在架构设计中,高性能、高可用、可拓展以及安全等等有多种维度去判断架构的设计纬度,但是一般来说我们需要考虑具体的业务场景,去判断采用那种合适的架构方案,但是对于大多数的设计来说,都需要满足高性能、高可用。所以这一篇主要介绍下如何设计高可用架构。
什么是高可用
说白了就是724小时不间断的提供服务。服务端开发的职责是按照产品文档进行设计和开发出一个功能,但是服务治理需要提供724小时的服务,也就是后续的服务的维护、监控等也是工程师的职责。
对于设计一个可容错的分布式系统架构来说,我们需要有一个准线,也就是如何去界定。
具体公示
Availability=MTTFMTTF+MTTRAvailability=MTTFMTTF+MTTR
MTTF 是 Mean Time To Failure,平均故障前的时间,即系统平均能够正常运行多长时间才发生一次故障。系统的可靠性越高,MTTF 越长。
MTTR 是 Mean Time To Recovery,平均修复时间,即从故障出现到故障修复的这段时间,这段时间越短越好。
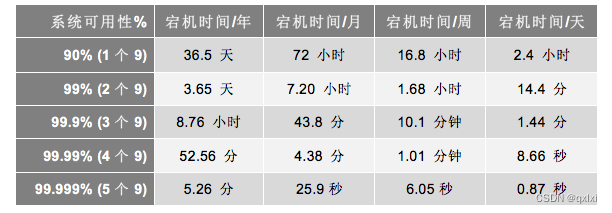
一般来说就是故障的时间,大多数可以做到3个9到4个9之间。即便是互联网应用也很难作答5个9。
所以为了提供可用性,我们要么减少故障的恢复时间,要么提供系统无故障时间。但是对于一个分布式系统来说,不出故障是不可能的,所以,当出现故障的时候我们需要紧急修复,减少故障恢复时间。
故障分类

一般对于每个公司来说都有自己划分故障的级别,可能有的按照系统的损失金额来划分,有的按照系统影响用户范围来划分。其实对于每个工程师来说遇到的故障越多,经验越丰富。处理起来越从容。所以出现故障的时候要紧急找到问题所在。
在我2年多的工作中也遇到过很多故障,比如因为在业务高峰期批量刷数据,导致主从库数据延迟影响业务。程序代码的逻辑BUG考虑不完善导致业务影响,以及同事遇到的一个慢SQL导致支付系统批扣失败等等。还遇到过三分的网线被挖断,导致服务不可用。
故障原因
影响故障的原因其实很多,但是包括不限于 软件设计、硬件故障、人为故障、自然灾害等。如果具体细分的话,其实一个是无计划,一个是有计划。
无计划故障
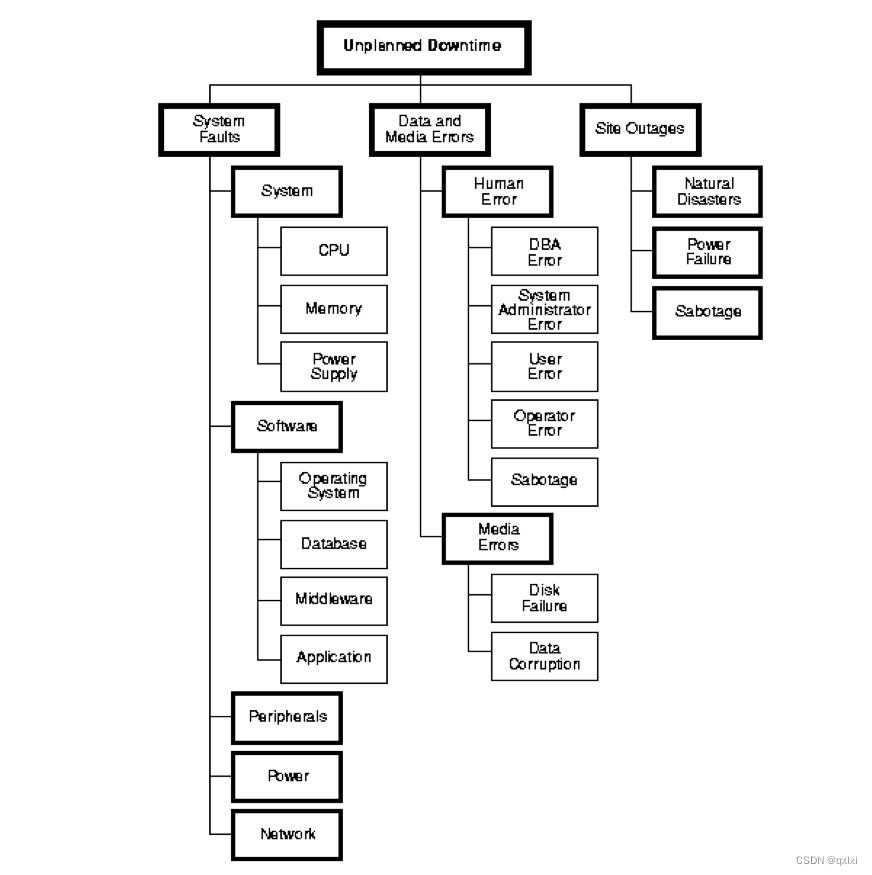
- 系统级故障,包括主机,操作系统,中间件,数据库,网络,电源以及外围设备
- 数据和中介的故障,包括人员误操作,硬盘故障,数据乱了
- 自然灾害,人为破坏,以及供电问题
有计划故障
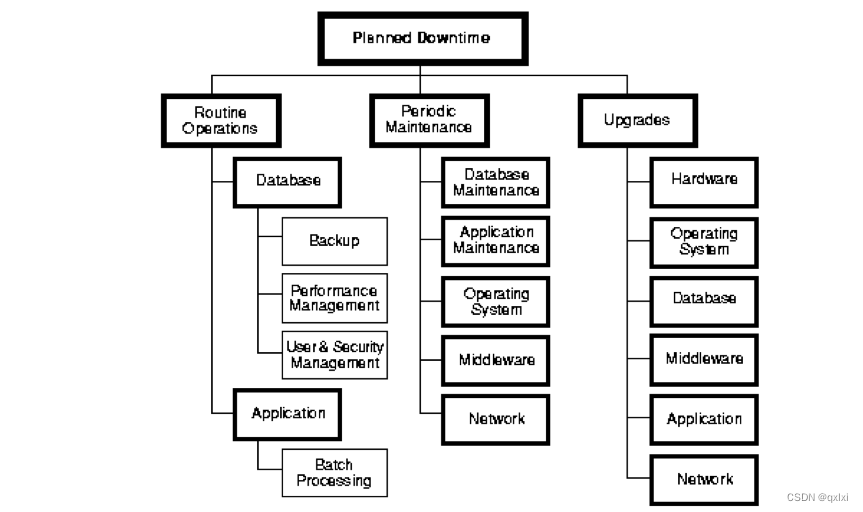
- 日常任务:备份,容量规划,用户和安全管理,后台批处理应用
- 运维相关:数据库维护,应用维护,中间件维护,操作系统维护,网络维护
- 升级相关:数据库,应用,中间件,操作系统,网络,包括硬件升级
分类
- 网络问题:网络连接出现问题,网络带宽出现用赛
- 性能问题:数据库慢SQL,Java Full GC,磁盘IO过大,CPU飙高,内存不足
- 安全问题:网络攻击,DDos
- 运维问题:系统总是在被更新和修改,架构在不断的调整,监控问题
- 管理问题:没有梳理出关键服务以及服务的依赖关系,运行信息没有和控制系统同步
- 硬盘问题:硬盘坏,网卡,交换机,机房掉电,挖掘机等
- 软件设计问题:新上线或者生产上跑的代码 逻辑有BUG导致的。
总结:其实对于大多数情况下,开发(编码、DB、中间件才是出现问题比较多的时候,针对软件质量其实仅仅只做Code Rewiew、上线管控根本不够)
故障不可避免
对于一个大规模分布式系统来说,出现故障是常态,一旦出先就是多米诺骨牌一样。
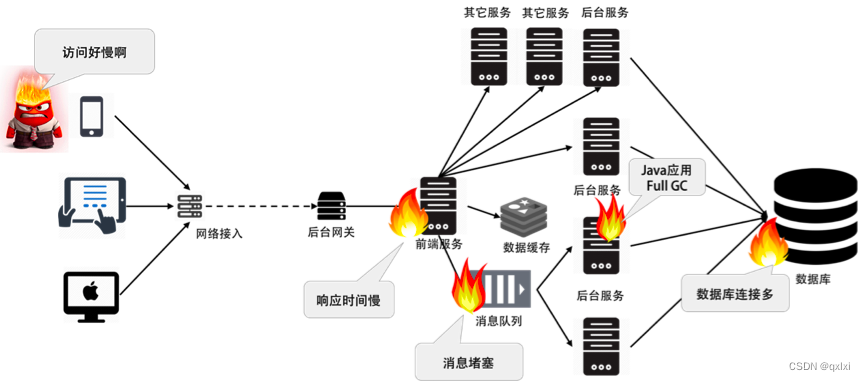
要意识到两个事情
- 故障是正常的,而且是常见的。
- 故障是不可预测突发的,而且相当难缠。
不要尝试着去避免故障,而是要把处理故障的代码当成正常的功能做在架构里写在代码里。Design for Failure。
弹力设计的目的是用尽一切办法降低MTTR,故障的修复时间,
弹力设计的目的是为来在好的情况下,可以系统自动修复,不需要人工的干预,不好的情况下,自我保护,事态不会变的更糟糕。
常见的高可用方法
架构设计层面
容错能力:服务隔离、异步调用、请求幂等性
可伸缩性:有/无状态的服务
一致性:补偿事务,重试
应对大流量能力:熔断、降级
接口层面:排队、限流
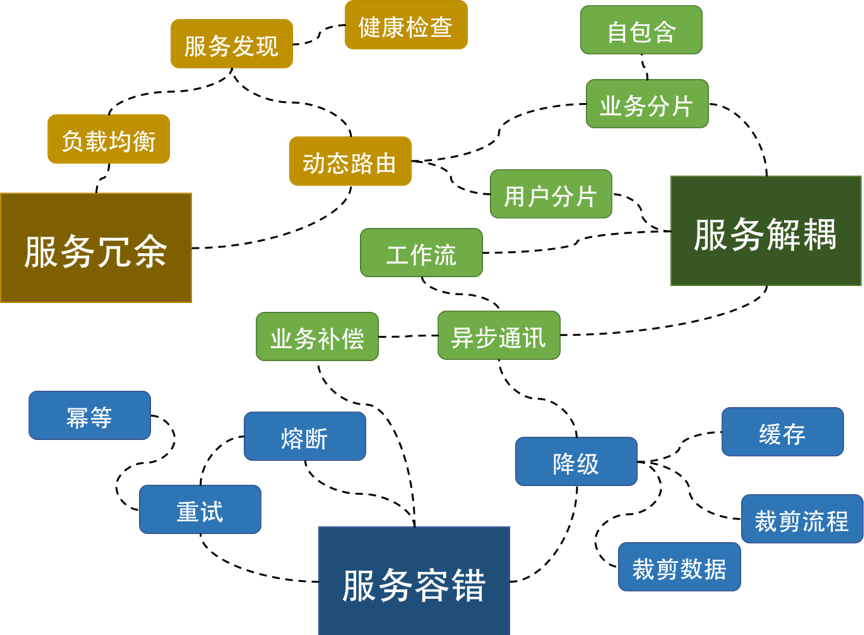
其他方面
软件工程层面
其实大多数出现故障的时候,除了不可控因素之外,更多的是程序逻辑BUG导致的,所以我们需要在代码上线上做一定的安全防范意识。比如从需求的合理性、以及软件设计上、具体代码实现的层面上,依赖的存储中间件等等,以及测试环节、上线环节,功能验收环节等,都需要从质量上把控。但是如果一味的只关注流程,其实没有办法去避免,所以需要针对每次变动,想好具体的应急方案。比如上线异常可以通过回滚的方式等等。
总结
本篇主要设计了高可用设计架构中,如何判断高可用系统,以及故障出现的类别,最后描述了在高可用设计中常用的设计模式,而后续会接着写完这个系列。隔离&异步设计,幂等&重试&补偿,熔断&降级,限流&排队。