识别项目中的接口并生成接口文档
- 前言
- 起点
- 用途
- 使用方法
- 控制台展示
- 文档内容展示
- 代码
- 注意事项
前言
前段时间也是来了一场说走就走的旅行,去看了看祖国的大好河山,不得不说也是一场让我难忘的旅行,可惜钱包太扁了,禁不起我的的折腾。
2023年一晃上半年已经结束了,看了看口袋,又是白干,一个字就是惨!所以想着下半年不能这样躺着了,再躺就四肢退化了。
下半年的开端还是好的,7月1号线上服务出现问题,火急火燎回公司加班到晚上8点,回来继续码代码到11点,就是本篇的《python | 识别项目中的接口并生成接口文档》,加油吧!
起点
《python | 识别项目中的接口并生成接口文档》 代码很早就完成了,实际上也申请过公司的专利,因为太简单了,而且大众,大家都有着想法所以当然就不能通过评审了,但是我感觉用处还是蛮大的。
用途
比如说你接收一个项目,但是接口文档不是很全的情况下,可以使用程序梳理出项目的接口文档
再比如说你开发了一个新项目,但是只有开始的时候写了接口文档但是后面对接口有改动,并且没有及时更新文档,导致文档和代码实际不符合,我觉得这个比较常见,因为我经常忘记更新文档。
使用方法
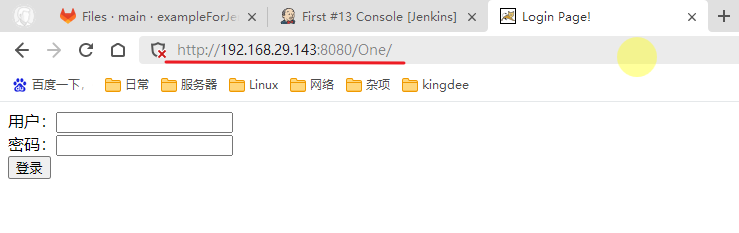
文末会贴代码,只需要复制粘贴,然后添加依赖,运行之后输入项目地址即可。
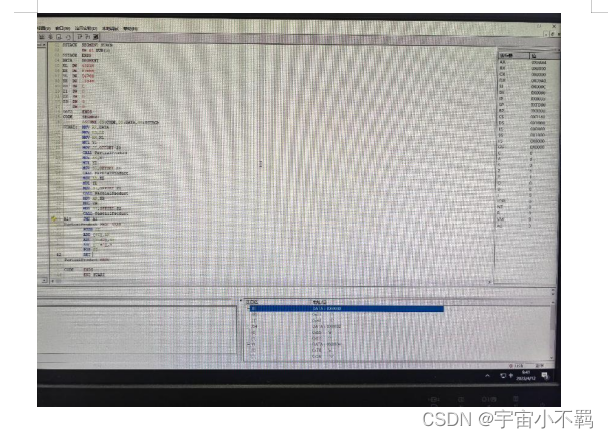
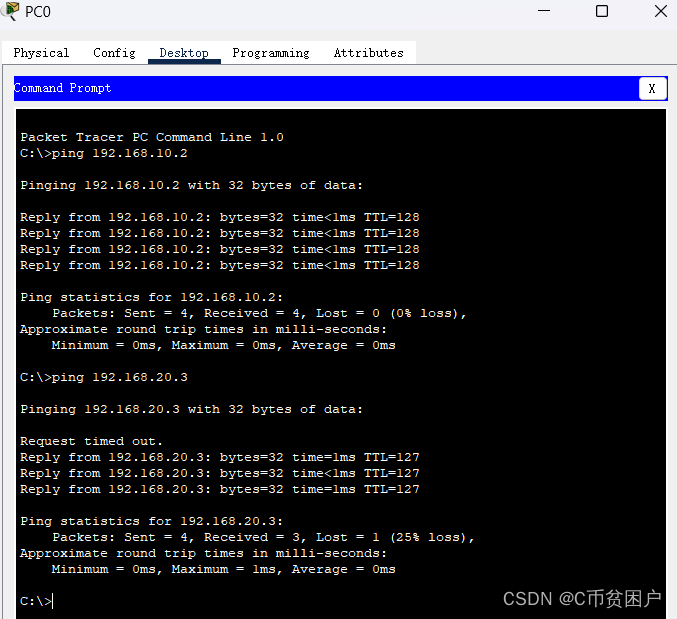
控制台展示
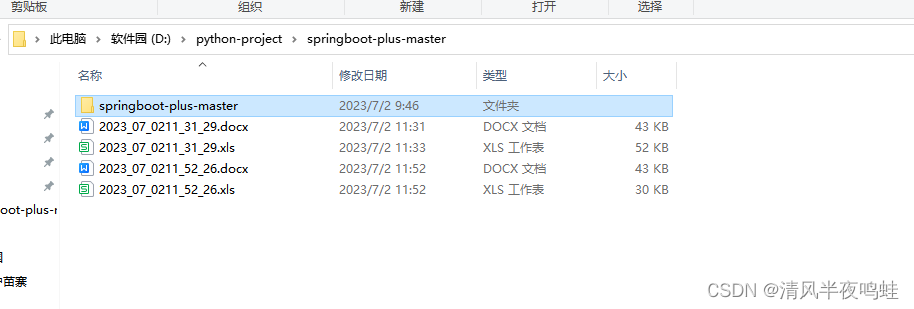
输入项目地址之后是这样的,这个是你在控制台上看到的,实际会在你项目的同级目录下生成docx和xls文档
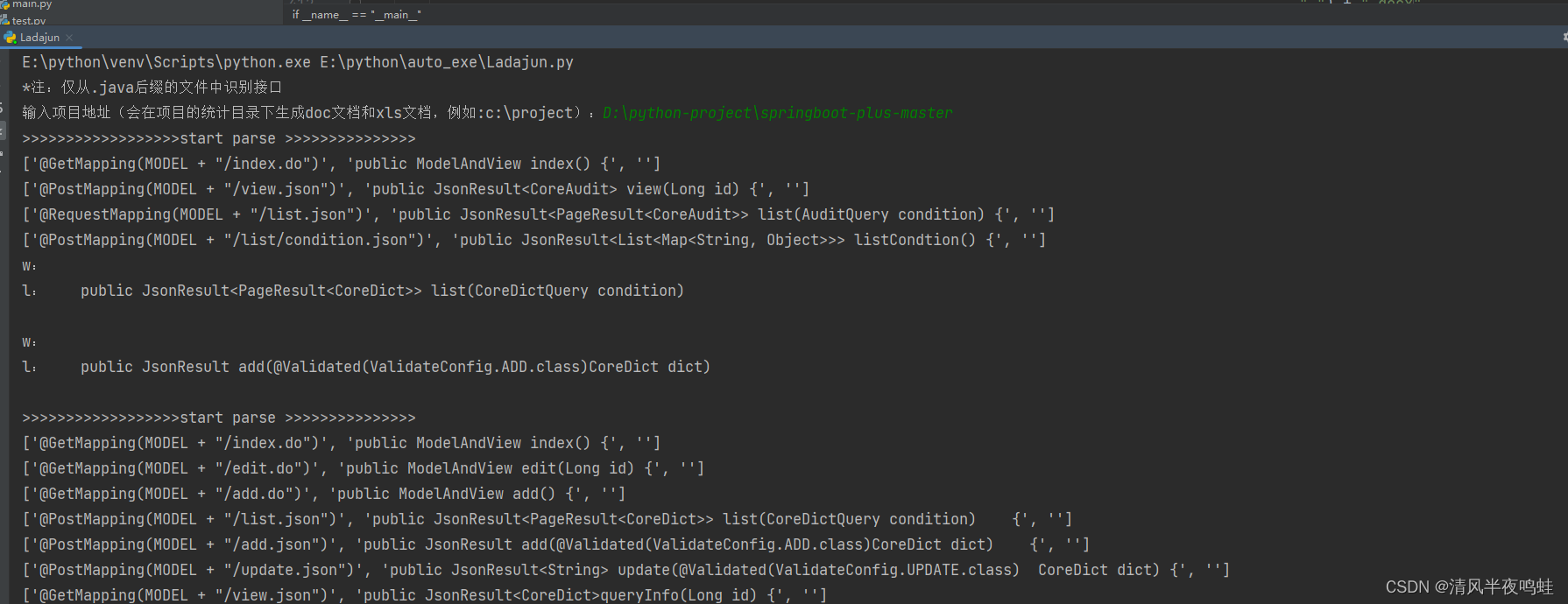
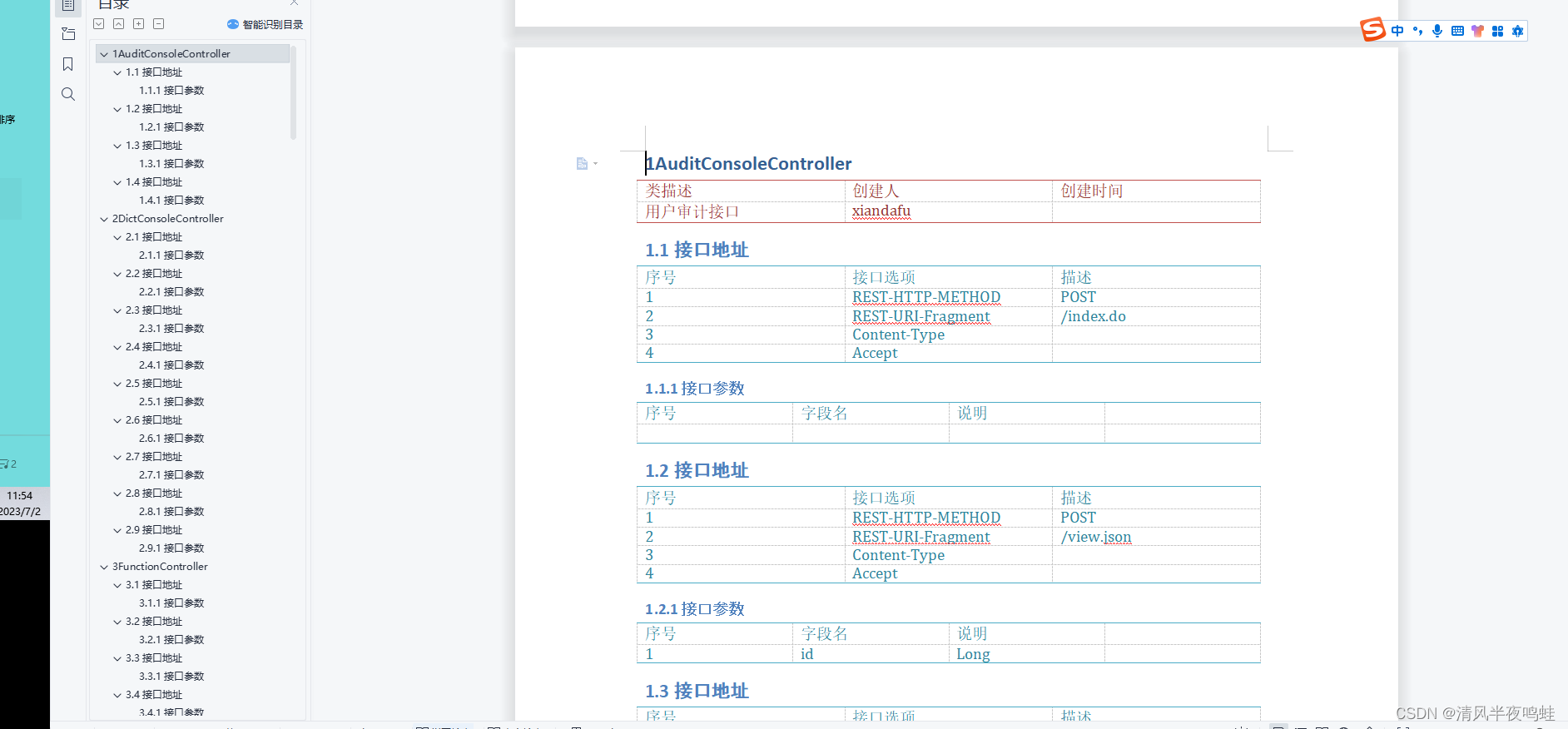
文档内容展示
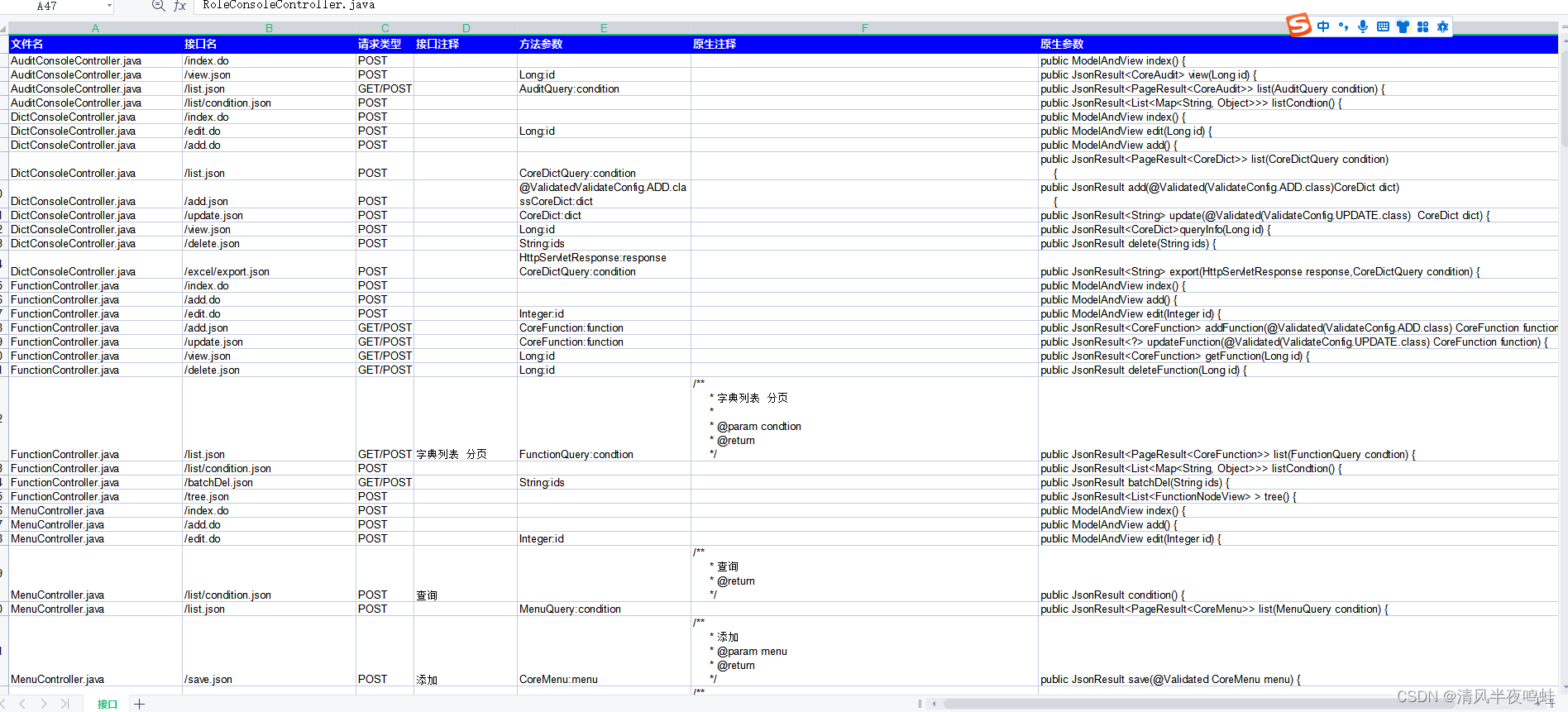
代码
# 从文件中提取接口
# 定义一个文件夹名称
import datetime
import os
from docx import Document
from docx.enum.style import WD_STYLE_TYPE
import xlwt
# 生成excel文档要素
style_head = xlwt.XFStyle()
style_row = xlwt.XFStyle()
font = xlwt.Font()
font.name = "微软雅黑"
font.bold = True
font.colour_index = 1
bg = xlwt.Pattern()
bg.pattern = xlwt.Pattern.SOLID_PATTERN
bg.pattern_fore_colour = 4
style_head.font = font
style_head.pattern = bg
style_row.alignment.wrap = 1
ee = xlwt.Workbook(encoding='utf-8')
ss = ee.add_sheet("接口")
ss.write(0, 0, "文件名", style_head)
ss.write(0, 1, "接口名", style_head)
ss.write(0, 2, "请求类型", style_head)
ss.write(0, 3, "接口注释", style_head)
ss.write(0, 4, "方法参数", style_head)
ss.write(0, 5, "原生注释", style_head)
ss.write(0, 6, "原生参数", style_head)
sec = ss.col(0)
ser = ss.row(0)
sec.width = 256 * 30
sec = ss.col(1)
ser = ss.row(1)
sec.width = 256 * 30
sec = ss.col(2)
ser = ss.row(2)
sec.width = 256 * 10
sec = ss.col(3)
ser = ss.row(3)
sec.width = 256 * 40
sec = ss.col(4)
ser = ss.row(4)
sec.width = 256 * 30
sec = ss.col(5)
ser = ss.row(5)
sec.width = 256 * 60
sec = ss.col(6)
ser = ss.row(6)
sec.width = 256 * 100
aa = 0
bb = 0
# 生成doc文档要素
docment = Document()
docment.add_heading('来自路由名.exe生成的接口文档', 0)
doc_p = docment.add_paragraph("")
doc_p.add_run('路由名').bold = True
docment.add_page_break()
def p(i):
if os.path.isdir(i):
dirs = os.listdir(i)
for d in dirs:
if (i + "\\" + d).endswith(".java"):
q(i + "\\" + d)
elif os.path.isdir(i + "\\" + d):
p(i + "\\" + d)
else:
if i.endwith(".java"):
q(i)
else:
print("不支持此类型的文档!")
def q(r):
i_o = False
with open(r, encoding='utf-8', errors='ignore') as f:
for l in f:
if "@Controller" == l.replace("\n", "").strip() \
or "@Controller(" in l \
or "@RestController" == l.replace("\n", "").strip() \
or "@Controller(" in l:
i_o = True
break
if not i_o:
return
global aa
global bb
s = ""
t = False
u = False
v = False
w = ""
x = []
y = []
z = r.split("\\")[-1:][0]
is_zh = False
str_zh = ""
i_c = 0
# 调整编码 显示中文
with open(r, encoding='utf-8', errors='ignore') as f:
for l in f:
if l == "":
continue
if 'Mapping' in l and 'import' in l:
continue
if '/**' in l and not is_zh:
# 注释行
str_zh = ""
is_zh = True
str_zh = str_zh + l
continue
if '*/' in l and is_zh:
is_zh = False
str_zh = str_zh + l
continue
if is_zh:
str_zh = str_zh + l
continue
if 'Mapping' in l and 'import' not in l and t is False:
s = l
continue
if 'public class' in l:
t = True
xls_h = str_zh
str_zh = ""
continue
if 'Mapping' in l:
x.append(l.strip())
u = True
continue
if u and l.strip().startswith("public") and l.strip().endswith("{"):
w = l
x.append(w.strip())
x.append(str_zh.strip())
str_zh = ""
y.append(x)
w = ""
x = []
u = False
continue
if u and l.strip().startswith("public") and not l.strip().endswith("{"):
print("w:"+w)
print("l:" + l)
w = w + l
v = True
continue
if u and v and l.strip().endswith("{"):
v = False
w = w + l
x.append(w.strip())
x.append(str_zh.strip())
str_zh = ""
y.append(x)
w = ""
x = []
u = False
continue
if u and v:
w = w + l
if s != "" or len(y) != 0:
print(">>>>>>>>>>>>>>>>>>start parse >>>>>>>>>>>>>>>")
if s != "":
print(s.strip().split("\"")[1].split("\"")[0])
# 标题就是 xls_h
docment.add_heading(str(bb + 1) + "" + z.replace(".java", ""), level=1).bold = False
# 产生一个表格吧
table = docment.add_table(2, 3)
table.style = "Light Shading Accent 2"
heading_cells = table.rows[0].cells
heading_cells[0].text = "类描述"
heading_cells[1].text = "创建人"
heading_cells[2].text = "创建时间"
row_cells = table.rows[1].cells
row_cells[0].text = str(get_word(xls_h))
row_cells[1].text = str(get_creator_user(xls_h))
row_cells[2].text = str(get_creator_time(xls_h))
bb += 1
if len(y) != 0:
for oi in y:
print(str(oi).replace("\\n", ""))
pt = ""
jk = oi[0]
ff = oi[1]
zh = oi[2]
if "Post" in jk or "POST" in jk:
pt = "POST"
elif "Get" in jk or "GET" in jk:
pt = "POST"
elif "Delete" in jk or "DELETE" in jk:
pt = "POST"
elif "Put" in jk or "PUT" in jk:
pt = "POST"
elif "@RequestMapping" in jk:
pt = "GET/POST"
else:
pt = "UNKNOWN"
if len(jk.strip().split("\"")) == 1:
jk = ""
else:
jk = jk.strip().split("\"")[1].split("\"")[0]
ss.write(aa + 1, 0, z.strip(), style_row)
new_s = ""
if "" != s:
new_s = str(s.strip().split("\"")[1].split("\"")[0] + "/" + jk).replace("//", "/")
new_s = ("/" + new_s).replace("//", "/").strip()
ss.write(aa + 1, 1, new_s, style_row)
else:
new_s = jk.replace("//", "/")
new_s = ("/" + new_s).replace("//", "/").strip()
ss.write(aa + 1, 1, new_s, style_row)
ss.write(aa + 1, 2, pt.strip(), style_row)
s6 = ff
s6 = s6[:s6.find("<")] + s6[s6.find("<"):s6.rfind(">")].replace(",", "$") + s6[s6.rfind(">"):]
s6 = s6[s6.find("(") + 1:s6.rfind(")")]
c = s6.count("(")
for i in range(c):
s6 = s6[:s6.find("(")] + s6[s6.find("(") + 1:s6.find(")")].replace(",", "").replace("",
"") + "" + s6[
s6.find(
")") + 1:]
p6 = s6.split(",")
n6 = ""
for u6 in p6:
if u6 != "" and "HttpServetRequest".lower() not in u6.lower() and "HttpServetResponse".lower() not in u6.lower():
u6 = u6.replace("$", ",")
k6 = u6.split(" ")[-2:][0]
v6 = u6.split(" ")[-2:][1]
n6 = n6 + k6 + ":" + v6 + "\n"
ss.write(aa + 1, 3, get_word(zh), style_row)
ss.write(aa + 1, 4, n6[:n6.rfind("\n")].strip(), style_row)
ss.write(aa + 1, 5, zh.strip(), style_row)
ss.write(aa + 1, 6, ff.strip(), style_row)
i_c = i_c + 1
create_interface_table(bb, i_c, pt.strip(), new_s)
create_interface_canshu(bb, i_c, n6[:n6.rfind("\n")].strip(), zh.strip())
# 设置代码块
# document.add_paragraph(zh.strip())
# document.add_paragraph(ff.strip())
aa = aa + 1
def create_interface_table(l, i_c, a, b):
docment.add_heading(str(l) + "." + str(i_c) + "接口地址", level=2).bold = False
# 产生一个表格
table = docment.add_table(5, 3)
table.style = "Light Shading Accent 5"
heading_cells = table.rows[0].cells
heading_cells[0].text = "序号"
heading_cells[1].text = "接口选项"
heading_cells[2].text = "描述"
row_cells = table.rows[1].cells
row_cells[0].text = "1"
row_cells[1].text = "REST-HTTP-METHOD"
row_cells[2].text = a
row_cells = table.rows[2].cells
row_cells[0].text = "2"
row_cells[1].text = "REST-URI-Fragment"
row_cells[2].text = b
row_cells = table.rows[3].cells
row_cells[0].text = "3"
row_cells[1].text = "Content-Type"
row_cells[2].text = ""
row_cells = table.rows[4].cells
row_cells[0].text = "4"
row_cells[1].text = "Accept"
row_cells[2].text = ""
def create_interface_canshu(l, i_c, a, b):
docment.add_heading(str(l) + "." + str(i_c) + ".1 接口参数", level=3).bold = False
if a == "":
table = docment.add_table(2, 4)
table.style = "Light Shading Accent 5"
heading_cells = table.rows[0].cells
heading_cells[0].text = "序号"
heading_cells[1].text = "字段名"
heading_cells[2].text = "类型"
heading_cells[2].text = "说明"
return
r_l = a.split("\n")
table = docment.add_table(len(r_l) + 1, 4)
table.style = "Light Shading Accent 5"
heading_cells = table.rows[0].cells
heading_cells[0].text = "序号"
heading_cells[1].text = "字段名"
heading_cells[2].text = "类型"
heading_cells[2].text = "说明"
# 处理说明的内容
s_m = {"1": 2}
if b != "":
shuo_b = b.split("\n")
for s_b in shuo_b:
if "@param" in s_b and len(s_b.strip().split(" ")) >= 4:
s_m[s_b.strip().split(" ")[2]] = s_b.strip().split(" ")[3]
rr_l = 0
for rl in r_l:
row_cells = table.rows[rr_l + 1].cells
row_cells[0].text = str(rr_l + 1)
row_cells[1].text = rl.split(":")[1]
row_cells[2].text = rl.split(":")[0]
try:
row_cells[3].text = s_m[rl.split(":")[1]]
except:
pass
rr_l += 1
def get_word(zh):
z1 = ""
if zh != "":
zh_list = zh.replace("/**", "").replace("*/", "").split("*")
for row_zh in zh_list:
if "@" in row_zh or row_zh.strip() == "":
continue
z1 = z1 + row_zh + "\n"
return z1.replace("\n", "").strip()
# 获取创建人
def get_creator_user(zh):
z1 = ""
if zh != "":
zh_list = zh.replace("/**", "").replace("*/", "").split("*")
for row_zh in zh_list:
if "@author" in row_zh:
z1 = row_zh.strip().split(" ")[1]
break
return z1
# 获取创建时间
def get_creator_time(zh):
z1 = ""
if zh != "":
zh_list = zh.replace("/**", "").replace("*/", "").split("*")
for row_zh in zh_list:
if "@since" in row_zh:
z1 = row_zh.strip().split(" ")[1]
break
return z1
def get(str1):
rr = ""
if len(str1.split("(")) == 1 and len(str1.split(")")) == 1:
for s in str1.split(" ")[-2:]:
rr = rr + " " + s
return rr.strip()
for s in str1.split["("][1:]:
rr = rr + s
rr1 = ""
if rr == "":
for s in str1.split(")")[:-1]:
rr1 = rr1 + s
if "" != rr1:
rr = ""
for s in rr1.split(" ")[-2:]:
rr = rr + " " + s
else:
for s in rr.split(")")[:-1]:
rr1 = rr1 + s
if "" != rr1:
rr = ""
for s in rr1.split(" ")[-2:]:
rr = rr + " " + s
return rr.strip()
if __name__ == "__main__":
print("*注:仅从.java后缀的文件中识别接口")
i = input(r"输入项目地址(会在项目的统计目录下生成doc文档和xls文档,例如:c:\project):")
# i = r"D:\python-project\springboot-plus-master"
o = ""
c_o = ""
if not i.endswith("\\"):
o = "\\" + str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".xls"
c_o = "\\" + str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".docx"
else:
o = str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".xls"
c_o = str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".docx"
p(i)
if i.endswith(".java"):
i = i.split(".")[0]
o = str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".xls"
c_o = str(datetime.datetime.now()).replace(" ", "").split(".")[0].replace(":", "-").replace("-",
"_") + ".docx"
ee.save(i + o)
docment.save(i + c_o)
input('* 请按两次任意键退出>>>>>>>>>>>>>')
input("")
注意事项
1、代码中间经过脱敏处理,然后基本上不可读了,但是其中的一些生成规则啊,其实还是可以看的懂得,也就是说你可以根据你的需求进行定制化改造。
2、代码逻辑比较简单,就是一种特殊匹配即可,匹配到了就放到篮子里,所以不建议读,看下就行了,有思路自己可以写
3、方便起见我打包成了exe程序,这个过程比较艰辛,因为环境导致我在打包过程中一直缺依赖,用不了,这一篇文章特别好,可以细读。
【问题的根本解决思路】pycharm可以运行但是pyinstaller 打包后运行exe程序出现的“ModuleNotFindError“错误
当然这个我设置了积分为0,并且禁止调分,直接下载使用就行,如果担心安全问题,可以研究一下代码自己生成exe程序,方便快捷。
点击下载 -》识别项目中的接口并生成接口文档

过去的就过去吧,至少珍惜一下眼前吧