b站刘二大人《PyTorch深度学习实践》课程第九讲多分类问题笔记与代码:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9&vd_source=b17f113d28933824d753a0915d5e3a90
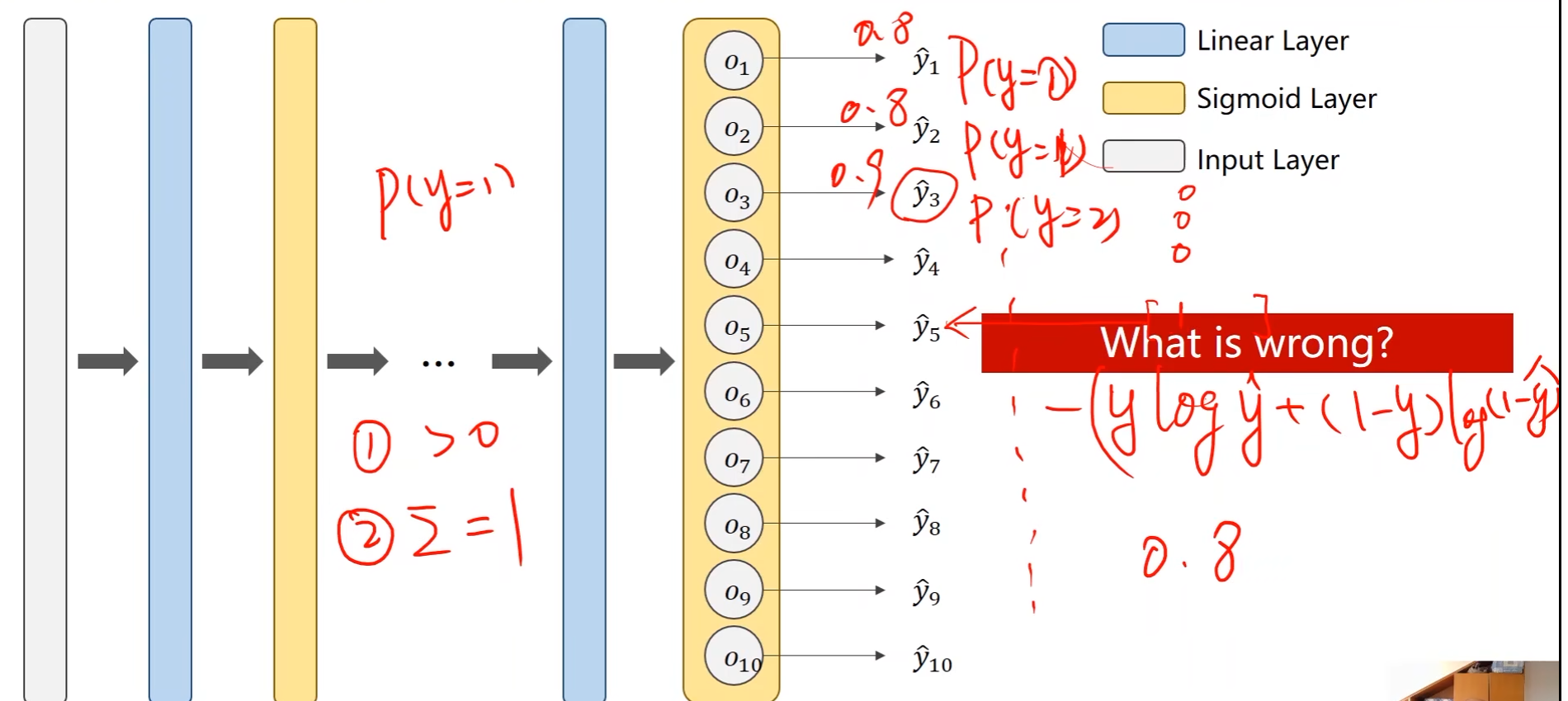
- 二分类问题中计算出 P ( y = 1 ) P(y=1) P(y=1)即可直接得到 P ( y = 0 ) P(y=0) P(y=0),即 P ( y = 0 ) = 1 − P ( y = 1 ) P(y=0) = 1 - P(y=1) P(y=0)=1−P(y=1)
- 在多分类问题中则无法这样得到,样本属于各个类别的概率是互斥的,例如某个样本属于1的概率为0.8,那么该样本属于其他数字的概率就会被抑制,变得更小,因为这个样本属于各个类别的概率的总和必须等于1
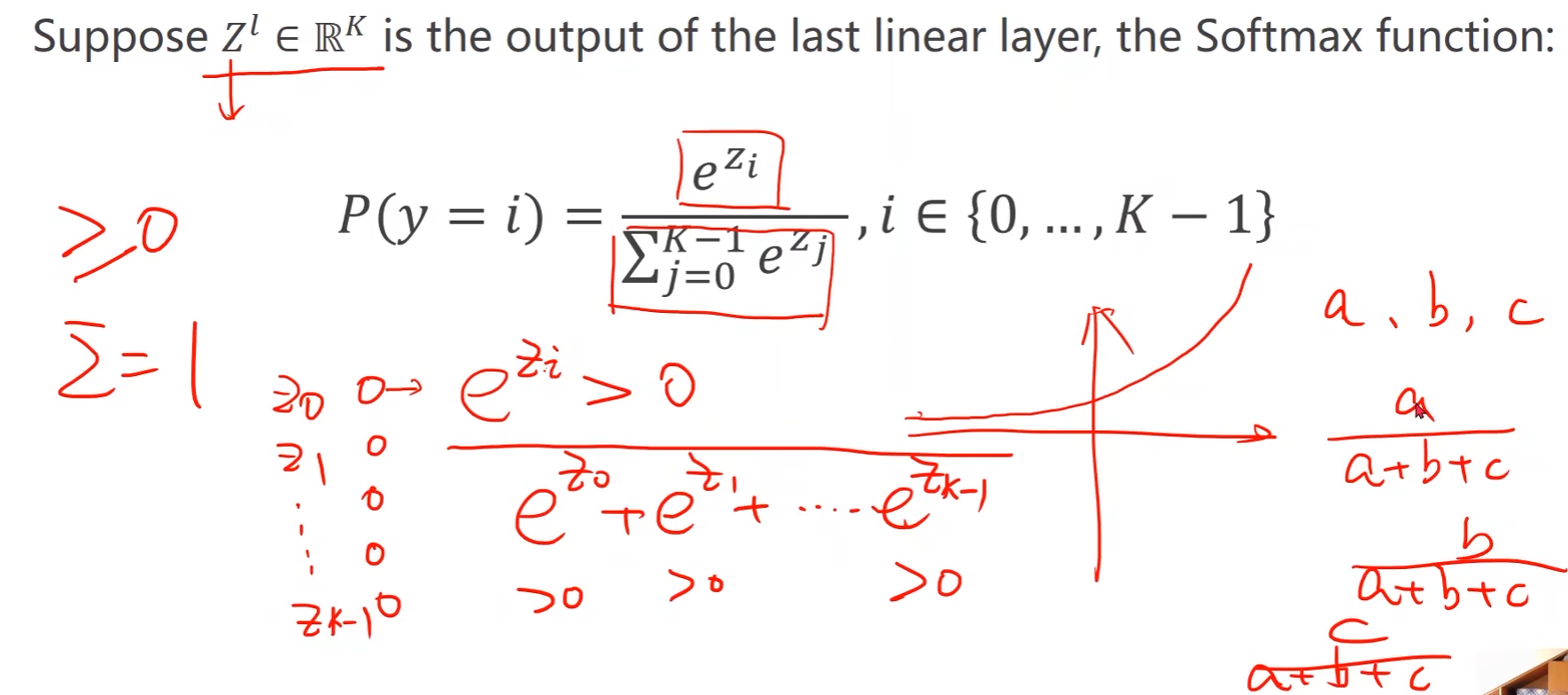
- 概率大于0
- 所有概率和等于1
- 分类问题的输出是一个分布
- 输出之间存在竞争
多分类问题中,中间用Sigmoid,输出层加Softmax,使其输出一个分布,满足概率大于0且概率和为1这两个条件
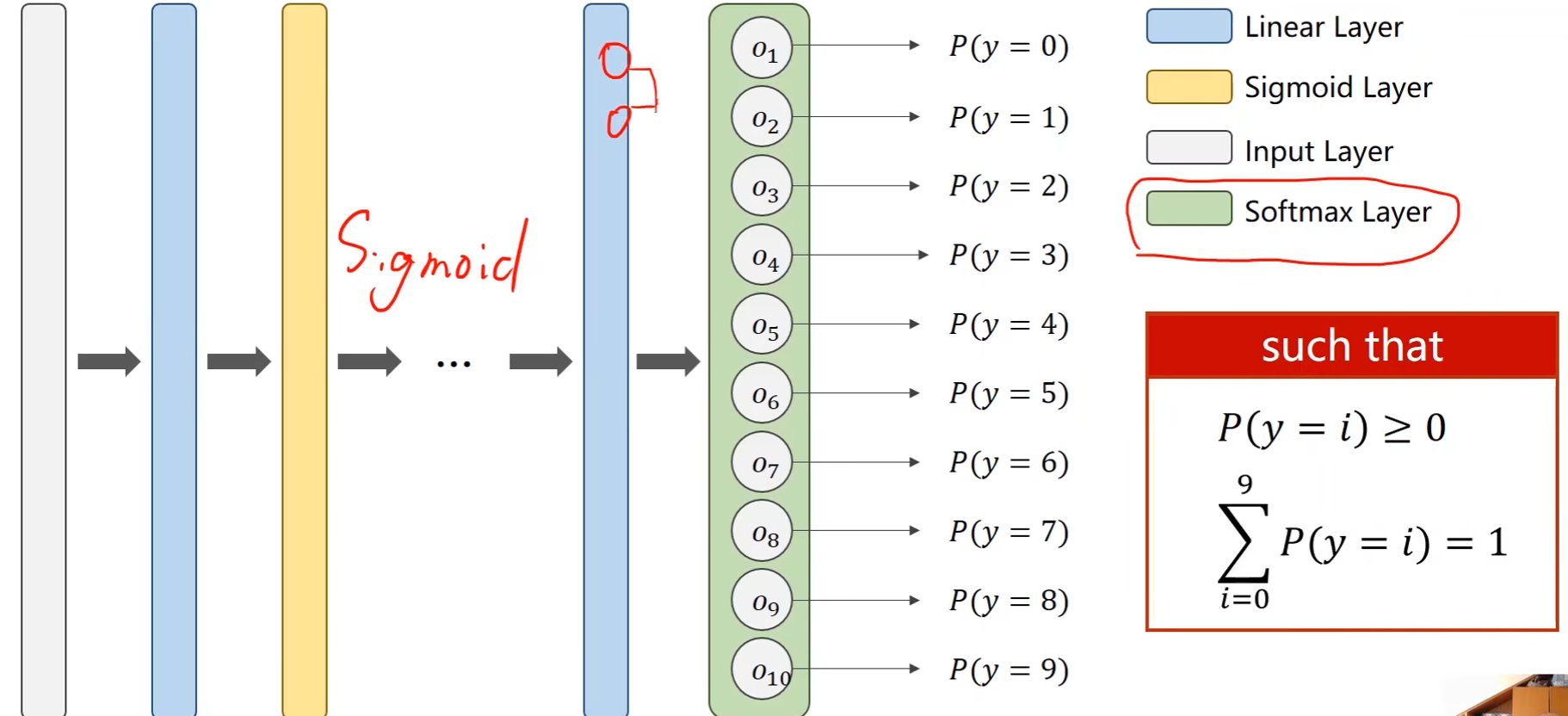
Softmax Layer
- 指数运算(exponent)一定大于0
- 所有的和作为分母 -> 保证和为1
例子:
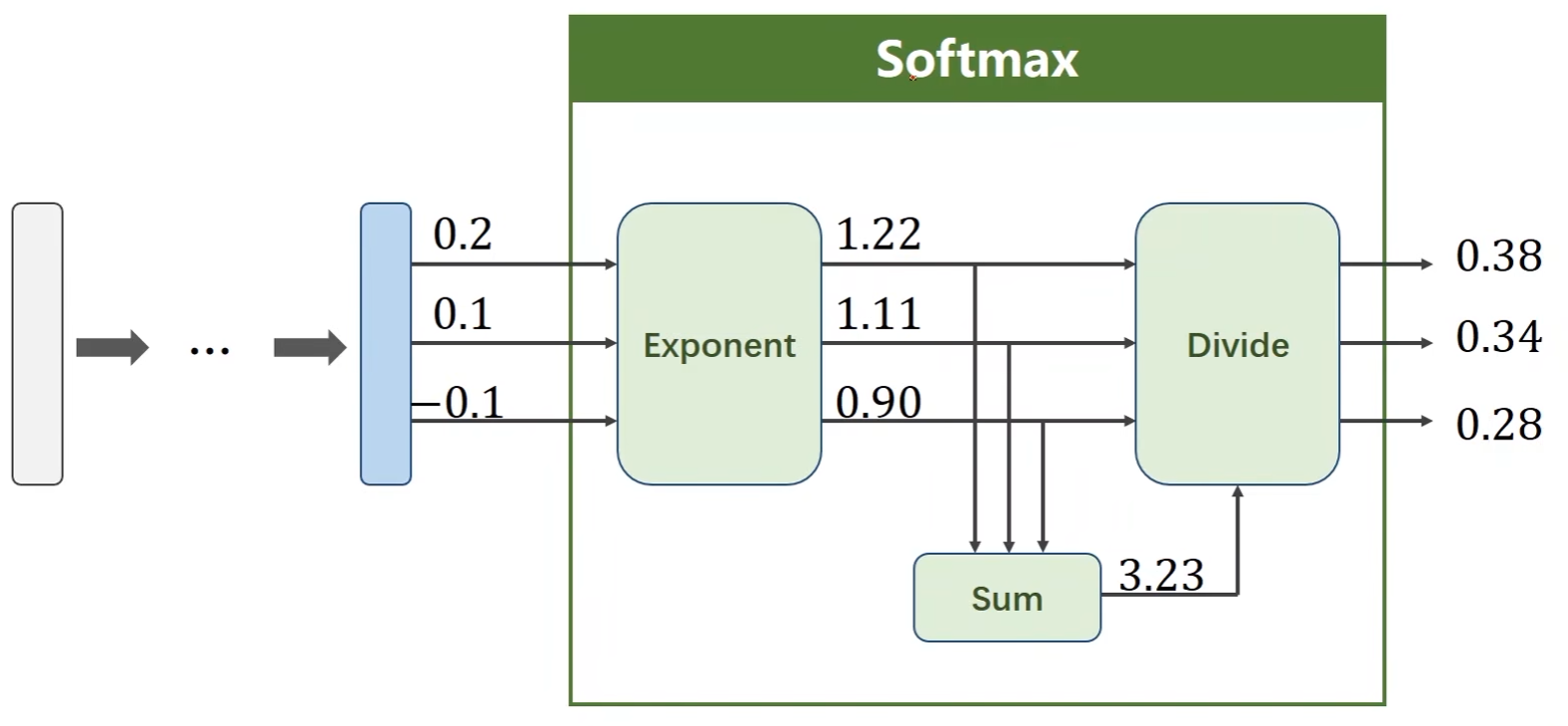
通过softmax得到一个分布后如何计算损失函数Loss ???
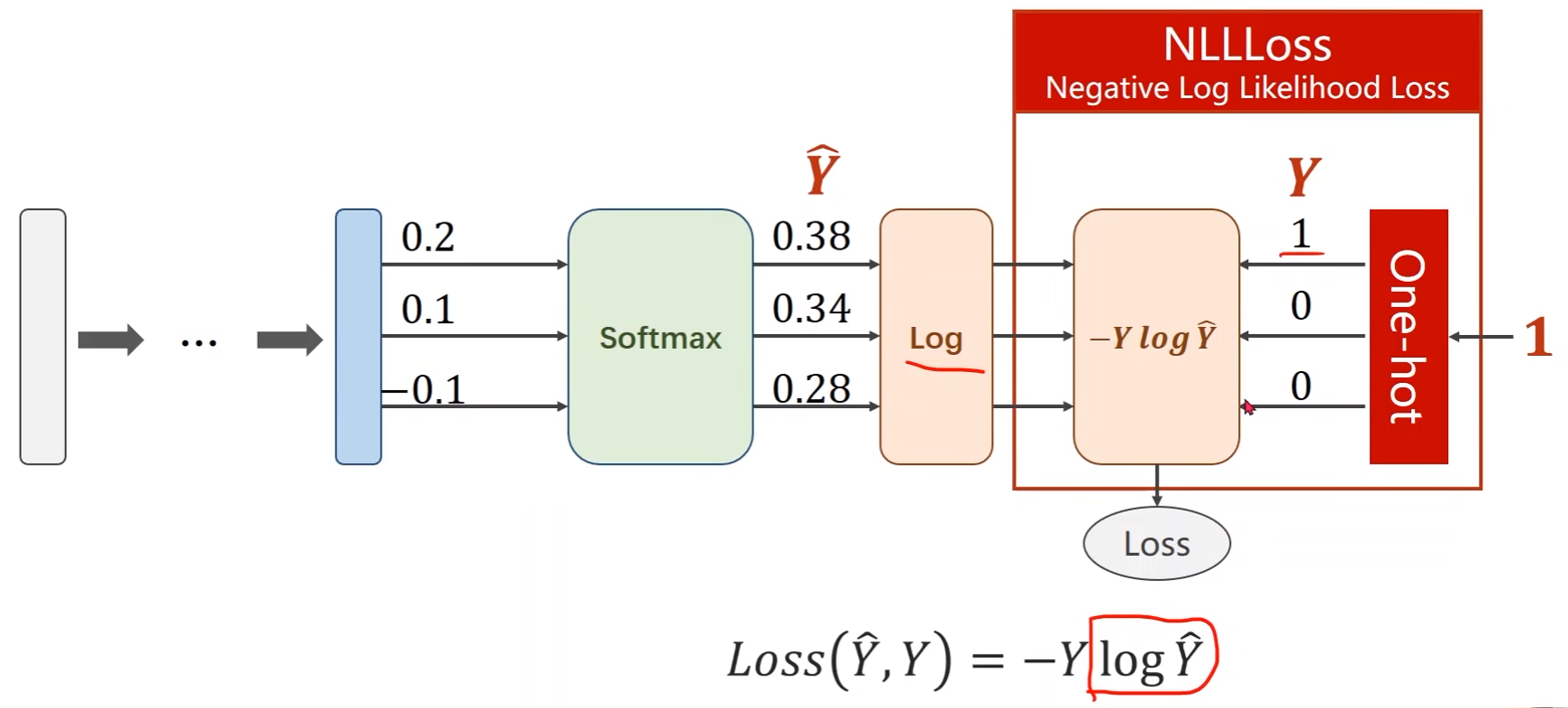
import numpy as np
y = np.array([1, 0, 0]) # 真实标签
z = np.array([0.2, 0.1, -0.1]) # softmax输入
y_pred = np.exp(z) / np.exp(z).sum() # softmax输出
loss = (-y * np.log(y_pred)).sum() # 计算loss
print(loss)
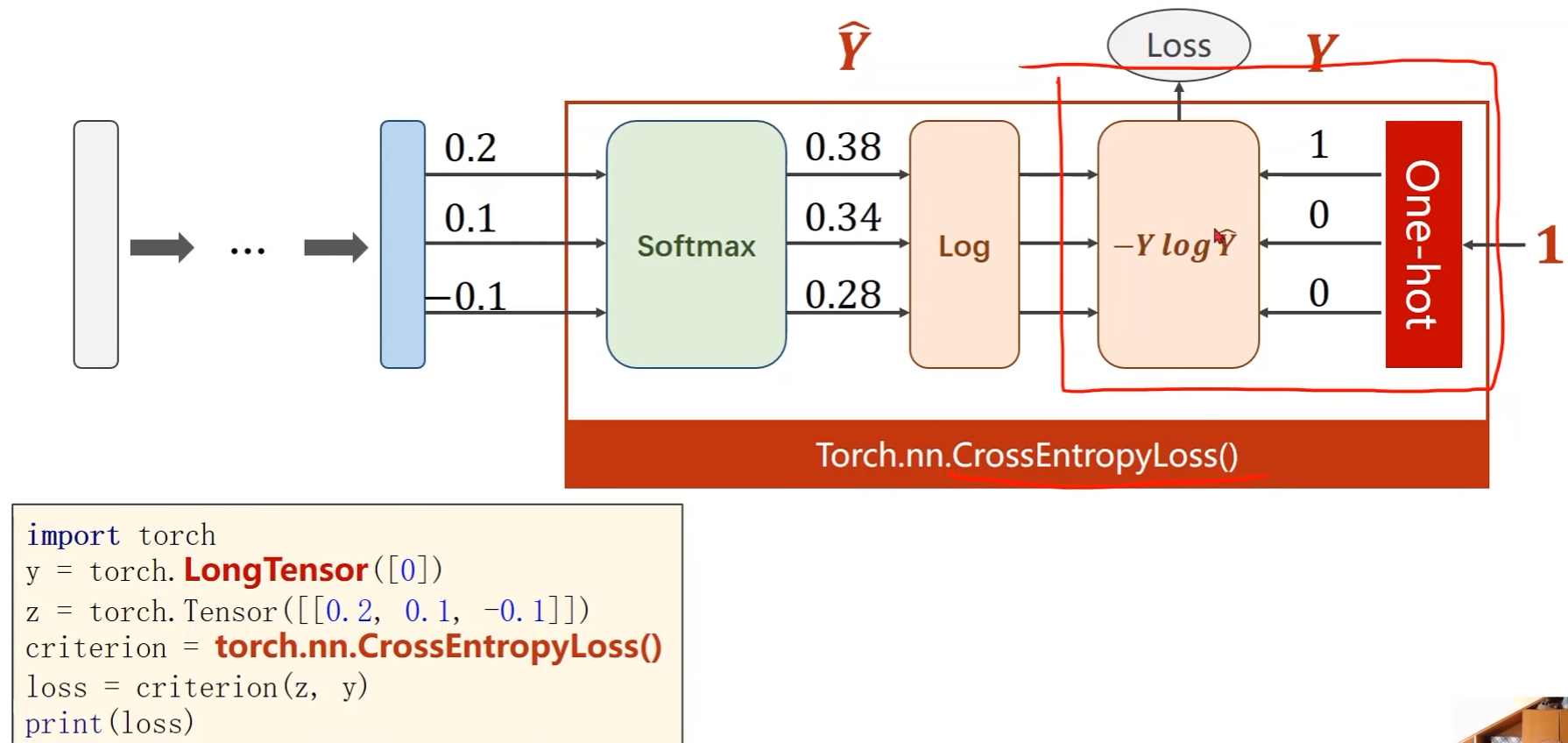
PyTorch中实现:
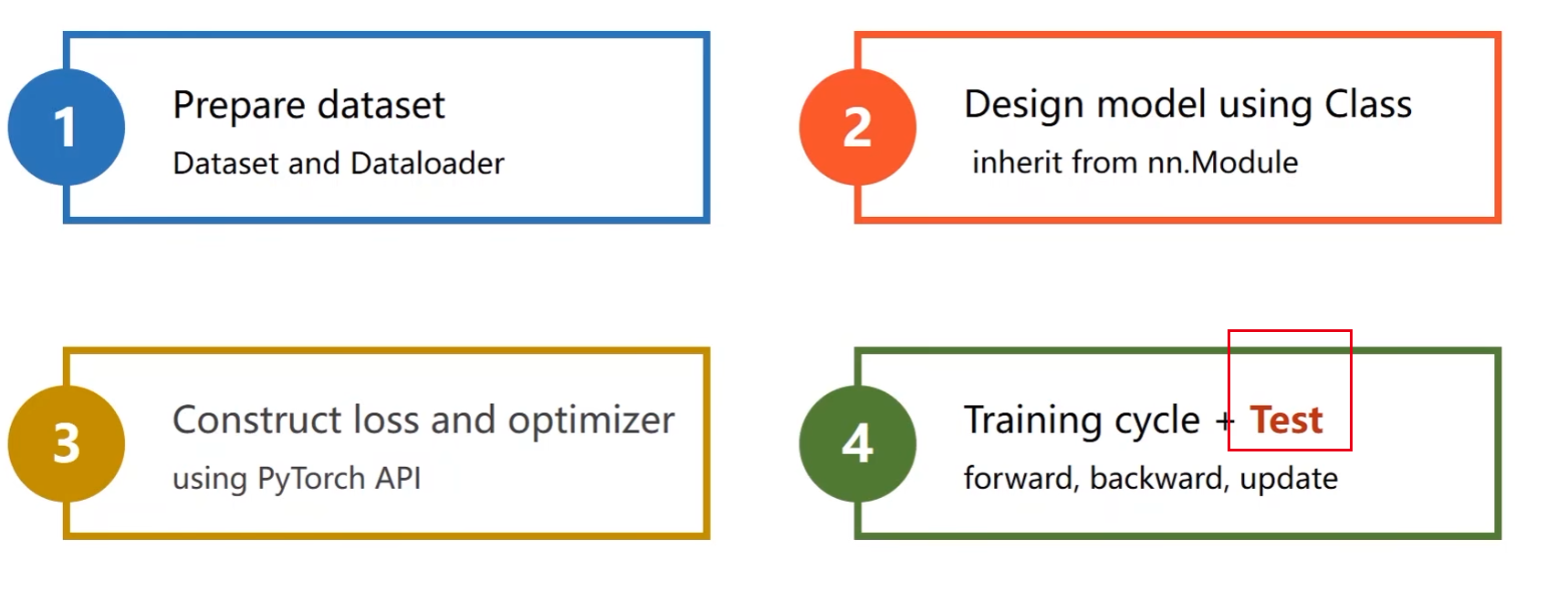
MNIST Dataset分类
- http://yann.lecun.com/exdb/mnist/

-
Import Package
- 激活函数使用更流行的Relu
import torch # 构造Dataloader from torchvision import transforms # 用于对图像进行一些处理 from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F # 使用更流行的激活函数Relu import torch.optim as optim # 构造优化器 -
Prepare Dataset
batch_size = 64 # 将PIL图像转成Tensor transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) ]) # 训练集 train_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist', train=True, download=True, transform=transform) # 读取到某个数据后就直接进行transform处理 train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size) # 测试集 test_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist', train=False, download=True, transform=transform) test_loader = DataLoader(train_dataset, shuffle=False, batch_size=batch_size)-
原始图像像素值是0 ~ 255的整数,将其转成0 ~ 1的张量
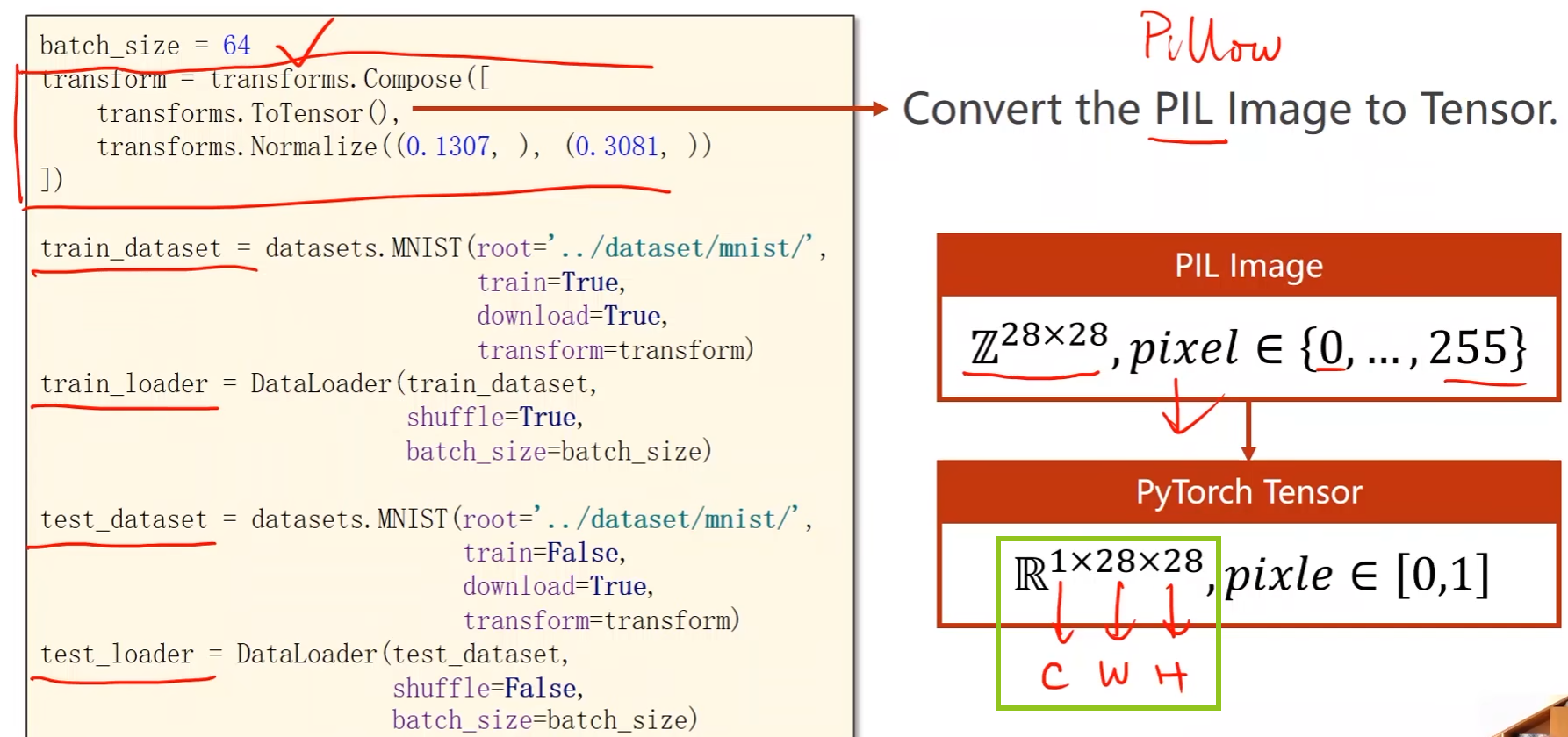
- Normalize是归一化处理。0.1307是均值,0.3081是标准差

-
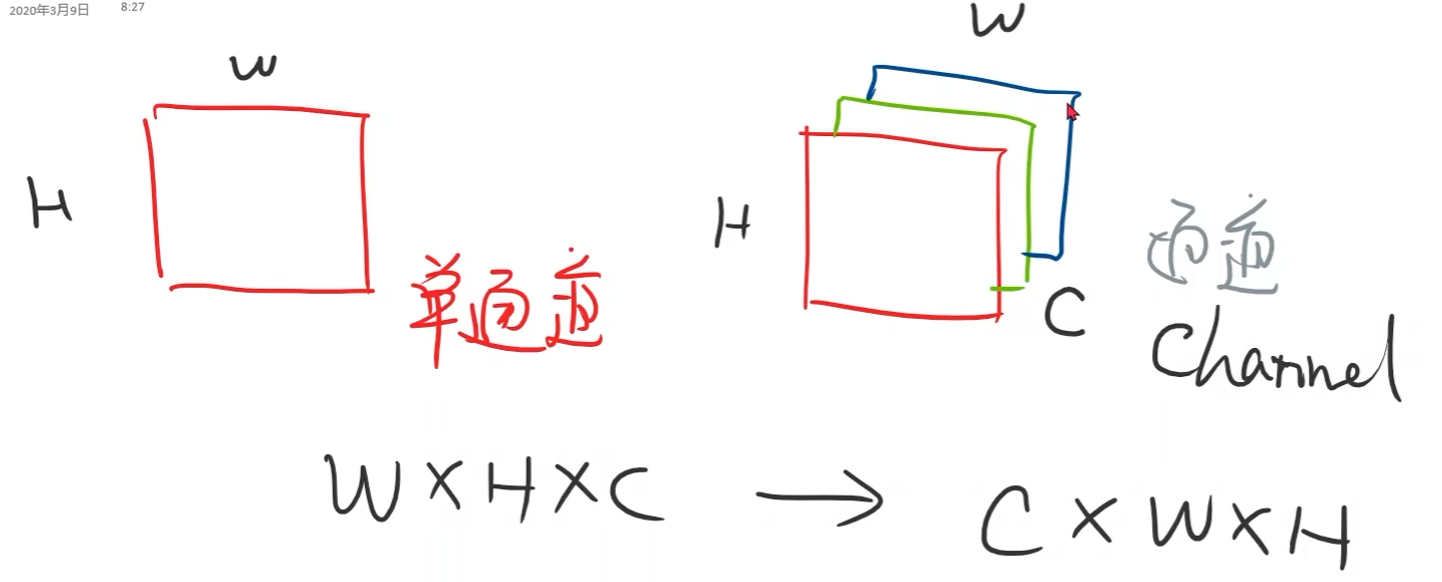
通道(H:高,W:宽,C:通道channel)
- 表示图像时一般是W * H * C,PyTorch中是C * W * H
-
-
Design Model
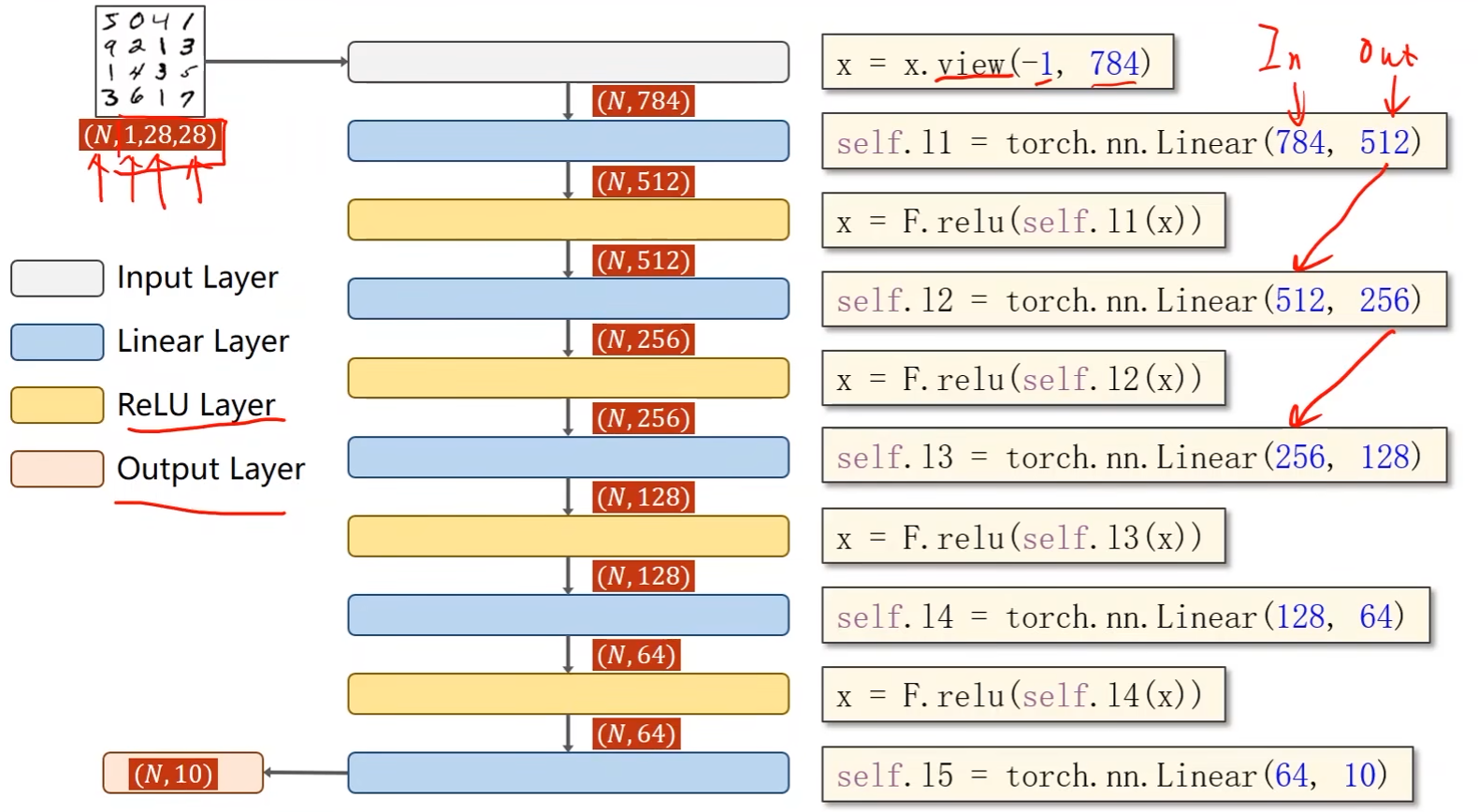
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784, 512) self.l2 = torch.nn.Linear(512, 256) self.l3 = torch.nn.Linear(256, 128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) # 最后一层不做激活,要直接输到softmax中 model = Net() -
Construct Loss and Optimizer
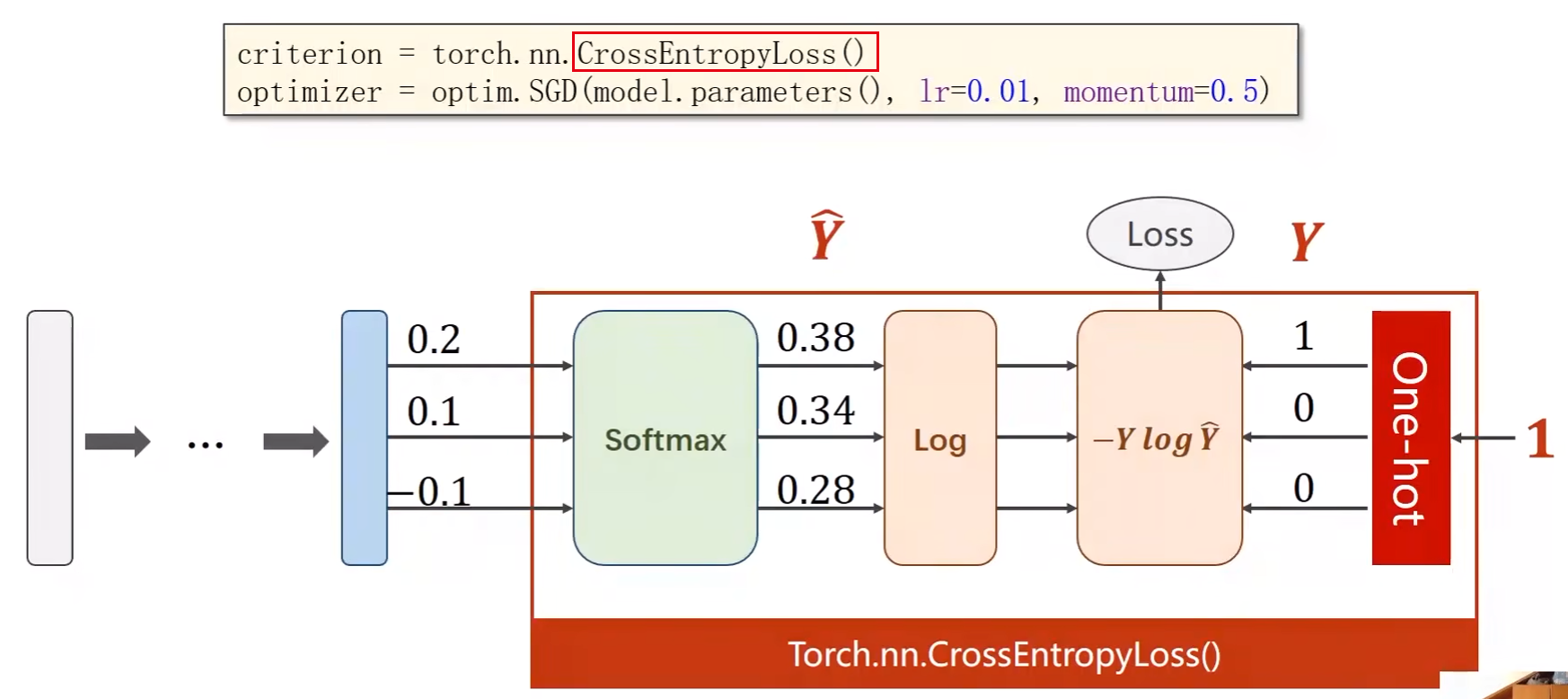
criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 带冲量(momentum)的梯度下降 -
Train and Test
- 将一轮循环封装成函数,简化代码复杂度
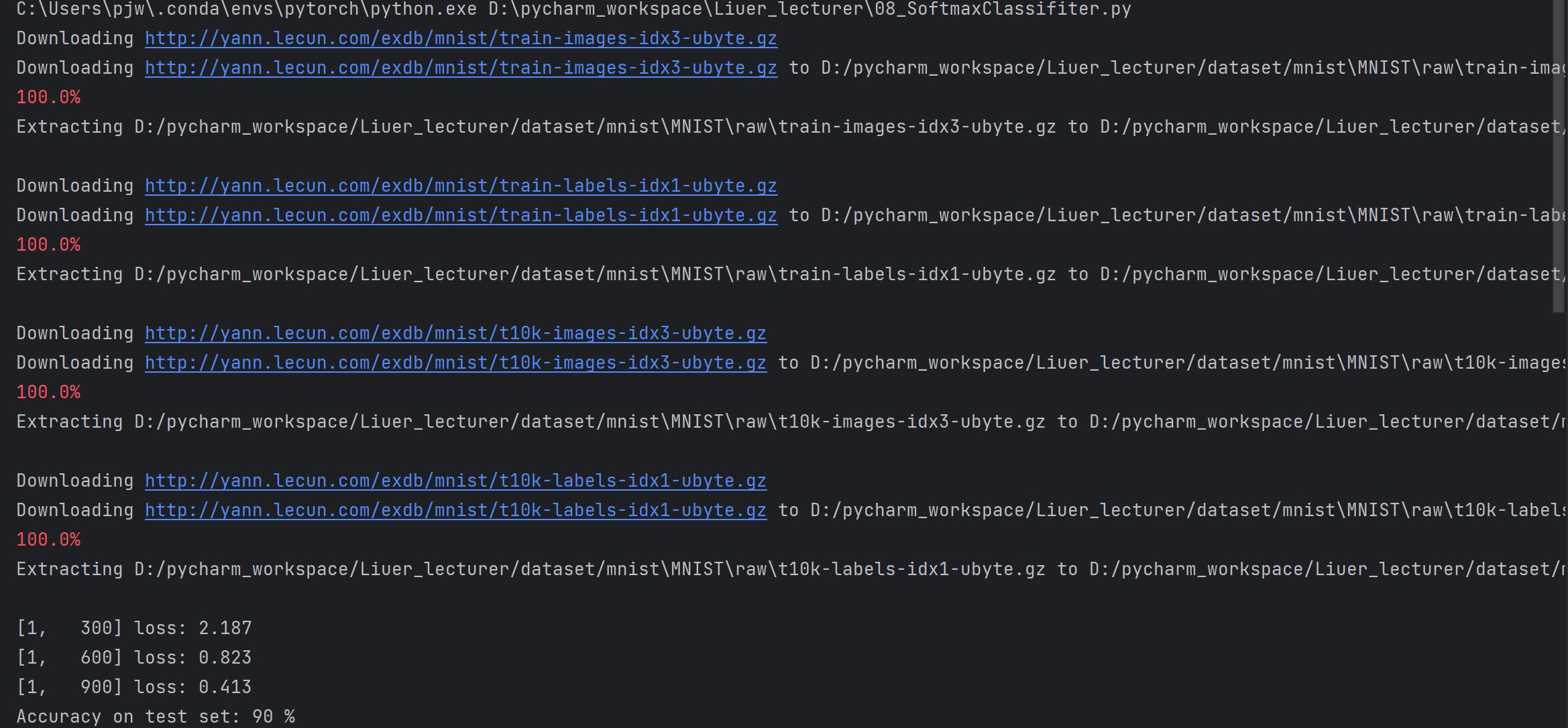
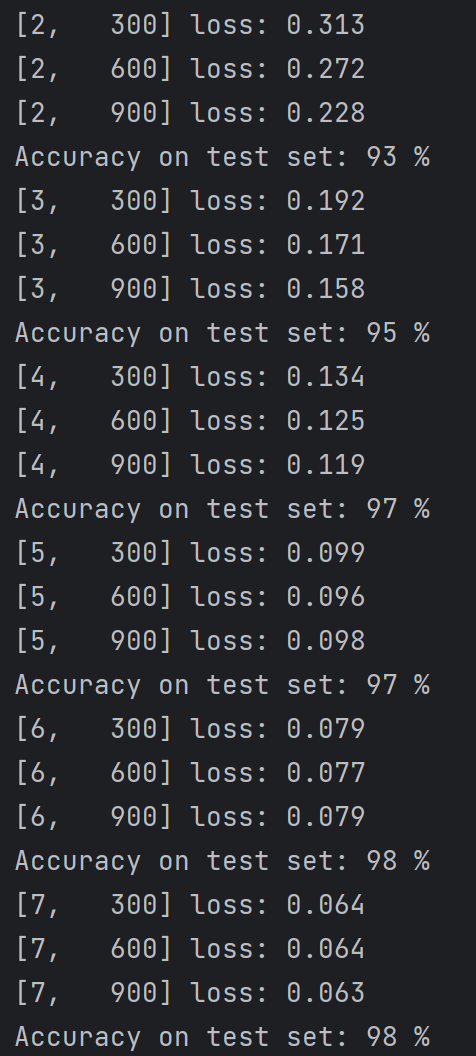
# 一轮训练 def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data # inputs输入x,target输出y optimizer.zero_grad() # forward + backward + update outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() # loss累加 # 每300轮输出一次,减少计算成本 if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300)) running_loss = 0.0 # 测试函数 def test(): correct = 0 total = 0 with torch.no_grad(): # 让后续的代码不计算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total))
完整的代码:
import torch
# 构造Dataloader
from torchvision import transforms # 用于对图像进行一些处理
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 使用更流行的激活函数Relu
import torch.optim as optim # 构造优化器
batch_size = 64
# Compose的实例化
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转成Tensor
transforms.Normalize((0.1307, ), (0.3081, )) # 归一化。0.1307是均值,0.3081是标准差
])
# 训练集
train_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',
train=True,
download=True,
transform=transform) # 读取到某个数据后就直接进行transform处理
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root='D:/pycharm_workspace/Liuer_lecturer/dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(train_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 带冲量的梯度下降
# 一轮训练
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data # inputs输入x,target输出y
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # loss累加
# 每300轮输出一次,减少计算成本
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
# 测试函数
def test():
correct = 0
total = 0
with torch.no_grad(): # 让后续的代码不计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()