基本架构:一个键值数据库包含什么?
这样学 Redis,才能技高一筹
- 为了保证数据的可靠性,Redis 需要在磁盘上读写 AOF 和 RDB,但在高并发场景里,这就会直接带来两个新问题:
- 一个是写 AOF 和 RDB 会造成 Redis 性能抖动;
- 另一个是 Redis 集群数据同步和实例恢复时,读 RDB 比较慢,限制了同步和恢复速度。
- 其实,一个可行的解决方案就是使用非易失内存 NVM,因为它既能保证高速的读写,又能快速持久化数据。
- 很多技术人都有一个误区,那就是,只关注零散的技术点,没有建立起一套完整的知识框架,缺乏系统观,但是,系统观其实是至关重要的。
- 比如,要把 Redis 的长尾延迟维持在⼀定阈值以下:
- 首先对 Redis 的线程模型做分析,对于单线程的 Redis 而言,任何阻塞性操作都会导致长尾延迟的产生。
- 接着开始寻找可能导致阻塞的关键因素,一开始想到的是网络阻塞,但 Redis 使用了 IO 多路复用机制,并不会阻塞在单个客户端上。
- 再后来,主要把目光转向了键值对数据结构、持久化机制下的 fork 调用、主从库同步时的 AOF 重写,以及缓冲区溢出等多个方面。
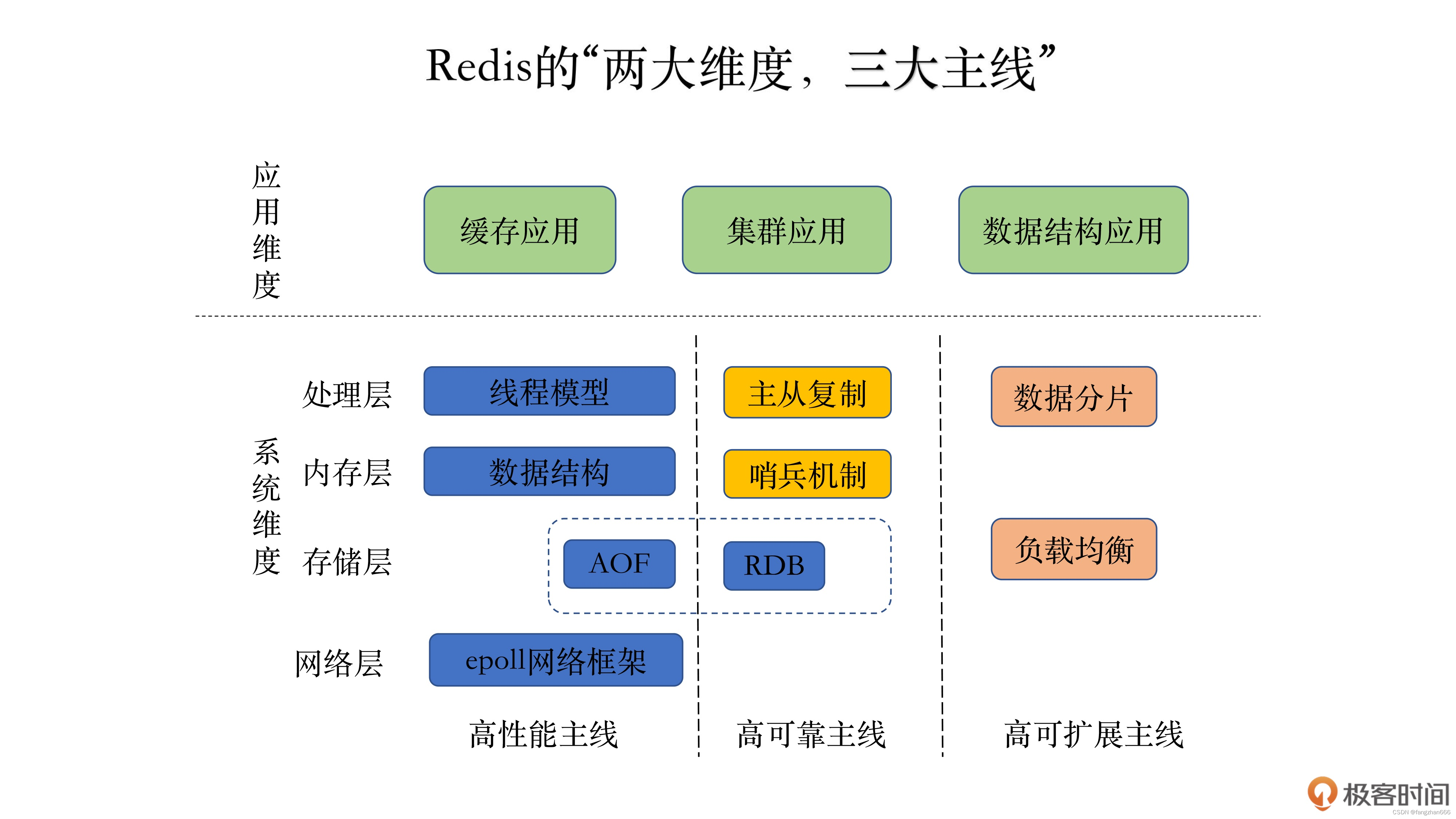
- 如何高效地形成系统观呢?
- 只要你能抓住主线,在自己的脑海中绘制一幅 Redis 全景知识图,这完全是可以实现的。
- Redis 知识全景图包括“两大维度,三大主线”。“两大维度”就是指系统维度和应用维度,“三大主线”也就是指高性能、高可靠和高可扩展。
- 比如,要把 Redis 的长尾延迟维持在⼀定阈值以下:
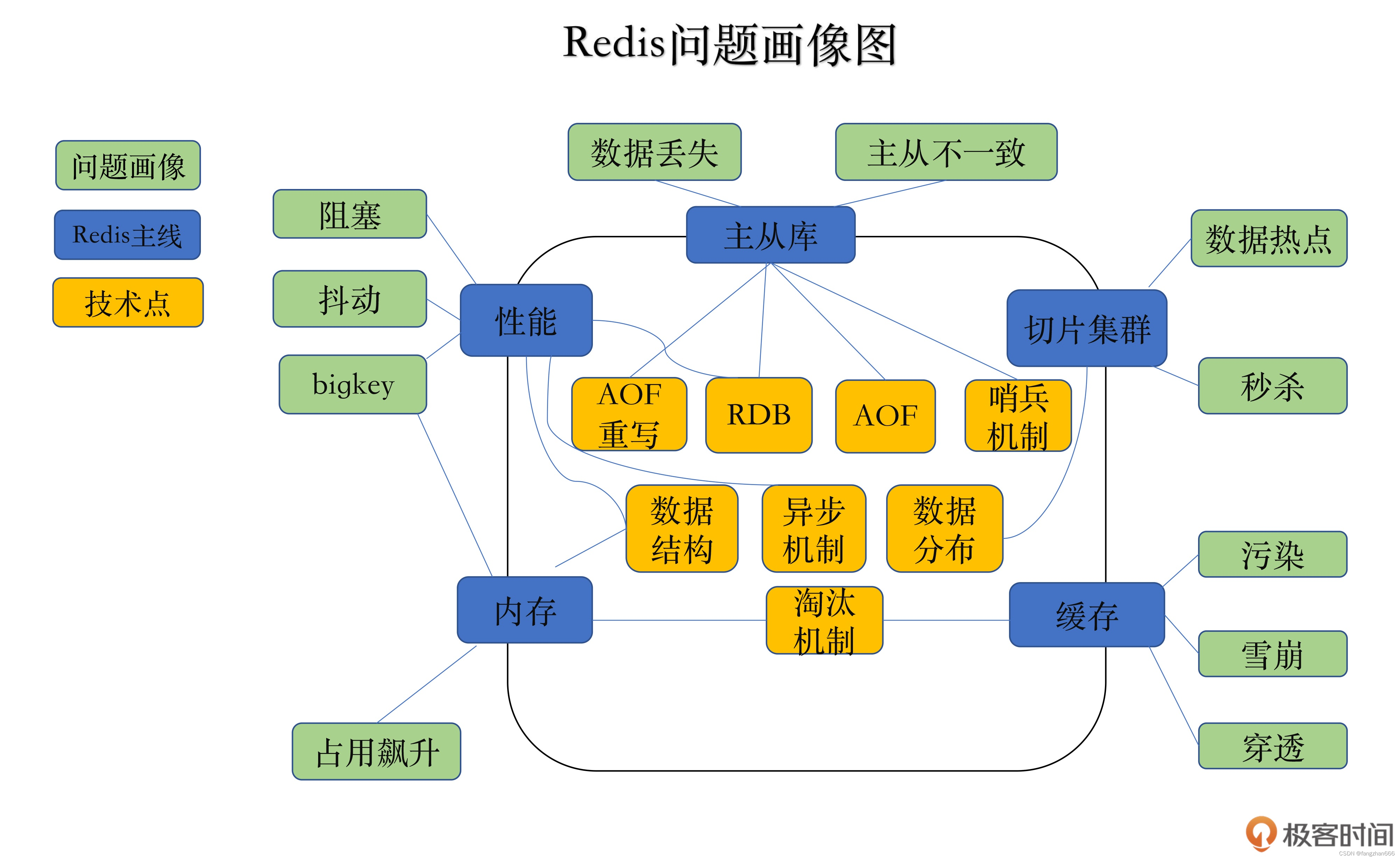
- Redis 的各大典型问题
构建一个简单的键值数据库
可以存哪些数据?
- 对于键值数据库而言,基本的数据模型是 key-value 模型。
- 不同键值数据库支持的 key 类型一般差异不大,而 value 类型则有较大差别。
- 我们在对键值数据库进行选型时,一个重要的考虑因素是它支持的 value 类型。
- 例如,Memcached 支持的 value 类型仅为 String 类型,而 Redis 支持的 value 类型包括了 String、哈希表、列表、集合等。
- Redis 能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的 value。
可以对数据做什么操作?
- SimpleKV 需要支持 3 种基本操作,即 PUT、GET 和 DELETE。
- PUT:新写入或更新一个 key-value 对;
- GET:根据一个 key 读取相应的 value 值;
- DELETE:根据一个 key 删除整个 key-value 对。
- 在实际的业务场景中,我们经常会碰到这种情况:查询一个用户在一段时间内的访问记录。
- 这种操作在键值数据库中属于 SCAN 操作,即根据一段 key 的范围返回相应的 value 值。
- 因此,PUT/GET/DELETE/SCAN 是一个键值数据库的基本操作集合。
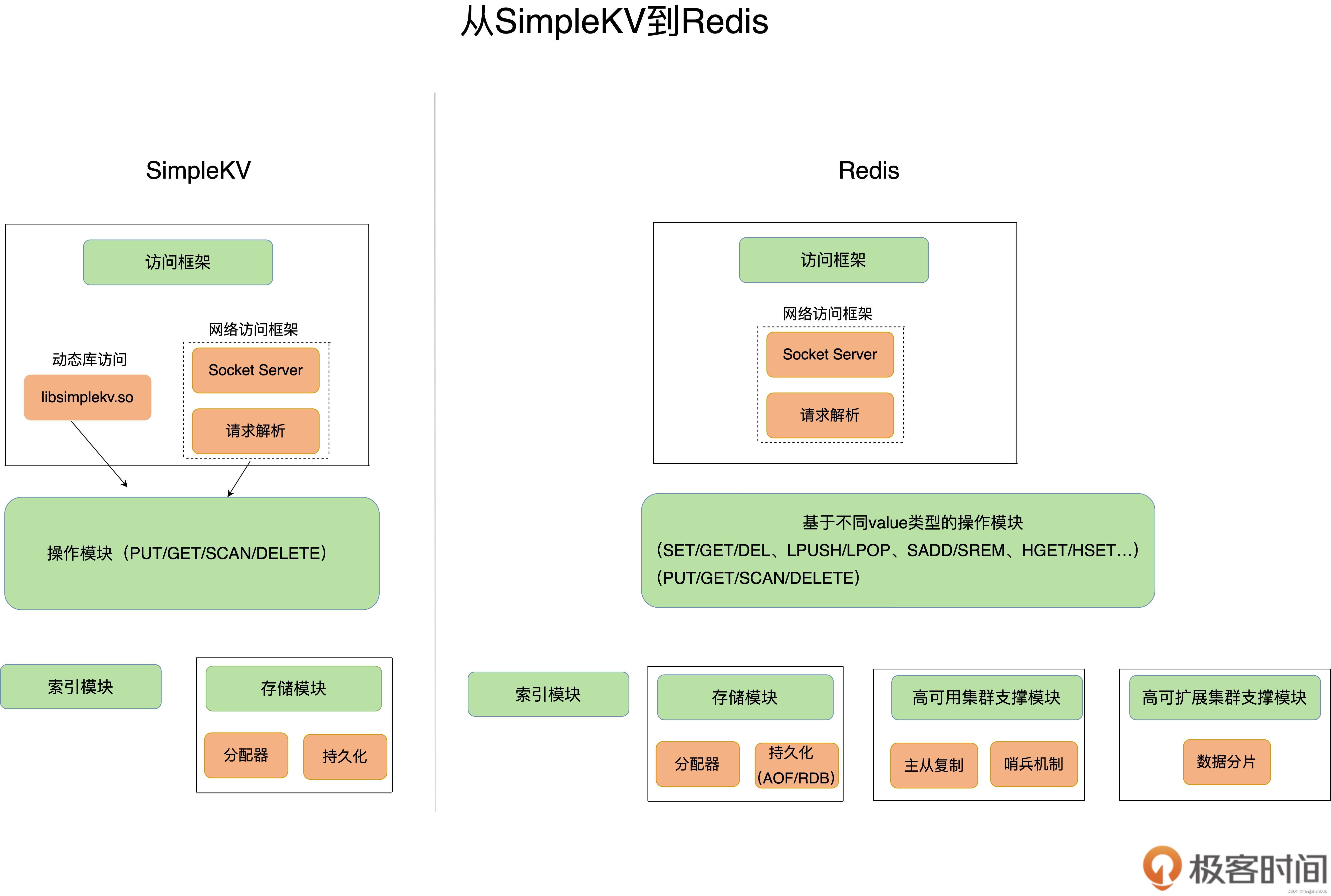
- 大体来说,一个键值数据库包括了访问框架、索引模块、操作模块和存储模块四部分:
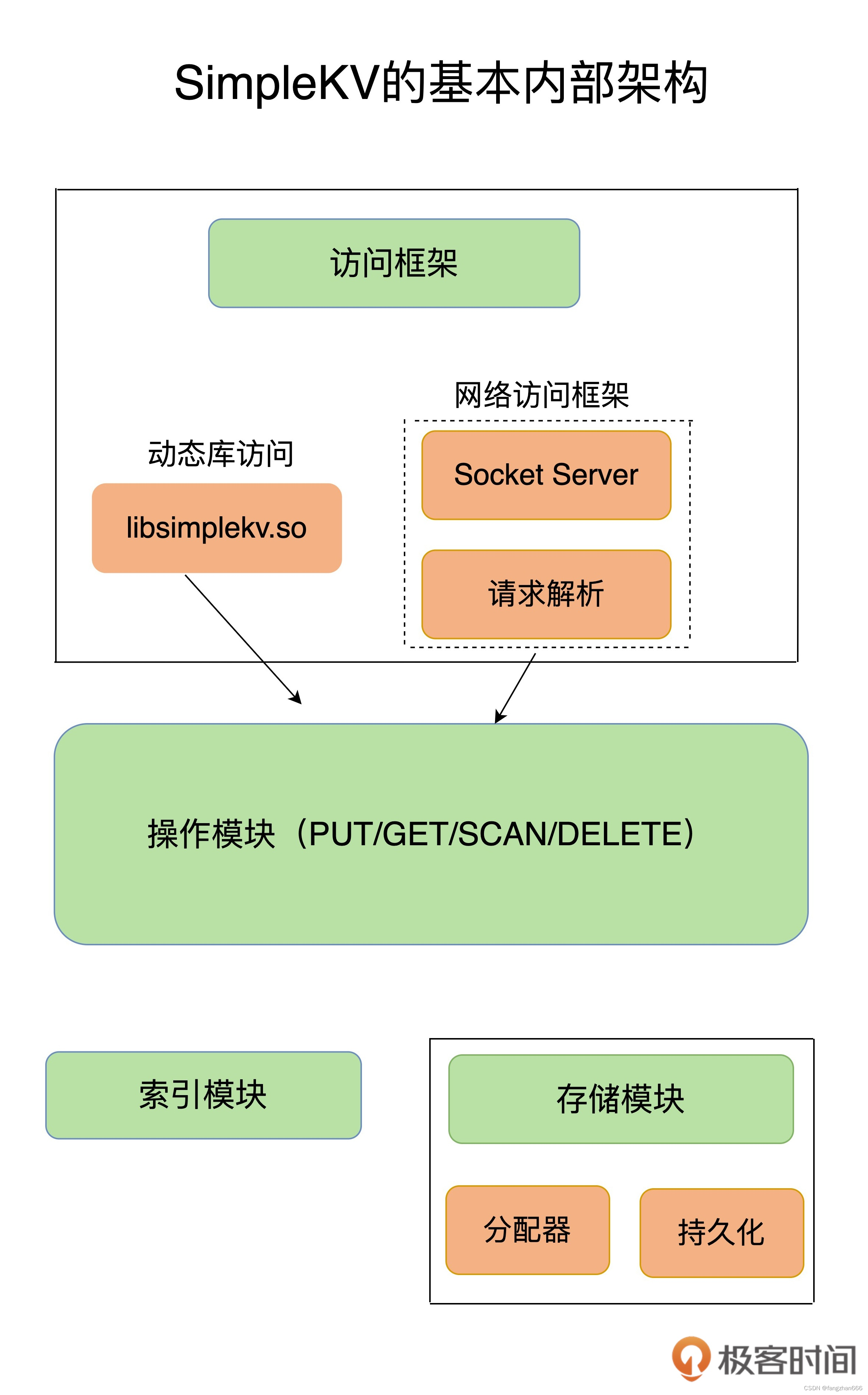
采用什么访问模式?
- 访问模式通常有两种:
- 一种是通过函数库调用的方式供外部应用使用,就是以动态链接库的形式链接到我们自己的程序中,提供键值存储功能;
- 另⼀种是通过网络框架以 Socket 通信的形式对外提供键值对操作,这种形式可以提供广泛的键值存储服务。
- 实际的键值数据库也基本采用上述两种方式,例如 RocksDB 以动态链接库的形式使用,而 Memcached 和 Redis 则是通过网络框架访问。
如何定位键值对的位置?
- 索引的作用是让键值数据库根据 key 找到相应 value 的存储位置,进而执行操作。
- Memcached 和 Redis 采用哈希表作为 key-value 索引,而 RocksDB 则采用跳表作为内存中 key-value 的索引。
不同操作的具体逻辑是怎样的?
- SimpleKV 的操作模块就实现了不同操作的具体逻辑:
- 对于 GET/SCAN 操作而言,此时根据 value 的存储位置返回 value 值即可;
- 对于 PUT 一个新的键值对数据而言,SimpleKV 需要为该键值对分配内存空间;
- 对于 DELETE 操作,SimpleKV 需要删除键值对,并释放相应的内存空间,这个过程由分配器完成。
如何实现重启后快速提供服务?
- SimpleKV 采用了常用的内存分配器 glibc 的 malloc 和 free,因此,SimpleKV 并不需要特别考虑内存空间的管理问题。Redis 的内存分配器提供了多种选择,分配效率也不一样。
- 鉴于磁盘管理要比内存管理复杂,SimpleKV 就直接采用了文件形式,将键值数据通过调用本地文件系统的操作接口保存在磁盘上。
- 此时,SimpleKV 只需要考虑何时将内存中的键值数据保存到文件中就可以了。
- 和 SimpleKV 一样,Redis 也提供了持久化功能。不过,为了适应不同的业务场景,Redis 为持久化提供了诸多的执行机制和优化改进。