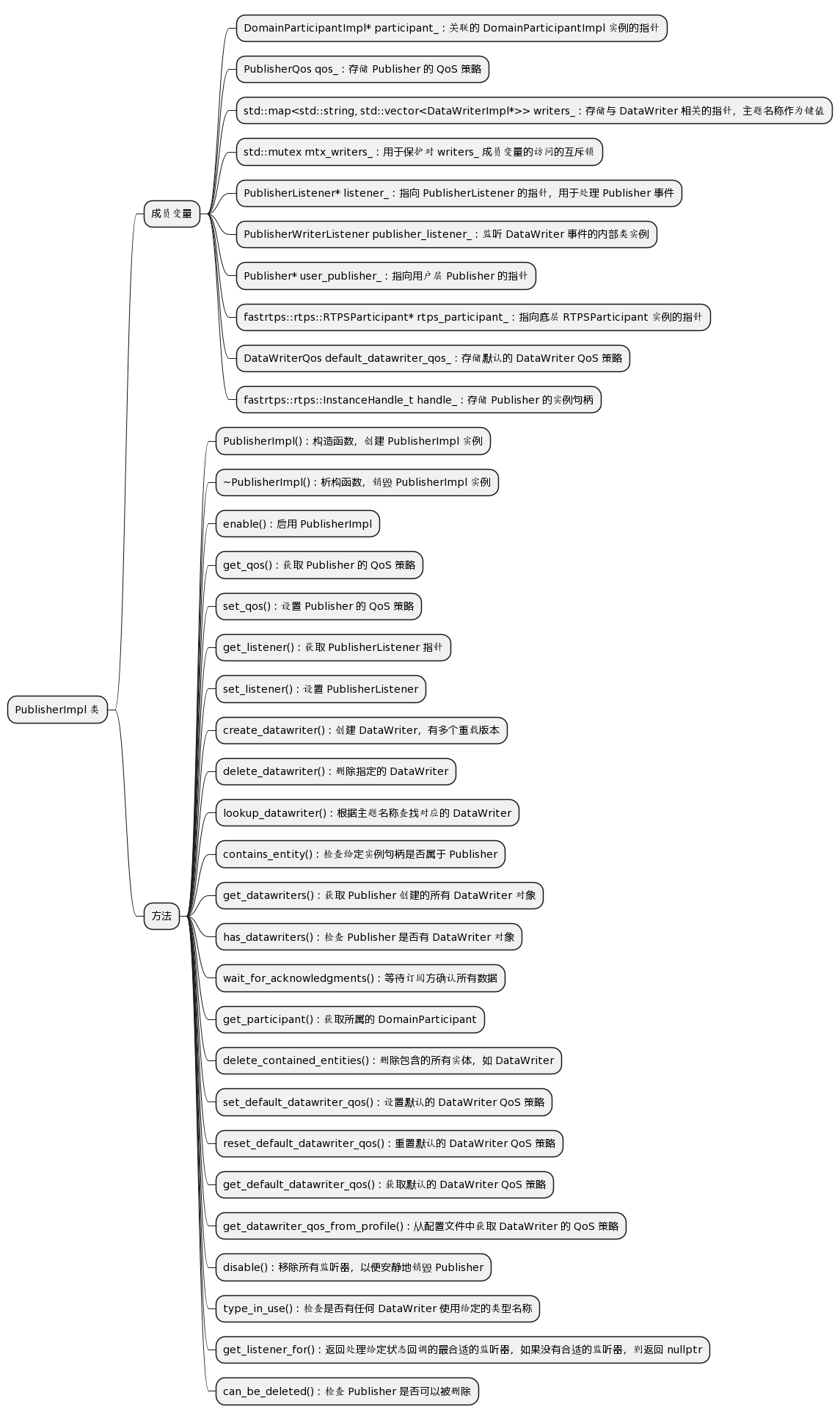
Coggle 30 Days of ML(23年7月)任务八:训练BILSTM模型
任务八:使用Word2Vec词向量,搭建BILSTM模型进行训练和预测
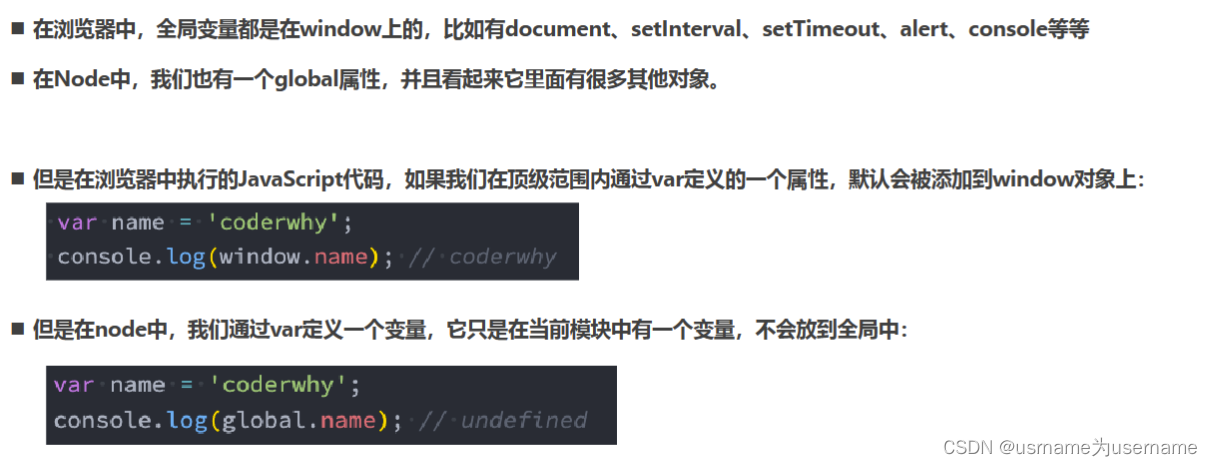
- 说明:在这个任务中,你将使用Word2Vec词向量,搭建BILSTM模型进行文本分类的训练和预测,通过双向长短期记忆网络来进行文本分类。
- 实践步骤:
- 准备Word2Vec词向量模型和相应的训练数据集。
- 构建BILSTM模型,包括嵌入层、BILSTM层、全连接层等。
- 将Word2Vec词向量应用到模型中,作为词特征的输入。
- 使用训练数据集对BILSTM模型进行训练。
- 使用训练好的BILSTM模型对测试数据集进行预测。
对于这一部分来说,整体的问题就是需要把上述的TextCNN模型换成我们新的模型进行训练和预测,也就是BILSTM模型,所以首先先介绍一下BILSTM模型
BILSTM
LSTM的全称是Long Short-Term Memory,它是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。
那为什么需要使用BILSTM呢?
将词的表示组合成句子的表示,可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法,但是这些方法没有考虑到词语在句子中前后顺序。如句子“我不觉得他好”。“不”字是对后面“好”的否定,即该句子的情感极性是贬义。使用LSTM模型可以更好的捕捉到较长距离的依赖关系。因为LSTM通过训练过程可以学到记忆哪些信息和遗忘哪些信息。
但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码,模型如图所示。
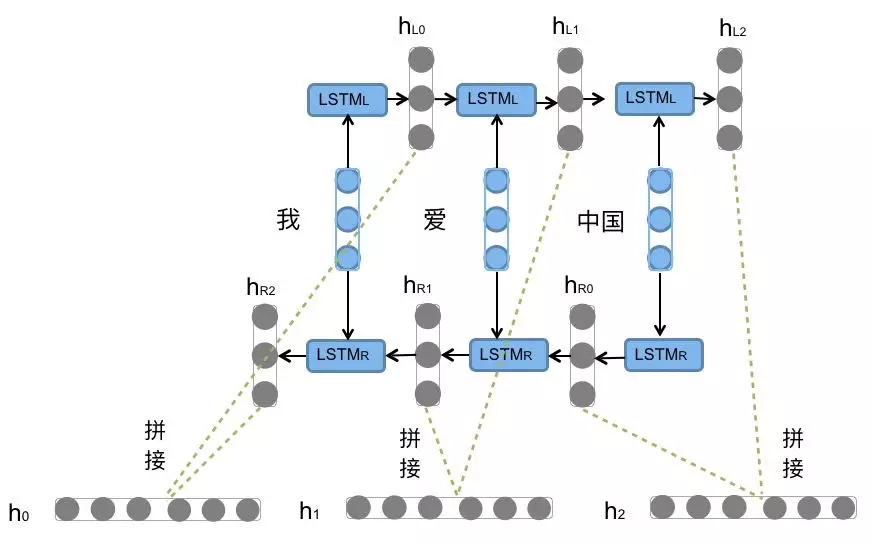
前向的依次输入“我”,“爱”,“中国”得到三个向量 { h L 0 , h L 1 , h L 2 } \{h_{L0},h_{L1},h_{L2}\} {hL0,hL1,hL2}。后向的依次输入“中国”,“爱”,“我”得到三个向量 { h R 0 , h R 1 , h R 2 } \{h_{R0},h_{R1},h_{R2}\} {hR0,hR1,hR2}。最后将前向和后向的隐向量进行拼接得到 { [ h L 0 , h R 0 ] , [ h L 1 , h R 1 ] , [ h L 2 , h R 2 ] } \{[h_{L0},h_{R0}],[h_{L1},h_{R1}],[h_{L2},h_{R2}]\} {[hL0,hR0],[hL1,hR1],[hL2,hR2]},即 { h 0 , h 1 , h 2 } \{h_{0},h_{1},h_{2}\} {h0,h1,h2}。
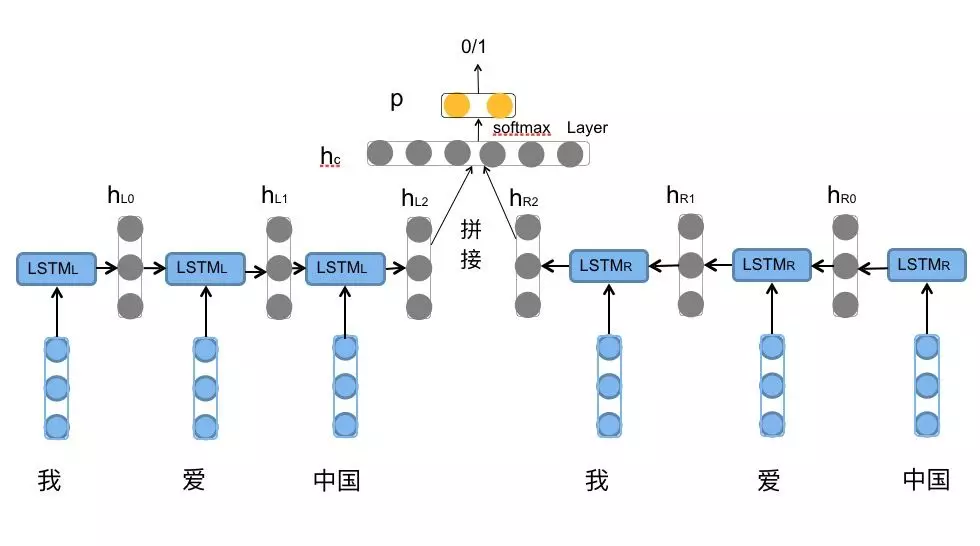
对于情感分类任务来说,我们采用的句子的表示往往是 [ h L 2 , h R 2 ] [h_{L2},h_{R2}] [hL2,hR2]。因为其包含了前向与后向的所有信息,如下图所示:
代码实现
在这一部分,我们只需要修改一下,利用一个BILSTM模型即可,我们这里使用了keras作为框架实现,大致上的思路和方法是和之前是差不多的
vocab_size = len(word2vec_model.wv.key_to_index)
print(vocab_size)
model = tf.keras.Sequential()
model.add(layers.Embedding(vocab_size, embedding_dim, weights=[word2vec_model.wv.vectors], input_length=max_length, trainable=False))
model.add(layers.Bidirectional(layers.LSTM(100, return_sequences=True)))
model.add(layers.Dense(100, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
print(model.summary())
# 设置优化器和学习率
optimizer = optimizers.SGD(learning_rate=0.1) # 使用Adam优化器,并设置学习率为0.1
# 编译模型
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 转换训练数据集的标签为one-hot编码
train_labels = tf.keras.utils.to_categorical(train_labels)
# 训练模型
model.fit(np.array(train_sequences), train_labels, epochs=5, batch_size=64)
# 预测测试数据集的分类结果
predictions = model.predict(np.array(test_sequences))
predicted_labels = predictions.argmax(axis=1)
# 读取提交样例文件
submit = pd.read_csv('ChatGPT/sample_submit.csv')
submit = submit.sort_values(by='name')
# 将预测结果赋值给提交文件的label列
submit['label'] = predicted_labels
# 保存提交文件
submit.to_csv('ChatGPT/bilstm.csv', index=None)