翻译博客:https://medium.com/pytorch/how-to-iterate-faster-in-machine-learning-by-versioning-data-and-models-featuring-detectron2-4fd2f9338df5
在本文中,您将学习如何创建和使用版本化的数据集作为可重现的机器学习流程的一部分。为了说明这一点,我们将使用Git、Docker和Quilt构建一个基于PyTorch驱动的软件系统Detectron2,该系统实现了最先进的目标检测算法,用于构建一个用于目标检测的深度神经网络。
定义可重现的模型
随着建模项目的发展,模型管道的调试、扩展和修改成本也在增加。减少模型维护成本的一种方法是通过可重现的迭代训练模型。在机器学习的上下文中,我们将可重现的模型迭代定义为一个可执行脚本的输出,该脚本是纯函数,其输入是代码、环境和数据。
model := script(code, environment, data)
给定相同的代码、环境和数据作为输入,可重现的训练脚本将始终产生相同的模型。可重现训练脚本的核心是一个以三个变量为输入的纯函数,类似于以下示例:
docker run \
-e GIT_HASH=${GIT_HASH} \
-e QUILT_HASH=${QUILT_HASH} \
YOUR/IMAGE@${DOCKER_HASH}
可重现性提高了敏捷性
可重现的模型不是目标,而是更快、更准确迭代的手段。可重现的模型历史意味着开发人员可以自信地重构任何过去的模型迭代。因此,可重现性使得开发人员更容易进行修改的实验,隔离错误,并在出现问题时回退到已知的良好迭代。
版本化数据是一个缺失的要素
您可能熟悉像Git和Docker这样的系统,分别封装了代码和环境。这些系统提供了表示时间快照的不可变哈希值。接下来,我们将介绍Quilt作为数据不可变哈希值的来源。Quilt哈希表示数据在某个时间点的快照。
用于版本控制代码的系统不适用于版本控制数据,因为数据与代码在根本上是不同的:数据通常比代码大上千倍,数据需要专门的API进行传输和序列化,并且数据需要进行探索(通过搜索、浏览和可视化)。
Quilt源代码和项目状态
Quilt是一个开源核心平台,旨在像代码一样管理数据:具有版本、包、存储库和协作工作流程。Quilt的源代码可在GitHub上找到。您可以使用quilt3 Python客户端作为独立库来创建、记录和共享数据集。可选择性地,您可以运行Quilt堆栈,它添加了一个带有搜索、文件预览和基于角色的访问控制的Web数据目录。 Quilt的开发由Quilt Data资助。
概述和先决条件
本教程分为三个部分,每个部分具有不同的要求:
- 安装版本化数据集 - 需要Python 3.6或更高版本
- 可重现地训练深度神经网络 - 需要配备GPU的机器,安装了nvidia-docker,并且至少有100GB的- 可用磁盘空间。为了快速训练时间,可以考虑配备八个V100 GPU的实例。
- 共享和记录自定义数据集 - 需要Python 3.6或更高版本,quilt3(pip install quilt3),以及配置了AWS CLI的Amazon S3存储桶。要尝试使用S3,可以注册AWS免费套餐。
注意:本文中提到的机器实例类型可能会产生较大的云服务提供商费用。根据需要调整示例的规模。
使用quilt3安装版本化数据集
下载大型数据集通常依赖于脆弱的脚本和缓慢或不可靠的数据存储。quilt3提供了一个简化的界面,用于构建、安装和与数据集交互。例如,您可以使用quilt3安装常见的上下文对象(COCO)数据集。首先安装quilt3:
pip install quilt3
您需要至少22GB的可用磁盘空间来安装COCO数据集。如果您计划在接下来的部分中训练Detectron2,则无需运行以下代码。以下是使用quilt3安装COCO的方法
cv/coco2017是数据集的名称
- –top-hash是一个SHA-256摘要,由quilt3自动计算,用于指定感兴趣的版本
- –dest是将数据复制到本地磁盘的目录
- –registry指定数据包所在的位置,通常是一个S3存储桶
如果您想尝试一个较小的数据集(1.1MB),可以尝试quilt/altair:
quilt3 install quilt/altair \
--registry s3://quilt-example \
--dest ./YOUR/DIR/
有关使用quilt3构建自己的数据集的详细信息,请参阅下面的"共享和记录自定义数据集"部分。
可选:验证数据集
在训练之前,您可能希望确保您本地的数据集副本没有发生变化:
quilt3 verify计算数据集中每个文件的SHA-256哈希值。在具有4个vCPU和16 GiB内存的实例上验证cv/coco2017大约需要两分半钟。
quilt3 verify cv/coco2017 \
--top-hash 3722a4 \
--dir ./datasets/coco2017 \
--registry s3://quilt-ml
quilt3 verify会计算数据集中每个文件的SHA-256哈希值。在具有4个vCPU和16 GiB内存的实例上验证cv/coco2017大约需要两分半钟。
可重现地训练深度神经网络:在COCO上使用Detectron2
有多种方法可以结合Git、Docker和Quilt进行可重现的训练。以下是一个示例。我们定义了我们的代码、环境和数据的哈希值,然后拉取一个Docker镜像(quiltdata/pytorch-detectron2-demo),然后运行训练任务:
# define hashes
GIT_HASH=0a7a9d10
QUILT_HASH=3722a498
DOCKER_HASH=sha256:8d12a8997c6f65923f7e7788f70f70134b5f845ddcba5570beb5182c18d2526e
# pull image
DOCKER_IMAGE=quiltdata/pytorch-detectron2-demo@${DOCKER_HASH}
docker pull ${DOCKER_IMAGE}
# run image (interactively for illustration)
nvidia-docker run -it \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--shm-size=8gb \
# Optional: mount a volume (be sure to clone detectron2 there)
# --volume /YOUR/DIR/:/io \
-e GIT_HASH=${GIT_HASH} \
-e QUILT_HASH=${QUILT_HASH} \
${DOCKER_IMAGE}
## clone and install detectron2
git clone https://github.com/facebookresearch/detectron2
cd detectron2
git checkout ${GIT_HASH}
### "Running setup.py develop for detectron2" takes several minutes
pip install -e .
## install data
quilt3 install cv/coco2017 \
--registry=s3://quilt-ml \
--dest=./datasets/coco/ \
--top-hash=${QUILT_HASH}
## train
python tools/train_net.py \
--num-gpus 8 \
--config-file \
configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml
版本控制和加载训练好的模型
为了完全实现可重现性,我们将在容器内运行脚本来保存训练好的模型:
import os
import quilt3
model_pkg = quilt3.Package()
# capture all logs and checkpoints from /output
model_pkg.set_dir(".", "./detectron2/output/")
model_pkg.push(
"detectron2-trained-models/mask_rcnn_R_50_FPN_1x",
registry="s3://YOUR-S3-BUCKET",
message=(
f"detectron2@{os.environ.get('GIT_HASH')}, "
f"trained in quiltdata/pytorch-detectron2-demo@{os.environ.get('DOCKER_HASH')}, "
f"on cv/coco2017@{os.environ.get('QUILT_HASH')}"
)
)
现在,我们已经将模型保存到Quilt中,协作者可以加载过去的模型,包括它们的检查点和日志,用于推断、审计和调试:
quilt3 install detectron2-trained-models/mask_rcnn_R_50_FPN_1x \
--registry=s3://quilt-ml \
--dest=/detectron2/models/mask_rcnn_R_50_FPN_1x/ \
--top-hash=6e830aa5
cd /detectron2
python tools/train_net.py \
--config-file ./configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
--eval-only MODEL.WEIGHTS \
models/mask_rcnn_R_50_FPN_1x/model_final.pth
python demo/demo.py \
--config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
--input YOUR_INPUT_1.jpg YOUR_INPUT_2.jpg \
--opts MODEL.WEIGHTS \
models/mask_rcnn_R_50_FPN_1x/model_final.pth
从quilt3加载数据到PyTorch
Detectron2提供了自己的代码路径来加载COCO数据集。对于自定义数据集,你可以使用torchvision的DatasetFolder,或者你可以子类化torch的Dataset:
from torch.utils.data import Dataset
class ExamplePyTorchDataset(Dataset):
def __init__(self, quilt_package_name, registry, pkg_hash=None):
# insert your own package here
pkg = quilt3.Package.browse(
"quilt/coco2017",
registry="s3://quilt-ml",
top_hash="3722a4"
)
# only return files in the train/ directory
self.img_entries = [
e for l, e in pkg.walk()
if l.startswith("train/")
]
def __len__(self):
return len(self.img_entries)
def __getitem__(self, idx):
entry = self.img_entries[idx]
img_annotations = entry.meta["annotations"]
return {
"image": entry.get_bytes(),
"annotations": img_annotations
}
在你的Dataset子类中使用quilt3的API相比原始的Python代码具有几个优势,包括缓存、版本控制和网络和存储的抽象,这些都可以导致更简洁和可靠的训练脚本。
为了提高性能,你可以利用torch的DataLoader。有关详细信息,请参阅编写自定义Dataset、DataLoader和Transforms。
分享和记录自定义数据集
构建自己的版本化数据集的最简单方法是将本地目录的内容快照到Quilt包中:
p = quilt3.Package()
# snapshot a directory into package root
p.set_dir(".", "./your/local/dataset/")
以更具体的例子为例,让我们构建、记录和分享一个自定义的COCO子集,其中只包含动物的图像。我们首先使用quilt3 browse加载现有COCO包的轻量级表示:
coco = quilt3.Package.browse(
"quilt/coco2017",
registry="s3://quilt-ml",
top_hash="3722a4"
)
browse只加载包的清单到内存中。清单是一种类似目录结构的小型键值存储:
(remote Package)
└─annotations/
└─captions_train2017.json
└─captions_val2017.json
└─instances_train2017.json
└─instances_val2017.json
└─person_keypoints_train2017.json
└─person_keypoints_val2017.json
└─train2017/
...
包清单中的每个条目都有一个逻辑键(用户友好的路径)、一个物理键(指向字节的URI)和可选元数据(消除了与外部注释文件的处理需求)。我们可以使用方括号表示法访问包条目。例如,coco[“train2017”][“000000000009.jpg”].meta会返回一个字典:
{
'image_info': {
'license': 3,
'file_name': '000000000009.jpg',
'coco_url': 'http://images.cocodataset.org/train2017/000000000009.jpg',
'height': 480,
'width': 640,
'date_captured': '2013-11-19 20:40:11',
'flickr_url':
'http://farm5.staticflickr.com/4026/4622125393_84c1fdb8d6_z.jpg',
'id': 9
},
'annotations': [...]
}
我们可以使用Quilt包条目的.meta属性将COCO过滤为只包含动物图像:
coco_animals = coco.filter(
lambda l, e: l.endswith(".jpg") and
"animal" in (a["supercategory"] for a in e.meta["annotations"])
)
filter接受一个带有两个参数的lambda函数,即logical_key和entry。
作为最佳实践,我们将在coco_animals中添加一个README文件,以便其他开发人员有足够的上下文来使用我们的新数据集:
coco_animals.set("README.md", "./YOUR/DIR/README.md")
现在,我们可以将coco_animals推送到S3,以便在具有读取父S3存储桶权限的任何人都可以访问云端托管的数据集副本
coco_animals.push(
# 填入你的详细信息
"USERNAME/DATASET_NAME",
registry="s3://YOUR_S3_BUCKET",
message="Experimental subset of COCO 2017"
)
推送数据集到S3后,你的同事可以使用quilt3.list_packages()来发现数据集。使用quilt3 catalog来浏览数据集的内容:
quilt3 catalog s3://quilt-example/akarve/coco_animals/
例如,我们可以点击train2017目录来确保coco_animals确实包含动物的图片。
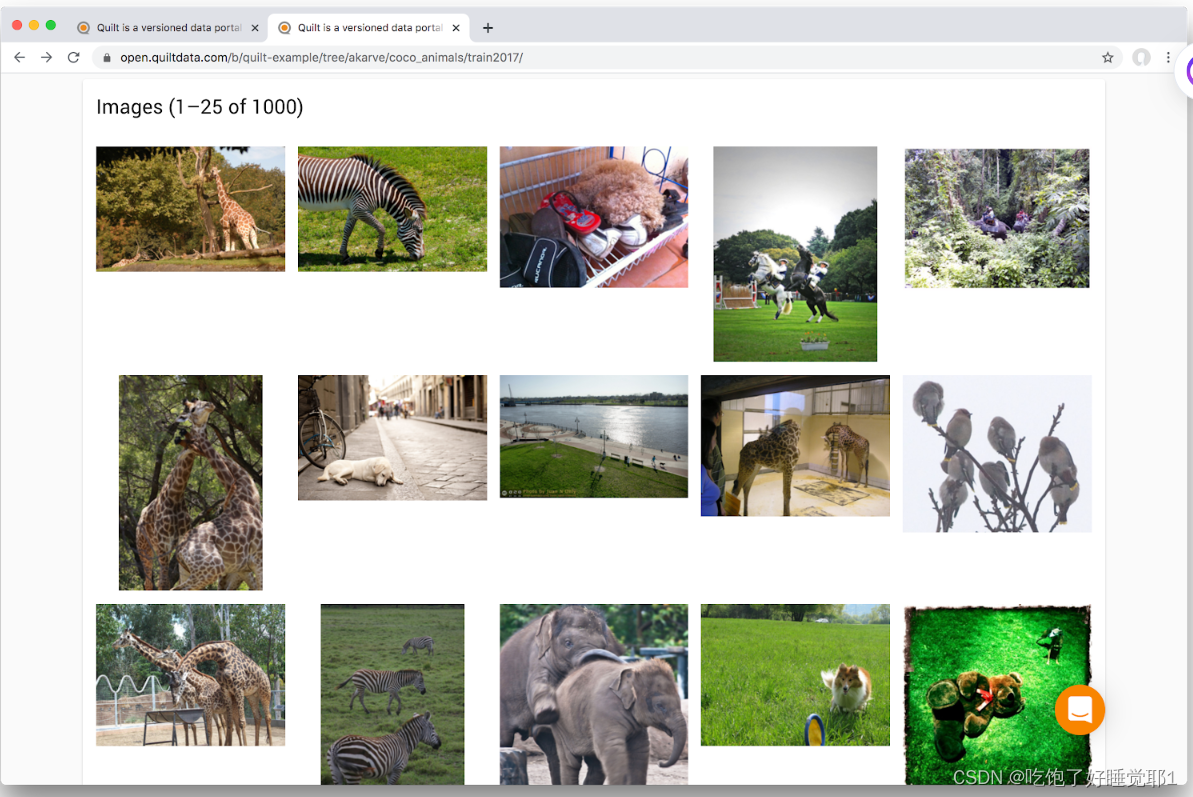
图1 - 在Quilt目录中查看COCO图片
Quilt目录生成大文件的轻量级、与浏览器兼容的预览,如Jupyter笔记本、Parquet表、Vega-Lite可视化、图像等。
quilt3 catalog命令只推荐用于开放数据。对于敏感数据,请运行一个私有的Quilt堆栈,它将数据限制在你的虚拟私有云中。
前面我们提到,quilt3.browse()加载的是轻量级清单,而不是实际数据。当我们准备使用实际数据时,可以使用quilt3的get方法进行延迟获取。例如,如果你想在Jupyter中呈现README文件的内容,可以调用get_as_string:
from IPython.display import display, Markdown
display(
Markdown(
coco_animals["README.md"].get_as_string()
)
)
结论和如何贡献
我们演示了如何通过可重现的训练脚本提高模型迭代的速度和正确性。我们还介绍了Quilt作为版本化数据集的系统。
向社区贡献数据集
如果你有一个有趣的公共数据集要分享,我们鼓励你申请在open.quiltdata.com上管理数据集,那里可以免费托管大型公共数据集。
向Quilt贡献代码
Quilt团队正在积极开发用于管理数据的规模、性能和云原生工具,类似于代码。欢迎贡献代码。请访问Quilt的路线图、文档和Slack频道以了解更多信息。Quilt的路线图强调了Python、Parquet、MinIO和无服务器函数等技术领域。