来源
ClimateLearn官网使用介绍
ClimateLearn 是一个 Python 库,用于以标准化、直接的方式访问最先进的气候数据和机器学习模型。
背景
近年来,极端天气事件使气候变化的威胁更加明显。 袭击美国东部的大西洋飓风的强度和严重程度一直在增加。 倾盆大雨将巴基斯坦大部分地区淹没,造成数千人死亡。 前所未有的热浪引发了野火,席卷了葡萄牙和西班牙的大片地区。 中东和北非的严重干旱破坏了该地区的供水,引发了冲突。 根据国际社会未来十年的反应,到 2100 年,地球平均表面温度预计将上升 2°C 至 4°C。 随着气温的升高,气候科学家预测极端天气事件将变得更加普遍。
气候科学家用来预测未来天气和气候的工具称为大气环流模型(general circulation models, GCM)。 简而言之,GCM 是微分方程组,可以随着时间的推移进行积分,以产生对温度、风速和降水等变量的预测。 这些模型以物理学为基础,其内部工作原理很容易解释,并且对其进行模拟可以产生相当准确的输出。 然而,运行模拟是一个计算成本高昂的过程,并且当给定更多数据时很难改进模型。 这就是机器学习算法作为一种有前途的替代方案发挥作用的地方。 特别是,此类算法在解决气候建模的两个子问题“天气预报”和“空间降尺度”方面表现出了与传统气候模型的竞争力。
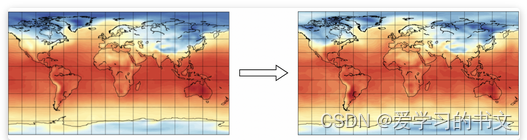
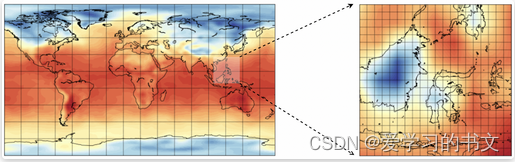
天气预报是预测未来气候变量的问题。 例如,鉴于过去一周加利福尼亚州洛杉矶的每日地表温度,下周的每日地表温度会是什么样? 回答这样的问题类似于计算机视觉中的视频帧预测问题。 空间降尺度是细化空间粗略气候模型预测的问题(例如,从 100 km×100 km 单元的网格到 1 km×1 km 单元的网格)。 这类似于另一个称为超分辨率(SR)的计算机视觉问题,其目标是对低分辨率图像进行上采样。 预测/缩减和帧预测/SR 之间的一个关键区别是我们可以使用额外的信号来限制可能预测的空间。 例如,在视频帧预测中,机器学习模型被给予图像序列作为输入,并产生图像序列作为输出。 输入和输出模式是相同的。 在天气预报中,机器学习模型可以以不同的方式利用外生变量。 假设该模型正在预测表面温度。 未来的表面温度不仅仅受到过去的表面温度的影响。 湿度和风速等因素也发挥着作用,除了温度之外,它们还可以作为模型的输入。
因此,随着近年来深度学习研究的爆炸式增长,机器学习和气候科学家都开始探索深度学习方法在解决天气预报和空间降尺度问题中的应用。 然而,这两个社区以不同的方式处理应用机器学习的问题。 气候科学家知道应该尊重哪些物理方程以及哪些评估指标最重要。 与此同时,机器学习科学家知道哪些架构最适合解决哪些问题以及如何以适合现代机器学习方法的方式处理数据。 混淆术语(例如,气候建模中的“偏差”与机器学习中的“偏差”)、将机器学习应用于气候科学问题时缺乏标准化(例如,定义适当的训练和保留数据集、数据增强)阻碍了进展。 策略),并且不熟悉如何解释气候数据(例如,重新分析与模拟数据集、NetCDF 等文件格式)。 “通用语言”的缺乏正是我们推出 ClimateLearn 的动力。
我们相信良好的研究需要良好的基础设施的支持。 本着这种精神,ClimateLearn 是一个 Python 包,用于以标准化、直接的方式访问最先进的气候数据和机器学习模型。 在这个包中,我们提供了对多个数据集的访问、一系列最先进的基线模型以及一套用于大规模天气预报和空间缩小方法基准测试的指标和可视化。
数据集
ClimateLearn 支持从 ERA5 加载数据,第五代 ECMWF(欧洲中期天气预报中心)对过去四到七年的全球气候和天气进行再分析。 再分析数据集是使用建模和数据同化系统将历史观测结果结合到全球估计中的数据集。 真实数据和建模的这种结合使得再分析产品能够以相当高的精度获得完整的全局数据。 然而,创建重新分析的过程非常耗时。 ERA5 数据在 3 个月内实时发布,这激发了通过机器学习计算成本低廉的方法的必要性。 除了原始 ERA5 数据外,ClimateLearn 还支持从 WeatherBench(数据驱动天气预报的基准数据集)加载预处理的 ERA5 数据。 无论哪种情况,ClimateLearn 都会以当今深度学习架构可以轻松使用的格式提供数据。
模型
ClimateLearn 实现了各种基线机器学习算法,以便用户可以快速了解如何将机器学习应用于预测和缩小问题。 其中包括简单的统计方法,例如线性回归、持久性和气候学,以及残差卷积神经网络、U-net 和视觉转换器的最先进的深度学习实现。 我们的基线模型已经针对气候任务进行了很好的调整,并且很容易扩展到气候科学的其他下游管道。
指标和可视化
使用 ClimateLearn 对常用指标的支持,例如(纬度加权)均方根误差、异常相关系数、皮尔逊相关系数和平均偏差,可以轻松评估和可视化此类模型的预测。 ClimateLearn 还支持地面实况、模型预测以及两者之间差异的可视化。 对预测变量进行目视检查是获得有关模型性能和重要结果的直觉的自然方法。
结论
今天,我们推出了 ClimateLearn,这是一个软件包,可以通过提供直接的数据集访问、易于比较的基线方法以及用于理解模型输出的指标和可视化来弥合气候科学和机器学习社区之间的差距。
我们对 ClimateLearn 未来的路线图包括扩大对更多数据集的支持,例如 CMIP6(第六代气候建模比对项目),该数据集已在 IPCC(国际气候变化专门委员会)的第六次评估报告中使用。 我们还计划通过新的不确定性量化指标(例如连续排名概率得分)和新的机器学习算法(例如贝叶斯神经网络和扩散模型)来增加对概率预测的支持。 实施这些功能将为 ClimateLearn 创造额外价值。 机器学习研究人员可以深入了解模型性能、表达力和鲁棒性。 气候科学家可以理解改变输入变量的值将如何导致不同的输出分布,这与现代气候研究的完成方式相匹配:科学家根据假设的排放情景提供了一系列潜在结果。 我们还将正式制定 Github 存储库的功能/拉取请求指南,并期待社区贡献。
我们构建 ClimateLearn 的目标是创建一个可以加速机器学习和气候科学交叉领域研究的工具,我们希望您和我们一样对此感到兴奋。