文章目录
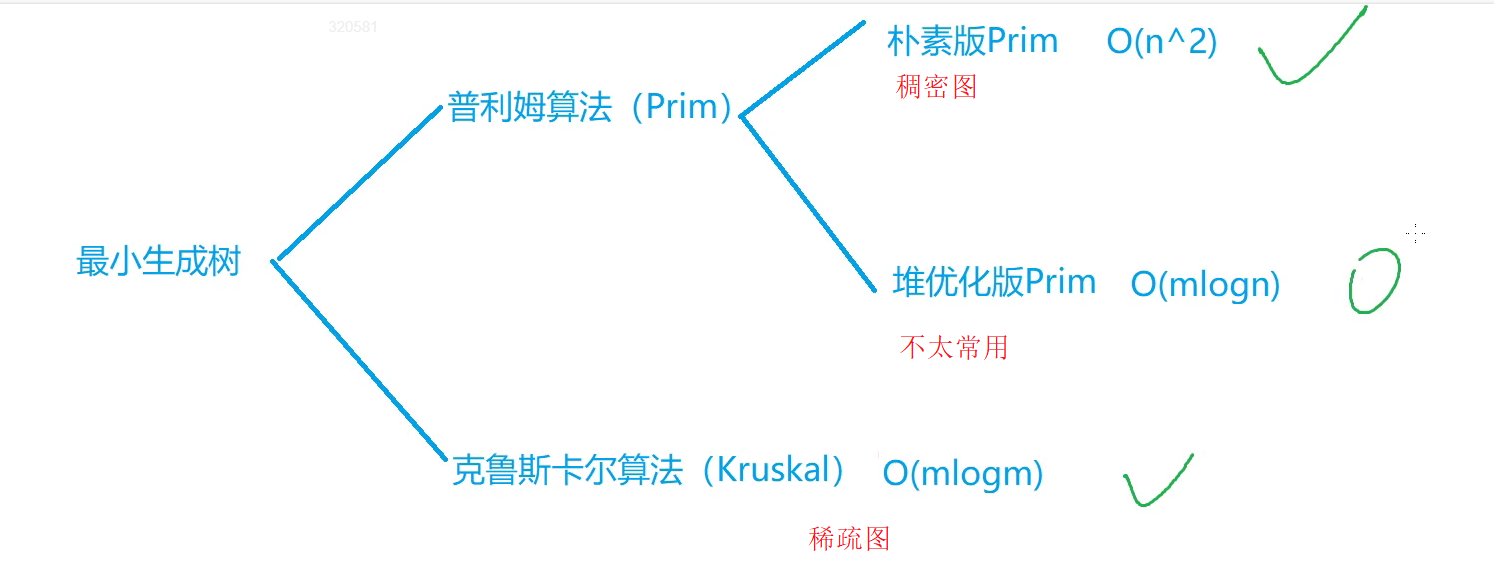
- 最小生成树
- Prim
- Kruskal
- 二分图
- 染色法
- 匈牙利算法
- 最小生成树练习题
- 858. Prim算法求最小生成树
- 859. Kruskal算法求最小生成树
- 二分图练习题
- 860. 染色法判定二分图
- 861. 二分图的最大匹配
最小生成树
最小生成树针对无向图,有向图不会用到
Prim
求解稠密图的最小生成树
和Dijkstra的思想相似,两者都是基于贪心
区别在于Dijkstra求单源最短路,而Prim求最小生成树
最小生成树:用最少的边连通图中所有的点,使得这些边的权值和也最小
Prim中的dis数组含义:点到集合的最短距离,注意与Dijkstra对比,不是点到源点的最短距离!
外循环迭代n次,每次选择一个点加入集合
也可以理解为迭代n次,每次选择一条与集合距离最短的边加入集合,不过第一次迭代无法选择边,只能随便选一个点作为集合中的元素,后续的迭代就是选择边(选择一条边,连接集合内的点与集合外的点,并且该边的权值最小)
选择完一个点后,更新集合外的点到集合的距离
由于新的点加入了集合,连接集合内外点的边发生了变化,需要更新dis数组,使集合外的点到集合的距离最小
总结下:
- 迭代n次
- 根据
dis数组每次选择一个与集合距离最近的点 - 用该点更新
dis数组
由于要求最小生成树,所以迭代的过程中用res记录最小生成树的权值和
当找不到距离集合最近的点时(距离为正无穷),退出迭代,因为无法找到最小生成树
模板:
const int INF = 0x3f3f3f3f;
int g[N][N], dis[N], st[N];
int prim()
{
memset(dis, 0x3f, sizeof(dis));
int res = 0;
for (int i = 0; i < n; ++ i )
{
int t = -1;
for (int j = 1; j <= n; ++ j)
if (!st[j] && (t == -1 || dis[j] < dis[t])) t = j;
if (i && dis[t] == INF) return INF;
if (i) res += dis[t];
st[t] = true;
for (int j = 1; j <= n; ++ j )
dis[j] = min(dis[j], g[t][j]);
}
return res;
}
用堆优化prim算法,可以求解稀疏图的最小生成树。不过稀疏图的最小生成树有更优的解法——Kruskal
Kruskal
求解稀疏图的最小生成树
- 将所有边按权值从小到大排序
- 枚举每条边,x,y,d ,若两点位于不同的集合,合并两集合(选择这条边)
1为该算法的效率瓶颈,时间复杂度为O(logn),2的时间复杂度为 O(m)
开始时每个点自成集合(可以理解为连通块),贪心地选择权值最小且连接两个连通块的边,直到边的数量为n - 1(点的数量 - 1),最小生成树构造完成
其中:合并集合与查找某个元素所在集合的操作为并查集的基本操作,很简单
不需要用邻接矩阵或邻接表存储边,直接用结构体存储边,简单且方便排序。重载该结构体的小于运算符,按照权值进行小于比较
const int INF = 0x3f3f3f3f;
int p[N];
struct Edge
{
int x, y, w;
bool operator<(const Edge& e)
{
return w < e.w;
}
}edges[M];
int find(int x)
{
if (x != p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; ++ i ) p[i] = i;
int x, y, w;
int cnt = 0, res = 0;
for (int i = 0; i < m; ++ i )
{
auto t = edges[i];
x = t.x, y = t.y, w = t.w;
x = find(x), y = find(y);
if (x != y)
{
res += w;
cnt ++ ;
p[x] = y;
}
}
if (cnt == n - 1) return res;
return INF;
}
二分图

二分图:将所有点划分成两个集合,使得所有边连接两个集合,即集合内没有边
一个图是二分图,当且仅当图中不含奇数环
图中不含有奇数环,那么图是二分图
必要性:遍历一个奇数环,假设起点属于集合A,那么下一个点一定属于集合B,下一个点一定属于集合A…这样推导到最后,结果是起点属于集合B,与二分图的性质矛盾
充分性:由于图中不不存在奇数环,所以染色过程不会出现矛盾,那么所有的点都能正确染色,使点集被分为两个集合
反证法:假设染色过程出现了矛盾,能否推出图中一定含有奇数环?
染色法
判断二分图
通过深搜或者广搜将每个点染上颜色
出现矛盾,不是二分图
不出现矛盾,就是二分图
维护一个color数组,由于需要染两种颜色,用1和2表示这两种颜色,0表示该点为染色
从任意一个点开始进行染色,染色的过程是一个dfs。先对当前点染色,若下一个要遍历的点未染色,那么染上和当前点相反的颜色。然后需要判断这个递归是否出现矛盾,若出现矛盾返回false
若下一个要遍历的点染色了,判断其颜色是否和当前点相同,若相同则说明该图不是一个二分图,返回false
dfs最后返回true
由于需要判断的图可能是非连通图,所以需要遍历每一个点,若当前点没有染色,则将其作为dfs的起点进行染色
模板:
bool dfs(int x, int c) // x表示点的编号,c表示要染的颜色
{
color[x] = c;
for (int i = h[x]; i != -1; i = ne[i])
{
int y = e[i]; // 获取下一点的编号
if(!color[j])
{
if (!dfs(y, 3 - c)) // 3 - c将1变成2,2变成1,也就是相反颜色
return false;
}
else if(color[j] == c) return false;
}
return true;
}
bool flag = true;
for (int i = 1; i <= n; ++ i )
{
if (!color[i])
{
if (!dfs(i, 1))
{
flag = false;
break;
}
}
}
if (flag == false) // 不是二分图
else // 是二分图
匈牙利算法
二分图的最大匹配
在二分图中求子图,子图中不存在邻接两条边的点,即两点通过一条边匹配
对于二分图的两个顶点集合,假设为n1和n2
遍历n1的所有点,对于每个点,遍历邻接该点的所有边
- 若另外一点未匹配,则选择该点,匹配成功
- 若另外一点已经匹配,试着让其匹配的对象匹配其他点
- 若其匹配的对象能够匹配其他点,那么两点匹配成功
- 若其匹配的对象无法匹配其他点,那么两点匹配失败
时间复杂度为O(nm),这是最坏情况,一般情况下是线性复杂度
以上操作中,匹配是一个相同子问题,所以总问题可以用匹配这个子问题分解
对于逻辑中的一些细节:
遍历点的所有邻边时,需要注意对方是否已经匹配,这里用match数组表示对方已经匹配的点,默认值为0(没有0号点)表示还未匹配
当对方已经匹配,此时要看对方的匹配对象是否能匹配其他点。也就是假设对方已经和自己匹配,判断对方的匹配对象在不选择对方的情况下,是否能匹配成功
所以这里需要一个状态表示对方已经和自己匹配的假设,用st数组表示当前点正在考虑或考虑完成某点。每次遍历某点的邻边时,先设置st数组,以表示自己正在考虑对方
接着会出现两种情况:
- 对方没有匹配,此时和对方匹配成功
- 对方已经匹配,对方的匹配对象需要在不考虑对方的情况下,试着匹配其他点。不考虑对方的前提通过
st数组限制,对方的匹配对象每次匹配前通过st数组判断试着匹配的对象是否被考虑,正在被考虑的点无法被匹配
- 当前点试着匹配对方时,可能匹配成功,可能匹配失败。匹配失败的情况下,
st数组对应位置表示该点被考虑完成(已经无法匹配),后续不需要再考虑该点了
考虑和匹配是两个不同的概念,两者无法等价
已经被匹配的情况下,可以让对方的匹配对象重新匹配。若对方的匹配对象重新匹配失败,此时考虑完成,对方真的无法匹配
然后试着匹配下一条邻边的对象,若对方的匹配对象需要重新匹配,那么他就不应该试着匹配已经考虑完成的点
考虑完成的点一定无法匹配,虽然考虑完成分为匹配成功与匹配失败两种情况,但是匹配成功后,st数组失去了意义(此时要匹配n1的下一个点),因为该数组要被重置
只有无法匹配的情况下,考虑完成的点(st数组)才有意义,因为它将限制其他点的匹配与重新匹配。因此这时的st数组的含义变成了:该点是否被强绑定(该点的对象无法匹配其他点了,此时两点只能绑定在一起)
匹配下一个n1中点的对象时,将st数组被重置为false,表示n2中所有的点未被考虑过
虽然是无向图,但是我们只要存储n1到n2的边, n2到n1的边没必要存
模板:
int h[N], e[N], ne[N], idx = 1;
bool st[N];
int match[N];
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
最小生成树练习题
858. Prim算法求最小生成树
858. Prim算法求最小生成树 - AcWing题库
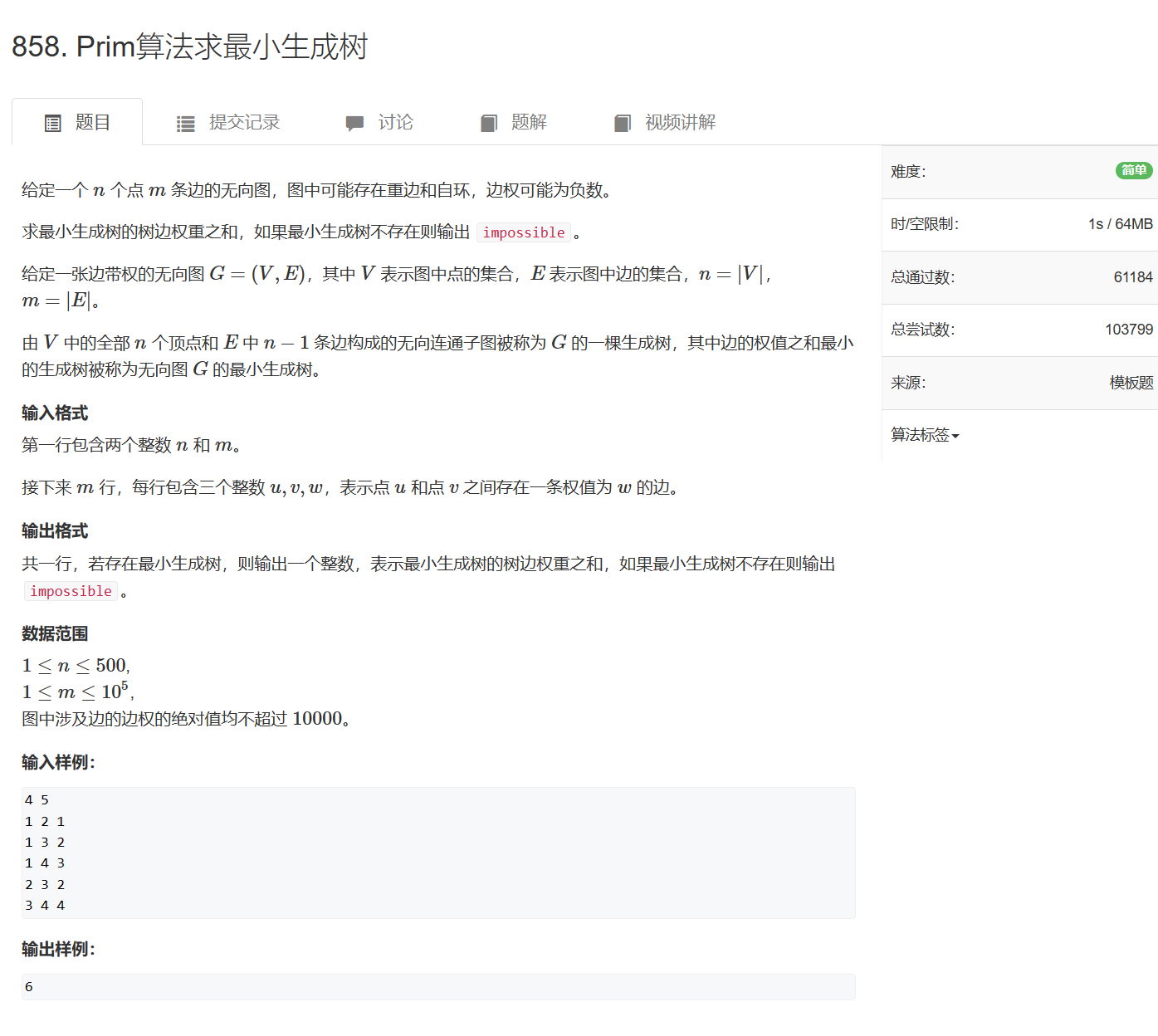
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int INF = 0x3f3f3f3f;
int g[N][N], dis[N];
bool st[N];
int n, m;
int prim()
{
memset(dis, 0x3f, sizeof(dis));
int res = 0;
for (int i = 0; i < n; ++ i )
{
int t = -1;
for (int j = 1; j <= n; ++ j)
if (!st[j] && (t == -1 || dis[j] < dis[t])) t = j;
if (i && dis[t] == INF) return INF;
if (i) res += dis[t];
st[t] = true;
for (int j = 1; j <= n; ++ j )
dis[j] = min(dis[j], g[t][j]);
}
return res;
}
int main()
{
memset(g, 0x3f, sizeof(g));
scanf("%d%d", &n, &m);
int x, y, d;
while (m -- )
{
scanf("%d%d%d", &x, &y, &d);
g[x][y] = g[y][x] = min(g[x][y], d);
}
int t = prim();
if (t == INF) puts("impossible");
else printf("%d\n", t);
return 0;
}
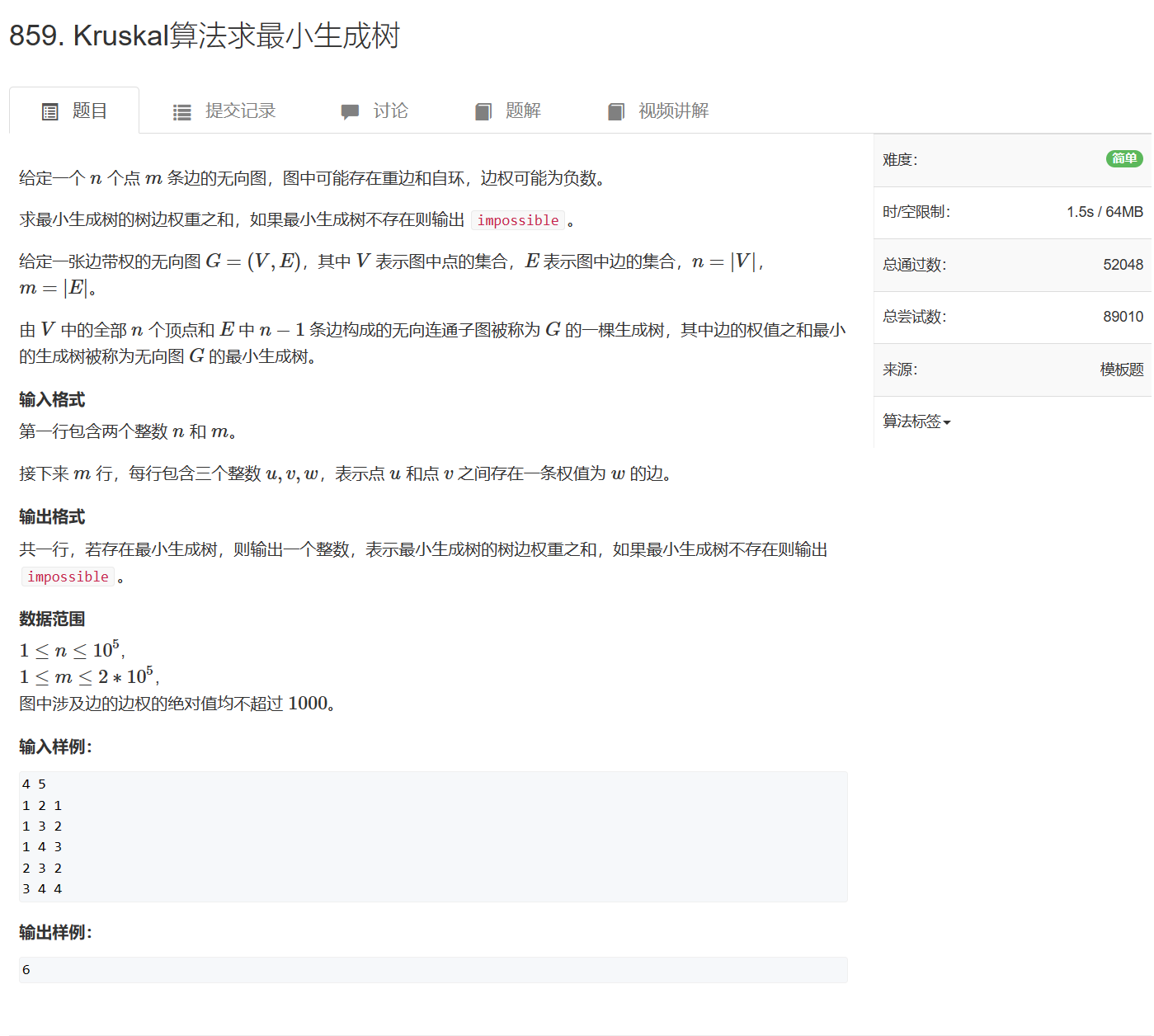
859. Kruskal算法求最小生成树
859. Kruskal算法求最小生成树 - AcWing题库
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10, M = 2 * N;
const int INF = 0x3f3f3f3f;
int n, m;
int p[N];
struct Edge
{
int x, y, w;
bool operator<(const Edge& e)
{
return w < e.w;
}
}edges[M];
int find(int x)
{
if (x != p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; ++ i ) p[i] = i;
int x, y, w;
int cnt = 0, res = 0;
for (int i = 0; i < m; ++ i )
{
auto t = edges[i];
x = t.x, y = t.y, w = t.w;
x = find(x), y = find(y);
if (x != y)
{
res += w;
cnt ++ ;
p[x] = y;
}
}
if (cnt == n - 1) return res;
return INF;
}
int main()
{
scanf("%d%d", &n, &m);
int x, y, d;
for (int i = 0; i < m; ++ i )
{
scanf("%d%d%d", &x, &y, &d);
edges[i] = { x, y, d };
}
int t = kruskal();
if (t == INF) puts("impossible");
else printf("%d\n", t);
return 0;
}
二分图练习题
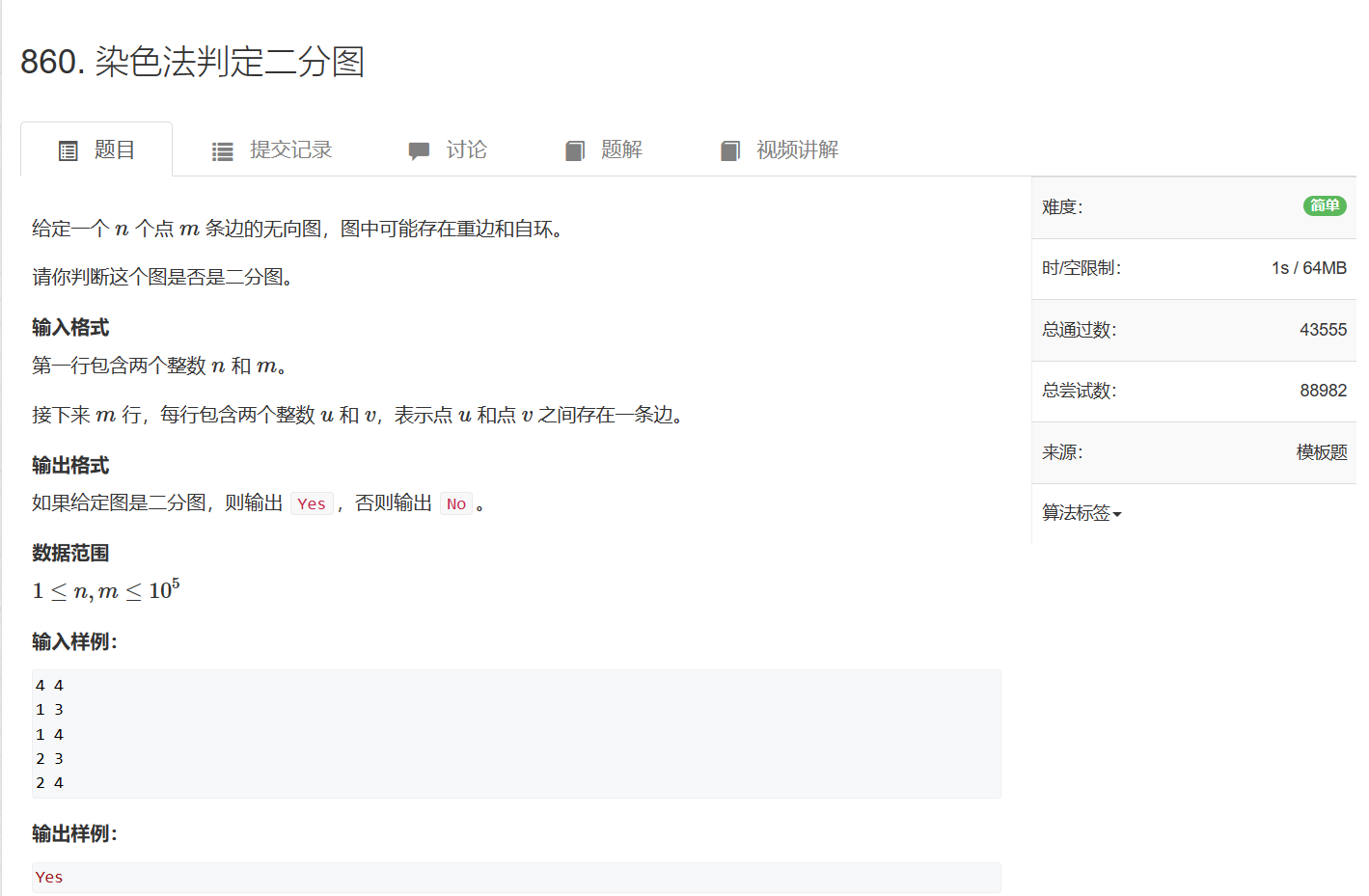
860. 染色法判定二分图
860. 染色法判定二分图 - AcWing题库
#include <cstring>
#include <iostream>
using namespace std;
const int N = 1e5 + 10, M = 2 * N;
int h[N], e[M], ne[M], idx = 1;
int color[N];
int n, m;
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
bool dfs(int x, int c)
{
color[x] = c;
for(int i = h[x]; i != -1; i = ne[i])
{
int y = e[i];
if (!color[y])
{
if (!dfs(y, 3 - c)) return false;
}
else if (color[y] == c) return false;
}
return true;
}
int main()
{
memset(h, -1, sizeof(h));
scanf("%d%d", &n, &m);
int x, y;
while (m -- )
{
scanf("%d%d", &x, &y);
add(x, y), add(y, x);
}
bool flag = true;
for (int i = 1; i <= n; ++ i )
{
if (!color[i])
{
if (!dfs(i, 1))
{
flag = false;
break;
}
}
}
if (flag) puts("Yes");
else puts("No");
return 0;
}
debug:把int color[N]写成bool color[N],看了半天,乐
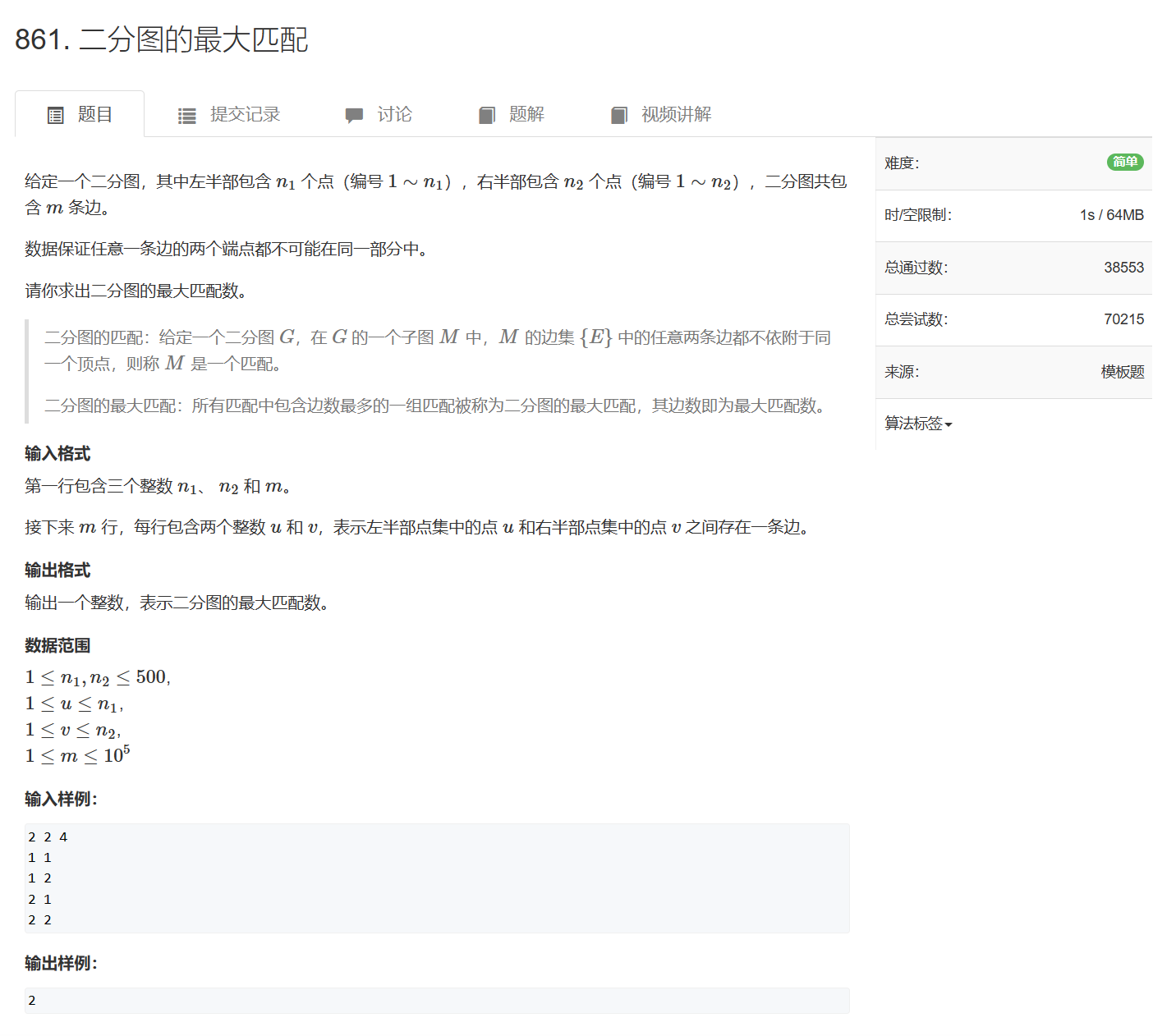
861. 二分图的最大匹配
861. 二分图的最大匹配 - AcWing题库
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, M = 1e5 + 10;
int h[N], e[M], ne[M], idx = 1;
int match[N];
bool st[N];
int n1, n2, m;
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
int main()
{
scanf("%d%d%d", &n1, &n2, &m);
memset(h, -1, sizeof(h));
int x, y, res = 0;
while (m -- )
{
scanf("%d%d", &x, &y);
add(x, y);
}
for (int i = 1; i <= n1; ++ i )
{
memset(st, false, sizeof(st));
if (find(i)) res ++ ;
}
printf("%d\n", res);
return 0;
}









![[SSM]MyBatis使用javassist生成类和接口代理机制](https://img-blog.csdnimg.cn/c96eff2b0cf44fc59788f4f28da5c8f6.png)