参考资料:
- 《机器学习》李宏毅
1 Self-attention
当模型输入为长度不定的向量序列时(如一段文字、一段语音、图模型),要求模型输出为等长的向量序列(序列标注)时,可以使用 Self-attention
Self-attention 的基本结构为:
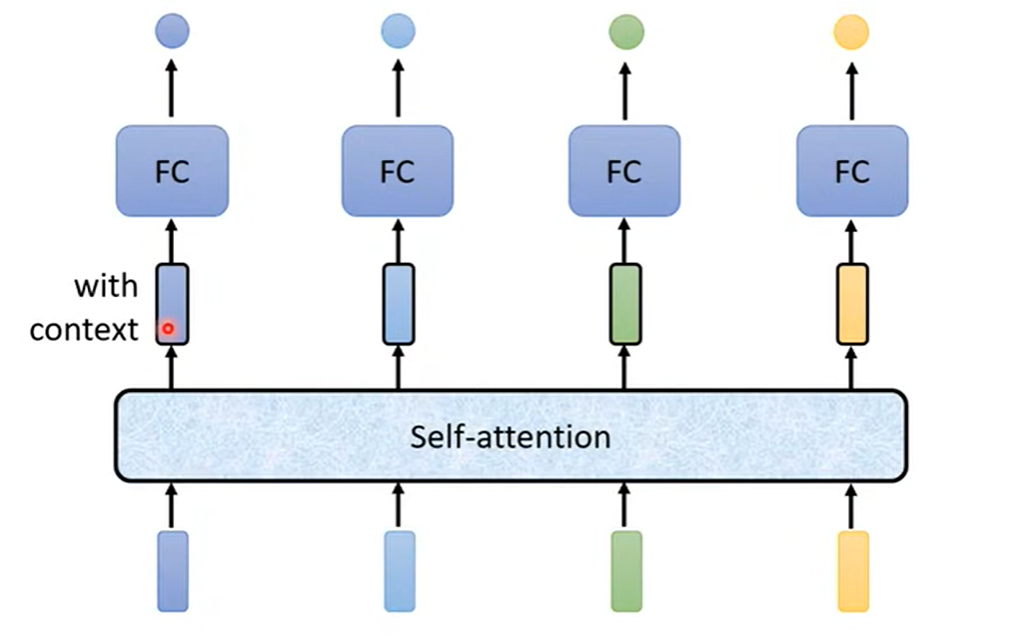
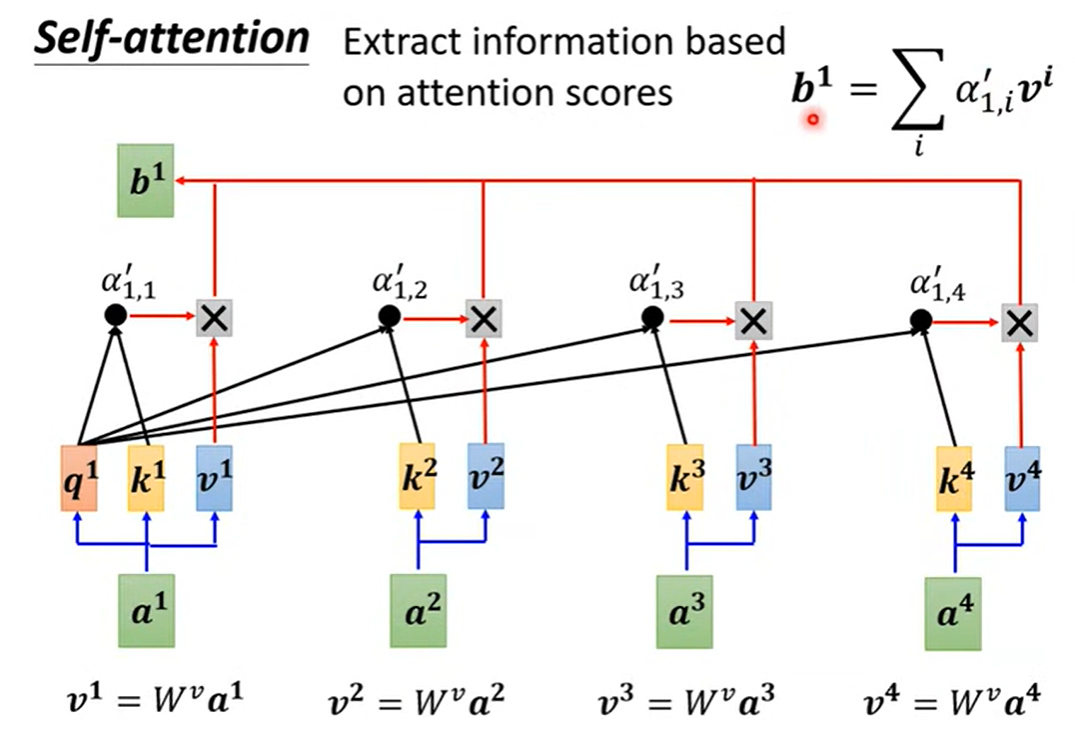
模型的输入为一整个向量序列, q 1 = W q a 1 q^1=W^q a^1 q1=Wqa1 , k 1 = W k a 1 k^1=W^k a^1 k1=Wka1 , v 1 = W k a 1 v^1=W^k a^1 v1=Wka1 , α 1 , 1 = q 1 k 1 \alpha_{1,1}=q^1 k^1 α1,1=q1k1 经过 Softmax后得到 α 1 , 1 ′ \alpha'_{1,1} α1,1′ ;模型的参数为 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv 。用矩阵表示上述运算:
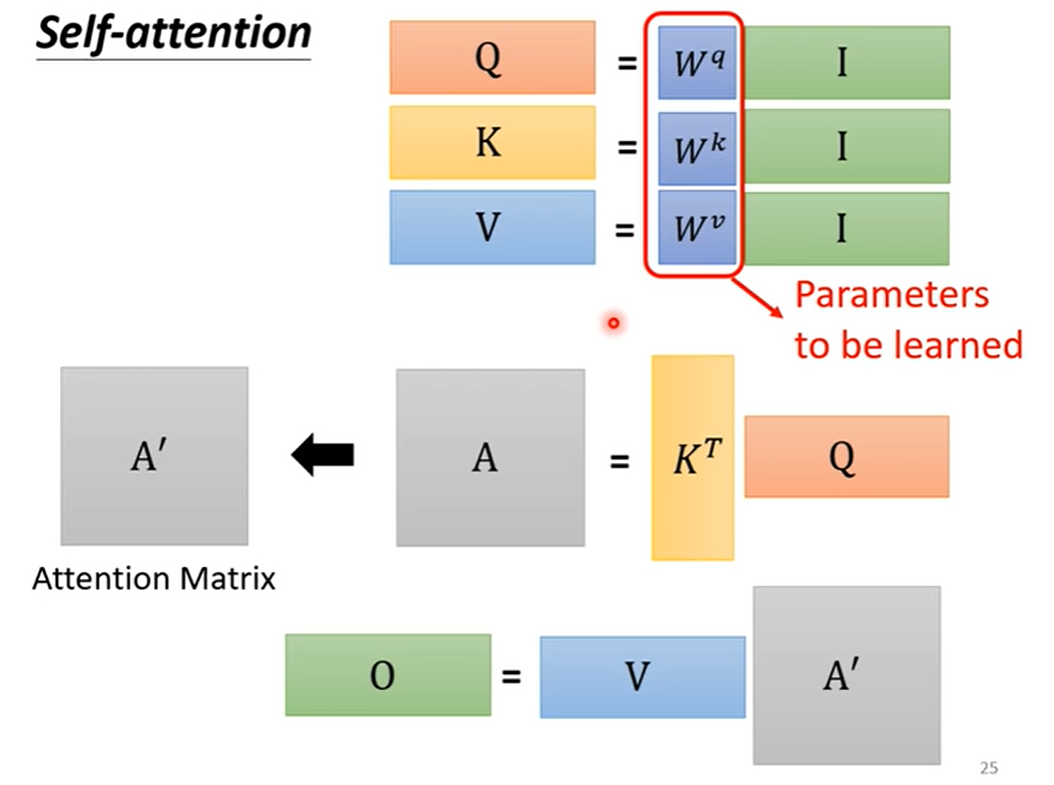
Self-attention 机制通过 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv 引入了输入向量之间的关系,那么如何表示向量之间的多种关系呢?答案是用 Multi-head Self-attention:
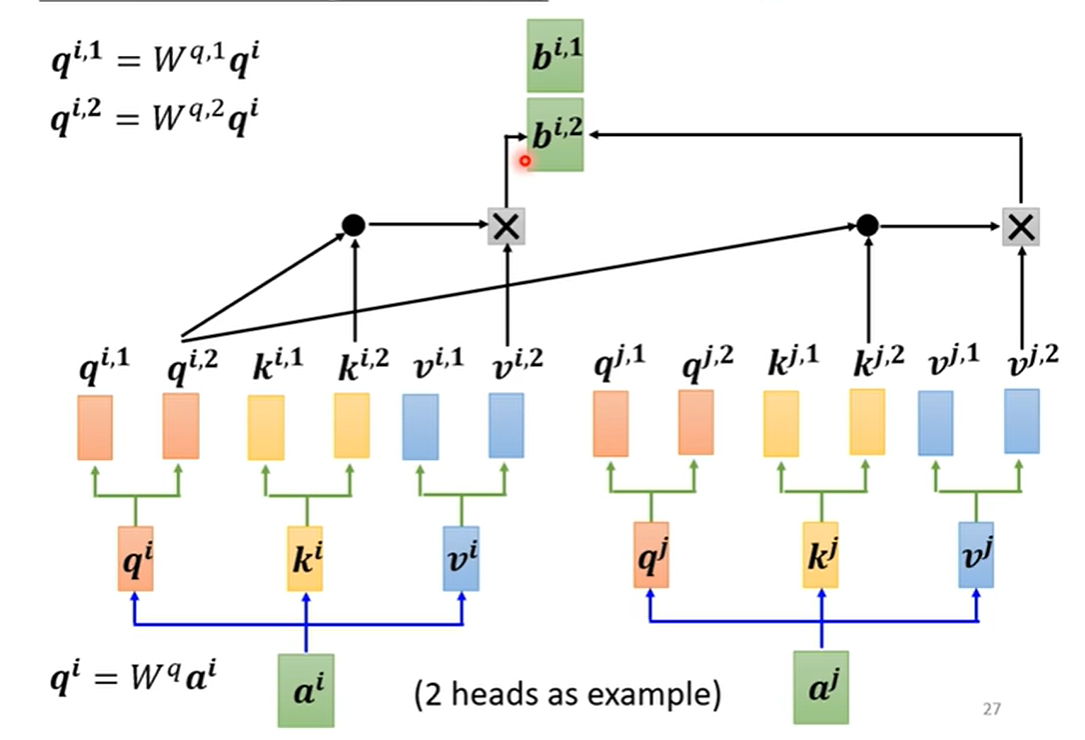
最终,模型输出为 b i = W o ( b i , 1 , b i , 2 ) b^i=W^o(b^{i,1},b^{i,2}) bi=Wo(bi,1,bi,2) ,式中“ ( ) () ()”表示串接。
不难看出,虽然 Self-attention 引入了向量之间的关系,但却没有引入向量的位置信息(如句子的第一个单词为动词的概率较小),这需要通过 Positional Encoding 来解决 。
Self-attention也可以用于图像处理(如把图片看作 RGB 三维向量的序列)。理论上可以证明,CNN 是 Self-attention 的特例,在训练集足够大时,Self-attention 能表现得更好。
2 Transformer
Transformer 用于解决 Seq2Seq 问题(如语音辨识、文字翻译、生成文章摘要等)。解决 Seq2Seq 问题的模型有一个基本架构:
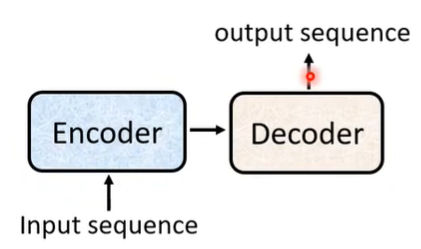
其中,Encoder 的输出和 Input 是等长的,Output 的长度是由模型决定的。Transformer 的 encoder 如下图所示:
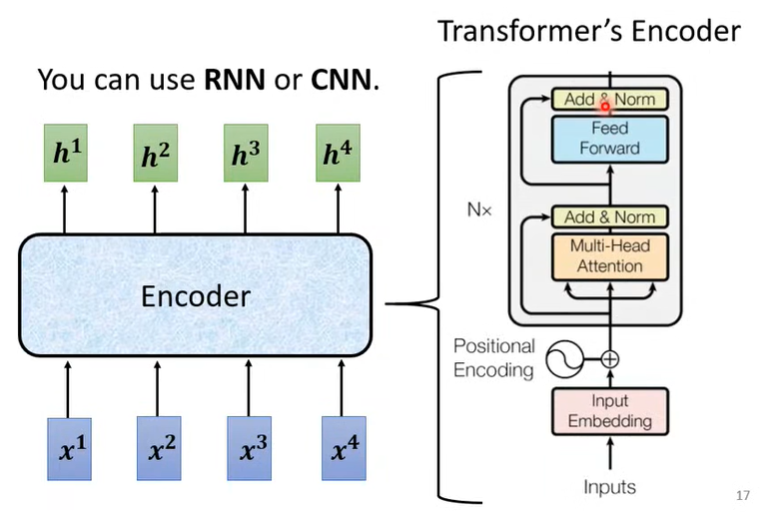
Transformer 的 Decoder 主要有两种模式,分别为 AT 和 NAT ,这里先介绍效果比较好的 AT :
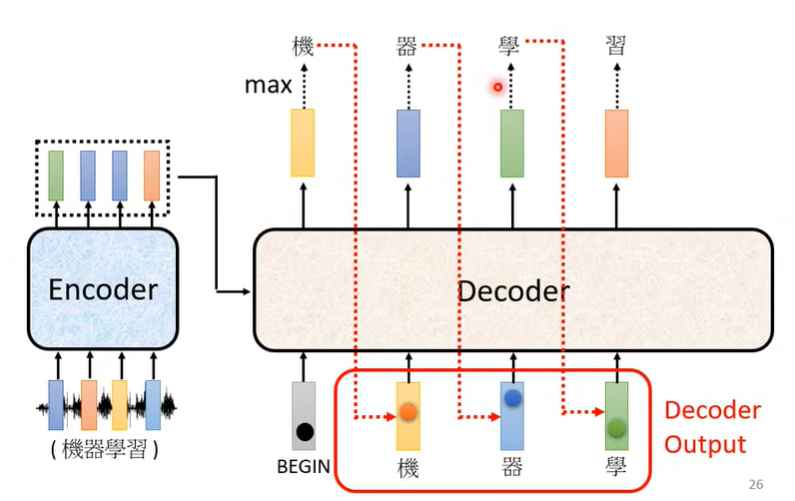
如上图所示,Decoder 最开始接受 Encoder 的输出和一个 BEGIN 作为输入,输出为一个向量,然后根据输出向量选择可能性最大的字,并将该字加入到 Decoder 的输入中,以此类推,直到 Decoder 输出的向量最可能为 END 为止。
NAT的结构为:
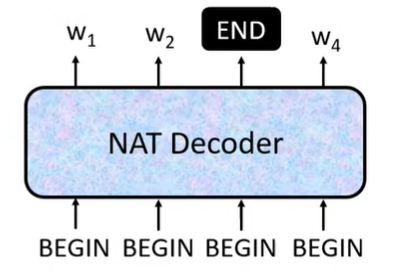
需要说明的是,NAT 同样需要接收 Encoder 的输出作为输入,但 NAT 的 Decoder 的所有输出是并行产生的。
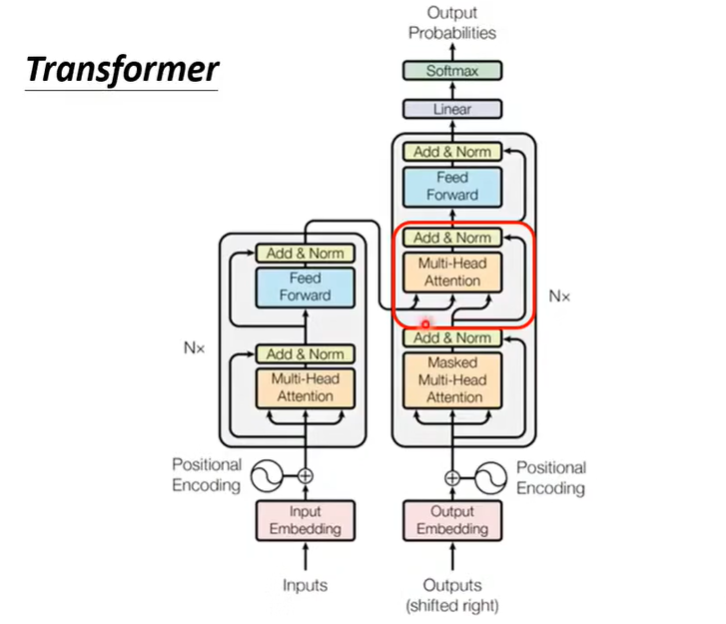
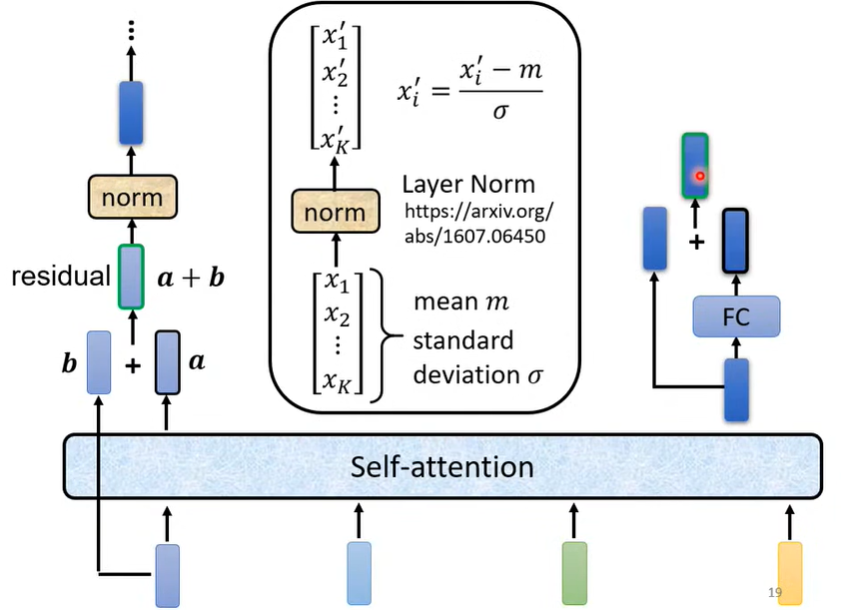
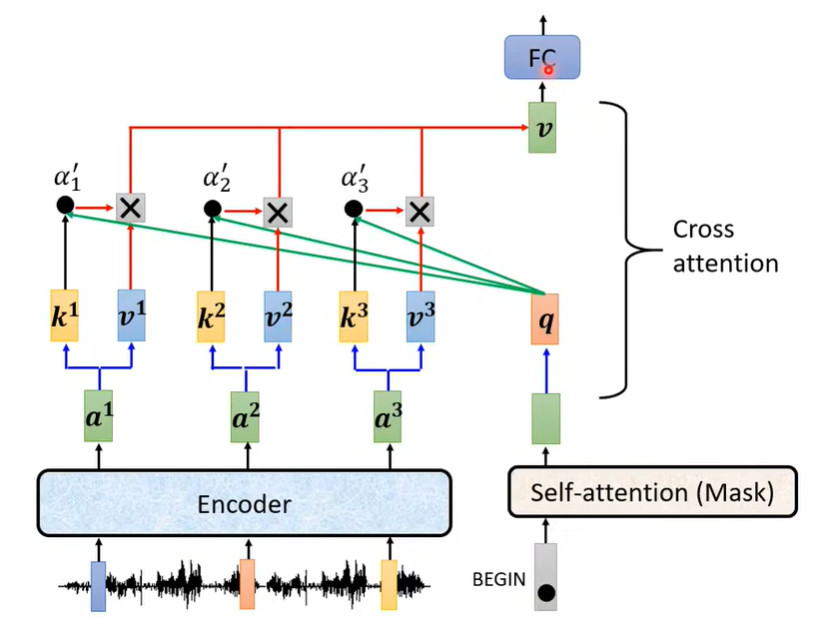
可以看出,除红框外,Decoder 和 Encoder 的工作几乎相同。需要说明的是,Decoder 里用到的 Masked Multi-Head Attention 只考虑了每个向量与其前面的向量的关系,这与 AT 的工作模式一致。红框部分主要做了如下图的工作:
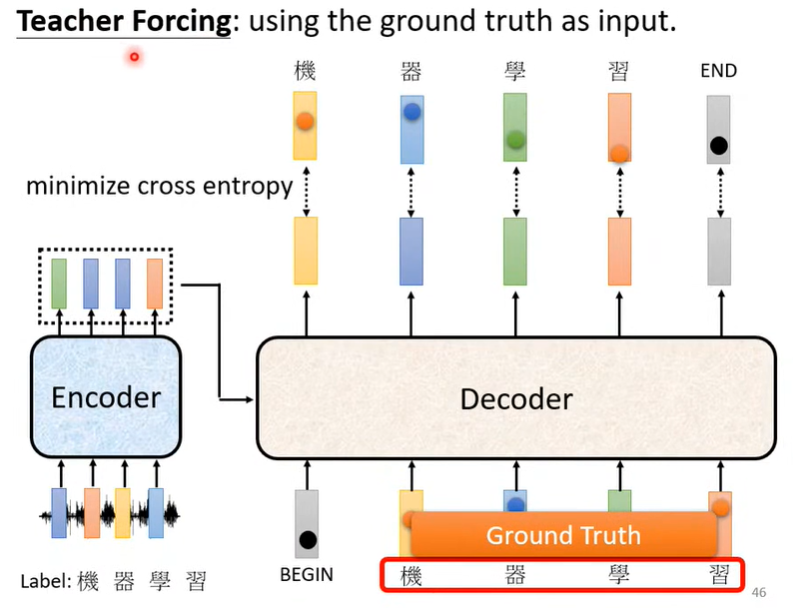
Transformer 在训练时,会给 Decoder 真实的输入:
2051733.png" alt=“image-20230702205128607” style=“zoom:67%;” />
Transformer 的小技巧:Copy Mechanism、Guide Attention、Beam Search