readv()和writev()系统调用分别实现了分散输入和集中输出的功能。
NAME
readv, writev, preadv, pwritev - read or write data into multiple buffers
SYNOPSIS
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
ssize_t preadv(int fd, const struct iovec *iov, int iovcnt,
off_t offset);
ssize_t pwritev(int fd, const struct iovec *iov, int iovcnt,
off_t offset);
这些系统调用并非只对单个缓冲区进行读写操作,而是一次即可传输多个缓冲区的数据。数组iov定义了一组用来传输数据的缓冲区。整型数iovcnt则指定了iov的成员个数。iov中的每个成员都是如下形式的数据结构。
struct iovec {
void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */
};SUSv3标准允许系统实现对iov中的成员个数加以限制。系统实现可以通过定义<limits.h>文件中IOV_MAX来通告这一限额,程序也可以在系统运行时调用sysconf (_SC_IOV_MAX)来获取这一限额。(11.2节将介绍sysconf()。)SUSv3要求该限额不得少于16。Linux将IOV_MAX的值定义为1024,这是与内核对该向量大小的限制(由内核常量UIO_MAXIOV定义)相对应的。
然而,glibc对readv()和writev()的封装函数⑤还悄悄做了些额外工作。若系统调用因iovcnt参数值过大而失败,外壳函数将临时分配一块缓冲区,其大小足以容纳iov参数所有成员所描述的数据缓冲区,随后再执行read()或write()调用(参见后文对使用write()实现writev()功能的讨论)。
图5-3展示的是一个关于iov、iovcnt以及iov指向缓冲区之间关系的示例。

图5-3:iovec数组及其相关缓冲区的示例
测试一:打印IOV_MAX的值:
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#include <sys/types.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
#include <sys/epoll.h>
#include <sys/uio.h>
#include <limits.h>
#define _DEBUG_INFO
#ifdef _DEBUG_INFO
#define DEBUG_INFO(format, ...) printf("%s:%d $$ " format "\n" \
,__func__,__LINE__ \
, ##__VA_ARGS__)
#else
#define DEBUG_INFO(format, ...)
#endif
int main(int argc, char **argv)
{
DEBUG_INFO("IOV_MAX = %d",IOV_MAX);
DEBUG_INFO("IOV_MAX = %d",sysconf(_SC_IOV_MAX));
return 0;
}
执行结果:
main:27 $$ IOV_MAX = 1024
main:28 $$ IOV_MAX = 1024分散输入
readv()系统调用实现了分散输入的功能:从文件描述符fd所指代的文件中读取一片连续的字节,然后将其散置(“分散放置”)于iov指定的缓冲区中。这一散置动作从iov[0]开始,依次填满每个缓冲区。
原子性是readv()的重要属性。换言之,从调用进程的角度来看,当调用readv()时,内核在fd所指代的文件与用户内存之间一次性地完成了数据转移。这意味着,假设即使有另一进程(或线程)与其共享同一文件偏移量,且在调用readv()的同时企图修改文件偏移量,readv()所读取的数据仍将是连续的。
调用readv()成功将返回读取的字节数,若文件结束(EOF)将返回0。调用者必须对返回值进行检查,以验证读取的字节数是否满足要求。若数据不足以填充所有缓冲区,则只会占用(按IOV数组顺序)部分缓冲区,其中最后一个缓冲区可能只存有部分数据。
测试二:使用readv()执行分散输入readv.c
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#include <sys/types.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
#include <sys/epoll.h>
#include <sys/uio.h>
#include <limits.h>
#define _DEBUG_INFO
#ifdef _DEBUG_INFO
#define DEBUG_INFO(format, ...) printf("%s:%d $$ " format "\n" \
,__func__,__LINE__ \
, ##__VA_ARGS__)
#else
#define DEBUG_INFO(format, ...)
#endif
#define STR_SIZE 100
static char *file_name = "hello.txt";
int main(int argc, char **argv)
{
int fd;
struct iovec iov[3];
char a,b,c[3];
char str[STR_SIZE];
memset(c,0,sizeof(c));
fd = open(file_name,O_RDONLY);
if(fd < 0){
perror("open");
return -1;
}
DEBUG_INFO("fd = %d,open %s ok",fd,file_name);
iov[0].iov_base = &a;
iov[0].iov_len = 1;
iov[1].iov_base = &b;
iov[1].iov_len = 1;
iov[2].iov_base = c;
iov[2].iov_len = 2;
int len = readv(fd,iov,3);
if(len != 4){
DEBUG_INFO("error:read len = %d",len);
exit(0);
}
DEBUG_INFO("read ok: len = %d",len);
DEBUG_INFO("a = %c b = %c c = %s",a,b,c);
DEBUG_INFO("cur offset = %d",lseek(fd,0,SEEK_CUR));
close(fd);
DEBUG_INFO("bye bye");
return 0;
}
测试:
创建文件hello.txt
echo "hello" > hello.txt执行程序
./_build_/readv如下图,红框中便是测试读出的值。
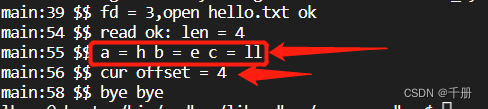
preadv测试:
将上面的int len = readv(fd,iov,3);替换为下面的代码,就是在偏移1的位置开始读。
![]()
执行结果:
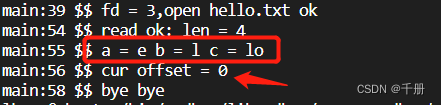
对比可知readv会改变偏移量,preadv不会改变偏移量,这和read与readv的区别是一样的。
集中输出
writev()系统调用实现了集中输出:将iov所指定的所有缓冲区中的数据拼接(“集中”)起来,然后以连续的字节序列写入文件描述符fd指代的文件中。对缓冲区中数据的“集中”始于iov[0]所指定的缓冲区,并按数组顺序展开。
像readv()调用一样,writev()调用也属于原子操作,即所有数据将一次性地从用户内存传输到fd指代的文件中。因此,在向普通文件写入数据时,writev()调用会把所有的请求数据连续写入文件,而不会在其他进程(或线程)写操作的影响下分散地写入文件。
如同write()调用,writev()调用也可能存在部分写的问题。因此,必须检查writev()调用的返回值,以确定写入的字节数是否与要求相符。
readv()调用和writev()调用的主要优势在于便捷。如下两种方案,任选其一都可替代对writev()的调用。
- 编码时,首先分配一个大缓冲区,随即再从进程地址空间的其他位置将数据复制过来,最后调用write()输出其中的所有数据。
- 发起一系列write()调用,逐一输出每个缓冲区中的数据。
尽管方案一在语义上等同于writev()调用,但需要在用户空间内分配缓冲区,进行数据复制,很不方便(效率也低)。
方案二在语义上就不同于单次的writev()调用,因为发起多次write()调用将无法保证原子性。更何况,执行一次writev()调用比执行多次write()调用开销要小。
测试三 writev测试
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#include <sys/types.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
#include <sys/epoll.h>
#include <sys/uio.h>
#include <limits.h>
#define _DEBUG_INFO
#ifdef _DEBUG_INFO
#define DEBUG_INFO(format, ...) printf("%s:%d $$ " format "\n" \
,__func__,__LINE__ \
, ##__VA_ARGS__)
#else
#define DEBUG_INFO(format, ...)
#endif
static char *file_name = "writev.txt";
int main(int argc, char **argv)
{
int fd;
struct iovec iov[3];
char a[10],b[10],c[10];
int write_len = 0;
memcpy(a,"we",sizeof("we"));
memcpy(b,"lc",sizeof("lc"));
memcpy(c,"ome\n",sizeof("ome\n"));
fd = open(file_name,O_WRONLY | O_CREAT | O_TRUNC,0666);
if(fd < 0){
perror("open");
return -1;
}
DEBUG_INFO("fd = %d,open %s ok",fd,file_name);
iov[0].iov_base = a;
iov[0].iov_len = strlen(a);
iov[1].iov_base = b;
iov[1].iov_len = strlen(b);
iov[2].iov_base = c;
iov[2].iov_len = strlen(c);
write_len += strlen(a);
write_len += strlen(b);
write_len += strlen(c);
int len = writev(fd,iov,3);
if(len != write_len){
DEBUG_INFO("error:writev len = %d,write_len = %d",len,write_len);
exit(0);
}
DEBUG_INFO("writev ok: len = %d",len);
DEBUG_INFO("cur offset = %ld",lseek(fd,0,SEEK_CUR));
close(fd);
DEBUG_INFO("bye bye");
return 0;
}
测试:

查看生成的文件writev.txt,文件长度8字节。与调试输出一样。
$ ls -lsh writev.txt
4.0K -rw-rw-r-- 1 lkmao lkmao 8 6月 28 20:19 writev.txt$ cat writev.txt
welcome测试三 pwritev测试
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#include <sys/types.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
#include <sys/epoll.h>
#include <sys/uio.h>
#include <limits.h>
#define _DEBUG_INFO
#ifdef _DEBUG_INFO
#define DEBUG_INFO(format, ...) printf("%s:%d $$ " format "\n" \
,__func__,__LINE__ \
, ##__VA_ARGS__)
#else
#define DEBUG_INFO(format, ...)
#endif
static char *file_name = "writev.txt";
int main(int argc, char **argv)
{
int fd;
struct iovec iov[3];
char a[10],b[10],c[10];
int write_len = 0;
memcpy(a," t",sizeof(" t"));
memcpy(b,"o ",sizeof("o "));
memcpy(c,"china\n",sizeof("china\n"));
fd = open(file_name,O_WRONLY,0666);
if(fd < 0){
perror("open");
return -1;
}
DEBUG_INFO("fd = %d,open %s ok",fd,file_name);
iov[0].iov_base = a;
iov[0].iov_len = strlen(a);
iov[1].iov_base = b;
iov[1].iov_len = strlen(b);
iov[2].iov_base = c;
iov[2].iov_len = strlen(c);
write_len += strlen(a);
write_len += strlen(b);
write_len += strlen(c);
int len = pwritev(fd,iov,3,7);
if(len != write_len){
DEBUG_INFO("error:writev len = %d,write_len = %d",len,write_len);
exit(0);
}
DEBUG_INFO("writev ok: len = %d",len);
DEBUG_INFO("cur offset = %ld",lseek(fd,0,SEEK_CUR));
close(fd);
DEBUG_INFO("bye bye");
return 0;
}

$ cat writev.txt
welcome to china实验解析
在偏移7的位置开始写,正好覆盖前一个测试的最后一个字符‘\n’,这样就能保证cat输出的时候,新添加的内容和旧的内容在同一行输出。
pwritev写完文件后,文件的位置不会发生变化,writev写完文件后,文件的位置会发生变化。这是write和pwrite是一样的。
小结