口语理解任务源码详解系列(一)数据集构建
写在前面
本系列从零开始构建口语理解项目,整个项目分为意图分类与槽位填充两个子任务。项目采用的数据集为ATIS航空领域口语理解数据集,项目源码请传送到:github
一、处理数据

| 样本数 | 词汇数 | 实体数 | 意图数 |
|---|---|---|---|
| 4978训练集/893测试集 | 943 | 129 | 26 |
读取原始数据
import os
import pickle
import pandas as pd
base_dir = os.getcwd()
# 原始数据
atis_raw_train = os.path.join(base_dir, 'atis', 'atis.train.pkl')
atis_raw_test = os.path.join(base_dir, 'atis', 'atis.test.pkl')
# 处理后保存为csv文件
atis_train_csv = os.path.join(base_dir, 'atis', 'atis.train.csv')
atis_test_csv = os.path.join(base_dir, 'atis', 'atis.test.csv')
定义加载数据方法
def load_atis(file_path):
with open(file_path, 'rb') as f_read:
ds,dicts = pickle.load(f_read)
print('done loading:', file_path)
print('samples:{}'.format(len(ds['query'])))
print('vocab_size:{}'.format(len(dicts['token_ids'])))
print('slot count:{}'.format(len(dicts['slot_ids'])))
print('intent count:{}'.format(len(dicts['intent_ids'])))
return ds,dicts



处理训练数据,保存为csv结构
train_ds, train_dicts = load_atis(atis_raw_train)
t2i, s2i, in2i = map(train_dicts.get, ['token_ids', 'slot_ids', 'intent_ids'])
i2t, i2s, i2in = map(lambda d:{d[k]:k for k in d.keys()}, [t2i, s2i, in2i])
query, slots, intent = map(train_ds.get, ['query', 'slot_labels', 'intent_labels'])
代码段 t2i, s2i, in2i = map(train_dicts.get, ['token_ids', 'slot_ids', 'intent_ids'])对字典train_dicts中的键进行映射操作
对列表[‘token_ids’, ‘slot_ids’, ‘intent_ids’]中的每个元素进行迭代,
t2i将存储train_dicts字典中键为token_ids的值,s2i存储slot_ids的值,in2i存储intent_ids的值。
代码段i2t, i2s, i2in = map(lambda d:{d[k]:k for k in d.keys()}, [t2i, s2i, in2i])使用了Python的map函数和lambda表达式来进行映射操作
对列表[t2i, s2i, in2i]中的每个元素进行迭代,
对于每个元素,使用lambda d:{d[k]:k for k in d.keys()}来创建一个新的字典,其中字典的键是原字典中的值,字典的值是原字典中的键。
将每个新创建的字典分别赋给变量i2t、i2s和i2in。这样,i2t将存储由t2i字典中的值作为键、对应的键作为值的新字典,i2s将存储由s2i字典中的值作为键、对应的键作为值的新字典,i2in将存储由in2i字典中的值作为键、对应的键作为值的新字典。
这段代码的目的是将原字典中的键值对反转,以创建新的字典,新字典的键是原字典中的值,而值是原字典中的键。这样可以方便根据值查找对应的键。

train_source_target = []
for i in range(len(train_ds['query'])):
intent_source_target_lst = []
# 1.存储intent ['flight']
intent_source_target_lst.append(i2in[intent[i][0]])
# 2.存储source
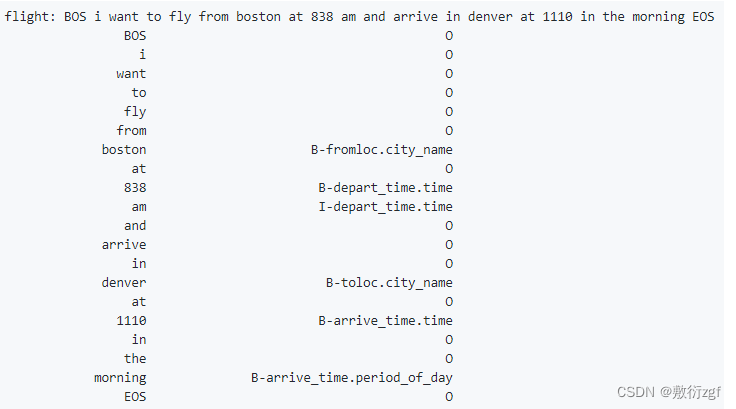
# ['BOS', 'i', 'want', 'to', 'fly', 'from', 'boston', 'at', '838', 'am', 'and', 'arrive', 'in', 'denver', 'at', '1110', 'in', 'the', 'morning', 'EOS']
source_data = list(' '.join(map(i2t.get, query[i])).split())
# 删除BOS
del(source_data[0])
# 删除EOS
del(source_data[-1])
# ['flight', 'i want to fly from boston at 838 am and arrive in denver at 1110 in the morning']
intent_source_target_lst.append(' '.join(source_data))
# 3.存储target
# ['O', 'O', 'O', 'O', 'O', 'O', 'B-fromloc.city_name', 'O', 'B-depart_time.time', 'I-depart_time.time', 'O', 'O', 'O', 'B-toloc.city_name', 'O', 'B-arrive_time.time', 'O', 'O', 'B-arrive_time.period_of_day', 'O']
target_data = [i2s[slots[i][j]] for j in range(len(query[i]))]
# 删除BOS
del(target_data[0])
# 删除EOS
del(target_data[-1])
# ['flight', 'i want to fly from boston at 838 am and arrive in denver at 1110 in the morning', 'O O O O O B-fromloc.city_name O B-depart_time.time I-depart_time.time O O O B-toloc.city_name O B-arrive_time.time O O B-arrive_time.period_of_day']
intent_source_target_lst.append(' '.join(target_data))
# [['flight', 'i want to fly from boston at 838 am and arrive in denver at 1110 in the morning', 'O O O O O B-fromloc.city_name O B-depart_time.time I-depart_time.time O O O B-toloc.city_name O B-arrive_time.time O O B-arrive_time.period_of_day']]
train_source_target.append(intent_source_target_lst)
name = ['intent', 'source', 'target']
train_csv = pd.DataFrame(columns=name, data=train_source_target)
train_csv.to_csv(atis_train_csv)
print('train data process done!')
处理测试数据,保存为csv结构
'''
处理测试数据,保存为csv结构
'''
test_ds, test_dicts = load_atis(atis_raw_test)
t2i, s2i, in2i = map(test_dicts.get, ['token_ids', 'slot_ids', 'intent_ids'])
i2t, i2s, i2in = map(lambda d:{d[k]:k for k in d.keys()}, [t2i, s2i, in2i])
query, slots, intent = map(test_ds.get, ['query', 'slot_labels', 'intent_labels'])
test_source_target = []
for i in range(len(test_ds['query'])):
intent_source_target_lst = []
# 1.存储intent
intent_source_target_lst.append(i2in[intent[i][0]])
# 2.存储source
source_data = list(' '.join(map(i2t.get, query[i])).split())
# 删除BOS
del(source_data[0])
# 删除EOS
del(source_data[-1])
intent_source_target_lst.append(' '.join(source_data))
# 3.存储target
target_data = [i2s[slots[i][j]] for j in range(len(query[i]))]
# 删除BOS
del(target_data[0])
# 删除EOS
del(target_data[-1])
intent_source_target_lst.append(' '.join(target_data))
test_source_target.append(intent_source_target_lst)
name = ['intent', 'source', 'target']
test_csv = pd.DataFrame(columns=name, data=test_source_target)
test_csv.to_csv(atis_test_csv)
print('test data process done!')
展示处理过后的数据
pd_train = pd.read_csv(atis_train_csv, index_col=0)
print(pd_train.head())

二、构建训练集和验证集
import os
from torchtext import data, datasets
import pandas as pd
import pickle # 读取pkl文件
base_dir = os.getcwd() # 该函数不需要传递参数,它返回当前的目录。
atis_data = os.path.join(base_dir, 'atis')
def build_dataset():
tokenize = lambda s: s.split()
将输入的字符串s按照空格进行分割,返回一个包含各个单词的列表。
SOURCE = data.Field(sequential=True, tokenize=tokenize,
lower=True, use_vocab=True,
init_token='<sos>', eos_token='<eos>',
pad_token='<pad>', unk_token='<unk>',
batch_first=True, fix_length=50,
include_lengths=True) # include_lengths=True为方便之后使用torch的pack_padded_sequence
Field类是TorchText库中用于定义数据预处理操作的核心类之一。在这个代码中,SOURCE是一个Field对象,用于表示输入的源文本序列。
- sequential=True:表示数据是一个序列(如句子),将被看作一个由多个连续元素组成的序列;
- tokenize=tokenize:指定了分词函数,即通过调用tokenize函数将文本进行分词,返回一个单词列表;
- lower=True:将所有文本转换为小写;
- use_vocab=True:是否将构建词汇表(vocabulary),如果为True,则会根据数据集创建一个词汇表;
- init_token=‘< sos >’ :在每个序列开头添加起始标记;
- eos_token=‘< eos >’:在每个序列结尾添加结束标记;
- pad_token=‘< pad >’:用于将序列填充到相同长度的填充标记;
- unk_token=‘< unk >’:用于表示未知单词(在词汇表中不存在的单词)的标记;
- batch_first=True:在生成批次时,将数据维度中的批次维度放在第一维;
- fix_length=50:将每个序列固定为指定的长度(50),如果序列长度不足,将使用填充标记进行填充;
- include_lengths=True:返回批次数据时,同时返回每个序列的实际长度。
TARGET = data.Field(sequential=True, tokenize=tokenize,
lower=True, use_vocab=True,
init_token='<sos>', eos_token='<eos>',
pad_token='<pad>', unk_token='<unk>',
batch_first=True, fix_length=50,
include_lengths=True)
LABEL = data.Field(
sequential=False,
use_vocab=True)
train, val = data.TabularDataset.splits(
path=atis_data,
skip_header=True,
train='atis.train.csv',
validation='atis.test.csv',
format='csv',
fields=[('index', None), ('intent', LABEL), ('source', SOURCE), ('target', TARGET)])
print('train data info:')
print(len(train))
print(vars(train[0]))
print('val data info:')
print(len(val))
print(vars(val[0]))
- data.TabularDataset.splits() 是一个静态方法,用于加载多个具有相同格式的表格数据集;
- skip_header=True 表示跳过数据集文件的第一行(通常是标题行);
- train=‘atis.train.csv’ 指定了训练数据集文件的名称;
- validation=‘atis.test.csv’ 指定了验证数据集文件的名称;
- format=‘csv’ 表示数据集文件的格式为CSV格式;
- fields=[(‘index’, None), (‘intent’, LABEL), (‘source’, SOURCE), (‘target’, TARGET)] 用于定义每个列对应的字段信息。其中,‘index’ 列被忽略(设为None),‘intent’ 列使用名为LABEL的字段对象进行处理,‘source’ 列使用名为SOURCE的字段对象进行处理,‘target’ 列使用名为TARGET的字段对象进行处理。
print(vars(train[0]))
打印出训练集中第一个样本的属性和值,返回一个字典,其中键是字段名,值是对应字段的取值。
例子:
{
'index': 1,
'intent': 'flight',
'source': ['show', 'me', 'the', 'flights', 'from', 'dallas'],
'target': ['O', 'O', 'O', 'O', 'O', 'B-fromloc.city_name']
}
‘index’ 表示样本的索引,‘intent’ 表示意图类别,‘source’ 是源文本序列(单词列表形式),‘target’ 是目标文本序列(标签列表形式)。

SOURCE.build_vocab(train, val)
TARGET.build_vocab(train, val)
LABEL.build_vocab(train, val)
SOURCE.build_vocab(train, val) 是一个用于构建词汇表(vocabulary)的操作,基于训练集和验证集数据。在这个操作中,使用了名为SOURCE的字段对象,并调用它的build_vocab()方法。
build_vocab()方法根据提供的数据集,在字段对象中构建词汇表。词汇表将每个不重复的单词映射到一个唯一的整数标识符(即单词的索引)。该操作还可选择性地根据指定的参数对词汇表进行过滤和修剪。
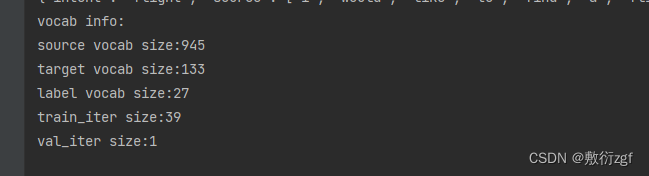
print('vocab info:')
print('source vocab size:{}'.format(len(SOURCE.vocab)))
print('target vocab size:{}'.format(len(TARGET.vocab)))
print('label vocab size:{}'.format(len(LABEL.vocab)))
train_iter, val_iter = data.Iterator.splits(
(train, val),
batch_sizes=(128, len(val)), # 训练集设置为128,验证集整个集合用于测试
shuffle=True,
sort_within_batch=True, # 为true则一个batch内的数据会按sort_key规则降序排序
sort_key=lambda x: len(x.source)) # 这里按src的长度降序排序,主要是为后面pack,pad操作)
return train_iter, val_iter
data.Iterator.splits() 是一个用于创建迭代器的操作,用于将数据集分割为训练集迭代器和验证集迭代器。
- batch_sizes=(128, len(val)):指定了批次大小,第一个元素(128)表示训练集每个批次的样本数量,第二个元素(len(val))表示验证集每个批次的样本数量;
- shuffle=True:表示在每个迭代周期中对训练集进行洗牌,以增加样本之间的随机性;
- sort_within_batch=True:表示对每个批次内的样本按照指定的键(sort_key=lambda x: len(x.source))进行排序;
- sort_key=lambda x: len(x.source):指定了排序键的函数,该函数根据源文本序列的长度进行排序。
train_iter, val_iter = build_dataset()
print('train_iter size:{}'.format(len(train_iter)))
print('val_iter size:{}'.format(len(val_iter)))
至此,该项目的数据集已全部构建完成!!!