循环依赖与三级缓存
文章目录
- 循环依赖与三级缓存
- 一、Spring 中的循环依赖问题
- 1. Spring 中的循环依赖概述
- 2. Spring 中的循环依赖的 5 种场景
- 二、Spring 三级缓存
- 1. spring 创建 bean 的流程
- 2. 场景一:单例的 setter 注入
- 3. 三级缓存
- 4. 关于二级缓存
- 三、循环依赖的其他 4 种场景
- 1. 多例的 setter 注入
- 2. 构造器注入
- 3. 单例的代理对象 setter 注入
- 4. DependsOn 循环依赖
- 三、出现循环依赖如何解决?
一、Spring 中的循环依赖问题
1. Spring 中的循环依赖概述
Spring 循环依赖指的是 SpringBean 对象之间的依赖关系形成一个闭环。即在代码中,把两个或者多个 Bean 相互之间去持有对方的引用,就会发生循环依赖,循环依赖会导致注入出现死循环,这是 Spring 发生循环依赖的主要原因之一。
Spring 循环依赖主要有三种情况,即:自身依赖自身,两者互相依赖,多者循环依赖
- 自身依赖自身:自己依赖自己的直接依赖
- 两者互相依赖:两个对象之间的直接依
- 赖多者循环依赖:多个对象之间的间接依赖
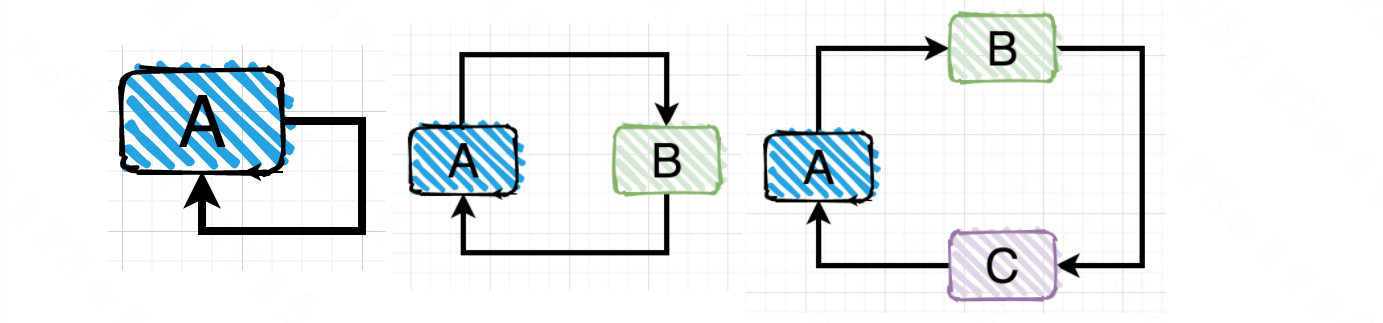
自身依赖自身,两者互相依赖 两者互相依赖的情况比较直观,很好辨识,但是我们工作中最有可能触发的还是多者循环依赖,多者循环依赖的情况有时候因为业务代码调用层级很深,不容易识别出来。但无论循环依赖的数量有多少,循环依赖的本质是一样的。就是你的完整创建依赖于我,而我的完整创建也依赖于你,但我们互相没法解耦,最终导致依赖创建失败。
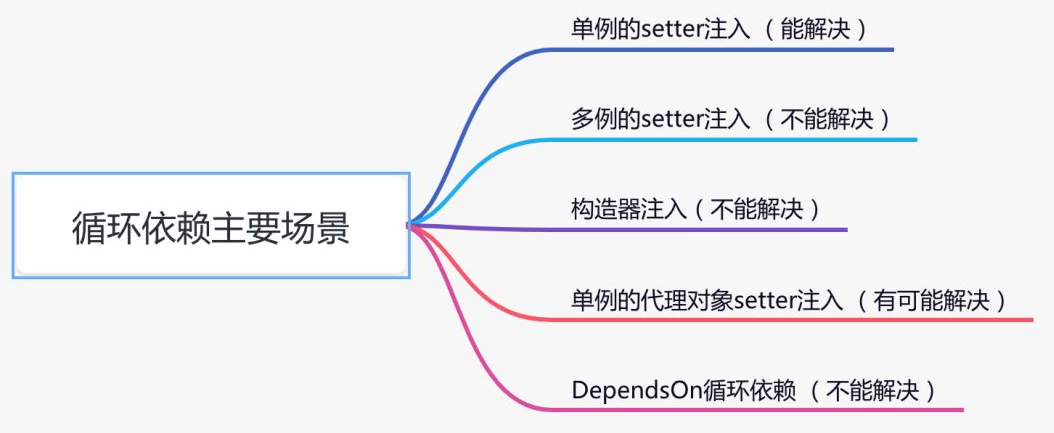
2. Spring 中的循环依赖的 5 种场景
Spring 中出现循环依赖主要有着 5 种场景:
- 单例的 setter 注入(能解决);
- 多例的 setter 注入(不能解决);
- 构造器注入(不能解决);
- 单例的代理对象 setter 注入(有可能解决);
- DependsOn 循环依赖(不能解决)。
接下来我们逐一来看。
二、Spring 三级缓存
1. spring 创建 bean 的流程
在开始理解 Spring 三级缓存如何让解决循环依赖问题前我们先来温习一下 spring 创建 bean 的流程:
- Spring 启动时会根据配置文件或启动类把所有的 bean 注册成 bean 定义(就是映射 标签属性的 Java 类)
- 遍历 bean 定义中的 beanName,调用 BeanFactory#getBean(beanName) 方法创建、初始化并返回 bean 实例
其中 getBean 方法:
- 先从缓存(一层到三层依次获取)拿,没有就去创建;
- 创建 Bean 时,把 beanName 标记为正在创建中,通过其定义里的 class找到构造器方法反射创建实例,并把其对象工厂放入第三层缓存;
- 对实例初始化,移除正在创建中的标记,把实例放入第一层缓存,移除第二、三层中的缓存,最后返回实例
实例初始化过程:获取此 bean 中有 @Autowired 等注解的成员变量,从所有 bean 定义中找出此类型的 beanName,又通过 BeanFactory#getBean 方法获取实例,然后反射设值成员变量。
位于 org.springframework.beans.factory.support.DefaultSingletonBeanRegistry 中的三级缓存源码:
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
2. 场景一:单例的 setter 注入
这种注入方式应该是 Spring 中最常见的,Demo 如下:
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
在上述代码中,就是一个经典的循环依赖,其中 TestService1 依赖 TestService2,TestService2 依赖 TestService1 构成了一个简单了两者互相依赖关系,但是我们在使用类似代码时,并没有感知过该类型的循环依赖存在,因为此种类型已经被 Spring 默默解决了。
3. 三级缓存
Spring 内部有三级缓存:
- 一级缓存(singletonObjects),用于保存实例化、注入、初始化完成的 Bean 实例
- 二级缓存(earlySingletonObjects),用于保存实例化完成的 Bean 实例
- 三级缓存(singletonFactories),用于保存 Bean 的创建工厂,以便于后面扩展有机会创建代理对象。
以上面 Demo 为例,现在项目启动,spring 开始创建 bean,比如先创建 TestService1:
- 标记 TestService1 为正在创建中,反射创建其实例,其对象工厂放入第三层缓存
- 初始化 TestService1 实例化时发现需要依赖注入 TestService2,则获取 TestService2 的实例
- 标记 TestService2 为正在创建中,反射创建其实例,其对象工厂放入第三层缓存
- 初始化 TestService2 实例化时发现需要依赖注入 TestService1,则获取 TestService1 的实例
- 这时候从缓存中获取时,TestService1 为正在创建中且第三层缓存有 TestService1 的值了,所以调用缓存的对象工厂的getObject 方法,把返回的 TestService1 实例放入第二层缓存,删除第三层缓存
- TestService2 实例初始化完成,放入第一层缓存,移除第二、三层中的缓存
- 回到第 2 步,TestService1 实例初始化完成,放入第一层缓存,移除第二、三层中的缓存
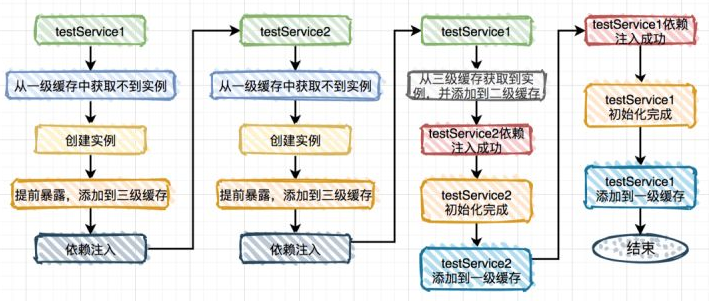
下面是 getBean(beanName) 方法最先调用的从这三层缓存中获取 bean 实例的逻辑(即上面第5步)
/**
* Return the (raw) singleton object registered under the given name.
* <p>Checks already instantiated singletons and also allows for an early
* reference to a currently created singleton (resolving a circular reference).
* @param beanName the name of the bean to look for
* @param allowEarlyReference whether early references should be created or not
* @return the registered singleton object, or {@code null} if none found
*/
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
以及一直提到的对象工厂,及其 getObject 方法的实现:
/**
* Obtain a reference for early access to the specified bean,
* typically for the purpose of resolving a circular reference.
* @param beanName the name of the bean (for error handling purposes)
* @param mbd the merged bean definition for the bean
* @param bean the raw bean instance
* @return the object to expose as bean reference
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
4. 关于二级缓存
细心的朋友可能会发现在这种场景中第二级缓存作用不大。那么问题来了,为什么要用第二级缓存呢?
试想一下,如果出现以下这种情况,我们要如何处理?
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
@Autowired
private TestService3 testService3;
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
@Service
public class TestService3 {
@Autowired
private TestService1 testService1;
public void test3() {
}
}
TestService1 依赖于 TestService2 和 TestService3,而 TestService2 依赖于 TestService1,同时 TestService3 也依赖于 TestService1。按照上图的流程可以把 TestService1 注入到 TestService2,并且 TestService1 的实例是从第三级缓存中获取的。
假设不用第二级缓存,TestService1 注入到 TestService3 的流程如图:
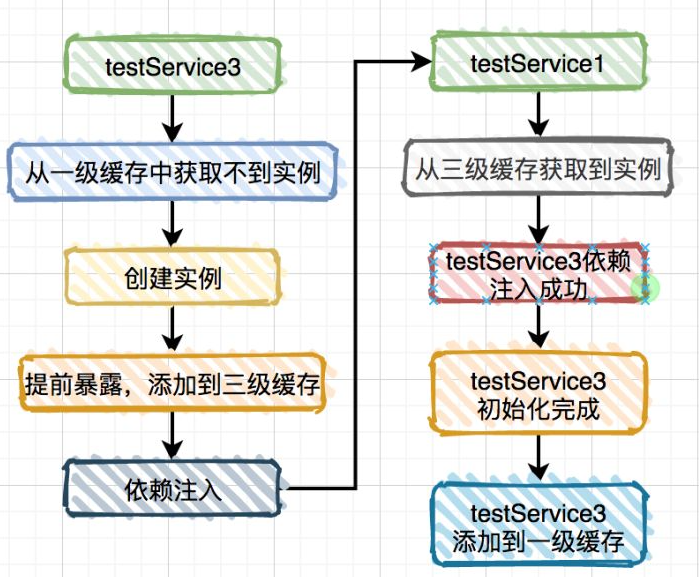
TestService1 注入到 TestService3 又需要从第三级缓存中获取实例,而第三级缓存里保存的并非真正的实例对象,而是 ObjectFactory对象。说白了,两次从三级缓存中获取都是 ObjectFactory 对象,而通过它创建的实例对象每次可能都不一样的。这样不是有问题?
为了解决这个问题,Spring 引入的第二级缓存。上面其实 TestService1 对象的实例已经被添加到第二级缓存中了,而在 TestService1 注入到 TestService3 时,只用从第二级缓存中获取该对象即可。
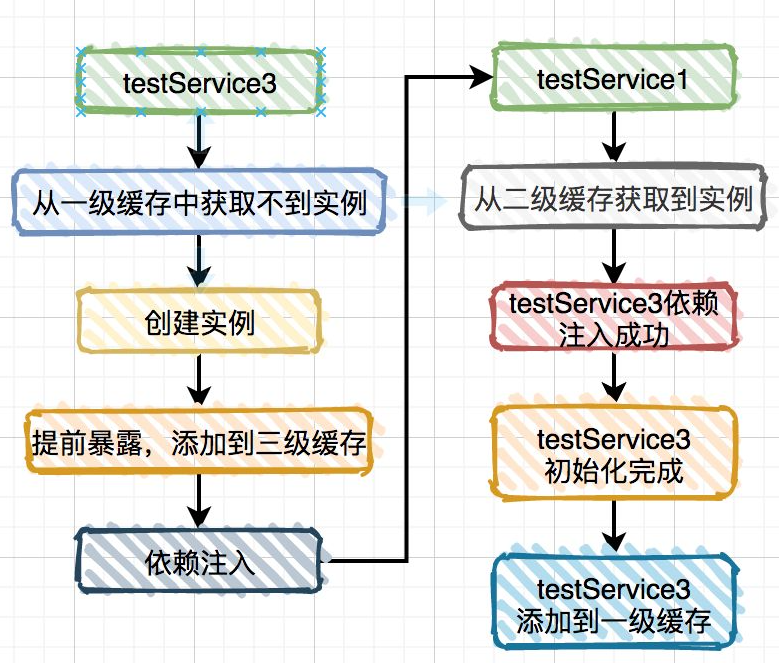
还有个问题,第三级缓存中为什么要添加 ObjectFactory 对象,直接保存实例对象不行吗?答:不行,因为假如你想对添加到三级缓存中的实例对象进行增强,直接用实例对象是行不通的。
三、循环依赖的其他 4 种场景
1. 多例的 setter 注入
这种注入方法偶然会有,特别是在多线程的场景下,具体代码如下:
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
public void test1() {
}
}
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
在上述多例的 setter 注入情况下,Spring 程序也是能够正常启动启动的,其实在AbstractApplicationContext 类的 refresh方法中告诉了我们答案,它会调用 finishBeanFactoryInitialization 方法,该方法的作用是为了 Spring 容器启动的时候提前初始化一些 Bean。该方法的内部又调用了 preInstantiateSingletons 方法
@Override
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
getBean(beanName);
}
}
}
其中非抽象、单例并且非懒加载的类才能被提前初始 Bean。,而多例即 SCOPE_PROTOTYPE 类型的类,非单例,不会被提前初始化 Bean,所以程序能够正常启动。如何让他提前初始化bean呢?
只需要再在 DEMO 中定义一个单例的类,在它里面注入 TestService1
@Service
public class TestService3 {
@Autowired
private TestService1 testService1;
}
重新启动程序,执行结果:
Requested bean is currently in creation: Is there an unresolvable circular reference?
果然出现了循环依赖。
这种循环依赖问题是无法解决的,因为它没有用缓存,每次都会生成一个新对象。
2. 构造器注入
这种注入方式现在其实用的已经非常少了,但是我们还是有必要了解一下,如下代码:
@Service
public class TestService1 {
public TestService1(TestService2 testService2) {
}
}
@Service
public class TestService2 {
public TestService2(TestService1 testService1) {
}
}
运行结果:
Requested bean is currently in creation: Is there an unresolvable circular reference?
出现了循环依赖,为什么呢?
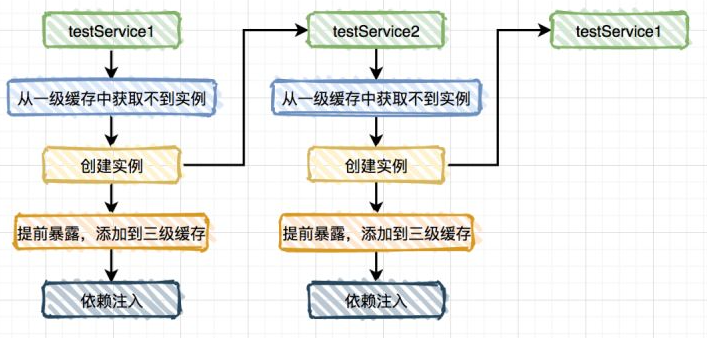
从图中的流程看出构造器注入没能添加到三级缓存,也没有使用缓存,所以也无法解决循环依赖问题。
3. 单例的代理对象 setter 注入
这种注入方式其实也比较常用,比如平时使用:@Async 注解的场景,会通过 AOP 自动生成代理对象。
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
@Async
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
从前面得知程序启动会报错,出现了循环依赖,为什么会循环依赖呢?答案就在下面这张图中:
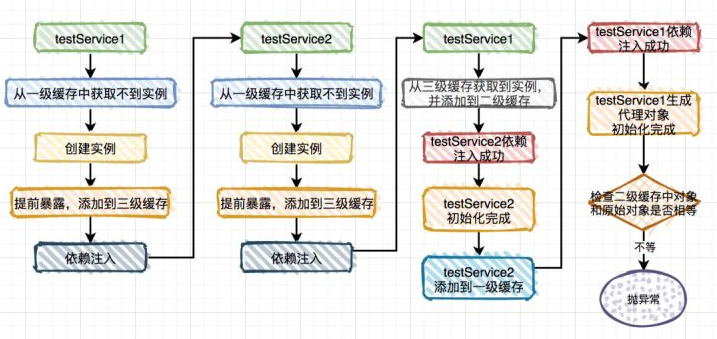
说白了,Bean 初始化完成之后,后面还有一步去检查:第二级缓存和原始对象是否相等。由于它对前面流程来说无关紧要,所以前面的流程图中省略了,但是在这里是关键点,我们重点说说:
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
正好是走到这段代码,发现第二级缓存和原始对象不相等,所以抛出了循环依赖的异常。如果这时候把 TestService1 改个名字,改成:TestService6,其他的都不变。
@Service
public class TestService6 {
@Autowired
private TestService2 testService2;
@Async
public void test1() {
}
}
再重新启动一下程序,神奇般的好了。这是为什么?这就要从 Spring Bean 加载顺序说起了,默认情况下,Spring 是按照文件完整路径递归查找的,按路径+文件名排序,排在前面的先加载。所以 TestService1 比T estService2 先加载,而改了文件名称之后,TestService2 比 TestService6 先加载。
为什么 TestService2 比 TestService6 先加载就没问题呢?答案在下面这张图中:
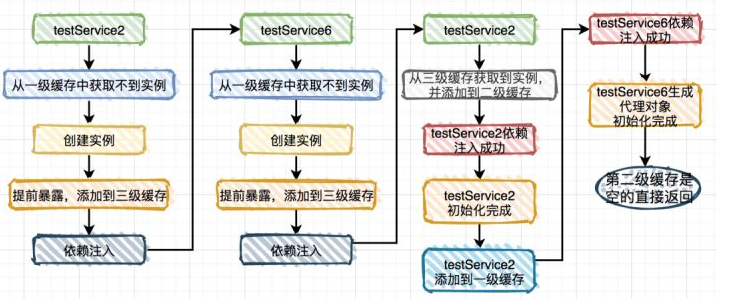
这种情况 testService6 中其实第二级缓存是空的,不需要跟原始对象判断,所以不会抛出循环依赖。
4. DependsOn 循环依赖
还有一种有些特殊的场景,比如我们需要在实例化 Bean A 之前,先实例化 Bean B,这个时候就可以使用 @DependsOn 注解。
@DependsOn(value = "testService2")
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
public void test1() {
}
}
@DependsOn(value = "testService1")
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
程序启动之后,执行结果:
Circular depends-on relationship between 'testService2' and 'testService1'
这个例子中本来如果 TestService1 和 TestService2 都没有加 @DependsOn 注解是没问题的,反而加了这个注解会出现循环依赖问题。
这又是为什么?答案在 AbstractBeanFactory 类的 doGetBean 方法的这段代码中:
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
try {
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
它会检查 dependsOn 的实例有没有循环依赖,如果有循环依赖则抛异常。
三、出现循环依赖如何解决?
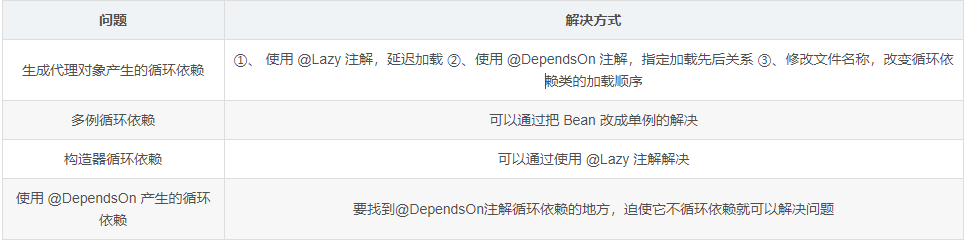
项目中如果出现循环依赖问题,说明是 Spring 默认无法解决的循环依赖,要看项目的打印日志,属于哪种循环依赖。目前包含下面几种情况:
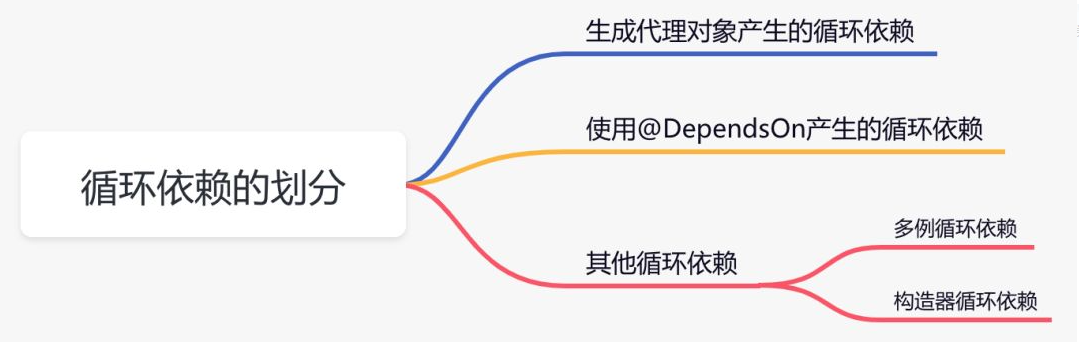
解决方式: