原文首发于博客文章langchain源码阅读
本节是langchian源码阅读系列第三篇,下面进入Chain模块👇:
LLM 应用构建实践笔记
Chain链定义
链定义为对组件的一系列调用,也可以包括其他链,这种在链中将组件组合在一起的想法很简单但功能强大,极大地简化了复杂应用程序的实现并使其更加模块化,这反过来又使调试、维护和改进应用程序变得更加容易。
Chain基类是所有chain对象的基本入口,与用户程序交互,处理用户的输入,准备其他模块的输入,提供内存能力,chain的回调能力,其他所有的 Chain 类都继承自这个基类,并根据需要实现特定的功能。
class Chain(BaseModel, ABC):
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...
实现自定义链
from __future__ import annotations
from typing import Any, Dict, List, Optional
from pydantic import Extra
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.manager import (
AsyncCallbackManagerForChainRun,
CallbackManagerForChainRun,
)
from langchain.chains.base import Chain
from langchain.prompts.base import BasePromptTemplate
class MyCustomChain(Chain):
prompt: BasePromptTemplate
llm: BaseLanguageModel
output_key: str = "text"
class Config:
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]:
"""pompt中的动态变量
"""
return self.prompt.input_variables
@property
def output_keys(self) -> List[str]:
"""允许直接输出的动态变量.
"""
return [self.output_key]
# 同步调用
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, str]:
# 下面是一个自定义逻辑实现
prompt_value = self.prompt.format_prompt(**inputs)
# 调用一个语言模型或另一个链时,传递一个回调处理。这样内部运行可以通过这个回调(进行逻辑处理)。
response = self.llm.generate_prompt(
[prompt_value], callbacks=run_manager.get_child() if run_manager else None
)
# 回调出发时的日志输出
if run_manager:
run_manager.on_text("Log something about this run")
return {self.output_key: response.generations[0][0].text}
# 异步调用
async def _acall(
self,
inputs: Dict[str, Any],
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
) -> Dict[str, str]:
prompt_value = self.prompt.format_prompt(**inputs)
response = await self.llm.agenerate_prompt(
[prompt_value], callbacks=run_manager.get_child() if run_manager else None
)
if run_manager:
await run_manager.on_text("Log something about this run")
return {self.output_key: response.generations[0][0].text}
@property
def _chain_type(self) -> str:
return "my_custom_chain"
继承Chain的子类主要有两种类型:
通用工具 chain: 控制chain的调用顺序, 是否调用,他们可以用来合并构造其他的chain。
专门用途 chain: 和通用chain比较来说,他们承担了具体的某项任务,可以和通用的chain组合起来使用,也可以直接使用。有些 Chain 类可能用于处理文本数据,有些可能用于处理图像数据,有些可能用于处理音频数据等。
从 LangChainHub 加载链
LangChainHub 托管了一些高质量Prompt、Agent和Chain,可以直接在langchain中使用。
def test_mathchain():
from langchain.chains import load_chain
chain = load_chain("lc://chains/llm-math/chain.json")
"""
> Entering new chain...
2+2等于几Answer: 4
> Finished chain.
Answer: 4
"""
print(chain.run("2+2等于几"))
运行 LLM 链的五种方式
from langchain import PromptTemplate, OpenAI, LLMChain
prompt_template = "给做 {product} 的公司起一个名字?"
llm = OpenAI(temperature=0)
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
print(llm_chain("儿童玩具"))
print(llm_chain.run("儿童玩具"))
llm_chain.apply([{"product":"儿童玩具"}])
llm_chain.generate([{"product":"儿童玩具"}])
llm_chain.predict(product="儿童玩具")
通用工具chain
- MultiPromptChain:可以动态选择与给定问题最相关的提示,然后使用该提示回答问题。
- EmbeddingRouterChain:使用嵌入和相似性动态选择下一个链。
- LLMRouterChain:使用 LLM 来确定动态选择下一个链。
- SimpleSequentialChain/SequentialChain:将多个链按照顺序组成处理流水线,SimpleMemory支持在多个链之间传递上下文
- TransformChain:一个自定义方法做动态转换的链
def transform_func(inputs: dict) -> dict: text = inputs["text"] shortened_text = "\n\n".join(text.split("\n\n")[:3]) return {"output_text": shortened_text} transform_chain = TransformChain( input_variables=["text"], output_variables=["output_text"], transform=transform_func ) template = """Summarize this text: {output_text} Summary:""" prompt = PromptTemplate(input_variables=["output_text"], template=template) llm_chain = LLMChain(llm=OpenAI(), prompt=prompt) sequential_chain = SimpleSequentialChain(chains=[transform_chain, llm_chain])
合并文档的链(专门用途chain)
BaseCombineDocumentsChain 有四种不同的模式
def load_qa_chain(
llm: BaseLanguageModel,
chain_type: str = "stuff",
verbose: Optional[bool] = None,
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> BaseCombineDocumentsChain:
"""Load question answering chain.
Args:
llm: Language Model to use in the chain.
chain_type: Type of document combining chain to use. Should be one of "stuff",
"map_reduce", "map_rerank", and "refine".
verbose: Whether chains should be run in verbose mode or not. Note that this
applies to all chains that make up the final chain.
callback_manager: Callback manager to use for the chain.
Returns:
A chain to use for question answering.
"""
loader_mapping: Mapping[str, LoadingCallable] = {
"stuff": _load_stuff_chain,
"map_reduce": _load_map_reduce_chain,
"refine": _load_refine_chain,
"map_rerank": _load_map_rerank_chain,
}
StuffDocumentsChain
获取一个文档列表,带入提示上下文,传递给LLM(适合小文档)
def _load_stuff_chain(
llm: BaseLanguageModel,
prompt: Optional[BasePromptTemplate] = None,
document_variable_name: str = "context",
verbose: Optional[bool] = None,
callback_manager: Optional[BaseCallbackManager] = None,
callbacks: Callbacks = None,
**kwargs: Any,
) -> StuffDocumentsChain:

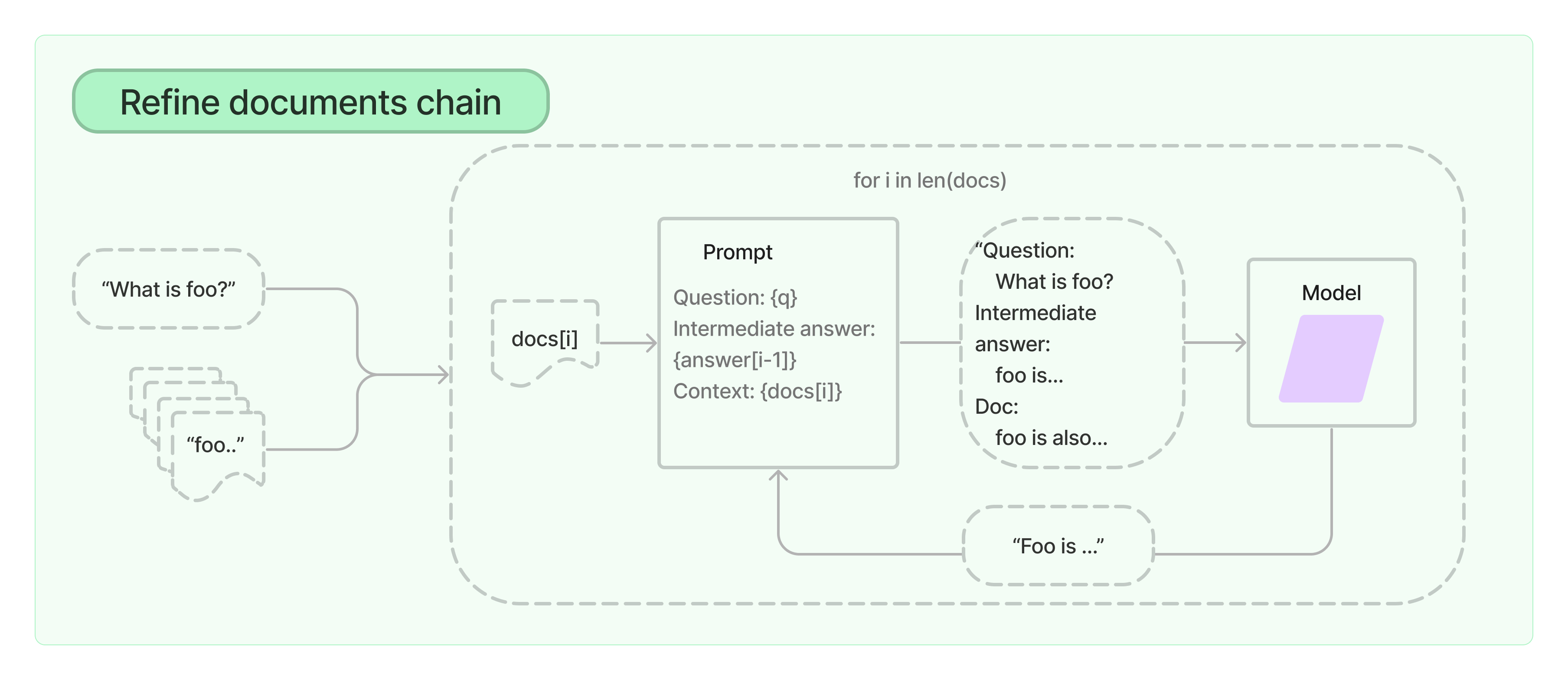
RefineDocumentsChain
在Studff方式上进一步优化,循环输入文档并迭代更新其答案,以获得最好的最终结果。具体做法是将所有非文档输入、当前文档和最新的中间答案组合传递给LLM。(适合LLM上下文大小不能容纳的小文档)
def _load_refine_chain(
llm: BaseLanguageModel,
question_prompt: Optional[BasePromptTemplate] = None,
refine_prompt: Optional[BasePromptTemplate] = None,
document_variable_name: str = "context_str",
initial_response_name: str = "existing_answer",
refine_llm: Optional[BaseLanguageModel] = None,
verbose: Optional[bool] = None,
callback_manager: Optional[BaseCallbackManager] = None,
callbacks: Callbacks = None,
**kwargs: Any,
) -> RefineDocumentsChain:
MapReduceDocumentsChain
将LLM链应用于每个单独的文档(Map步骤),将链的输出视为新文档。然后,将所有新文档传递给单独的合并文档链以获得单一输出(Reduce步骤)。在执行Map步骤前也可以对每个单独文档进行压缩或合并映射,以确保它们适合合并文档链;可以将这个步骤递归执行直到满足要求。(适合大规模文档的情况)
def _load_map_reduce_chain(
llm: BaseLanguageModel,
question_prompt: Optional[BasePromptTemplate] = None,
combine_prompt: Optional[BasePromptTemplate] = None,
combine_document_variable_name: str = "summaries",
map_reduce_document_variable_name: str = "context",
collapse_prompt: Optional[BasePromptTemplate] = None,
reduce_llm: Optional[BaseLanguageModel] = None,
collapse_llm: Optional[BaseLanguageModel] = None,
verbose: Optional[bool] = None,
callback_manager: Optional[BaseCallbackManager] = None,
callbacks: Callbacks = None,
**kwargs: Any,
) -> MapReduceDocumentsChain:

MapRerankDocumentsChain
每个文档上运行一个初始提示,再给对应输出给一个分数,返回得分最高的回答。
def _load_map_rerank_chain(
llm: BaseLanguageModel,
prompt: BasePromptTemplate = map_rerank_prompt.PROMPT,
verbose: bool = False,
document_variable_name: str = "context",
rank_key: str = "score",
answer_key: str = "answer",
callback_manager: Optional[BaseCallbackManager] = None,
callbacks: Callbacks = None,
**kwargs: Any,
) -> MapRerankDocumentsChain:

获取领域知识的链(专门用途chain)
APIChain使得可以使用LLMs与API进行交互,以检索相关信息。通过提供与所提供的API文档相关的问题来构建链。
下面是与播客查询相关的
import os
from langchain.llms import OpenAI
from langchain.chains.api import podcast_docs
from langchain.chains import APIChain
listen_api_key = 'xxx'
llm = OpenAI(temperature=0)
headers = {"X-ListenAPI-Key": listen_api_key}
chain = APIChain.from_llm_and_api_docs(llm, podcast_docs.PODCAST_DOCS, headers=headers, verbose=True)
chain.run("搜索关于ChatGPT的节目, 要求超过30分钟,只返回一条")
合并文档的链的高频使用场景举例
对话场景(最广泛)
ConversationalRetrievalChain 对话式检索链的工作原理:将聊天历史记录(显式传入或从提供的内存中检索)和问题合并到一个独立的问题中,然后从检索器查找相关文档,最后将这些文档和问题传递给问答链以返回响应。
def test_converstion():
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
loader = TextLoader("./test.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0), vectorstore.as_retriever(), memory=memory)
query = "这本书包含哪些内容?"
result = qa({"question": query})
print(result)
chat_history = [(query, result["answer"])]
query = "还有要补充的吗"
result = qa({"question": query, "chat_history": chat_history})
print(result["answer"])
基于数据库问答场景
def test_db_chain():
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
db = SQLDatabase.from_uri("sqlite:///../user.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True, use_query_checker=True)
db_chain.run("有多少用户?")
总结场景
def test_summary():
from langchain.chains.summarize import load_summarize_chain
text_splitter = CharacterTextSplitter()
with open("./测试.txt") as f:
state_of_the_union = f.read()
texts = text_splitter.split_text(state_of_the_union)
docs = [Document(page_content=t) for t in texts[:3]]
chain = load_summarize_chain(OpenAI(temperature=0), chain_type="map_reduce")
chain.run(docs)
问答场景
def test_qa():
from langchain.chains.question_answering import load_qa_chain
loader = TextLoader("./测试.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
qa_chain = load_qa_chain(OpenAI(temperature=0), chain_type="map_reduce")
qa = RetrievalQA(combine_documents_chain=qa_chain, retriever=docsearch.as_retriever())
qa.run()
参考链接
LLM 应用构建实践笔记