UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View

文章目录
- UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View
- 摘要
- 介绍
- Question: 说了半天这个时空融合到底什么意思?
- 方法
- 多视图融合的推导过程
- 统一多视图融合的网络架构
- 主干网络
- 融合Transformer
- 分割头
- 实验结果
- Reference
- >>>>> 欢迎关注公众号【三戒纪元】 <<<<<
2022年7月,浙江大学、大疆公司和上海AI实验室发表了《UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View》,
1College of Computer Science, Zhejiang University;
2DJI
3Shanghai Institute for Advanced Study of Zhejiang University;
4Shanghai AI Lab
摘要
Bird’s eye view (BEV) 表达自动驾驶中的一种新的感知构想,基于空间融合。BEV表达中引入时序融合,也取得了巨大成功。
本篇文章,介绍了一种新的方法统一时空融合,并融合到一个统一的数学表达。
因为有了时空融合,所以可以支持远距离融合,这是传统BEV方法做不到的。此外,BEV融合有时间自适应性且时间融合的权重也是可以学习的。而传统时间融合使用固定和相同的权重。此外,统一融合能够避免传统BEV融合中的信息丢失,且充分利用特征数据。
介绍
BEV表示是将多个相机特征映射到自车坐标系空间内。

这种空间融合构建了一个集成的BEV空间,来自不同相机的重复结果在BEV空间被唯一的表示出来,极大地降低了多相机特征融合的难度。
BEV空间融合自然地共享相同的3D空间,使得多模态融合更简单。基于空间融合的集成BEV表达提供了时间融合的基础。
好处:
1.可以表达出被暂时遮挡的物体;
2.基类远距离观测数据,可用于生成地图
3.稳定静止车辆的感知结果
Question: 说了半天这个时空融合到底什么意思?
所谓时空融合,就是对数据在空间上进行组合,在多个时间片段上予以融合。
- 空间:不同位置多相机(或其他传感器)融合;
- 时间:多个历史帧数据融合
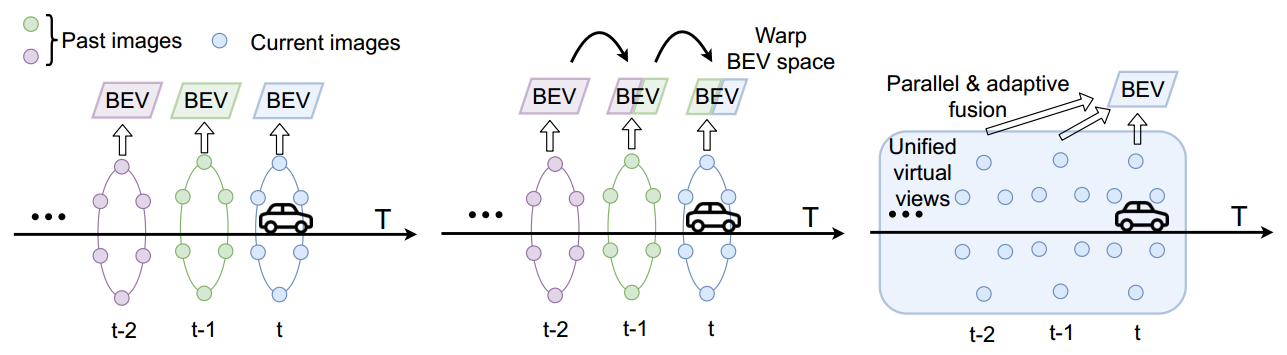
上图从左到右,无时域融合、基于warp的时域融合和提出的统一多视图融合。对于无时域融合的方法,仅在当前时间步长用周围图像预测BEV空间;基于warp的时域融合将上一时间步的BEV空间warp,是一种串行融合方法;统一的多视图融合,是一种并行方法,可以支持远距离融合。Virtual views
由于时间特征来自于过去,当前时间不存在,为了时间融合,作者提出了 虚拟视角(virtual views)的概念,假装它们存在于当前时间。
virtual views 就是将相机过去的视野当成现在的视野,根据相机的运动为这些视野分配当前BEV空间的虚拟位置。
通过这种方法,这个时空表达能够被简单当成一个统一的多视角融合,包含当前空间融合和过去的虚拟视角。
时间和空间同步融合了能够通过时空一次性获取到有用的特征。
由于直接获取到所有时间特征,因此可以实现可适应的时间融合。
并行的特征保证了在融合过程中没有丢失信息。
多视角统一融合可以支持不同传感器的融合,还能架起更高层次和异构融合的桥梁,比如车辆侧和道路侧的感知,比如车上的摄像头和交通灯上监控摄像头的信息融合。
方法
建立统一的多角度融合包括2部分:
- 多视图融合的推导过程;
- 统一多视图融合的网络架构
多视图融合的推导过程
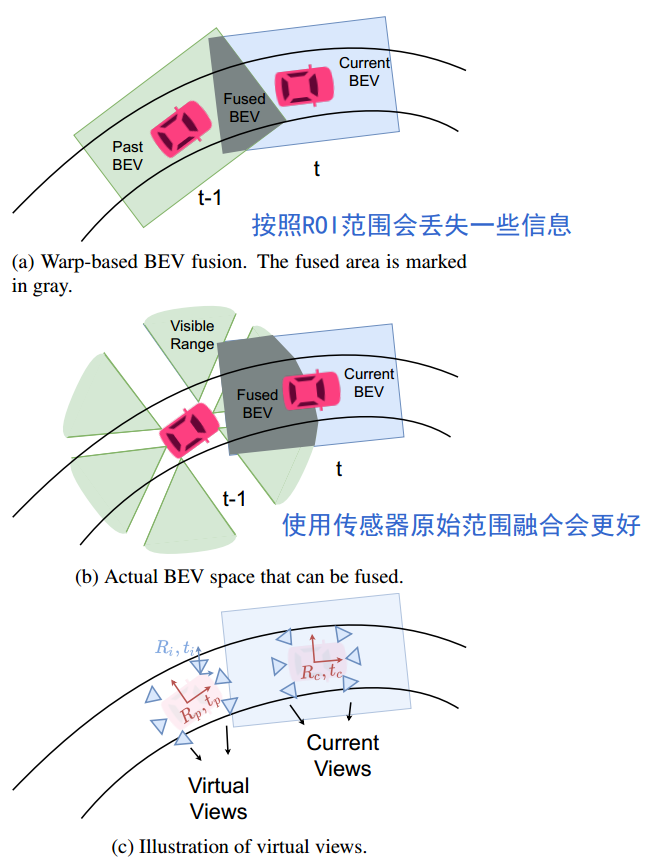
传统的BEV时间融合是基于扭曲时间的融合,即基于不同时间步长的自车运动扭曲过去的BEV特征信息。因为所有特征已经在扭曲前的某一时刻的定义的BEV自车空间中组织好了,一般会按照ROI的范围进行组织,所以范围变小了,会丢失一些信息,比如原来传感器能够捕获到100米远的信息,但是经过ROI可能就设定为55米。
因此使用传感器原始范围进行融合,效果会更好。
为了得到更好的时间融合,提出了 virtual view的概念。
虚拟视角(virtual view):不在当前时间步长内显示的传感器视角。将过去的视角通过平移和旋转到当前自车BEV空间,好像它们就在当前时间步长内一样。
说白了,就是将过去时刻的数据转换到当前时刻下
P
P
o
i
n
t
C
l
o
u
d
=
K
i
(
R
i
v
P
b
e
v
+
t
i
v
)
P_{PointCloud} = K_i \left( R_i^vP_{bev} + t_i^v \right)
PPointCloud=Ki(RivPbev+tiv)
统一多视图融合的网络架构
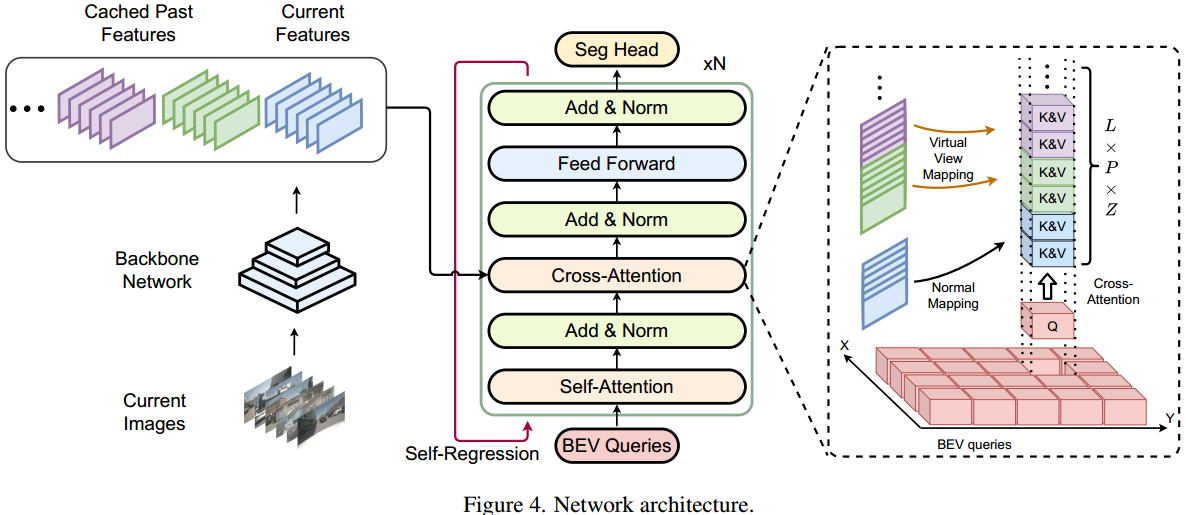
网络架构主要由3部分组成:
- 主干网络
- 统一多视角融合Transformer
- 分割头
主干网络
主干网络使用3种广泛使用的主干网络:ResNet50、Swin-Tiny、VoVNet 提取多尺度特征。
融合Transformer
使用 Transformer encoder 融合多角度特征。
主要包含4部分:
- BEV 查询
- 自注意模块
- 交叉注意模块
- 自回归机制
用BEV query Q来迭代BEV空间不同位置的特征、时间步、多尺度级和采样高度。可以以统一的方式直接检索来自任何地点和时间的信息,而不会造成任何损失。
受BEVFormer 的启发,自回归机制是将Transformer的输出与BEV查询连接起来作为新的输入,并重新运行Transformer以获得最终的特征。
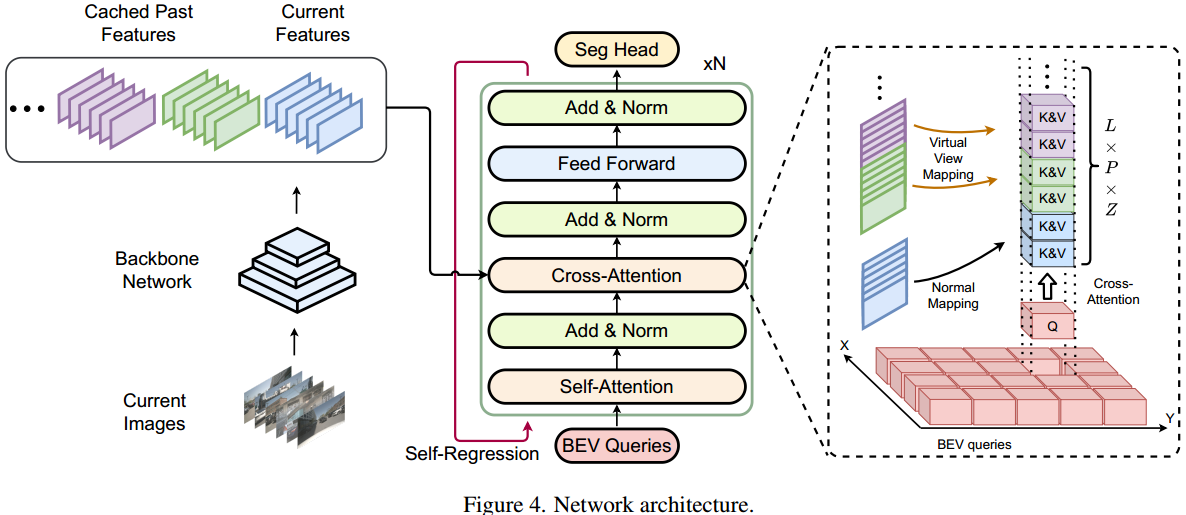
BEVFormer在自关注模块之前将扭曲的先前BEV特征与BEV查询连接起来以实现时间融合。这是性能提高的根本原因。
已有方法可以归类叫做warp-based temporal fusion,就是根据不同时刻BEV空间的位置关系,把过去时刻的BEV features 对齐(align,具体就是根据ego运动信息进行旋转、平移)到当前时刻,并与当前时刻的BEV features实施add、concat或transformer attention操作来融合形成temporal fusion BEV features。
BEV特征和查询的连接是隐式地加深和增加Transformer层的数量。
分割头
分割头是ERFNet
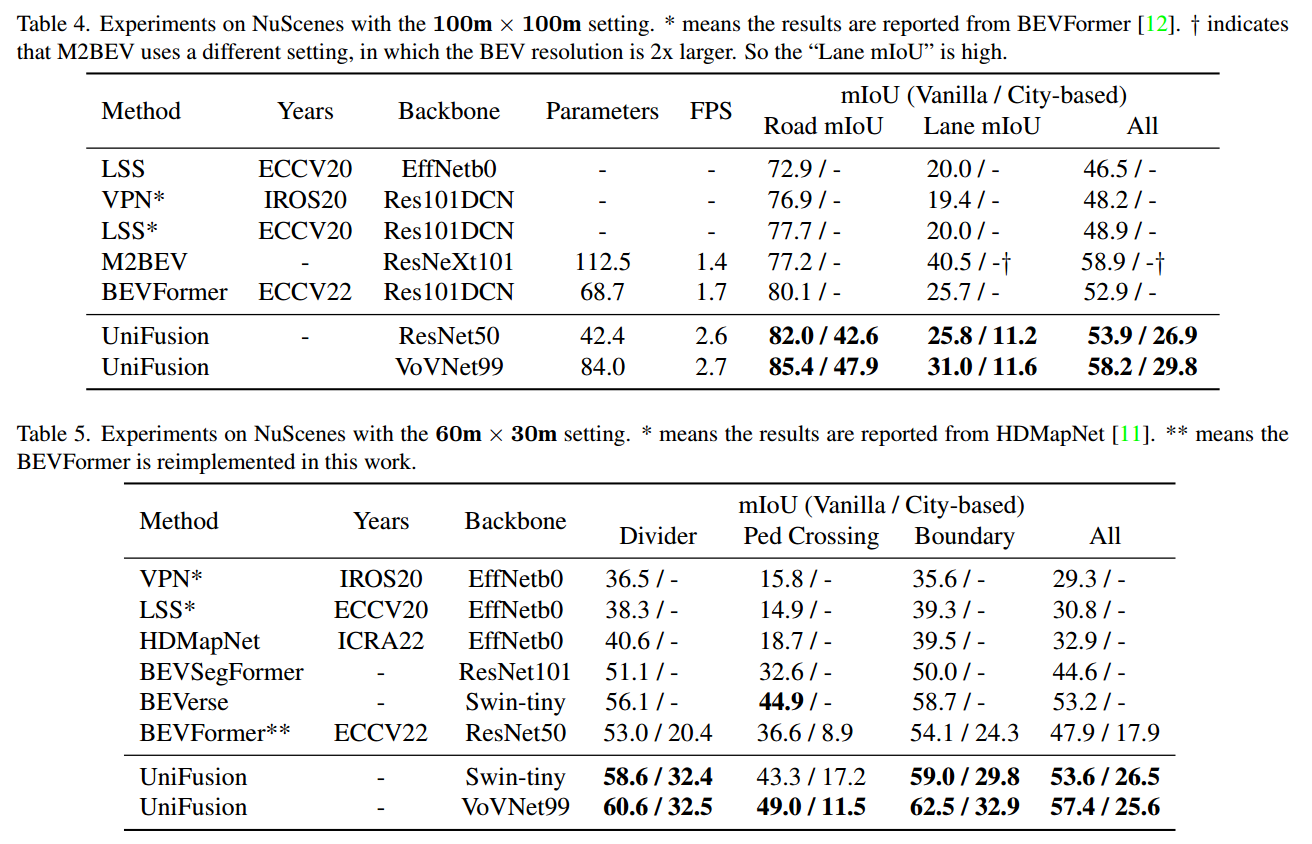
实验结果

Reference
- UniFormer:在BEV Features中融合更久远的信息
- 《UniFusion: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird’s-Eye-View》