文章目录
- 数据库基础
- 服务器,数据库,表关系
- Mysql的架构
- Sql分类
- 库的操作
- 修改默认的编码格式
- 两种校验
- 修改数据库
- 删除数据库
- 备份和恢复
- 观察用户,查看连接
- 表的操作
- 修改表字段长度
- 删除某一列
- 修改表名
- 修改列名称
- 数据类型
- 小数类型
- float
- decimal
- 字符串类型
- char
- varchar
- 日期时间
- enum 和 set
- 表的约束
- 空属性
- 默认值
- 列描述
- zerofill
- 主键
- 复合主键
- 自增长
- 唯一键
- 外键
- 表的操作
- NULL的比较
- and / or
- in
- 模糊匹配
- order by
- limit
- REPLACE
- update 语句
- 删除
- 插入查询结果
- 表的筛选字段
- group by
- having
- interval
- mysql的字符串函数
- conv
- 向上,向下取整
- ifnull
- union
- union all
- 总结
数据库基础
为什么要有数据库?
文件保存的缺点:安全性,文件删除,文件可能被用户恶意访问。
进程将数据从文件刷新到文件,而且要是刷新的数据过大,导致操作失败。
即文件的保存是不靠谱的
数据库是一个具有客户端,具有服务端的网络程序。
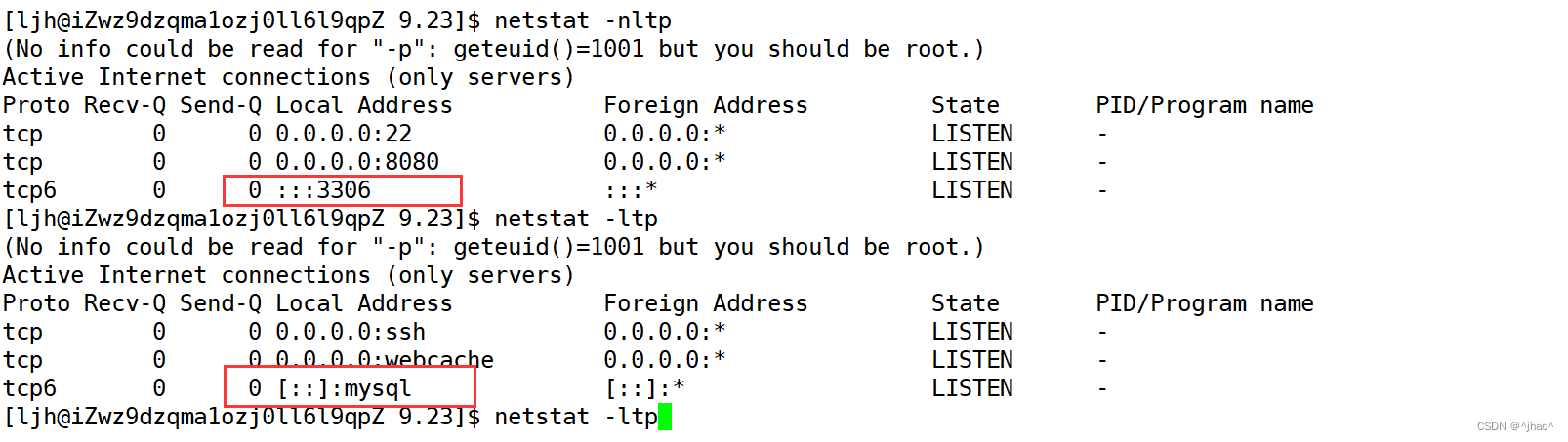
通过netstat -nltp 可以查看到mysql是一款ipv6的一款网络程序,占用3306的端口号。
[ljh@iZwz9dzqma1ozj0ll6l9qpZ 9.23]$ mysql -uroot -p
通过mysql命令行,输入密码就可以登入mysql 了。注意,这里用mysql -uroot -p 登入实际上我是一个客户端。
mysql> show databases;
通过show databases;可以查看有哪些数据库。
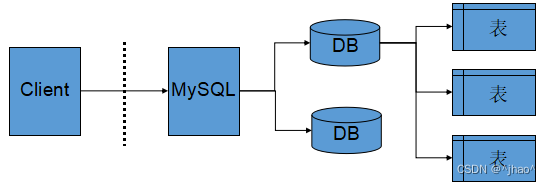
服务器,数据库,表关系
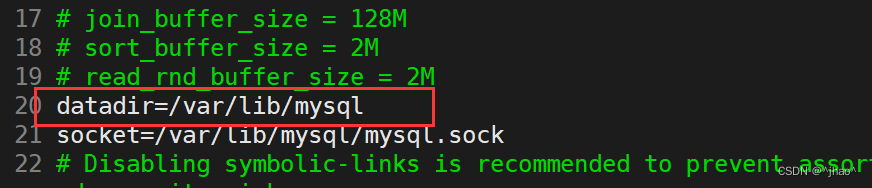
vim /etc/my.cnf 可以查看到这个数据库的文件
通过观察 /var/lib/mysql的时候可以查看有如下文件,其中我建的数据库ljh
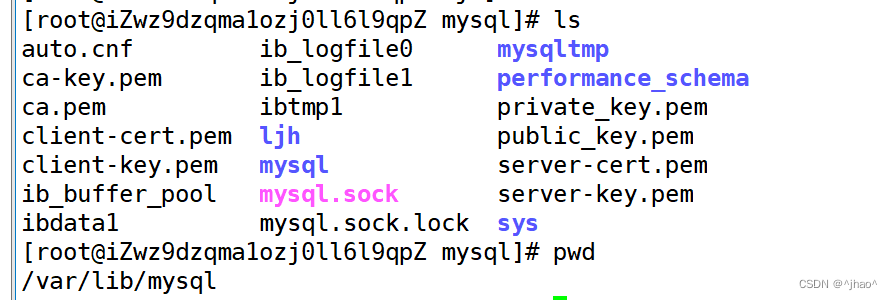
也就是所谓的数据库,实际上就是/var/lib/mysql 当中的一个文件夹
create database ljh;就可以创建一个数据库。
mysql> use ljh; Database changed
就可以切换到ljh这个数据库使用。
创建表的操作 create table [if not exists 不存在创建] + 表名(数据类型)引擎,编码
mysql> create table if not exists user( name varchar(8) not null, age int not null ) engine=InnoDB default charset=utf8;
通过show tables;指令可以查看到这个数据库的表。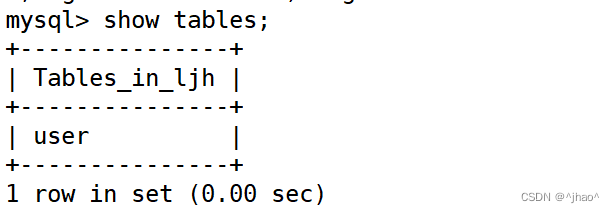
通过desc + 表名 可以查看到该表具有的字段。

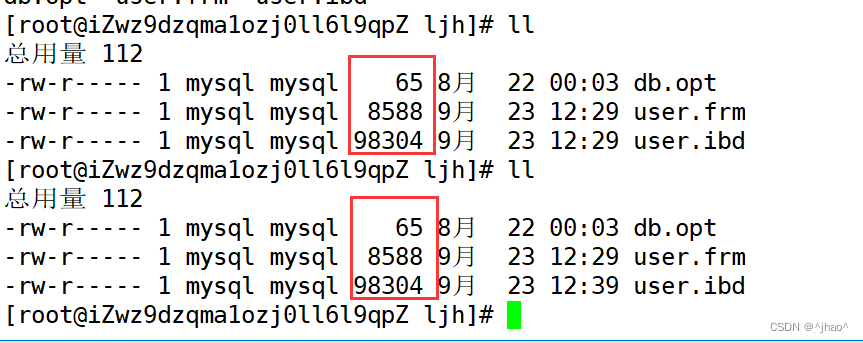
紧接着我们看看文件夹下面多了哪些文件,可以看到多了两个文件
- user.frm表示表的数据
- user.idb表示表的索引

在linux中,Mysql 在数据库的创建表结构,其实只是创建若干个普通文件。
也就是mysql client 命令行输入命令时,就可以让MySQL帮我们处理数据的存储
总结:
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,
- 一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
插入记录
mysql> insert into user ( name,age) values('张三',19);
查看插入记录
mysql> select * from user;
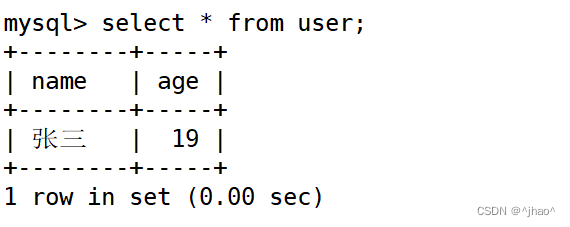
插入的时候我们观察表的数据大小,发现数据并没有刷新到文件。并且即使client 进行quit,该文件也不一定就会变大。
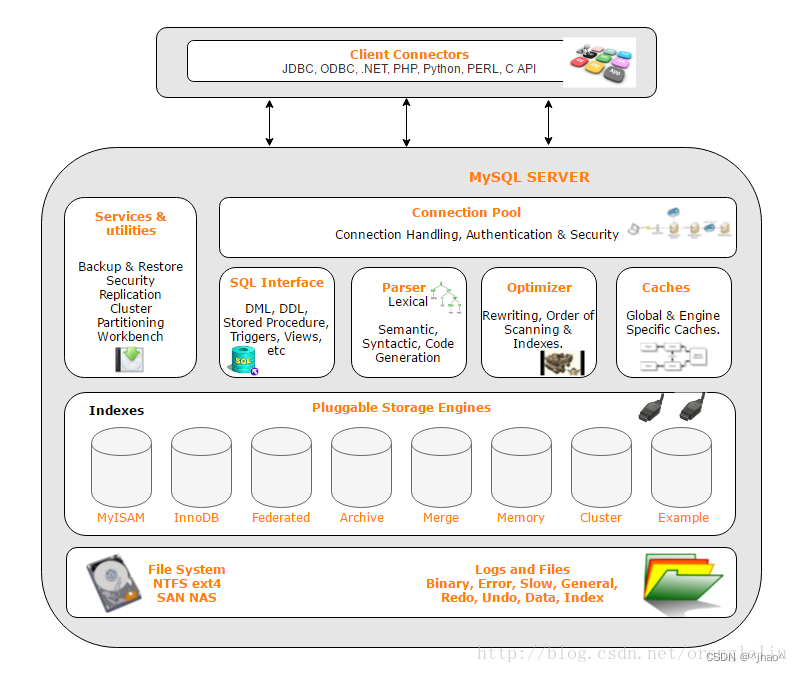
Mysql的架构
Mysql 是一个可移植的数据库,即源代码在任意平台下都可以进行跑,实际上只需要动态调用不同平台的系统调用就可以实现可移植性,通过条件编译来完成。如 Unix/Linux、Windows、Mac 和Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
Client Connections 表示客户端可以用什么语言进行连接。
Connetction Pool:类似reactor,对于连接进行管理
Sql Interface …:词法,语法分析,sql调优
Pluggable Storage Engines :表示用哪一个存储引擎实现用户的操作
文件系统: 往哪放
Sql分类
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构代表指令: create, drop, alter
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作代表指令: insert,delete,update
- DML中又单独分了一个DQL,数据查询语言,代表指令: select
- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
库的操作
修改默认的编码格式
default-storage-engine=INNODB
character_set_server=utf8
在my.cnf加上以上几行,reboot或重启mysqld,
mysql>show variables like '%storage_engine%';

mysql>show variables like 'character_set_%';
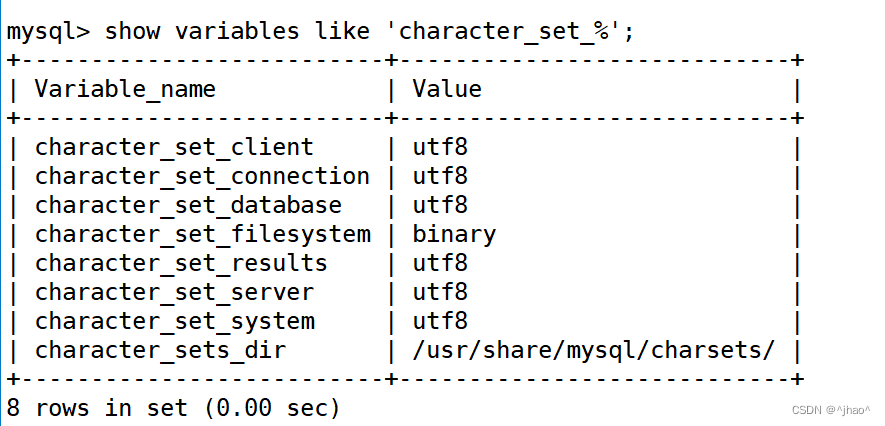
两种校验
校验是指调用select 之后的结果,通常编码我们采用utf8,那么校验规则会有不同的选择,接下来介绍两种不同的校验规则引起select的结果不同。
show variables like 'collation_database';

show variables like 'character_set_database';

对数据进行增删查改,都得对数据进行对比,比如插入的时候用utf8,但插入的时候用lation进行校验,那么就会出现问题、
创建一个用utf8_general_ci 的表。
create database test1 collate utf8_general_ci;
通过下面指令查看数据库的信息。
mysql> show create database test1;

此时通过mysql> show create table person\G;也可以看到该表的引擎和默认编码都已经是我们设置在my.cnf的。
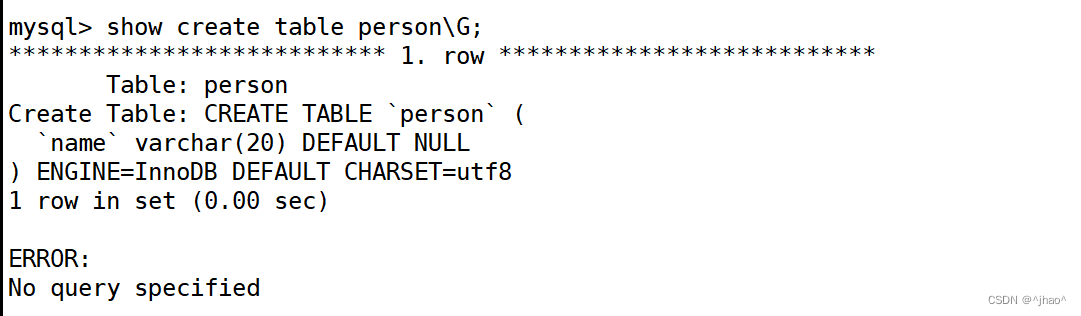
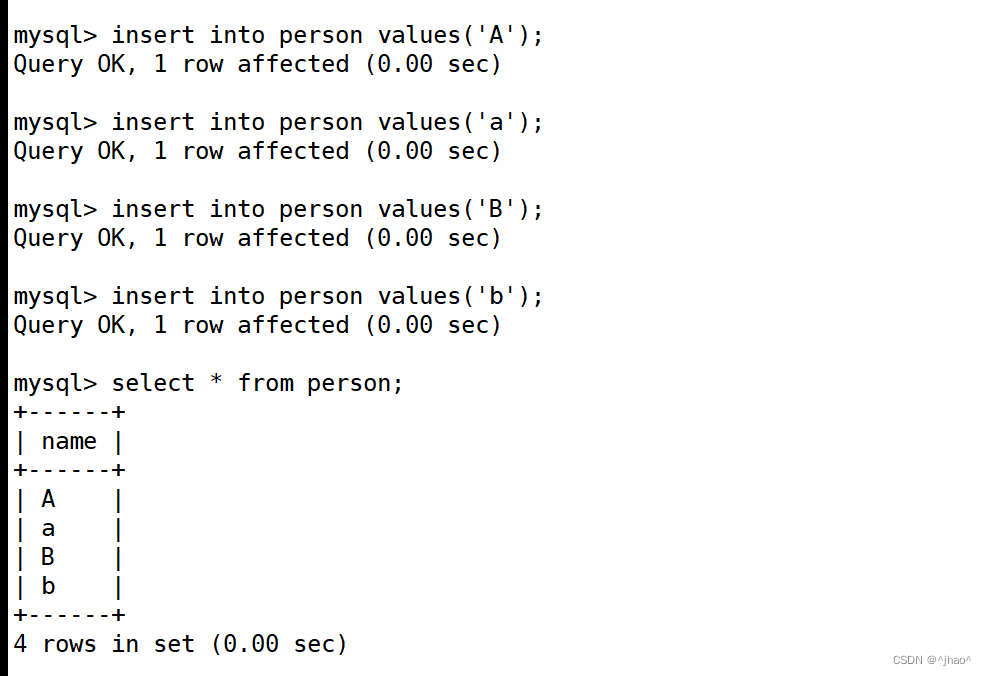
插入 a A b B的数据
mysql> insert into person values('a');

mysql> select * from person where name='b';
查看过后发现它默认是不区分大小写的。

改变校验方式:
创建test2的表,用 utf8_bin 的校验规则。
mysql> create database test2 collate utf8_bin;
mysql> show create database test2;
查看校验规则,此时时utf8编码,utf8_bin校验。

mysql> create table person (name varchar(20)); 我们依旧采用创建person 表的方式,插入同样的字符。
奇迹发生:
此时校验规则,筛选出来的数据集没有‘A’了

并且不只如此,调用order by 也会有所不同。
mysql> select * from person order by name;
表一:utf8_general_ci

表二:utf8_bin

推荐编码:utf 8 ,校验 utf8_general_ci,默认不填写校验的时候是和utf8_general_ci相同的,当然也有编码集可以显示表情包之类的。
好了,这样子不同的校验规则带来的不同也是显而易见了~
默认情况:

注意/*!40100 DEFAULT CHARACTER SET utf8 */不是注释,而是表示当前mysql版本大于4.01版本则编码用utf8.
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
修改数据库
数据库的修改尽量是在前期,后期的话倘若修改的话实际上是不好的。
ALTER DATABASE db_name [alter_spacification [,alter_spacification]...]
删除数据库
drop databases xxx;
备份和恢复
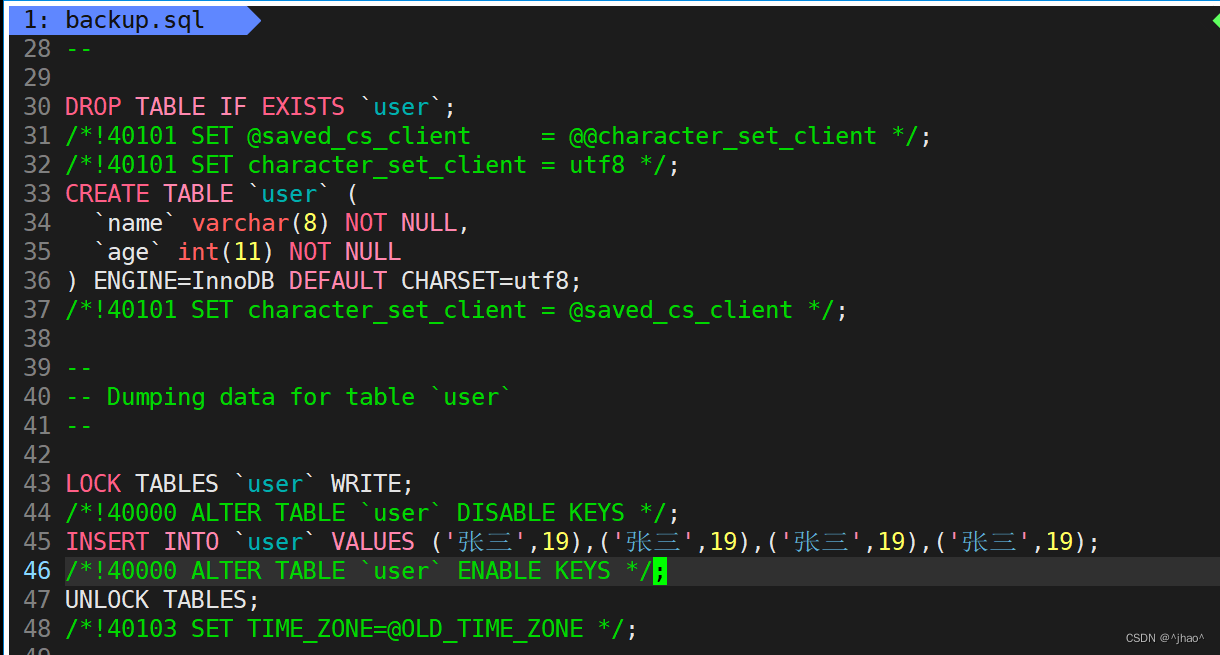
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
mysql内部有日志,bin,undo,redo,通过日志就能够将先前的sql语句获取出来,我们可以重定向到文件,然后拿到这个backup.sql。 后续可以拿backup.sql进行恢复。
[ljh@iZwz9dzqma1ozj0ll6l9qpZ ~]$ mysqldump -P3306 -uroot -p -B ljh > backup.sql;
mysql> drop database ljh;先删库,然后恢复
然后通过source 调用sql 就能够恢复ljh这个数据库了。
mysql> source ./backup.sql

-B选项若没有带上,则需要自己手动创建ljh这个数据库,之后才能执行./backup.sql
当进入数据库use ljh;,可以通过show tables;观察有哪些表。
观察用户,查看连接
mysql> show processlist;

表的操作
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
- field 表示列名
- datatype 表示列的类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
先创建一张表。
mysql> create table if not exists users(
-> id int,
-> name varchar(20) comment '用户名',
-> password varchar(30) comment '用户的密码',
-> birthday date comment '生日'
-> ) engine=InnoDB default charset=utf8;
又新增两个字段,

mysql> insert into users values(1,'a','b','1982-01-04'),(2,'b','c','1984-01-04')
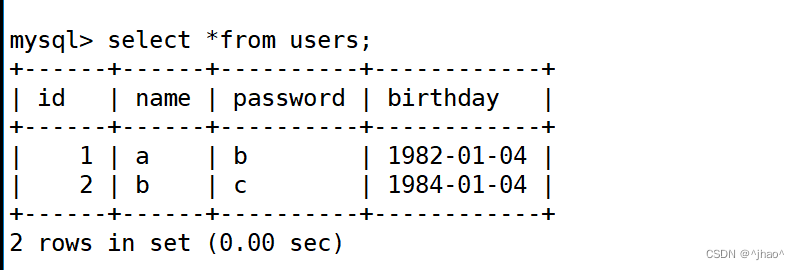
mysql> alter table users add path varchar(100) comment '图片路径' after birthday
先前数据默认为NULL
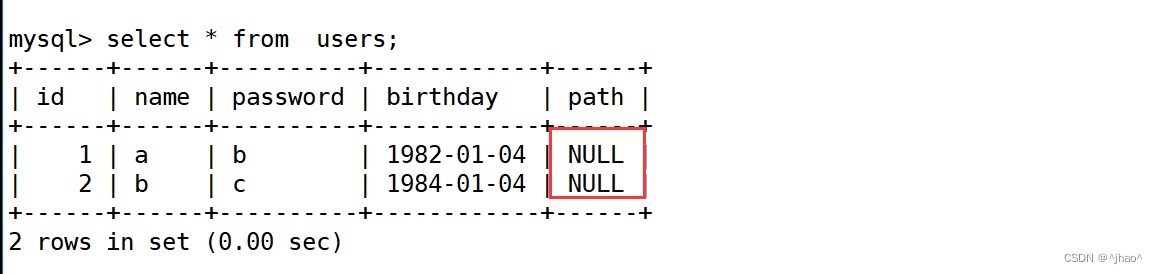
comment 语句当我们通过 show create table + 表名 的方式就可以看到有字段的注释。
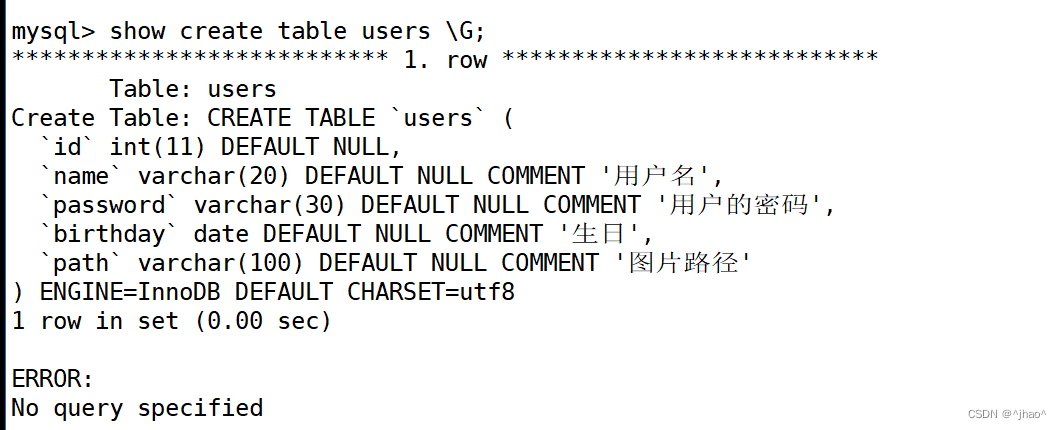
再插入一条语句。
mysql> insert into users values(3,'c','c','1983-03-04','/var/lib');
观察现象:

修改表字段长度
mysql> alter table users modify name varchar(40);
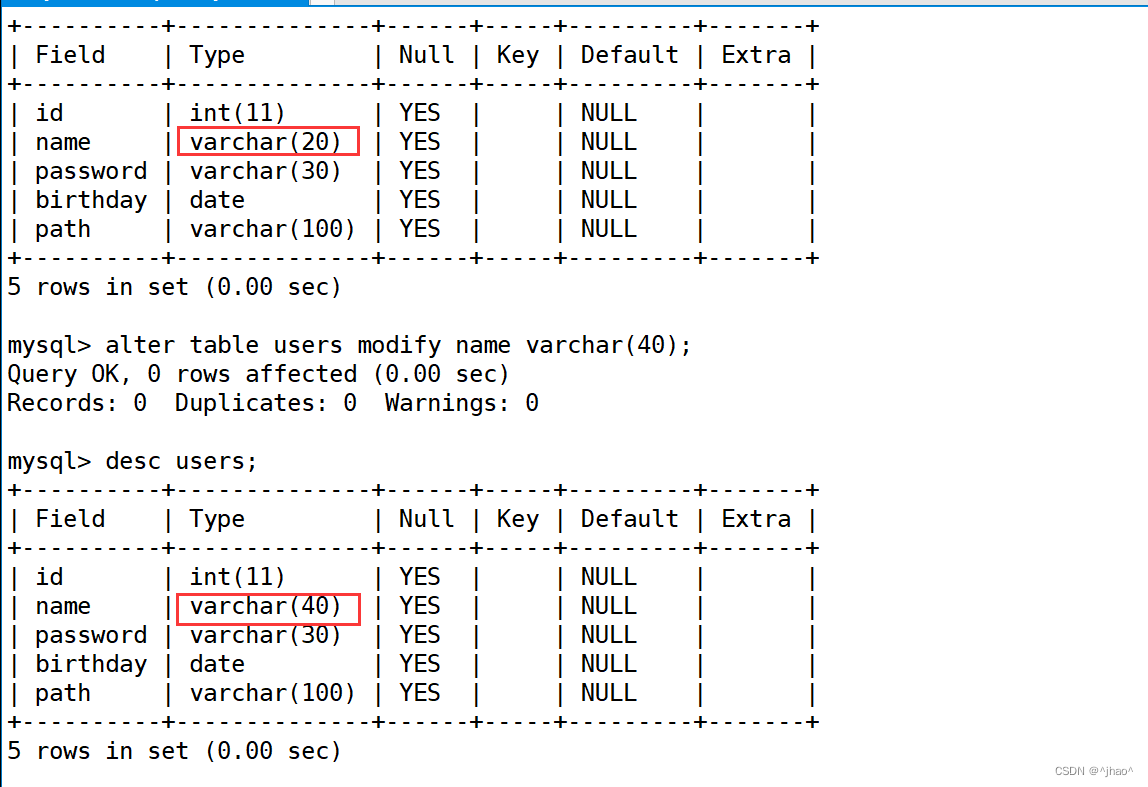
删除某一列
mysql> alter table users drop path; 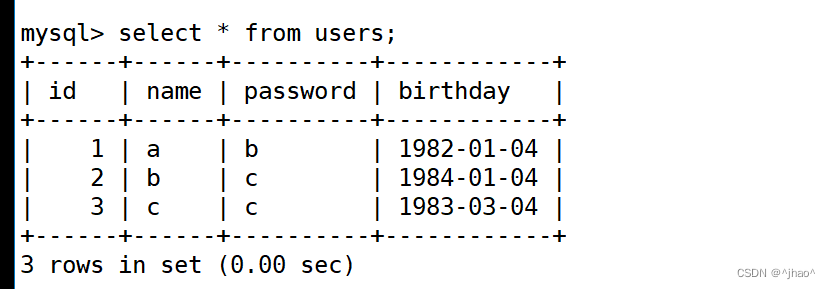
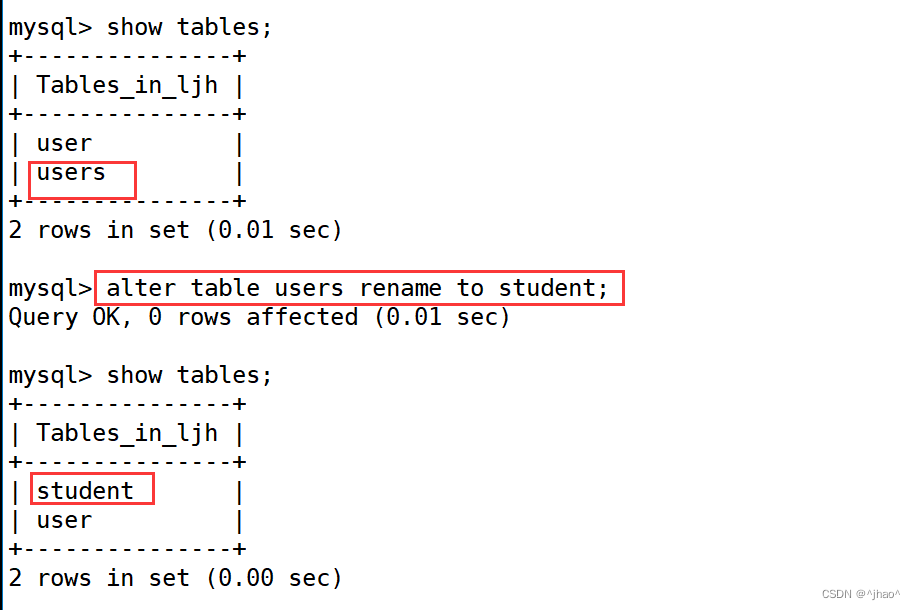
修改表名
mysql> alter table users rename to student;
修改列名称
mysql> alter table student change password passwd varchar(30); 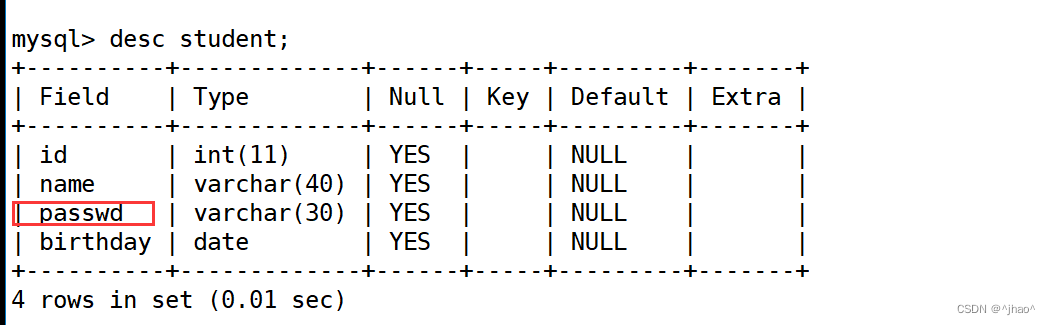
数据类型

bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
bool 类型底层是以tinyint来维护的。
mysql> create table stu(name varchar(30),sex bool);

小数类型
float
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节.
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
四舍五入体现在哪里?
mysql> create table stu (id int,salary float(4,2));
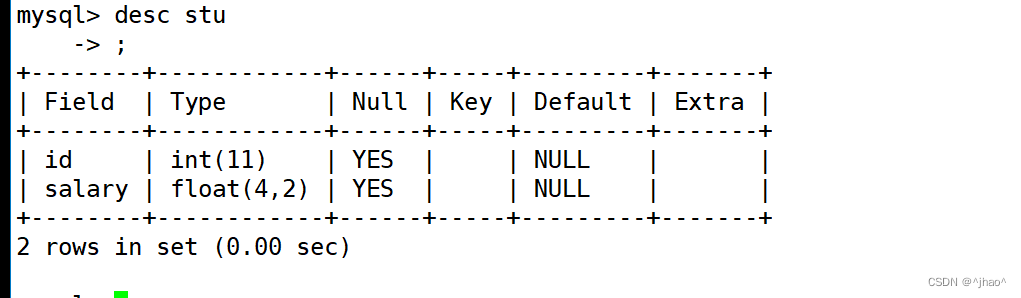

可以看出这里的的m指的是整数+小数的位数,d是小数的位数,也就是小数和整数都是固定长度的。
decimal
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
规则类似于float。
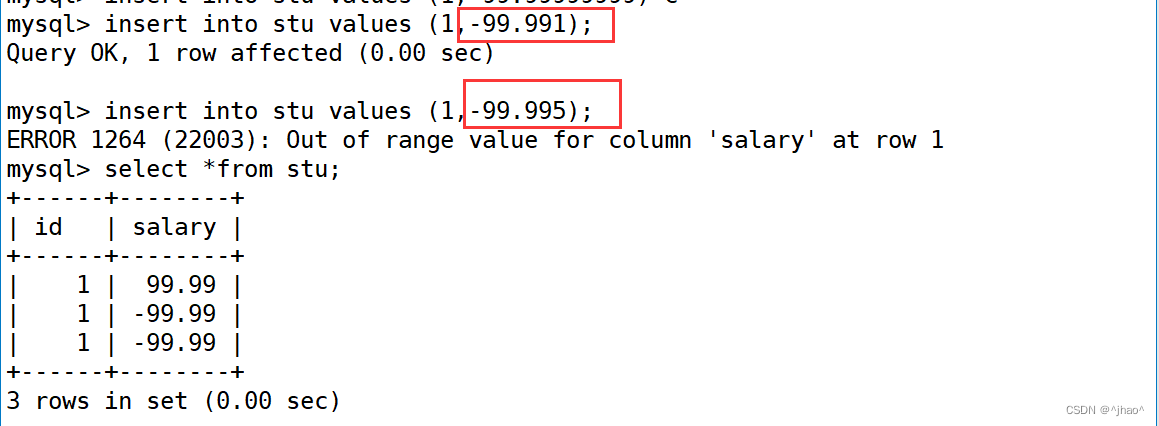
mysql> create table t2 (id int,salary decimal(4,2));
上述发现和float没有区别。其实是精度上面有区别。
原因:因为有些数据,小数部分乘二取整,有一些是取不到1的,所以转化的时候会有精度丢失。
验证:
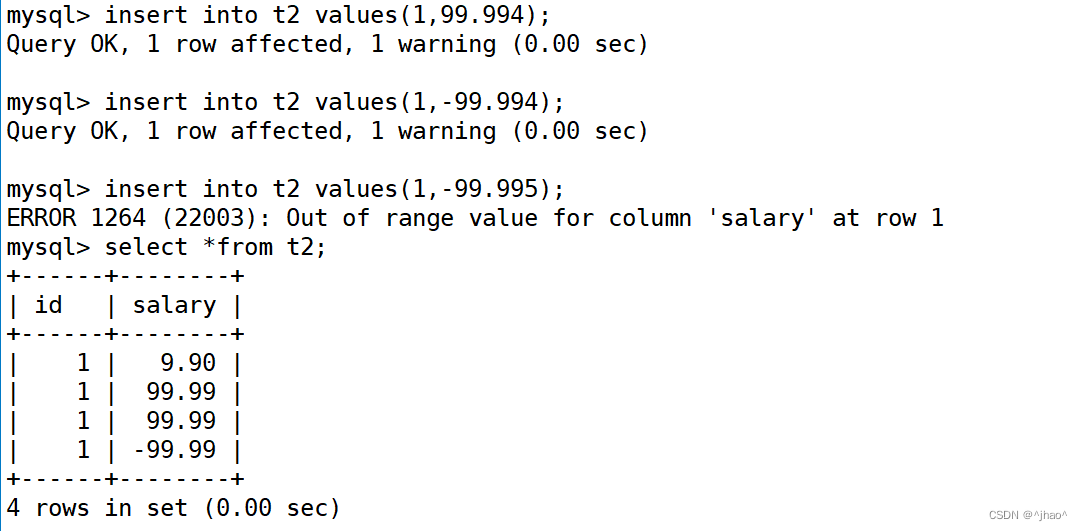
创建表
mysql> create table t3 (salay1 float(10,8),salay2 decimal(10,8));
插入一个小数点后8位的数。
mysql> insert into t3 values(12.12345678,12.12345678);
检查结果:
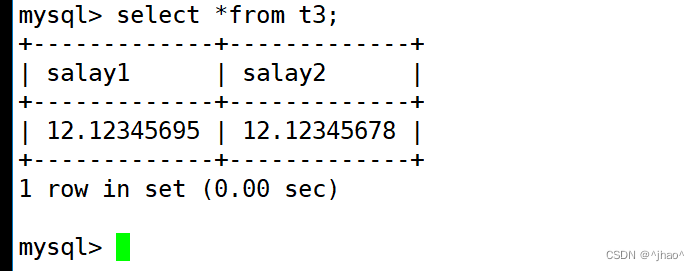
说明:float表示的精度大约是7位。
- decimal整数最大位数m为65。支持小数最大位数d是30。
- 如果d被省略,默认为0.如果m被省略,默认是10。
建议:如果希望小数的精度高,推荐使用decimal。
字符串类型
char
mysql 的char是字符串类型,最大长度为255.若要更大的则选择BLOG或者TEXT类型。固定长度字符串。

create table t4 (text char(1));
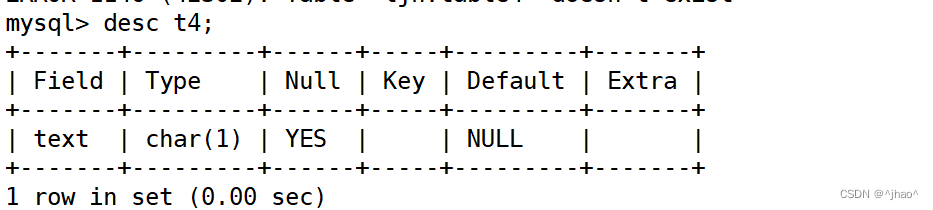
若修改时出现不能插入整数的情况:

则把latin1弄成utf8
具体方法
- su-
- vim /etc/my.cnf
- 添加 character-set-server=utf8
- service restart mysqld
- 此时创建一个数据库
由于我的数据库没有什么东西,我直接删掉重新创建。
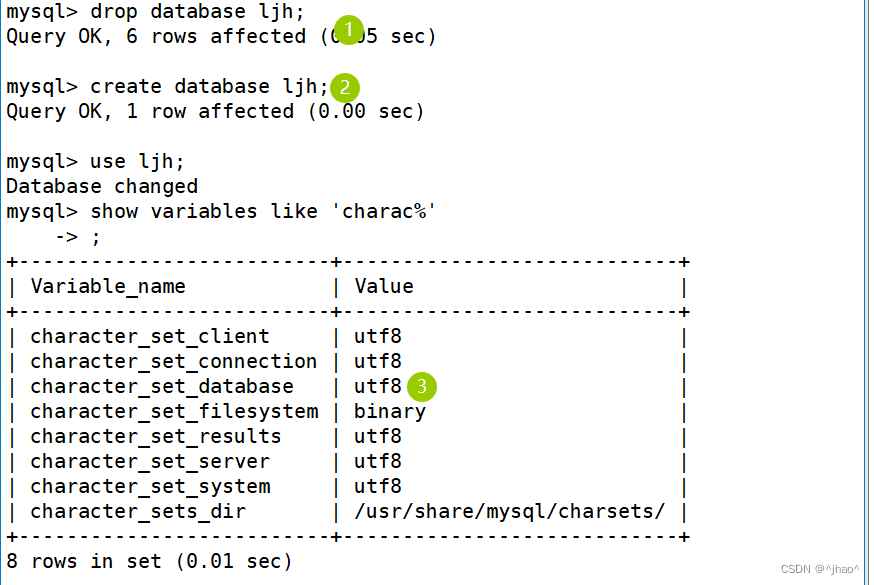
验证结果:可以存下一个汉字,汉字可不是一个字节。所以我们称mysql下的char为“字符” ,中英文都可!!
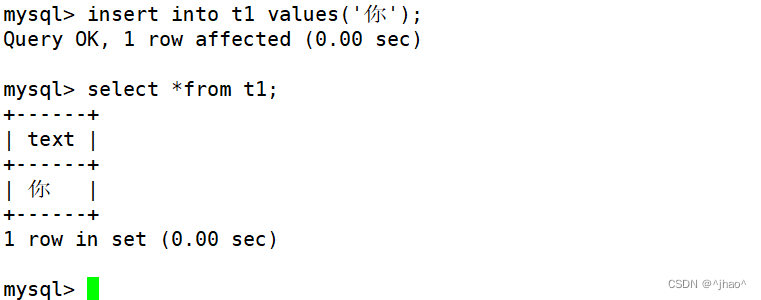
mysql的char类型让我们使用起来更简单了。
但是mysql更多人使用varchar 来定义变量,接下来介绍varchar
varchar
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
首先和char一样,他的“字符”也是汉字或字母!
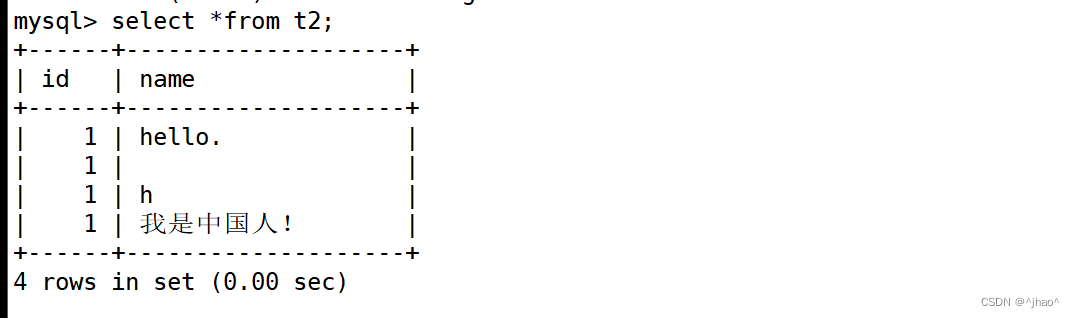
varchar长度可以指定为0到65535之间的值(字节),但是有1 - 3 个字节用于记录数据大小,所以说有效字节数是65532(字节)。
但是我们设置的时候最多只能为21844; 因为utf8 是3字节/1字节。当然这种情况表格当中只能由一个字段,才能到达21844.既不能即定义varchar(21844),又定义其他字段。

可变长度,如何理解?
类似string扩容,需要size,capacity来辅助进行扩容,所以需要一些数据记录长度。
但是如果我是定义varchar(1024);那么我们一开始只放1字符,实际上他一开始不会开到1024,浪费空间。所以平日用的比较多。
varchar vs char
- varchar的表示范围大于char
- varchar 可以动态扩容,相对来说节省空间。
如何选择定长或变长字符串?
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
- 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期时间
date 年月日
datetime 年月日 + 时分秒
timestamp 默认进行设置,就是当前时间,年月日 + 时分秒的格式。
mysql> create table birthday (
-> t1 date,
-> t2 datetime,
-> t3 timestamp);

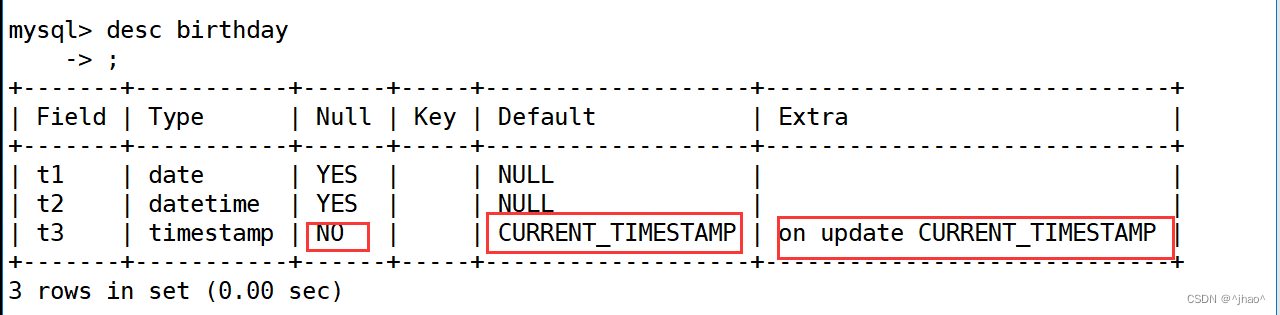
mysql> update birthday set t1='2000-01-01'; 当你通过update 进行更新的时候,它会自动更新t3
字段。
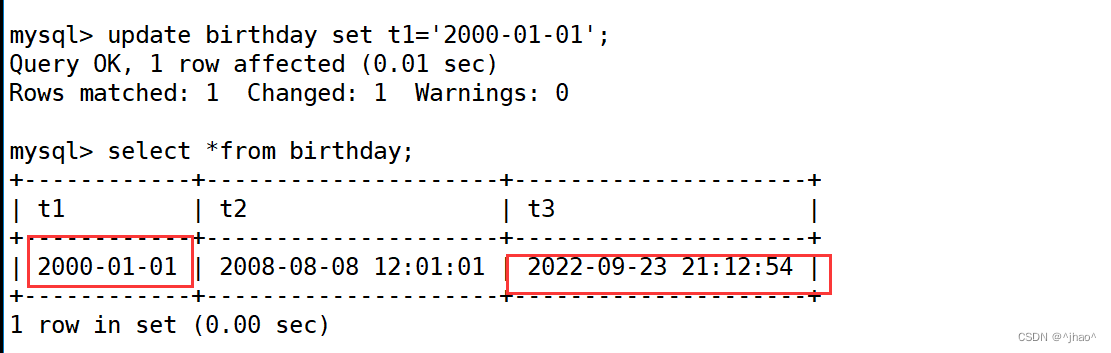
select now()now() 可以显示当前的 年月日 + 时分秒
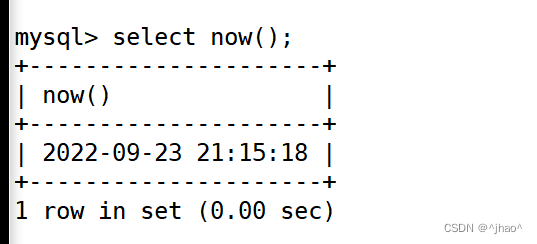
如果我们需要获取之前注册的值,而非当前时间,可以通过mysql> insert into birthday (t1,t2) values('2000-01-01',now());此时t2,t3的时间相同。
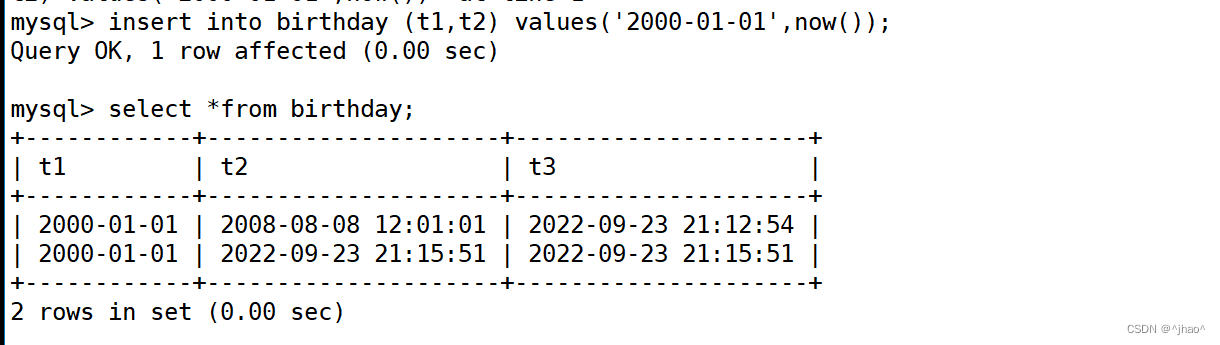
但如果我们再次更新时间,如果是类似用户的注册时间,那么t2就能很好的表示了。

enum 和 set
enum 和 set 和 C ++ 不太相同!
enum:枚举,“单选”类型;
enum(‘选项1’,‘选项2’,‘选项3’,…);
即多选一
你的性别::
o男 o女
set:集合,“多选”类型;
set(‘选项值1’,‘选项值2’,‘选项值3’, …);
即多选多
你喜欢的水果:
[]苹果 []香蕉 []葡萄 []哈密瓜
为什么说类型有着约束的作用:
sex char(); 如果这样设置那么sex可以填写’男’,‘女’,‘A’,这个’A’就很莫名其妙了,这就是类型char没有起到约束。
所以说sex enum 这样就不会乱套!!
mysql> create table votes( name varchar(16), sex enum('男','女'), hobby set('登山','游泳','打篮球','rap'));
插入两条正确的数据看看:
mysql> insert into votes values('张三','男','登山');
mysql> insert into votes values('李四','男','登山,游泳');

尝试插入错误的数据
性别错误:
mysql> insert into votes values('王五','A','登山,游泳');

集合没有开飞机错误:
mysql> insert into votes values('王五','男','开飞机');

总结:
集合和枚举的特点就是只要不在其中的选项mysql都会报错。只不过enum 多选一,set 则多选多(一)
小特性:
enum 相当于数组维护着,只不过是用1开始的,若是男女,则是1,2;
mysql> insert into votes values('赵六',1,'登山');

set 也有,只不过set稍微有点不同,他是相当于比特位进行使用,1表示登山,2表示游泳,3则是登山+游泳。相当于一个比特位意味着一个运动。
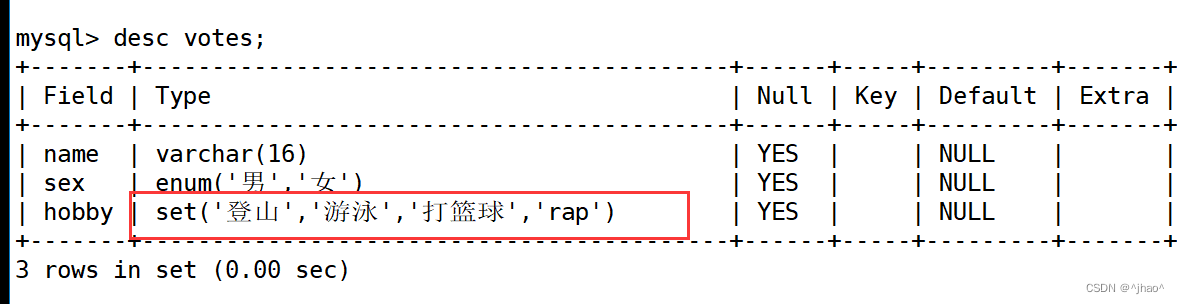
结果和上面所说的一样。
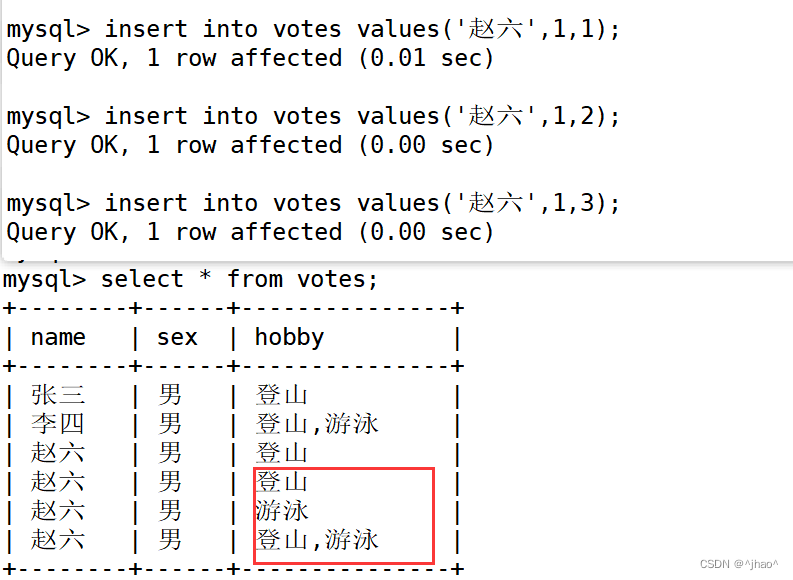
同理

不过数字这种方式可读性不好,直接用字符串比奥是就可以了,这里只是提一嘴~
集合的查找需要用find_in_set(sub,str_list):
如果 sub 在 str_list 中,则返回下标;如果不在,返回0; str_list 用逗号分隔的字符串。
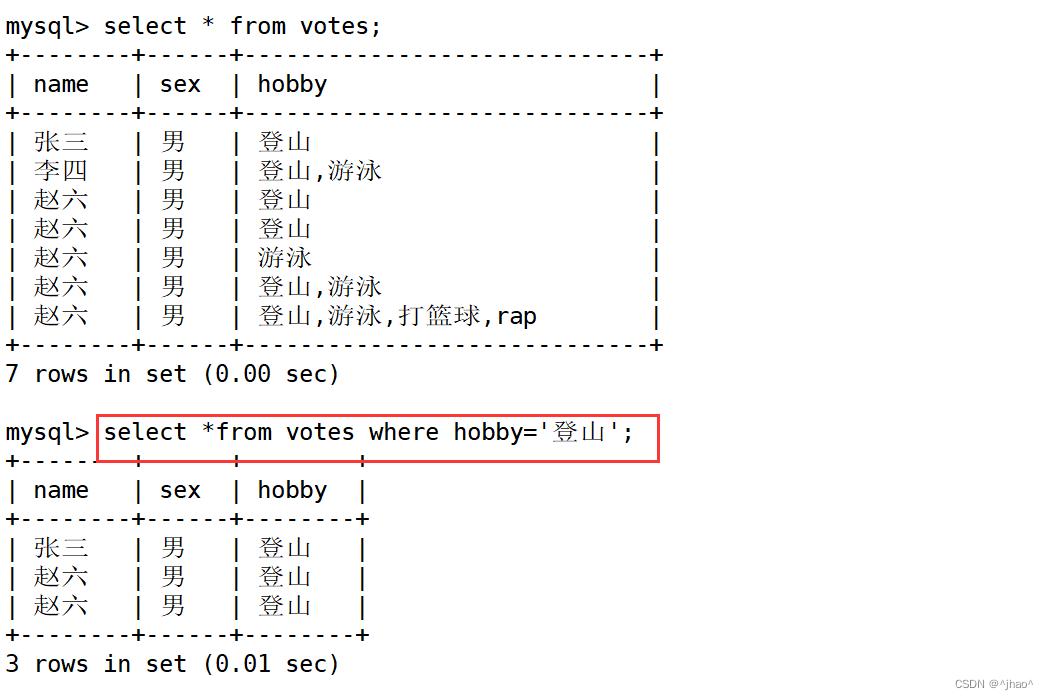

mysql> select * from votes where find_in_set('登山', hobby) and find_in_set('游泳',hobby); 如果需要查询多个兴趣,需要用and 连接

表的约束
空属性
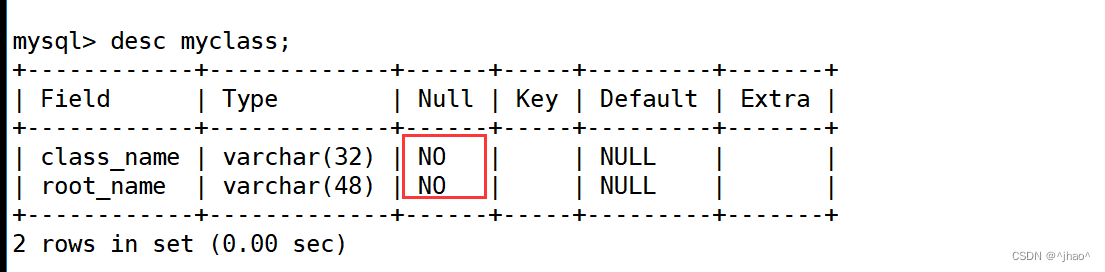
NULL、这个NULL能够约束上层是否必须要填写这个字段。
mysql> create table if not exists myclass ( class_name varchar(32) not null,root_name varchhar(48) not null));
mysql> insert into myclass(class_name,root_name) values('123','123');
若没有正常插入:
ERROR 1364 (HY000): Field ‘root_name’ doesn’t have a default value

默认值
一种数据一般为哪个值,那么我们就给默认值。比如我们是一所理工类院校的计算机学院的学生,那么我们选课表当中默认给性别为男生,这合理吗,还是很合理的~
mysql> create table if not exists t2(
-> name varchar (32) not null,
-> age tinyint unsigned default 18,
-> sex char(1) default '男'
-> ) engine=Innodb default charset=utf8;
如下图,不能为null,其实就没有必要默认值了。
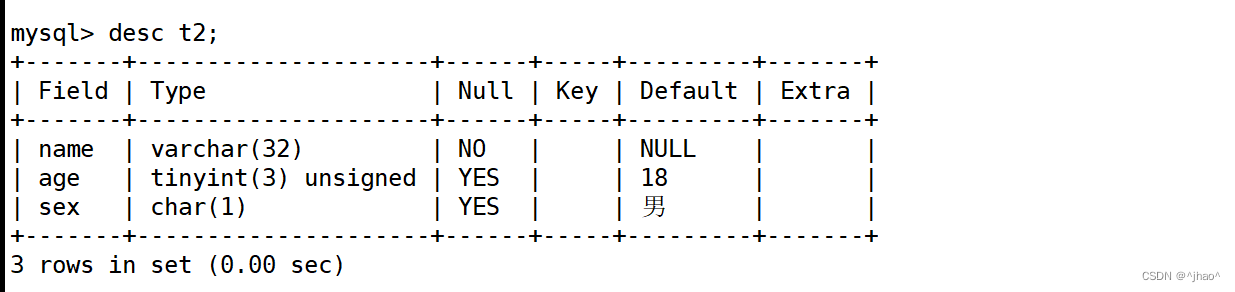
mysql> insert into t2(name) values('唐三藏');

设置NOT NULL 可不可以同时设置default 值?
可以的
mysql> create table if not exists t13(age int not null default 18,name char(16) not null);
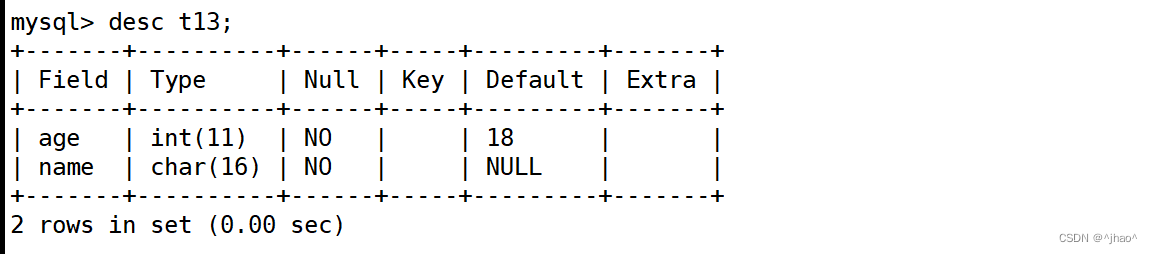
只插入name,age有默认值不为null可以正常插入的!
mysql> insert into t13 (name) values('张三');
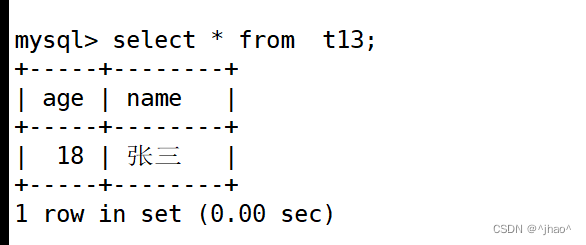
语义上:
NOT -> 不可能插入空值 -> 不能使用默认
DEFAULT -> 默认允许不给该列插入 -> 如果没有,就默认
实际上:
DEFAULT 的语义强于NOT NULL;即便为NOT NULL,也可以插入空。
列描述
相当于注释,通常说明列是用来做什么的?
mysql> create table if not exists t14( name varchar(32) not null comment '姓名', age tinyint unsigned default 18 comment '年龄,默认为18岁', sex char(1) default '女' comment '用户的性别,学校为女子院校' );
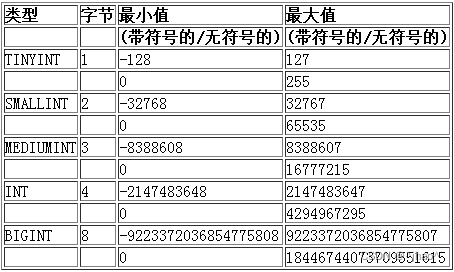
tinyint 为1字节,能表示 -128~127;
tinyint unsigned为1字节,能表示 0~255;
显示表的详细信息的时候就能看到这些字段。
mysql> show create table t14\G;
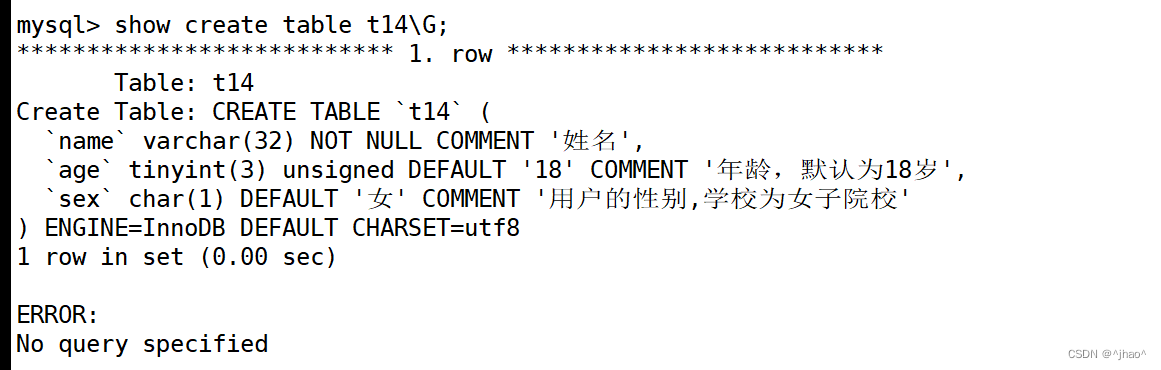
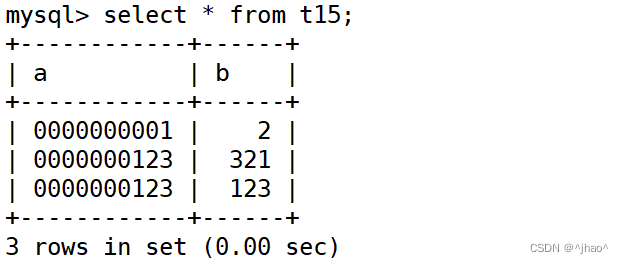
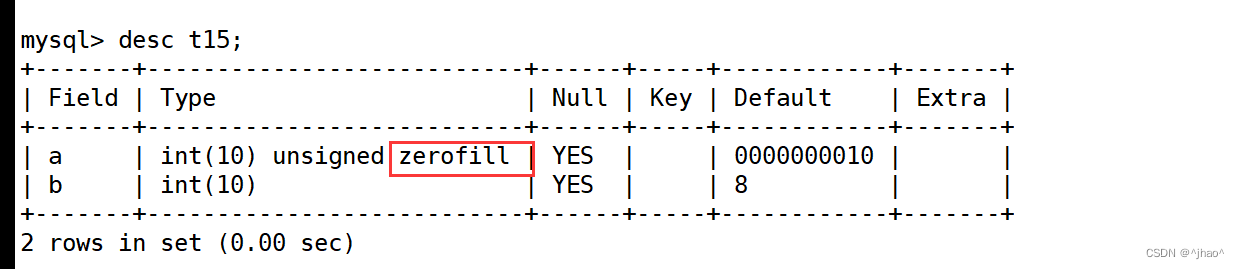
zerofill
表示输出的时候填充上0,超过位宽则不会补0.int(10),表示位宽是10,如果是有符号会多一位,放负号。
mysql> alter table t15 change a a int(10) zerofill default 10;
插入正常数据时:
mysql> insert into t15(a,b) values(123,321);
主键
主键:primary key用来唯一的约束该字段里面的数据,不能重复,不能为空,一张表中最多只能有一个主键;主键所在的列通常是整数类型。
mysql> create table t16 (id int primary key,name varchar(30) );

复合主键
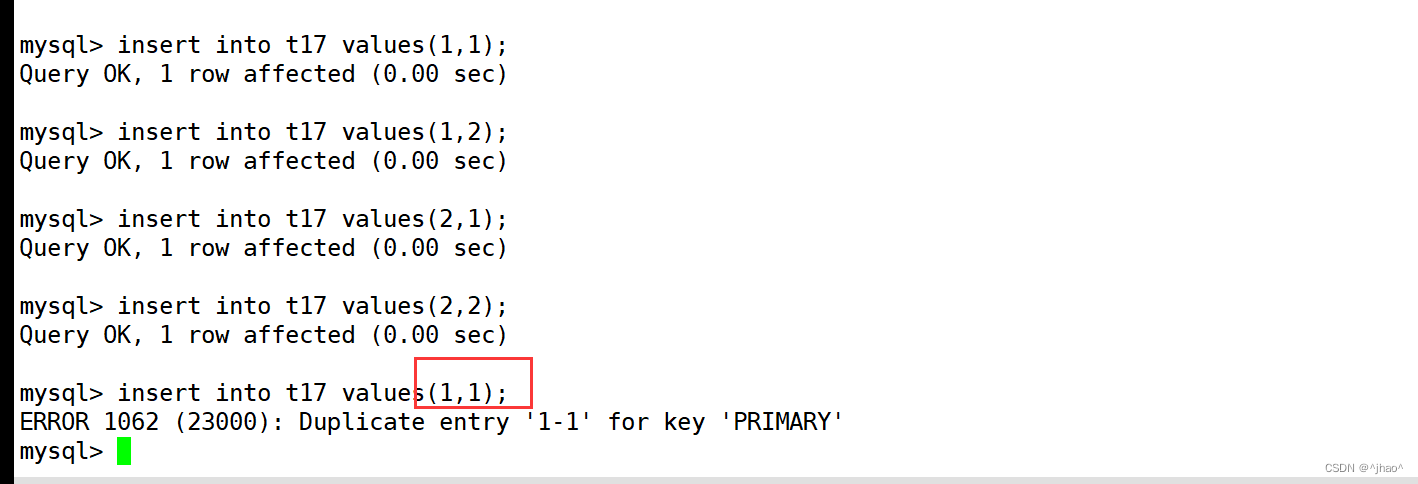
符合主键就是将多个列作为主键。
mysql> create table t17 (id int,school_id int,primary key(id,school_id));
查看表格,我们可以看到有两个PRI主键。

可以看出,只有复合主键所有的列值都出现冲突,才算主键冲突。
删除主键:
mysql> alter table t17 drop primary key;
自增长
只有主键所在列才能够自增长。
auto_increment 所在列是可以不填写,插入的时候需要指定插入的列即可。
创建表
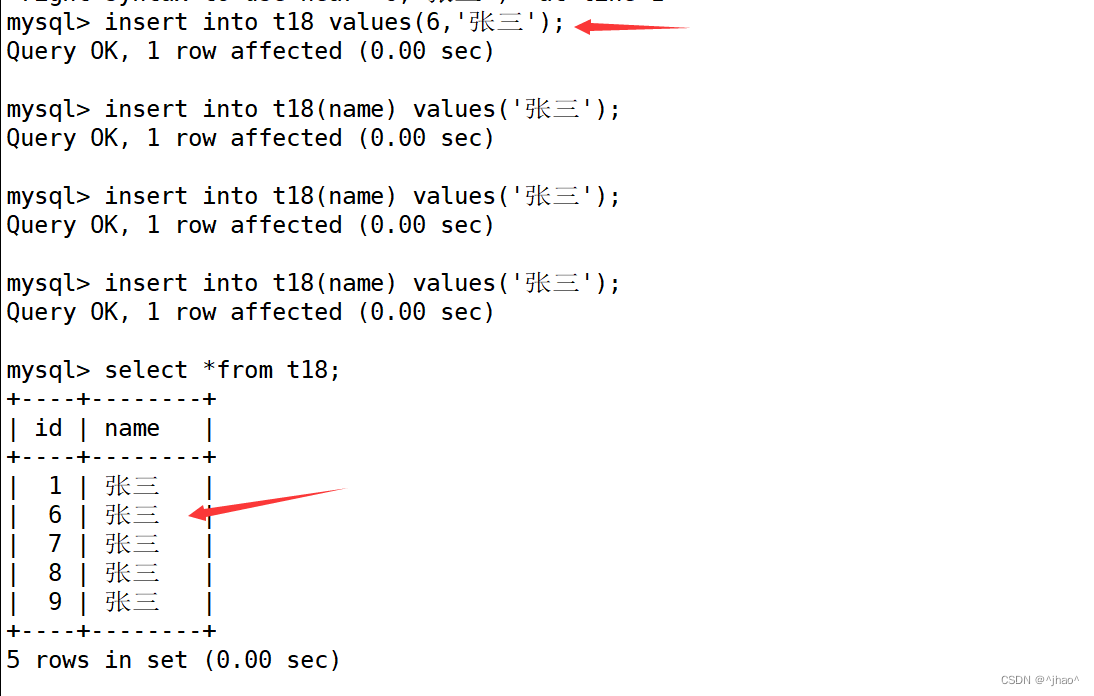
mysql> create table t18 (id int unsigned primary key auto_increment,name varchar(18));
查看表结构,
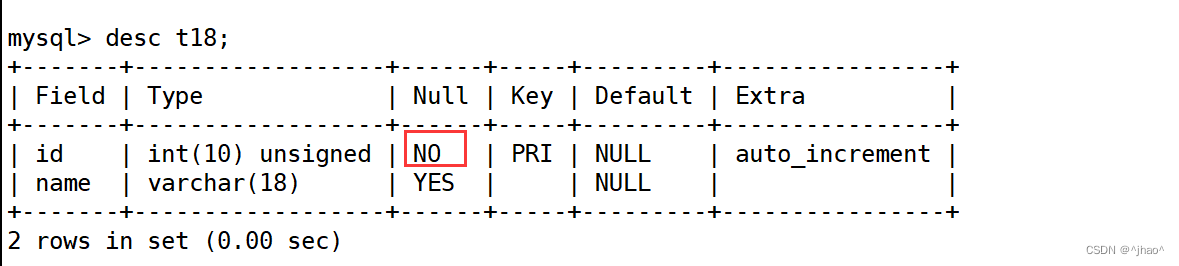
mysql> insert into t18 (name) values('张三'); 我仅仅插入名字这一行,虽然id不允许为null,但是没出错。这是因为Extra 字段显示auto_increment 表示该列能够自增长。

自增长会随着上次设置的id往后走。
唯一键
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多个字段需要唯一性约束的问题。
唯一键的本质和主键差不多,唯一键允许为空,而且可以多个为空,空字段不做唯一性比较。
唯一键: 唯一性 + 约束性;
主键是唯一的,唯一键也是唯一的,从这里看只有唯一键为空这一点有所不同。
由于主键具有唯一性,我们也有很多具有唯一性的属性,我们通常选择与挑选业务无关的id作为主键,其他字段设置为唯一键。
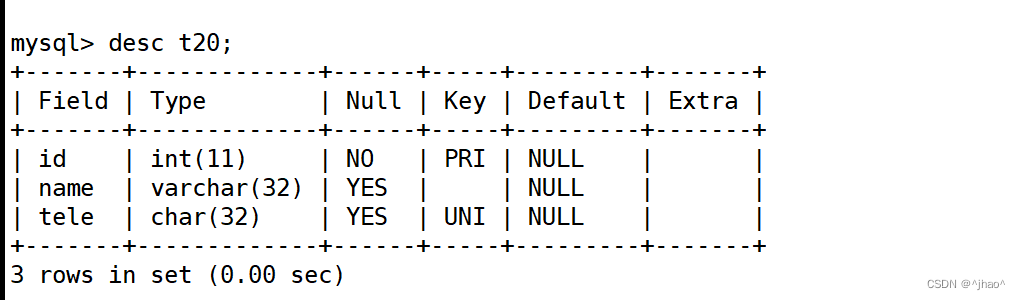
创建表
mysql> create table t20 (id int primary key,name varchar(32),tele char(32) unique);
KEY栏可以看见tele为UNI为唯一键。
插入之后若主键重复或者唯一键重复都会报错!!

外键
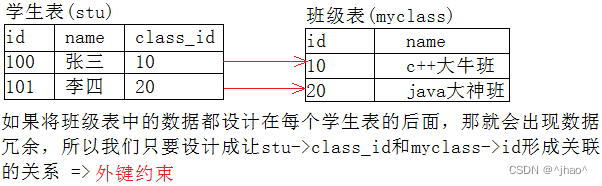
定义:
外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或unique约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
下面哪个是主表?哪个是从表?
答案:
班级表是主表,因为班级表不需要依附于学生表就能存活。
学生表是从表,因为class_id字段若是不能去班级表进行查找,也不能知道学生所在班级。
要求班级表的id必须是主键或唯一键。
外键 vs 外键约束
外键是指具体列,有外键不一定有外键约束;
外键约束就是外键预期想达到的效果。
相当于创建学生表没有使用 foreign key (字段名) references 主表(列),两个表没有产生联系,这时候只能说具有外键,但是没有外键约束。
表的操作
NULL的比较

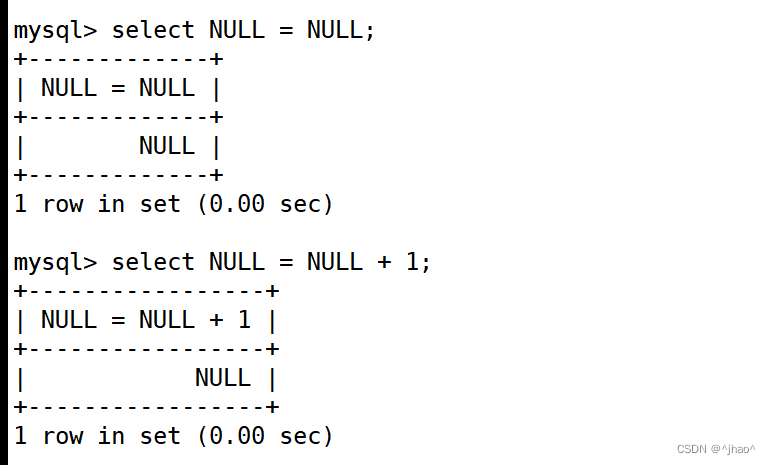
假设我们现在有t21这张表;

错误比较:
mysql> select *from t21 where name=NULL;
Empty set (0.00 sec)
正确的比较方式
mysql> select *from t21 where name <=> NULL;

select *from t21 where name is NULL;
mysql> select id from t21 where id <> 2;
mysql> select id from t21 where id != 2;
不等于的比较
and / or
and就是两个条件必须同时成立
or表示两个条件满足一个即可。
between xx and xx 表示一段范围
in
in表示是否在这个集合。

模糊匹配
LIKE,可以用%或者_ 搭配使用,%可以匹配一批,_可以匹配一个字符。

order by
order by在语句当中是靠后执行的
select name,english+chinese+math total from exam_result order by total desc; order by 是在select 将表结构弄出来之后才排序的。
试想万一我的表有百万条数据,他不会全部排序后才进行选择。
limit
limit 可以限定输出的条数,他执行的过程要晚于order by,我们一般在表结构比较大的时候通常可以带上limit。
limit一般跟在order by 的后面。
mysql> select *from votes limit 0,3; limit 可以指定从哪一条记录开始,从0开始,找几条。经常被用作分页功能。
limit 搭配 offset 也能实现上述效果。
mysql> select *from votes limit 3 offset 0;

REPLACE
REPLACE 若表中出现了重复的,就进行替换,没有则进行插入,类似map当中的operator[]操作。
REPLACE INTO students (sn, name) VALUES (20001, 'zhangsan');
update 语句
mysql> update votes set sex='女';
没有加入筛选条件,就会导致所有人的性别都被改成女了。
所以update 实际上是一个很危险的语句。

mysql> update votes set sex='男' where name='赵六';

删除
delete 和 truncate
delete 语句会记录在日志当中。
mysql> delete from votes;
如果是这样,表当中的数据都没有了。
跟update一样,删除动作也同样危险。

如果表中有auto_increament,表中不会重新从0开始。
mysql> truncate table t2; 则什么都没有,不会记录在日志。
插入查询结果
语法:
INSERT INTO table_name [(column [, column …])] SELECT …
类似往一张原始数据表查询想要的插入另一张表,可以用来去重插入。
创建表
mysql> CREATE TABLE duplicate_table (id int, name varchar(20));
插入重复数据
mysql> INSERT INTO duplicate_table VALUES (100, 'aaa'), (100, 'aaa'), (200, 'bbb'), (200, 'bbb'), (200, 'bbb'), (300, 'ccc');
select 语句通过distinct可以实现去重
mysql> select distinct * from duplicate_table;
如果需要把去重后的数据进行插入。
创建表结构
mysql> create table no_duplicate_table (id int,name varchar(20));
插入duplicate表中不重复的数据到no_duplicate_table中。
mysql> insert into no_duplicate_table select distinct * from duplicate_table; 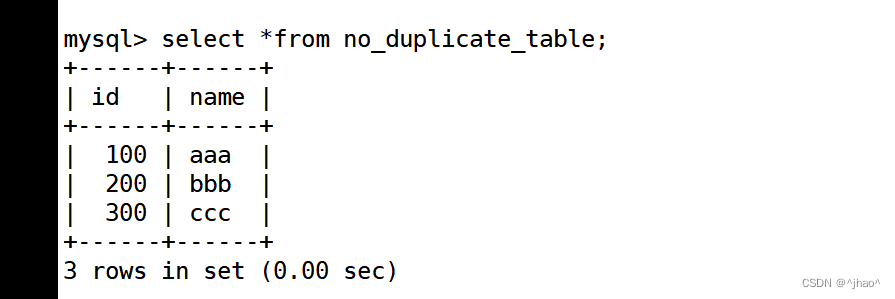
为什么可以进行上述操作?
select 是往显示屏显示一个表结果,insert之后相当于把向显示屏上输出的内容插入到表当中。
实际上有一点重定向的味道了~
若要对两个表进行重命名:
一定要通过RENAME,通过备份修改好后进行换名字。一般除非数据库设计不合理,出现大量重复数据,此时才能用这种方法,先把不重复的数据跳出来做备份,然后交换两个表的名字。
– 通过重命名表,实现原子的去重操作 RENAME TABLE duplicate_table TO old_duplicate_table, no_duplicate_table TO duplicate_table;
表的筛选字段
表的内容展示。
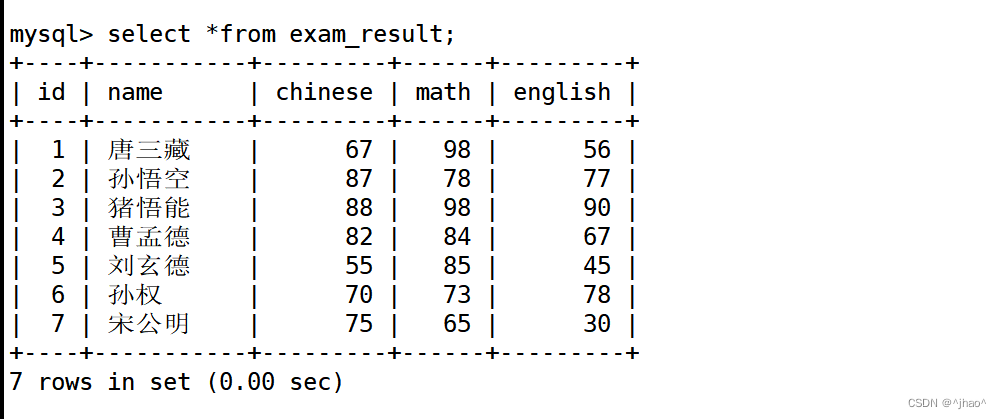
mysql> select count(chinese) from exam_result;

mysql> select sum(chinese) from exam_result;

mysql> select avg(math) from exam_result;

mysql> select sum(math) / count(*) from exam_result; 
mysql> select max(english) from exam_result;

group by
引入scoot表,是oracle当中经典测试表。
having
having 是group by 的条件筛选的组合,对比where,having 的执行是在group by 的后面。是对分完组,做完数据聚合统计之后,进行的条件筛选。
mysql> select avg(deptno),ename from emp where ename = 'CLARK' group by deptno,ename;
where 操作在group by 的前面。having 在 group by 的后面执行。

mysql> select current_timestamp(); 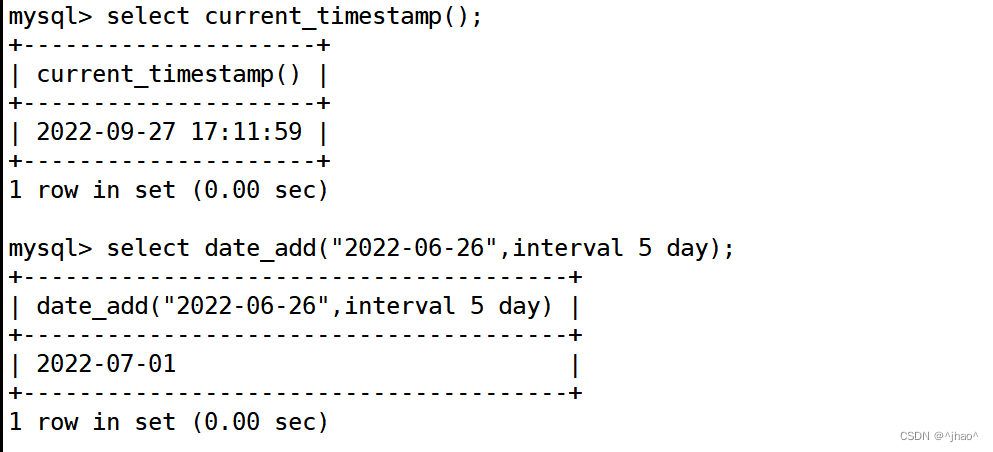
mysql> select datediff('2022-06-23','1949-10-01');
datediff能够用来计算两个日期的差值。若想查询从今天开始到先前的日志信息,需要进行计算。若将日志存放在数据库当中,就可以通过这种方式查看近期的日志。

interval
interval 可以用来加减时间,也有date_add和date_sub实现类似的功能。

mysql的字符串函数
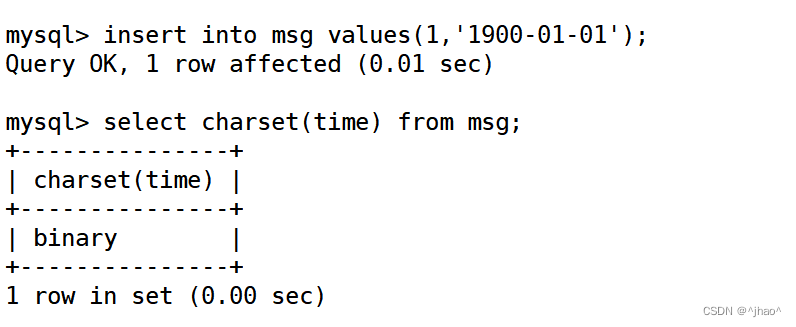
datetime 的类型。
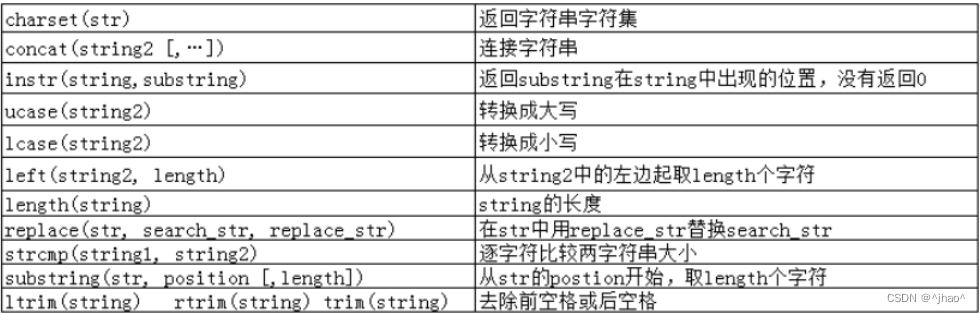
mysql> select concat('a','b');

mysql> select instr('aaabbbcccddd','abb');
instr 是返回匹配的第一个,返回的是第几个字符,不是下标。不满足返回0.


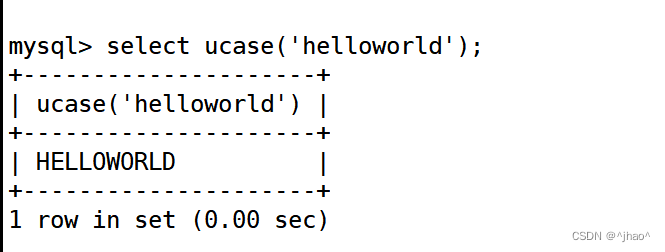
mysql> select ucase('helloworld');
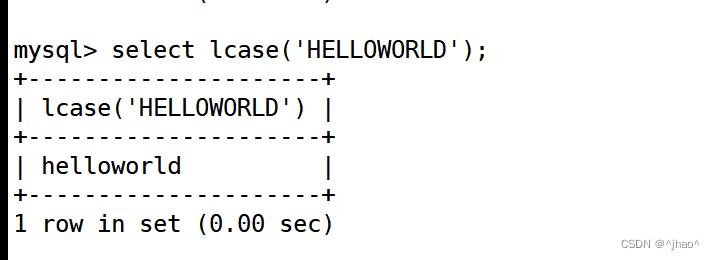
mysql> select lcase('HELLOWORLD');
left 从第一个字符开始,截取第二个参数个字符。
mysql> select left('helloworld',5);

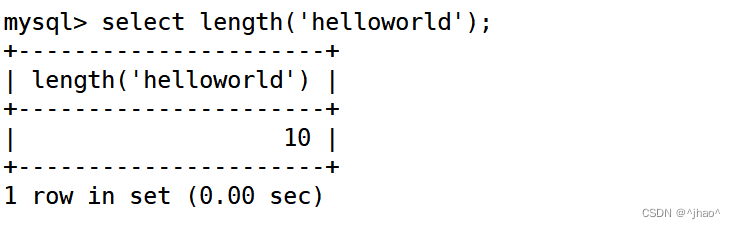
length 显示字符的长度
mysql> select length('helloworld');
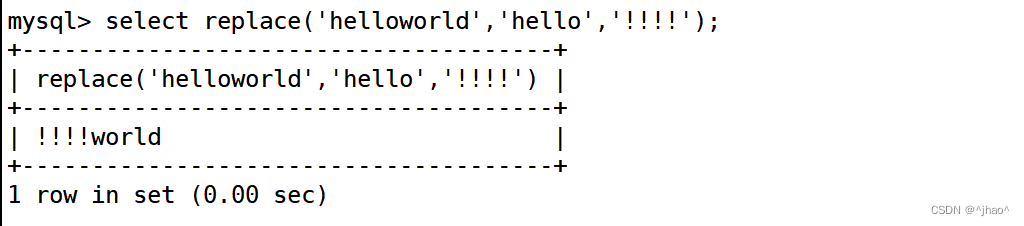
replace 将参数1中的参数二部分替换成参数3,hello 替换成 !!!
并且并一定需要等长替换。
mysql> select replace('helloworld','hello','!!!!');
strcmp 进行两个字符串的比较
mysql> select strcmp('aaa','bbb');
mysql> select strcmp('aaa','aaa');

substring 截取参数一中的从第二个参数开始截取,截取第三个参数个。
mysql 当中都是以字符计算,而不是下标。
mysql> select substring('abcd1234',1,4);

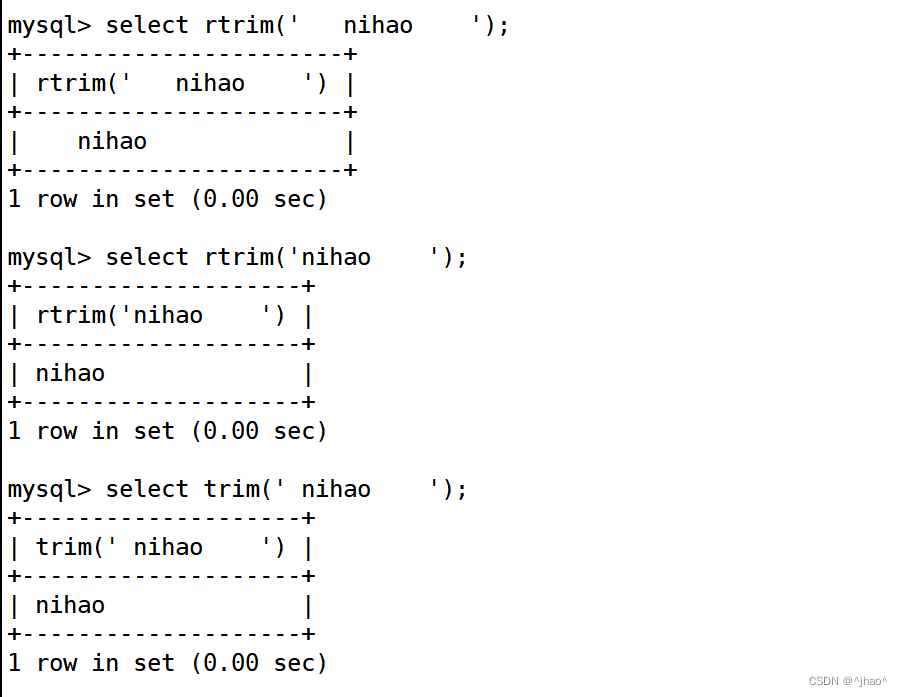
trim rtrim ltrim 就是去除表中的去除空格,去除右边空格,左边空格。
conv
mysql> select conv(15,15,2);

向上,向下取整
ceiling 向上取整 ceiling 本身有天花板的意思,在这里指向上取整。
floor 向下取整 floor 本身是地板的意思,在这里指向下取整。
ifnull
类似三目运算符,ifnull(a,b),a不是null返回a,反之返回b。
先分组后聚合。
union
union 合并两个自动是去重的。
union all
union all 不会进行去重。
总结
Mysql基本实操到此为止
- 喜欢就收藏
- 认同就点赞
- 支持就关注
- 疑问就评论