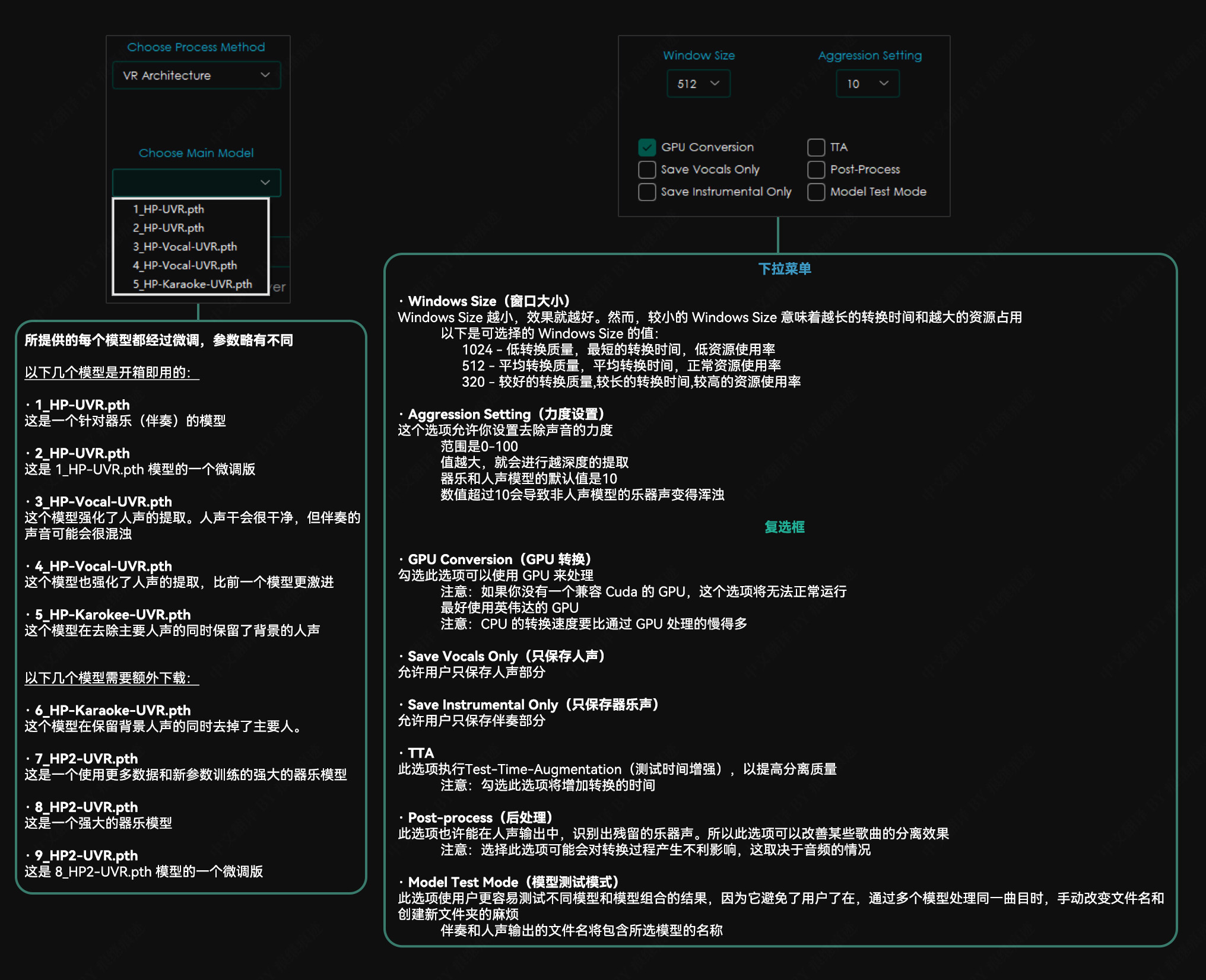
VR Architecture 选项
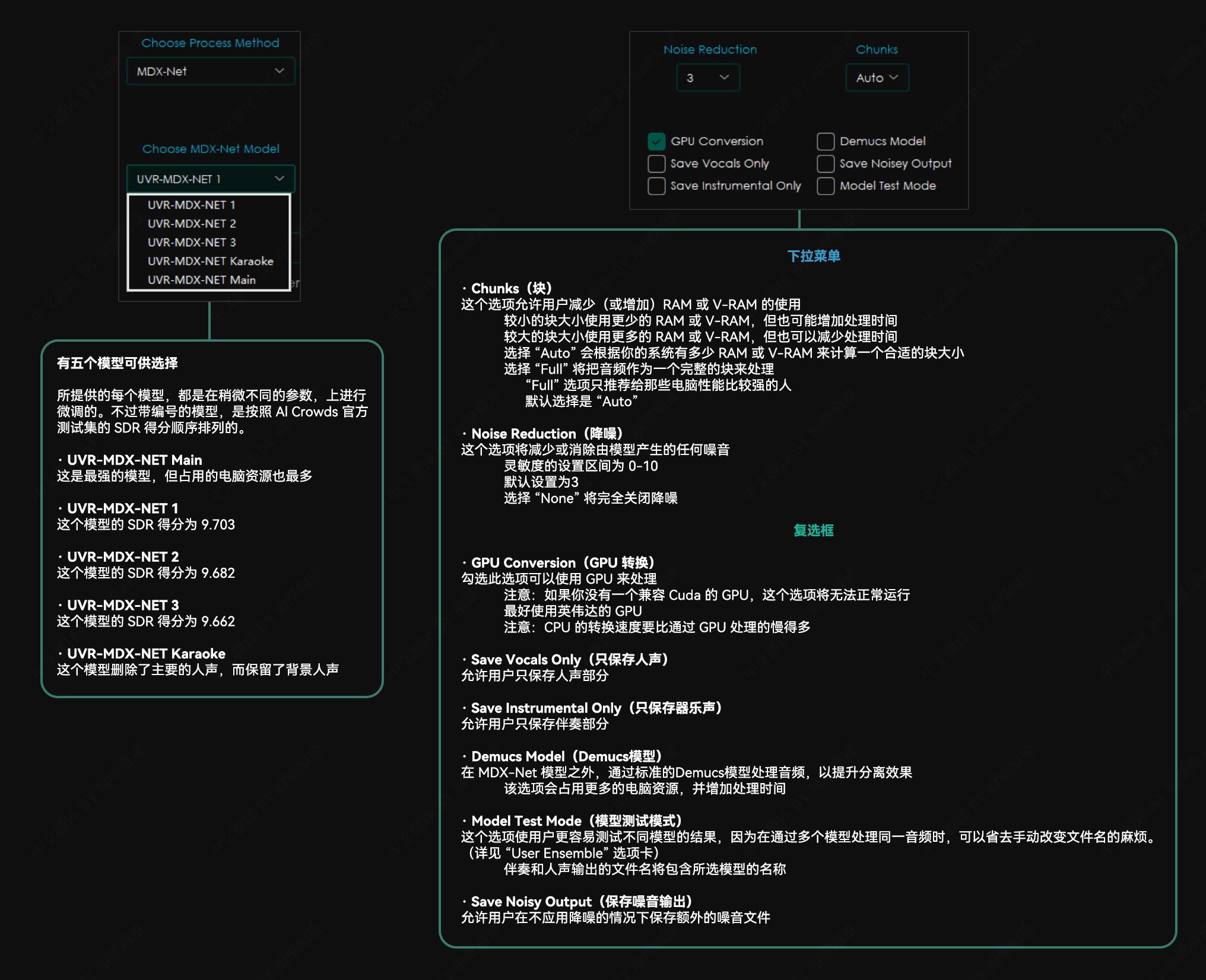
MDX-Net 选项
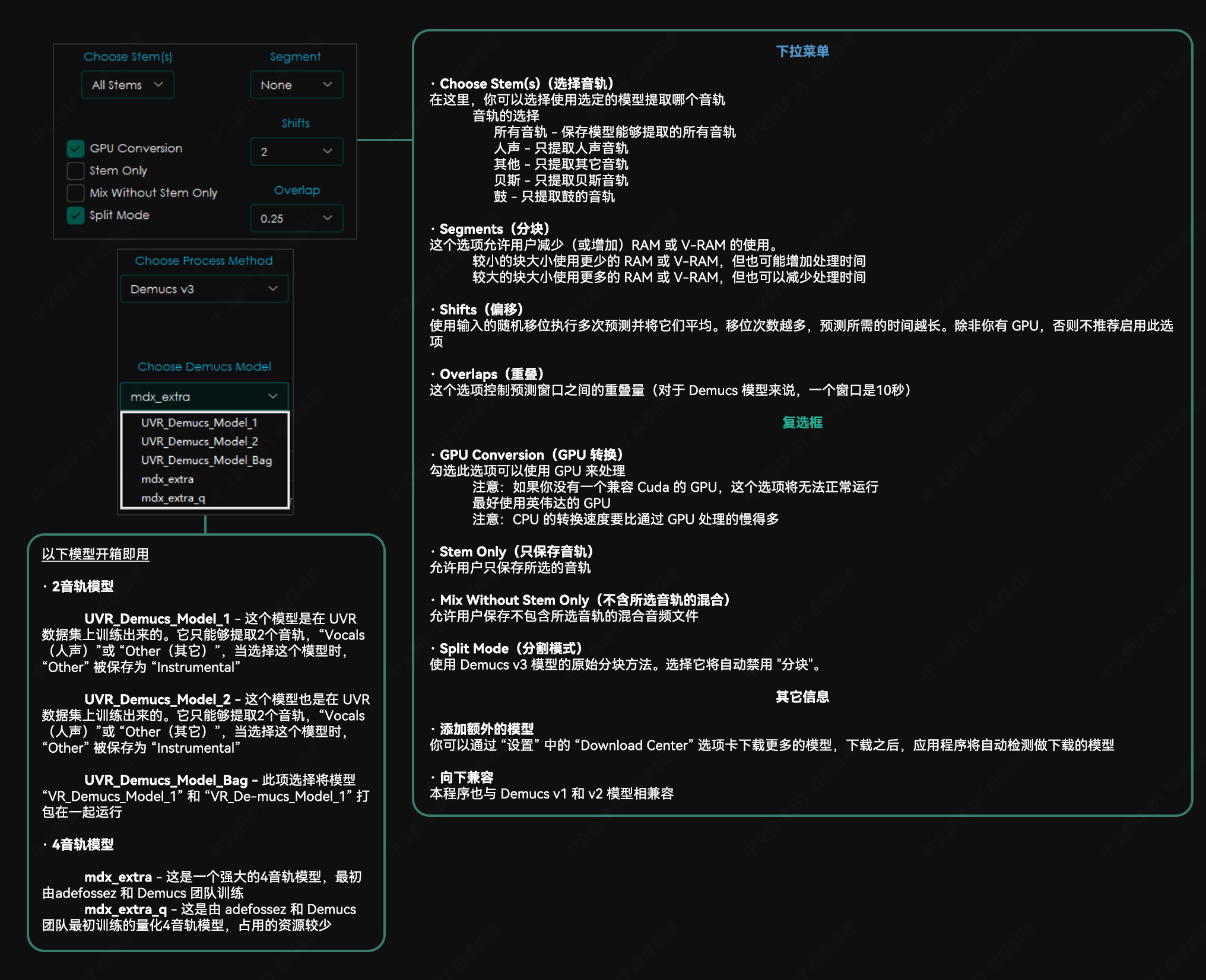
Demucs v3 选项
 Ensemble Mode 合奏选项
Ensemble Mode 合奏选项
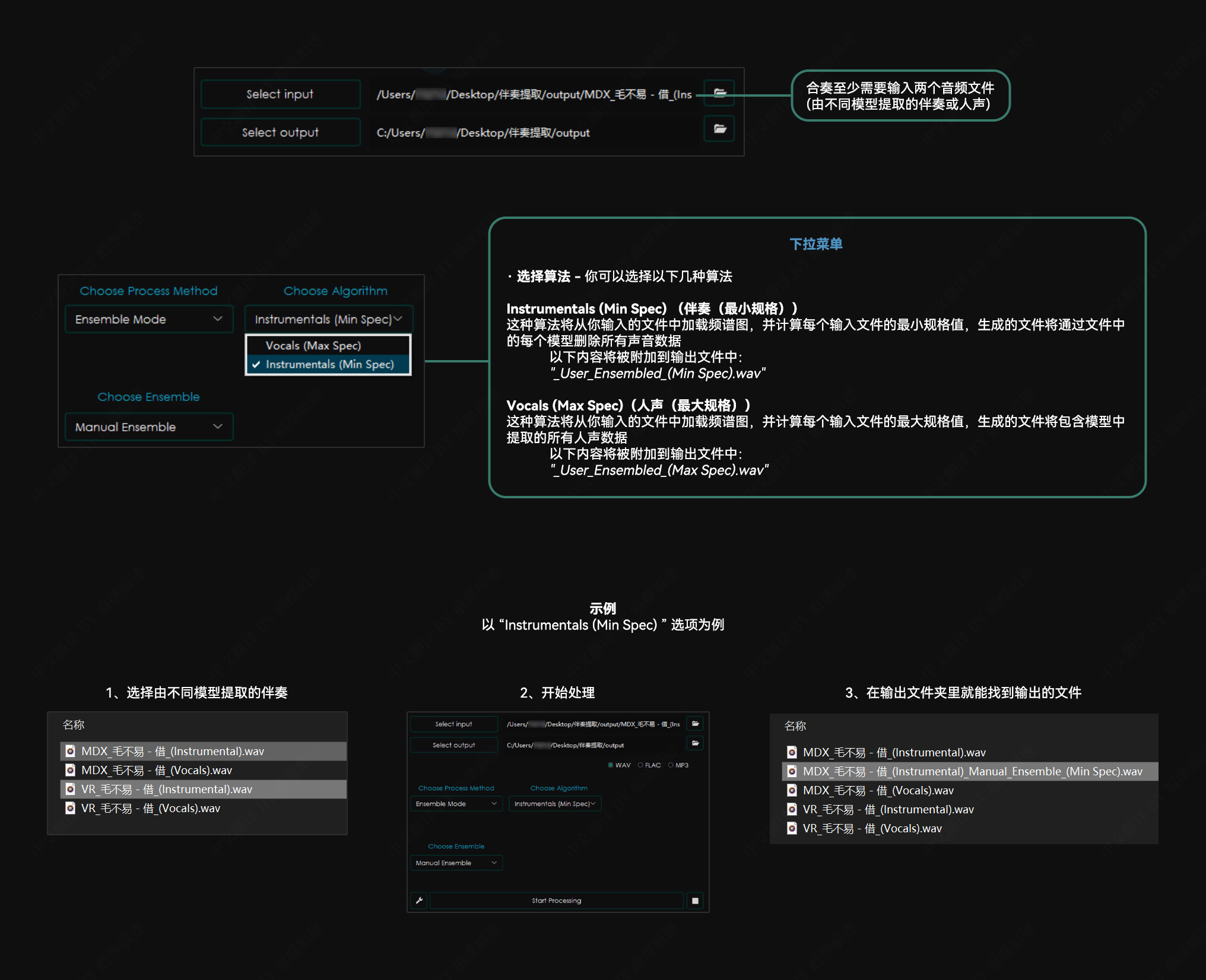
Manual Ensemble 手动合奏
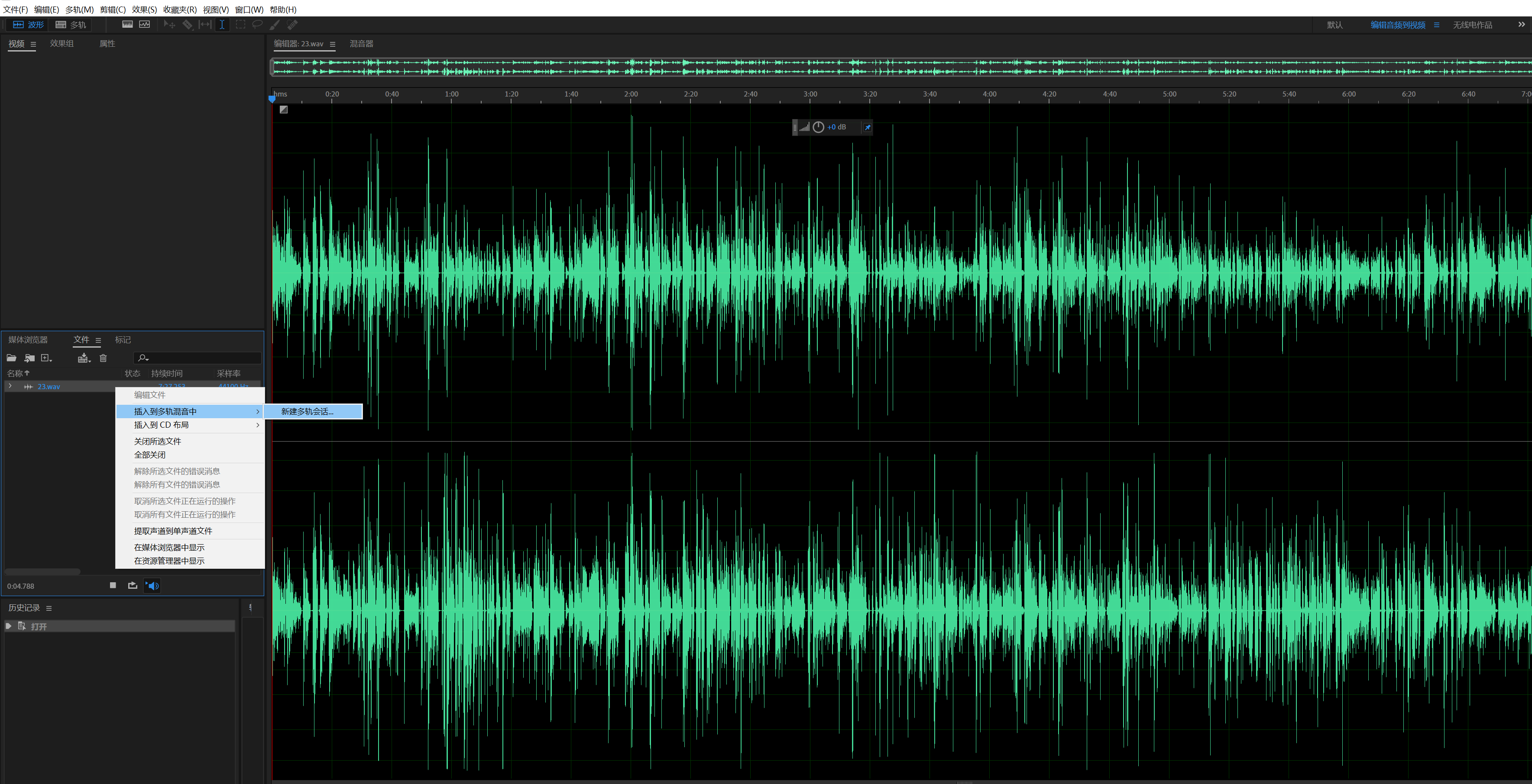
4.去掉背景音乐后,就要把音频剪切成2秒到10秒长度(不能超过10秒)的音频段。音频剪切标注则使用Adobe Audition来处理。安装完Adobe Audition之后,使用Adobe Audition打开准备好的视频或者音频文件,然后对着文件名点击—>插入到多轨混音中—>新建多轨会话,如果下图:
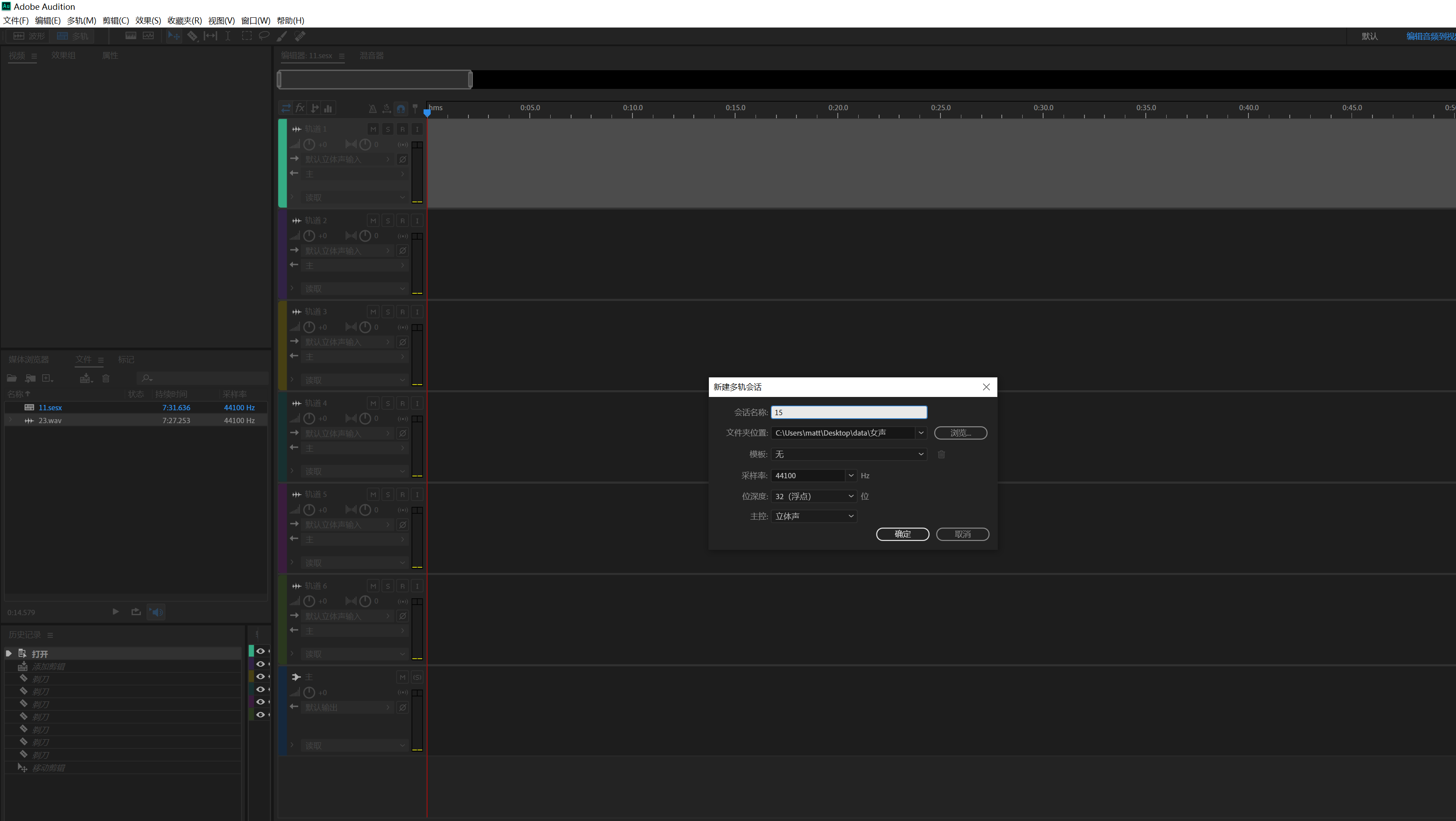
给要编辑的项目起个名:
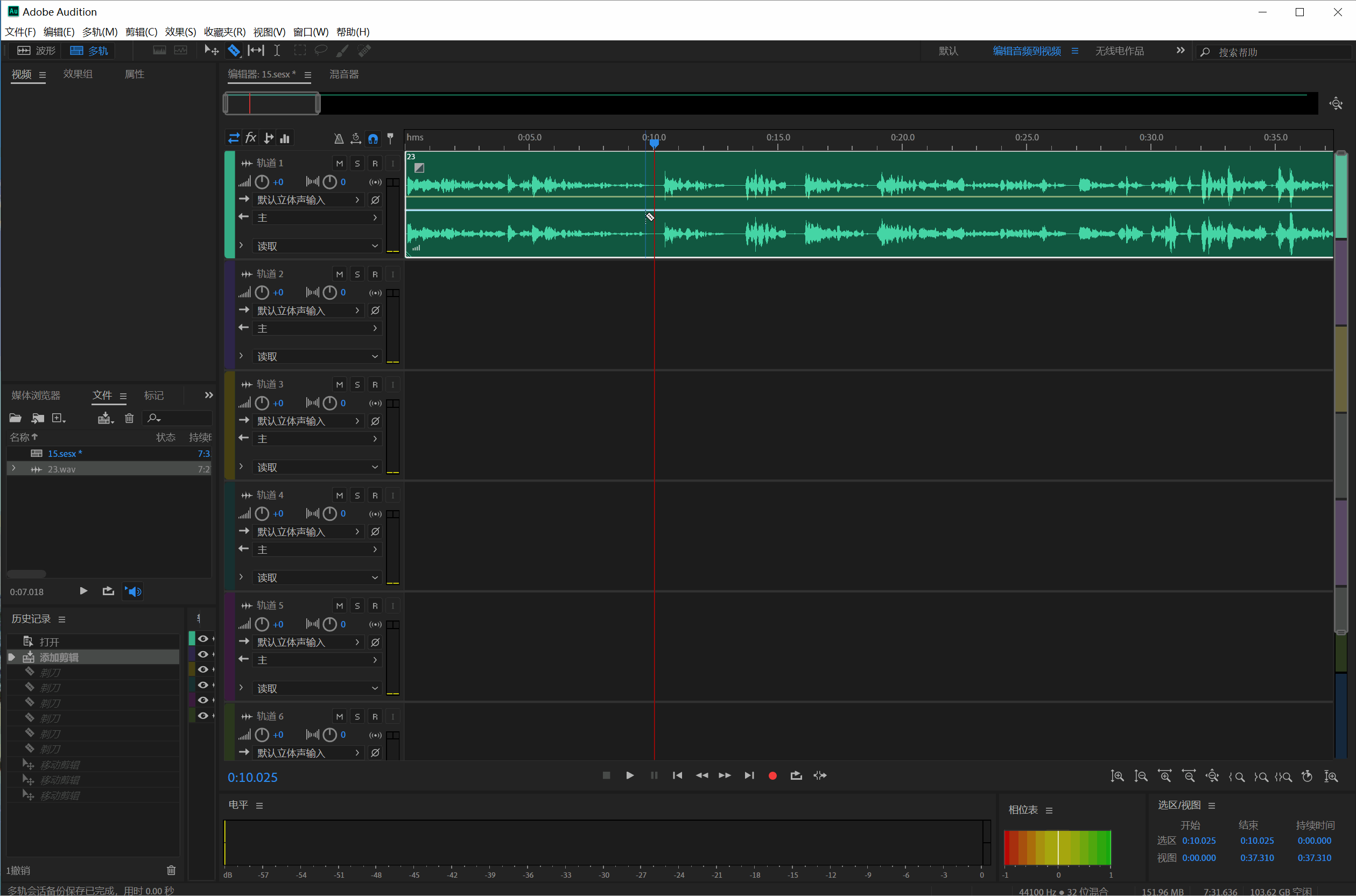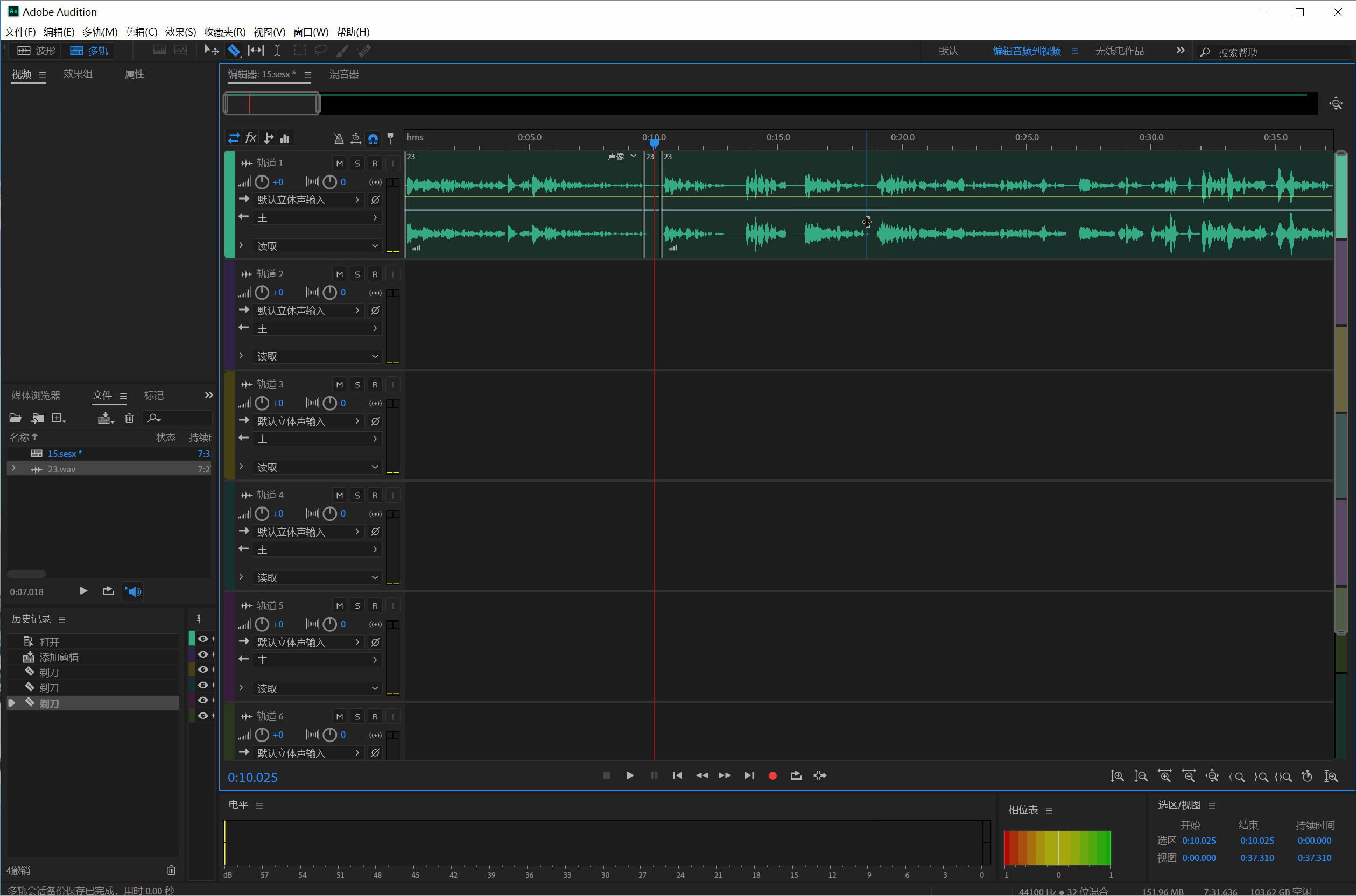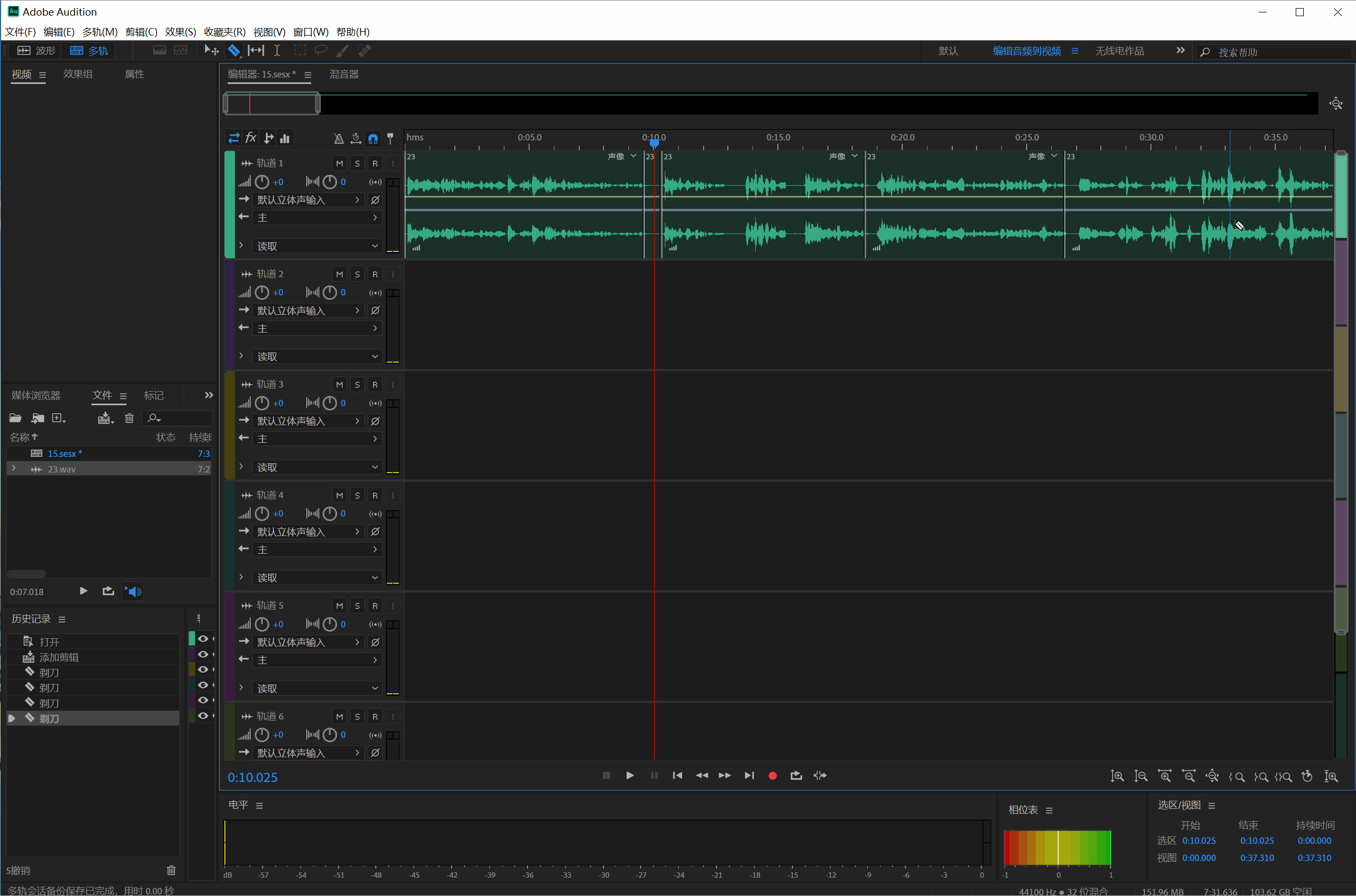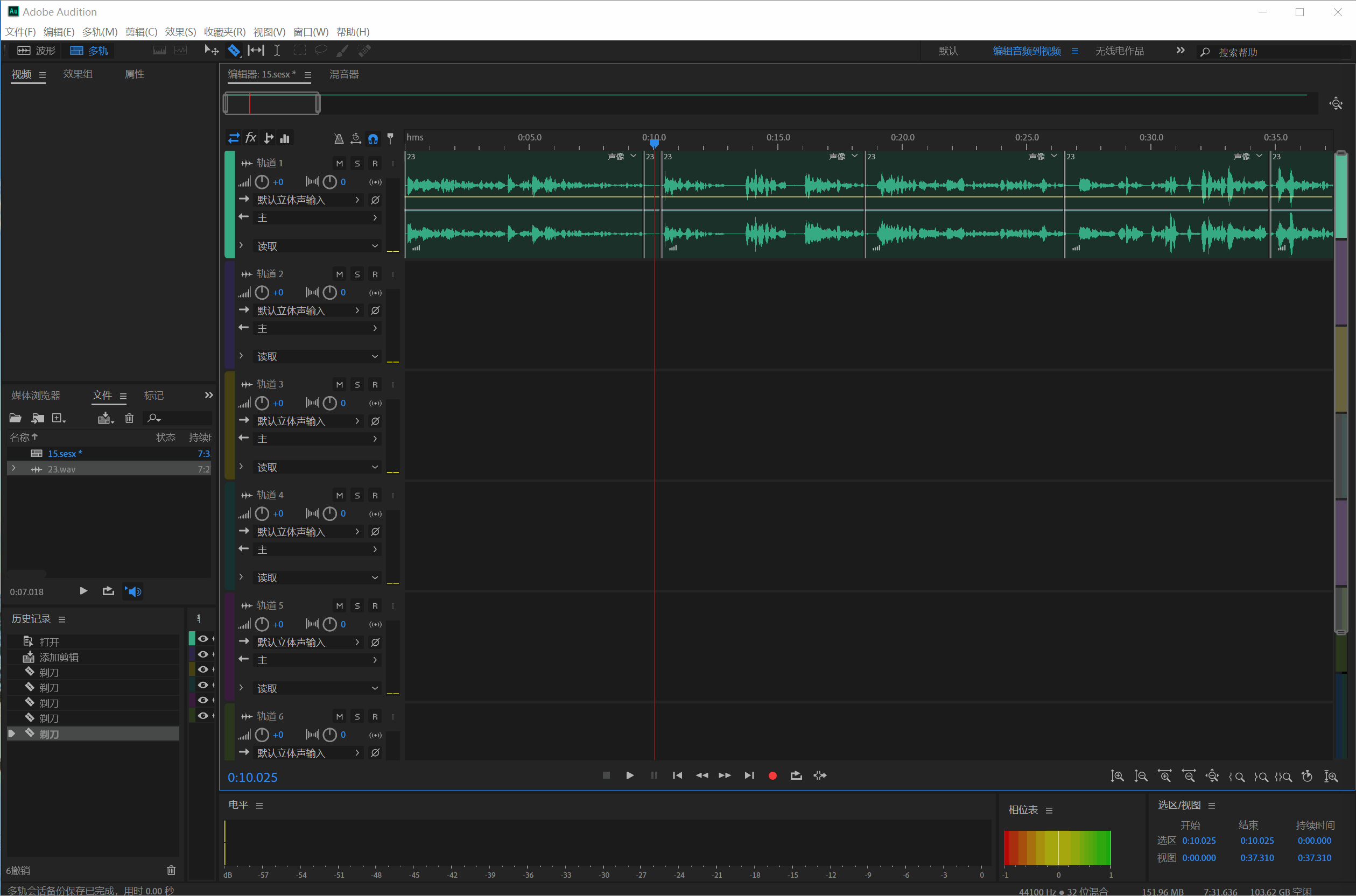
之后Adobe Audition界面的刀片就可以使用了,做切片的时候,切开的部分尽量是没有语音的部分,就是没有声波的部分,如果有很长一段没有声波,就切出来删除掉。做切片时要注意不能小于2秒不能大于10秒。
切完整个音频之后 ,把每个音频段拖动到单独的音轨里面,不用的片断则删除就行:、

然后选中所有剪切的片断(Ctrl+A),点击文件—>导出—>所有编辑
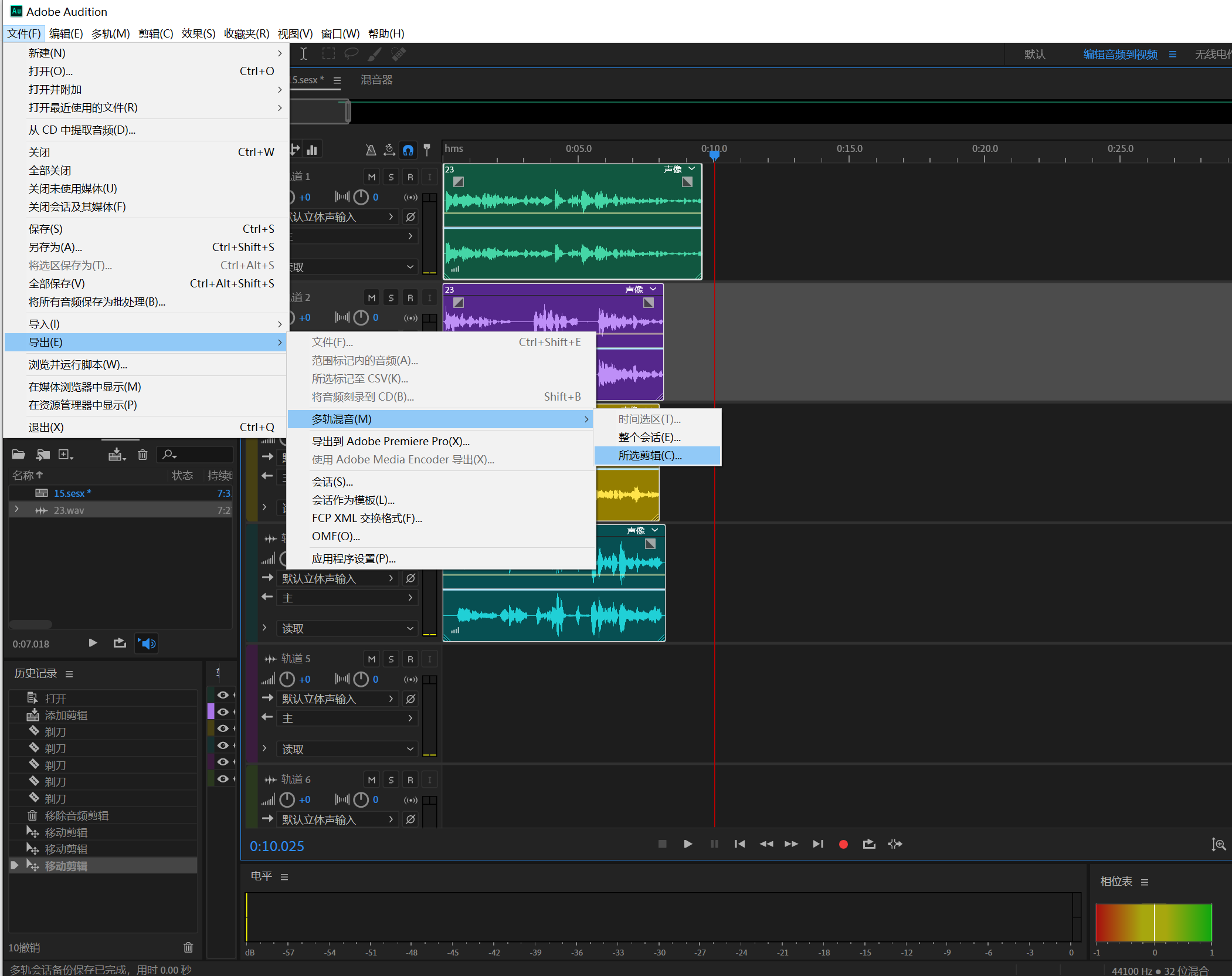
在导出界面把采样类型改成24000Hz,导出全部文件:
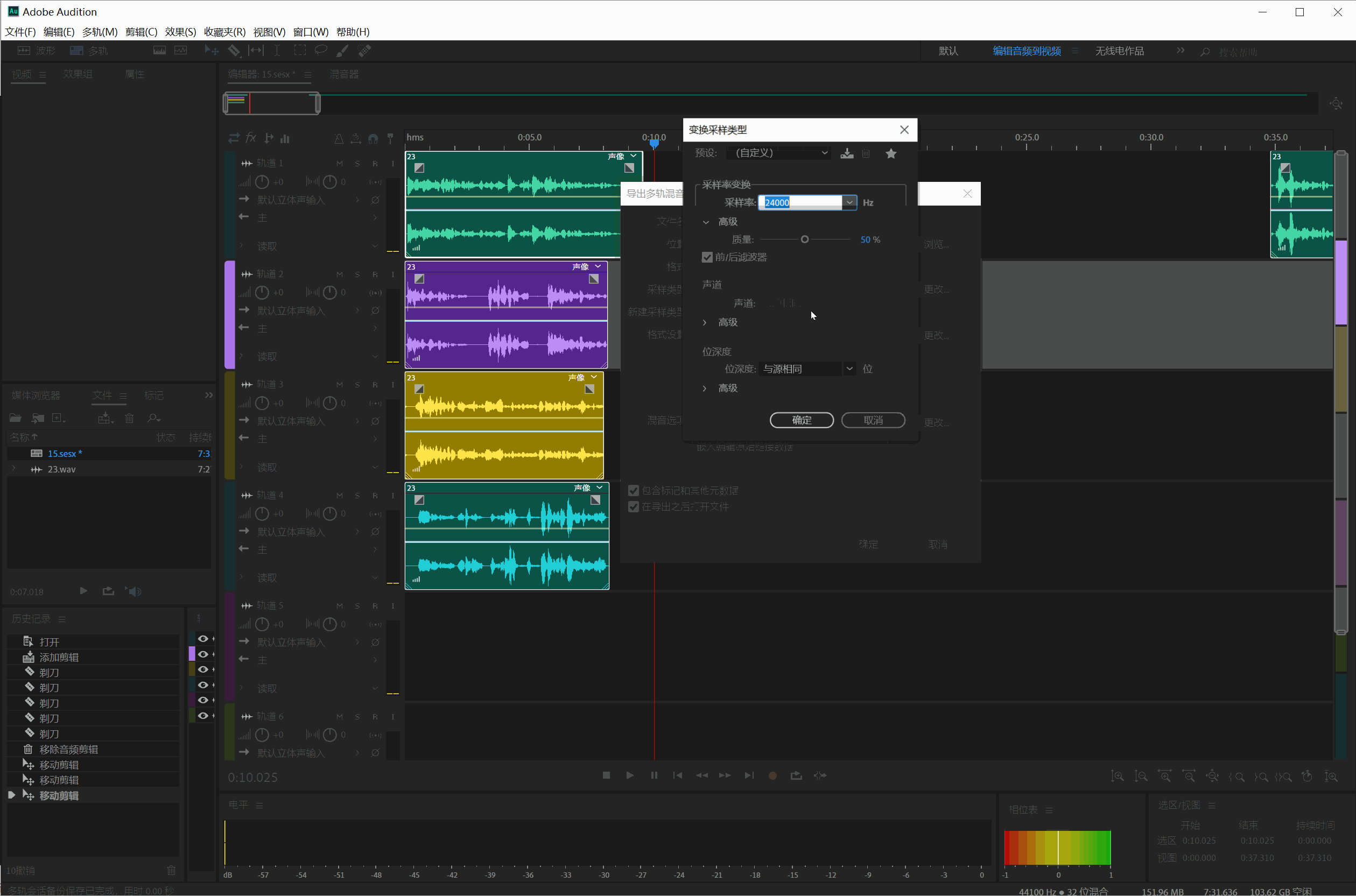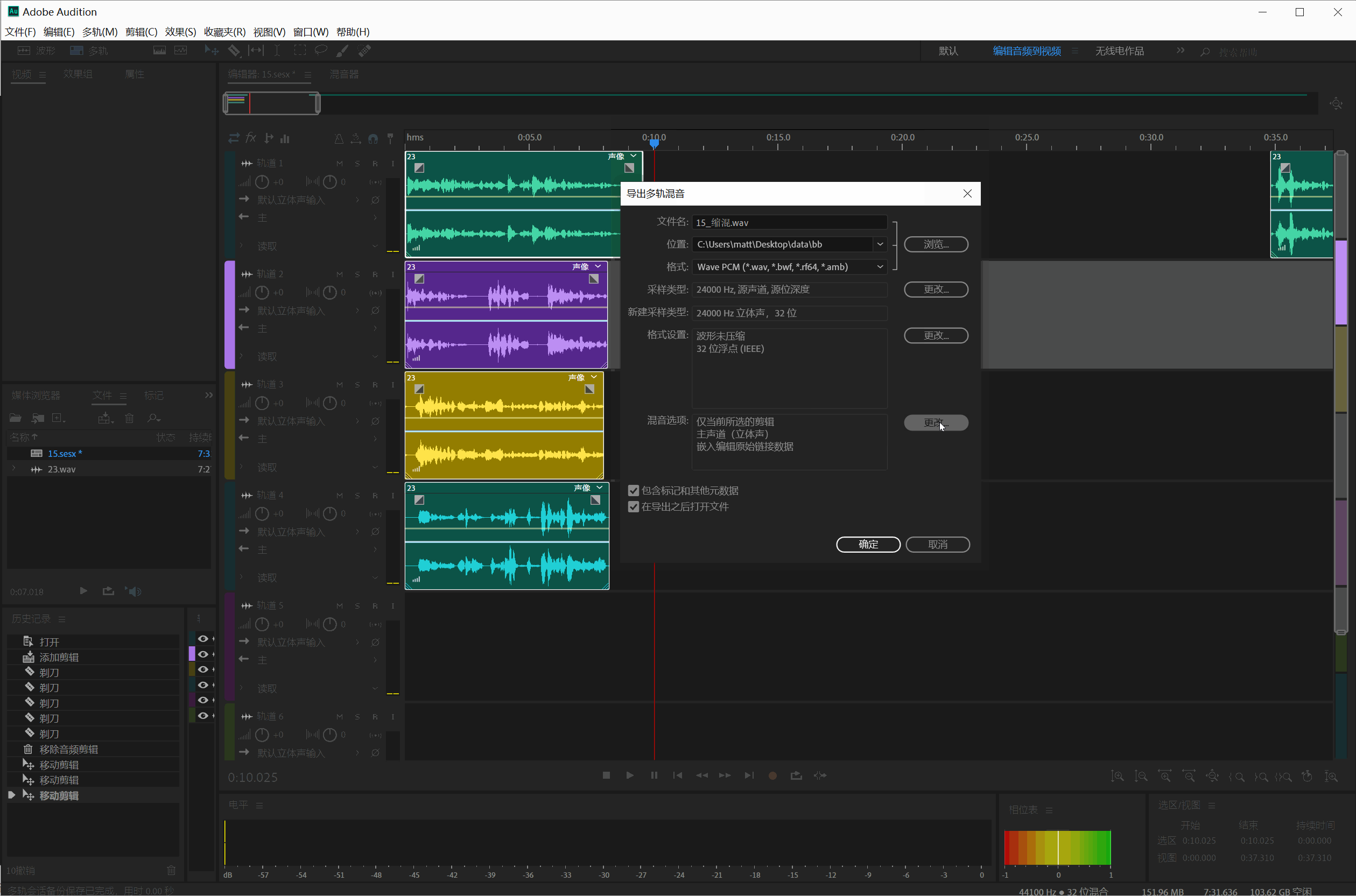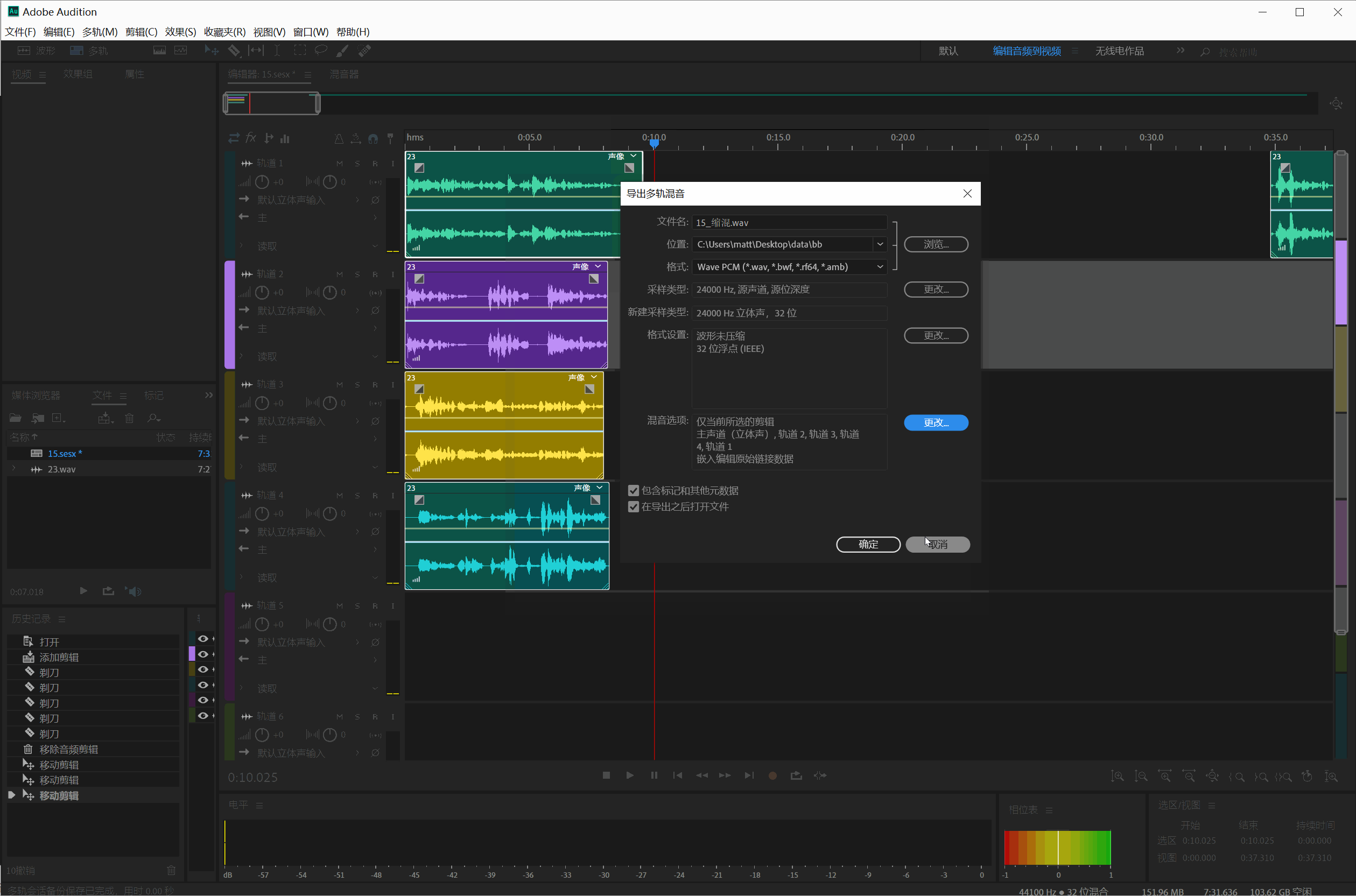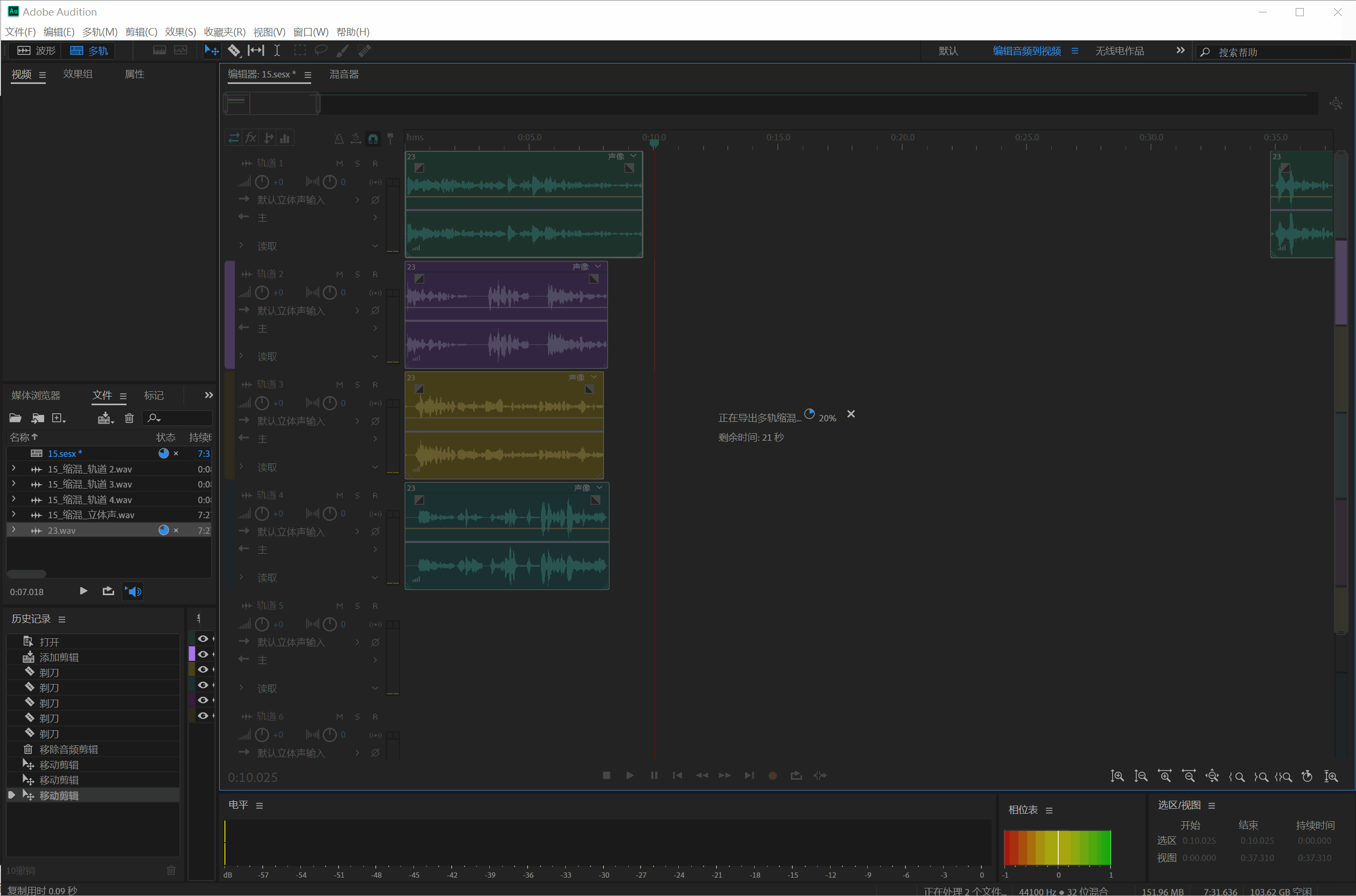
导出音频片断,保存的文件名有中文,要改成英文或者数字文件名。
相关软件下载
1.声音片断剪切软件下载:
https://download.csdn.net/download/matt45m/88033209
2.伴奏人声提取工具下载:
https://download.csdn.net/download/matt45m/88033228

![matlab[1,1]生成100个随机点](https://img-blog.csdnimg.cn/c9f61423afa24ed09e21240ec35e2838.png)