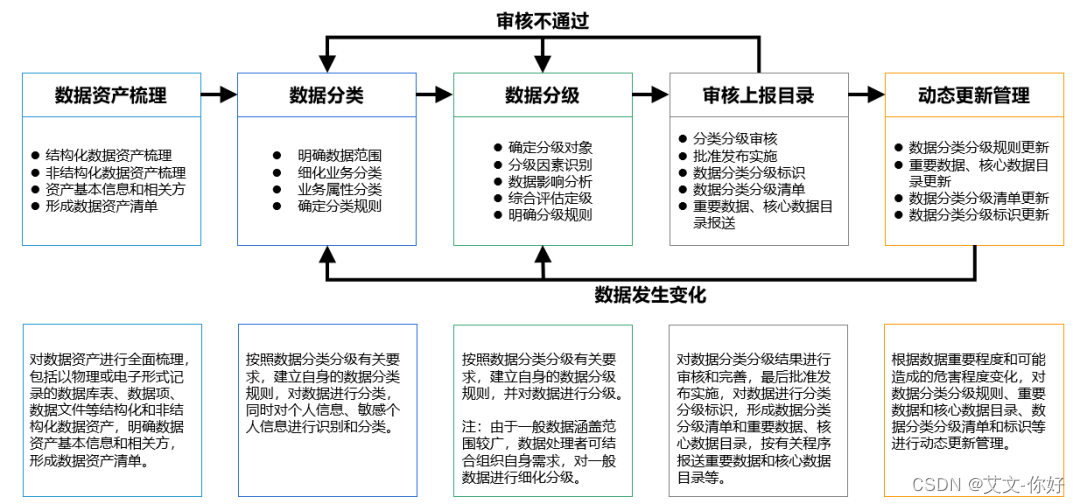
近年来静态程序分析已成为保障软件可靠性、安全性和高效性的关键技术之一. 指针分析作为基 础程序分析技术为静态程序分析提供关于程序的一系列基础信息,例如程序任意变量的指向关系、变量 间的别名关系、程序调用图、堆对象的可达性等. 介绍了 Java 指针分析的重要内容:指针分析算法、上下文 敏感、堆对象抽象、复杂语言特性处理、非全程序指针分析,特别是对近年来指针分析的研究热点选择性 上下文敏感技术进行了梳理和讨论.
目录
2 上下文敏感
2.1 上下文敏感指针分析算法
2.2 传统上下文敏感
2.3 选择性上下文敏感
2 上下文敏感
Java 程序中的一个方法在运行时可能被多次调 用,每次被调用时都处于不同的调用上下文(calling context)中,上下文敏感(context sensitivity)技术[30] 就 是研究如何在静态分析(如指针分析)中对动态运行 时的上下文进行建模和分析. 上下文敏感可以区分 同一方法在不同上下文中的数据流,从而减少数据 流的混淆并提升精度. 图 1 用一个例子解释上下文敏 感的思路及其作用.
在图 1 的代码片段中,方法 identity()分别被 foo() 和 bar()调用, foo()调用 identity()时传给其字符串 “foo”作为参数,然后由变量 r1 接收其返回值,显而 易见,运行时变量 r1 指向字符串“foo”. bar()与之类 似,运行时 r2 将指向字符串“bar”. 然而,若使用 1.3 节介绍的上下文非敏感指针分析算法分析这段程序, 则 identity()中的变量 s 会指向{“foo” , “bar” },且这 2 个字符串会传播 给 r1 与 r2, 使 得 r1 与 r2 都指向 {“foo”, “bar”},导致指针分析结果不精确(实际运行 时,r1 或 r2 不指向“bar”或“foo”).
造成图 1 的例子中精度丢失的原因在于方法

identity()在运行时有 2 个调用上下文(来自 foo()与 bar()),并且 identity()内的变量 s 在 2 个上下文中指 向不同对象(分别为“foo”与“bar”). 然而上下文非敏 感分析并不区分这 2 个上下文,因此 2 个上下文中的 数据流在 identity()内部混淆,并且传递给了 r1 与 r2 . 而上下文敏感分析的思路是将 identity()的不同调用 上下文加以区分并分别分析,从而避免数据流的混 淆以提升精度.
目前,上下文敏感是提升 Java 指针分析精度公 认最有效的方法[20,31-34] ,多年来一直是该领域的研究 重点. 2.1 节将 1.3 节介绍的指针分析算法扩展成上 下文敏感指针分析算法,2.2 节与 2.3 节分别介绍传 统上下文敏感技术以及近年来的相关研究热点,选 择性上下文敏感技术.
2.1 上下文敏感指针分析算法
在上下文敏感指针分析中,程序中的每个方法 会被冠以上下文,用 c:m 表示(c 表示某个上下文), 称为上下文敏感方法. 每个上下文可以被视为一个 标识符,用于将该上下文中的方法(如 c:m)与其它上 下文中的同一方法(如 c′:m)加以区分. 此外,通常每 个方法中的变量与创建出的对象也继承该方法的上 下文,成为上下文敏感变量与对象. 不同上下文中的 变量以及对象的实例字段可指向不同对象,从而达 到实现对不同上下文数据流的区分. 而具体上下文 的生成取决于指针分析使用的上下文敏感技术,本 文在 2.2~2.3 节进行介绍.
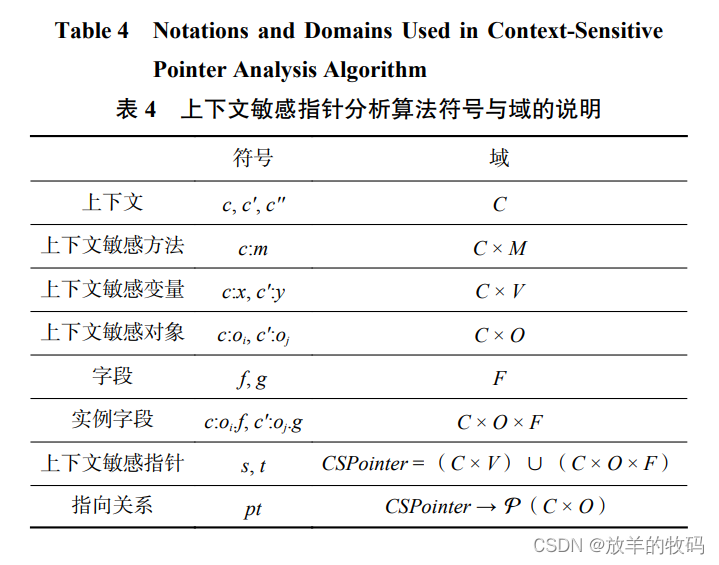
表 4 列出了上下文敏感指针分析算法用到的符 号以及相关域. 表 4 与表 2 相比的区别在于,上下文 敏感分析中程序的方法、变量、对象被冠以上下文. 相 应 地 , 指 向 关系 pt 相 关 的 域 , 即 指 针 集 合 (CSPointer)和对象集合中的元素也都带有上下文.
1)指针分析规则. 表 5 给出了上下文敏感指针分 析的规则. 假设表中语句所在方法的当前上下文为 c,则相关语句的变量的上下文都是 c,如复制语句的变 量 x 和 y、字段存储语句的变量 x 和 y 等,因为同一语 句的变量必然声明在同一方法内,因此它们具有相 同的上下文. 表 5 给出的分析规则与表 3 的上下文非 敏感指针分析在本质上都可视为 Andersen 风格指针 分析(描述了程序各指针之间如何建立子集约束), 表 5 与表 3 的区别在于上下文敏感分析中的指针都 带有上下文,可以使不同上下文中的指向关系得以 分开分析,从而提升精度.
在上下文敏感指针分析中,方法调用的规则最 为重要和复杂,因为它涉及到上下文的生成. 具体地 说,本文定义 Select(c, l, c':oi)函数,根据调用点的信 息(当前调用者上下文 c,调用点标号 l,接收者对象 c':oi)生成目标方法 m(与表 3 中上下文非敏感分析一 样,由 Dispatch 得到)的上下文 c t . Select()函数的具体 实现对应不同的上下文敏感技术,本文将在 2.2~2.3 节展开讨论. 得到目标方法的上下文 c t 后,指针分析 规则在 c 中 l 的变量与 m 在 c t 中的变量之间互相传递对象. 由于 m 的 c t 是根据调用点的信息生成的,因 此 m 也与当前调用建立了关联,从而可以与 m 的其 它上下文(例如由其它调用点发起的调用)区分开, 从而避免不同上下文数据流混淆造成的精度丢失.
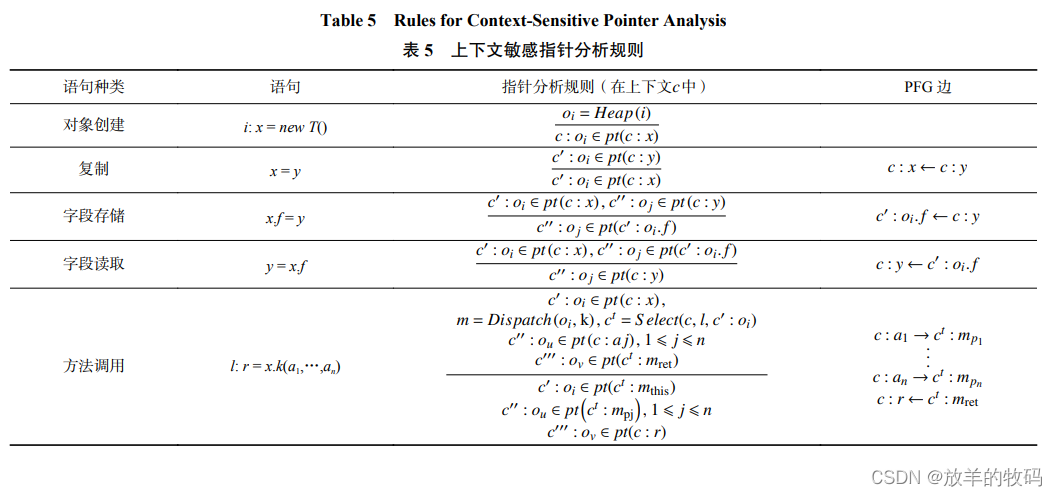
2)指针分析算法. 本文设计的上下文敏感指针 分析算法如算法 2 所示. 该算法是由算法 1(上下文 非敏感指针分析算法)扩展而成,算法的思路仍是构 建指针流图 PFG 用于表达子集约束关系 ,并沿 着 PFG 传播指向关系直至到达不动点. 表 5 的列 4 给出 了添加 PFG 边的规则. 在上下文敏感分析中,PFG 的 结点都是带有上下文的指针. 由于算法 2 的流程与算 法 1 一致,因此本文不再赘述.
2.2 传统上下文敏感
1)调 用 点 敏 感 . 调 用 点 敏 感 (call-site sensitivity) [30,40-41] ,又称调用串敏感(call-string sensitivity)或 kCFA,是最早诞生的上下文敏感技术. 调用点敏感的 每个上下文由一串调用点组成(具体实现中,通常会 给程序中的每个调用点赋予一个唯一的标号,并用 标号表示相应的调用点),当分析调用点 l 时,调用点 敏感将 l 所在方法的上下文加上 l 自身,作为目标方 法的上下文. 对应的 Select()函数定义为(下划线表 示无关的参数):
Select(c, l, _) = [l ′ , …, l ′′ , l], 其中,c = [l ′ , …, l ′′].
2)对象敏感. 2002 年,Milanova 等人针对面向对象 语言的特征,提出对象敏感(object sensitivity)技术[42-43] . 具体地说,对象敏感技术使用调用点的接收者对象 作为上下文,相应的 Select()函数定义为:
Select(_, _, c ′ : oi) = [oj , …, ok , oi], 其中c ′ = [oj , …, ok].
3)类型敏感. 作为面向对象程序,许多 Java 程序 会创建大量对象,因此使用对象敏感技术分析这类 程序且上下文层数大于 1 时,容易产生过多上下文, 导致指针分析开销过大. 对此,Smaragdakis 等人[44] 在 对象敏感的基础上提出类型敏感(type sensitivity)技 术以提升指针分析效率与可扩展性,对应的 Select() 函数定义为:
Select(_, _, c ′ : oi) = [t, …, t ′ , InT ype(oi)],
其中c ′ = [t, …, t ′ ].
2.3 选择性上下文敏感
1)选择上下文元素. 传统的上下文敏感使用的都是连续的上下文元素,例如,如果是调用点敏感技 术 ,l3 会调用 l2, l2 会调用 l1,那么 [l3 ,l2 ,l1 ] 就会作为 3 层上下文元素来被使用. 然而,Tan 等人[46] 发现连续 上下文中的很多上下文元素在很多情况下并不能提 升精度,而这些上下文元素由于占用了上下文资源, 比如,如果只能用 2 层上下文,那么该例中的 l3 如果 是能够帮助提升精度的上下文元素而 l2 不是,但是 由于传统方法的上下文元素是连续的,因此也只能 舍弃 l3 . 为了解决该问题,Tan 等人[46] 提出了对象分 配图(object allocation graph),并将识别有效上下文元 素的问题转换为在对象分配图上识别有效路径的问 题. 如果使用同样的上下文层数,该方法可以被证明 总能取得相较于传统方法更好的分析精度.
2)选择程序方法. Smaragdakis 等人[50] 为了能够 让指针分析有更好的可扩展性,提出了自省式分析 (introspective analysis),该方法人工选取 6 种不同的 程序指标(metrics)(例如,程序方法参数的指向集合 的大小);通过运行上下文非敏感指针分析作为预分 析将这些指标值算出;根据这些值和阈值的比较作为选择哪些方法需要上下文敏感的判断条件,其余 方法用上下文非敏感来分析,这样会节省计算和维 护上下文信息的开销. 实验数据显示,该方法确实能 够使得一些之前难以分析的程序在合理时间内分析 出结果,且取得了良好的分析精度.