本文首发自「慕课网」,想了解更多IT干货内容,程序员圈内热闻,欢迎关注!
动态类型一时爽,代码重构火葬场。
——题记
你生涯中写过的最严重的bug是什么?
我们日常接触的bug,无非是页面崩溃,服务宕机,数据丢失,一般都能尽快修复。
但是曾经有这么一家公司,因为一个bug,在长达一个月的时间内都无法修复,最终黯然退场。
这就是我今天要讲的故事。一个Python代码中的bug,直接干倒了一家估值1.6亿美金的公司。
有一家名为 Digg的公司。
成立于 2004 年,做的是科技类的新闻聚合,Digg创新性的允许用户提交自己搜集的新闻,然后根据订阅数量去评判内容的质量,并通过内部算法将新闻抓取到网站的首页。
这其实有点像今日头条的思路,在2004年,这还是非常先进的。
Digg也因此收获了一大批用户,估值曾达到过 1.6 亿美元,登上过《商业周刊》的封面,甚至Google 也曾计划以 2 亿美元将它收入囊中。
但好景不长,2011 年 Google 推出了 Panda “反垃圾网站”算法,主要目的是将质量低、含有垃圾内容的网页或网站排名降低,使得高质量的内容得到应有的合理排名。
由于没有针对Panda算法进行优化,Digg的流量直接减半,于是他们决定对网站进行改写,即发布 Digg v4 版本。
但由于各种原因,Digg v4 一拖再拖,耗费了两年还没完成,公司已经拖不起了,经过内部的商议,他们决定将没有完全准备好的 Digg v4 紧急上线。
但他们没有意识到,这个决定将直接葬送Digg的未来。
由于现有服务器的容量太小,该团队决定重新映像所有现有的服务器,然后在新的软件栈中重新配置。
但开始切换之后,新的网站并没有真正地出现,只好匆匆忙忙地发布了一个维护页面,一个小时后,V4版本的切换才完成,但大家发现多数的页面呈现无法加载的状态,访客页面没有问题,但是已经登录的用户却仍然看到报错的页面,网站每隔四个小时之后就会出现故障。除此之外,还有几十个小问题也在不断出现。
由于研发团队一直找不到该Bug,这也导致了在长达一个月的时间内,用户是无法访问Digg的。
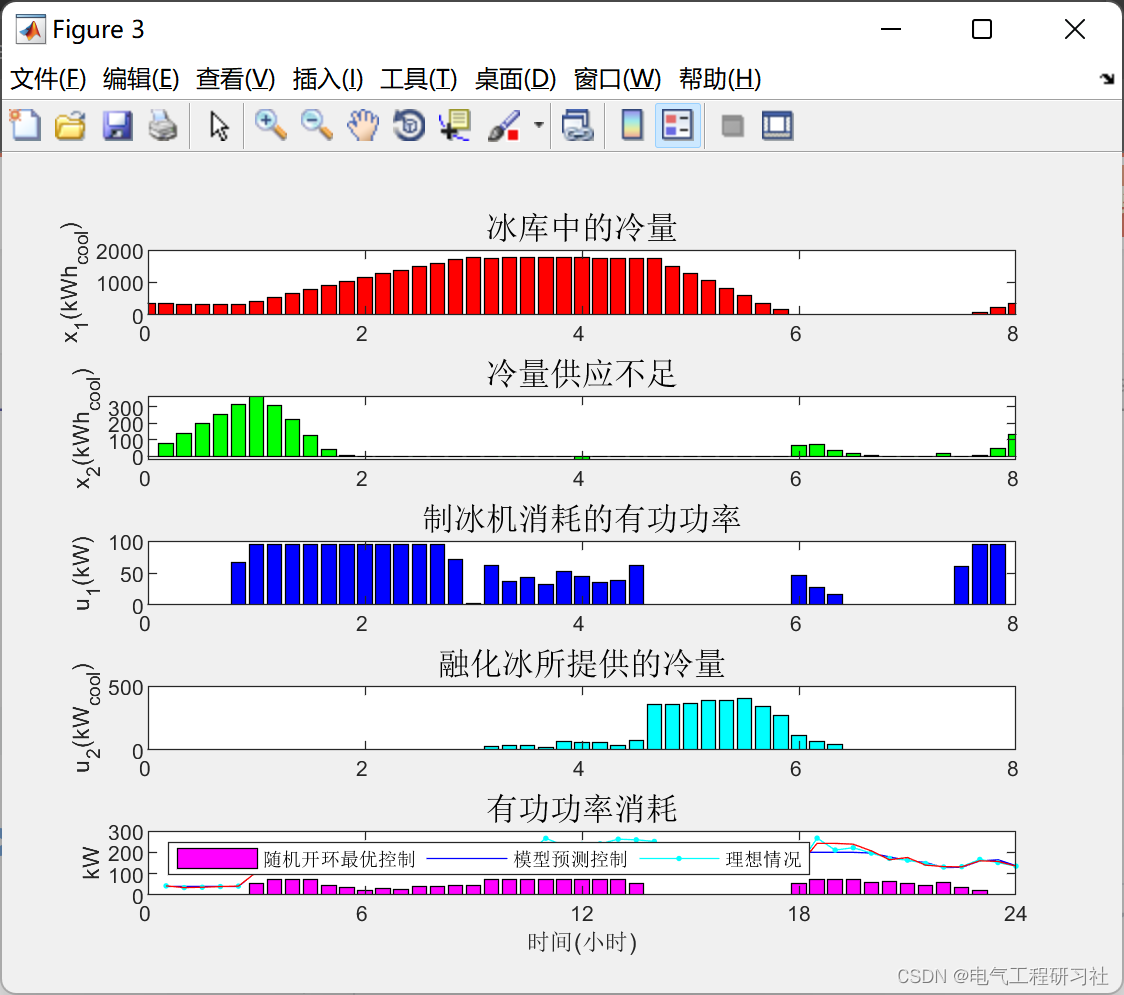
直到一个月后他们才发现,Digg 的 API 服务器是一个 Python Tornado 服务,它将 API 调用到 Python 后端层,即 Bobtail(前端是 Bobcat),其中一个最经常被访问的端点是用来通过用户的名字或 ID 来检索用户。因为它支持按名字或 ID 检索,所以它把两个参数的默认值都设置为空列表。
def get_user_by_ids(ids=[])
然而,Python 只在函数第一次被评估时初始化默认参数,这意味着每次调用函数时都会使用同一个列表。
在这种情况下,每次调用时,用户的 ID 和名字都被附加到默认列表中。几个小时后,这些列表开始在每次请求中检索数以万计的用户,甚至压垮了 memcache 集群,导致了页面崩掉。
但由于修复耗费了太久,Digg的用户群进一步萎缩,估值下降,开启了多轮裁员,并最终被以50万美金的价格收购。
一家创业明星公司就此陨落。
其实,这个bug出现的根本原因是该公司的技术团队不了解Python的特性。
可见bug不可怕,可怕的是不知道bug在哪里,不知道如何修复。
可见多看文档,还是有好处的。

欢迎关注「慕课网」,发现更多IT圈优质内容,分享干货知识,帮助你成为更好的程序员!




![[附源码]Python计算机毕业设计Django影评网站系统](https://img-blog.csdnimg.cn/a63e5a0f555f4e738179ce9b089b3eeb.png)







![[附源码]Python计算机毕业设计Django作业管理系统](https://img-blog.csdnimg.cn/6f00a98349e848a0ba3773ec0b1604f7.png)