导语: 复杂架构的危害是隐性且持续增长的,尤其在海量数据处理的业务场景下,导致系统吞吐量增长、各功能模块相互影响,且数据重复、维护困难。某游戏公司就面临这样的困境,在寻求解决方案的过程中,携手OceanBase 搭建了存储与实时分析的一体化数仓架构,替换了ClickHouse,Hive。该公司大数据平台负责人从实时数仓面临的问题与挑战谈起,讲述了他们从确定选型方向到最终实现选型落地的历程,以及使用 OceanBase 的经验,供大家参考。
业务背景:数仓架构复杂,重视数据分析、处理与运营
我们公司是一个游戏公司,以前重研发,现在重运营。对于游戏公司来说,数据分析是非常重要的一块业务,因此,我们非常看重数据分析系统的能力。目前,我们主要使用数仓工具对用户行为(下载、注册、充值)和广告营销数据进行分析,还有其他游戏数据的分析,比如用户打怪升级的现状、战斗的参数等,也会用到数仓。
和大多数公司一样,我们的数仓是典型的 Lambda 架构,如图1所示。我们通过数据源获取到数据后先进行预处理如数据质量控制、数据清洗等处理后,将数据放入 Kafka进行数据缓存。后续的任务调度分成两部分,一部分是通过Hive做离线处理,另一部分数据用ClickHouse 进行实时分析。处理后的数据供应用系统使用,比如BI系统、用户系统、营销系统、以及第三方系统如百度、腾讯、头条、抖音等。
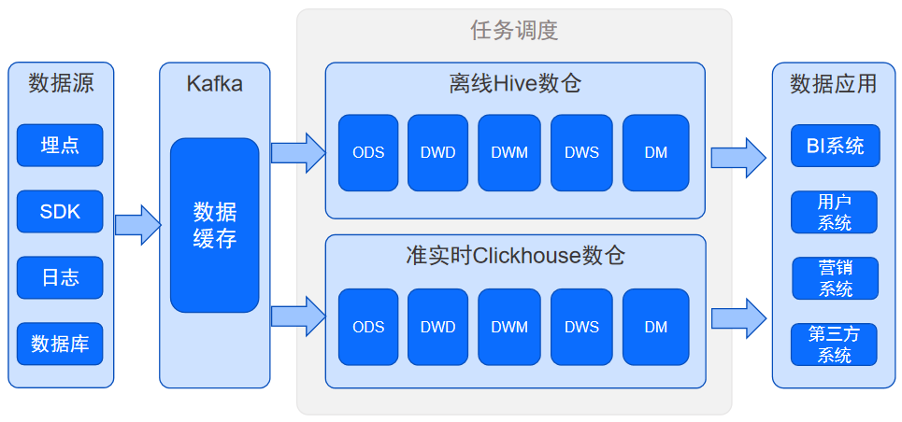
图1 数仓架构
当前的数仓在获取数据后会进行解析和数据质量的处理。当收集到质量不符合规定的(缺字段、字段的类型不对)数据都会进行告警和处理。游戏行业数据处理比较特别的一点是会对数据进行归因,简单来说就是把数据收集流程进行详细解析,以此来判断该数据是通过哪个渠道哪个广告位产生的,后续的广告营销策略也会依赖于数据归因。另外,我们还有一套“数据打宽”流程,这是数据仓库中最为常见的业务加工场景,可以将用户的 IP 解析后显示用户的国家、省市、地区、信息,可以解析用户的手机型号,可以解析用户的年龄和性别等,放入离线数仓和实时数仓中,为用户画像提供支撑。
业务挑战:实时性、一致性、可维护性差,查询慢
我们的数仓架构包括数据贴源层,数据详细层、数据中间层、数据服务层、数据集市等,原始数据通过数据质量检查后,分别写入Hive 和 ClickHouse 中的ODS贴源层,严格来说kafka中有什么数据,ODS层也有什么数据,Kafka也属于贴源层的范畴,数据通过任务调度系统,进行打宽如解析ip、解析年龄和加工后,存入数据详细层DWD,数据在数据中间层DWM和数据服务层DWS经过一系列指标汇聚处理后,放入数据集市,我们是用PostgreSQL数据库和Redis中来做的数据集市,其中任务调度系统是我们自研的,可以进行源数字典的管理和数据质量管理及任务调度,可以执行任务重跑、任务优先级调整、数据质量告警等操作,是一个比较强大的调度系统。虽说这个架构是当前较为先进的架构,但在使用过程中也遇到了不少挑战。
挑战1:实时性。 很多公司的数仓策略都是T+1,此前我们在使用 Hive 数仓时对其进行了优化,达到了数据从产生到可见只需要30分钟。就是说我们30分钟就去load一遍数据,写入Hive再insert overwrite 到当天的分区里面(可减少数据的碎片)。在实时数仓上ClickHouse也达到了一分钟可见。但有些场景需要在毫秒内看到结果,是 Hive 和ClickHouse无法达到的。
挑战2:一致性。 相信用过 Lambda 架构的人都知道 ClickHouse和Hive 的数据经常“打架”,二者计算出来的数据不一致。我们允许数据重复,在计算上也做了重复数据的去重处理,但即使重复处理完,仍然有数据不一致的问题,导致ClickHouse 的数据只能用于实时数据的查看,Hive 数据则会用于最终数据使用。
挑战3:可维护性。 ClickHouse实时数仓一套代码,Hive 离线数仓一套代码,一个架构两套系统,维护起来比较困难。
挑战4:即席查询。 Hive 离线数仓,需要几分钟甚至十几分钟才能看到查询结果。ClickHouse实时数仓在几秒钟至几分钟就能展示查询结果。即席查询在大多数情况下一切正常,但在以下两种极端情况下会遇到挑战。
-
一种情况是用户身份信息邦联查询,当用户在注册过程中绑定了身份证,需要通过身份证回查用户账号时,是需要毫秒级的响应。而我们的用户信息是存在MySQL中,在数据量较小时,查询达到毫秒级响应是没问题的,但在数量上亿或者数十亿的查询场景下,MySQL的响应就非常慢甚至不可用。
-
另一种情况是广告渠道邦联查分析,需通过订单数据邦联用户数据再邦联广告商渠道信息,以往查看广告投放效果需等待要半小时。而我们的需求是1秒内可见。
目前 Lambda 架构下的数仓不支持上述需求,这迫使我们探索新的数仓工具。
技术选型:OceanBase 查询测试,性能提升286倍
我们调研了Hudi、Doris两款数仓工具,Hudi从数据写入到Join查询,至少需要60秒;Doris 能实现10秒到60秒可见,而我们已经在用的ClickHouse查询结果的可见时间为 66秒(见图2),相比之下,如果选用Hudi或Doris与使用现有的ClickHouse并没有明显的数值提升,没有从根本上解决业务的需求。
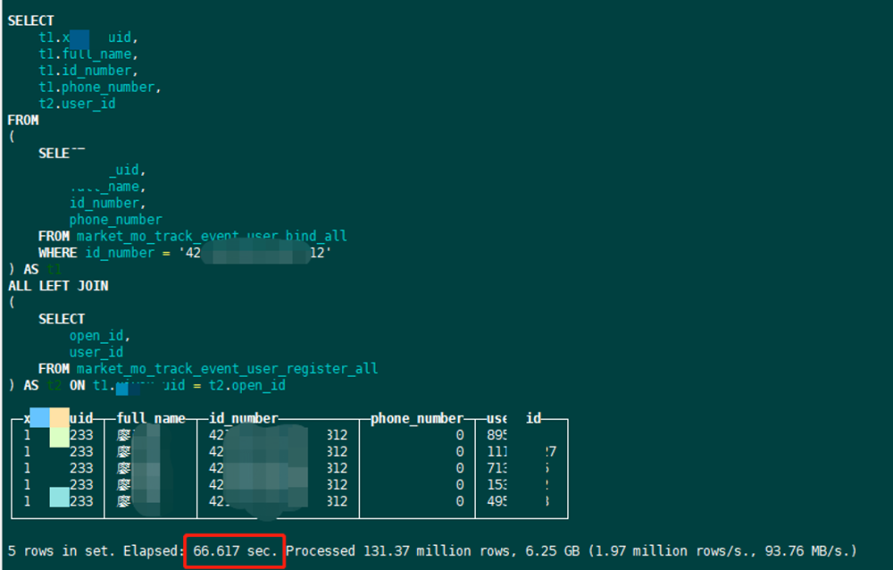
图2 ClickHouse查询数据66秒可见
在进行新工具调研的过程中,我们了解到 HTAP 数据库 OceanBase,并使用 OceanBase 在用户身份证号查找用户ID的场景下简单测试了数据查询速度。通过图3可以看到,我们在对 OceanBase 未做分区优化只做索引优化的情况下,1.2 亿 Join查询 34亿条数据,初次查询用时0.23秒,数据预热后 0.01秒出数据查询结果,性能提升66/0.23=286倍。我们认为,这是一个很“吓人”的性能提升。
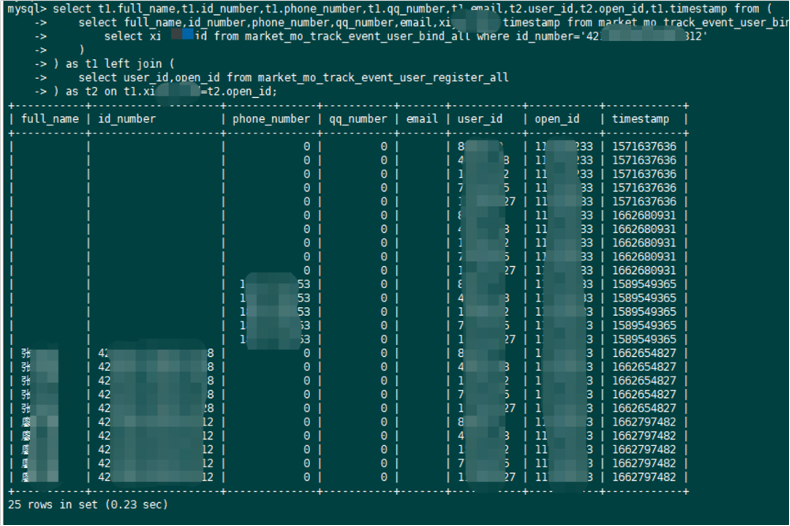
图3 OceanBase查询数据结果毫秒可见
因此,我们当即决定封装 OceanBase 的能力去满足业务需求,包括通过身份证号查找用户ID、通过用户ID查询广告信息、实时红包推广效果等。
生产部署:实时数据写入优化,历史数据导入踩坑
在确定使用 OceanBase 后,下一步的计划就是考虑如何把它用起来。首先,我们对历史数据和实时数据进行区分。
-
历史数据:我们用 DataX 将历史数据导出为 CSV 文件后,再用 DataX 将 CSV 文件导入OceanBase。
-
实时数据:考虑到用户需求是毫秒级响应,我们选用了 Flink SQL 抽取实时数据。经过测试,从数据产生到数据落到 OceanBase,1秒内完成。
对于历史数据的导入,由于前期对 OceanBase 不够熟悉,在使用过程中,我们也走了一些弯路,很多问题通过在OceanBase 技术答疑群(钉钉群号:33254054)与技术专家交流得到了解决。在数据导入过程中,通过 DataX 导出 CSV 文件时,配置文件中最好用 2881 端口直连 OceanBase 数据库,如果通过2883端口,也就是OBProxy 代理连接的话,由于OBProxy 的分发机制,可能将不同的命令分发到另外一台机器上,如果另外一台机器没有部署 DataX并导出文件的话则会找不到文件,所以我建议使用Datax的时候,连接2881是最保险的。
对于实时数据的写入,值得一提的是,在写 OceanBase 时,我们也考虑过 Spark。Spark 是通过微批的方式去写,在微批写时,实时性还是比 Flink 差了一些。最大的微批时间间隔为300毫秒的延迟。而 Flink 则可以实时写入 OceanBase,因此,我们选择通过 Flink SQL 的方式把数据写到 OceanBase 中。
下面三张图片是Flink 数据实时ETL 的加载转化以及写入OceanBase 的流程代码展示。其中,图4是使用Flink-kafka抽取实时数据的过程;图5为使用FlinkSQL转换、加工整理实时数据的过程;图6为使用FlinkSQL实时加载至目的地 OceanBase 的过程。
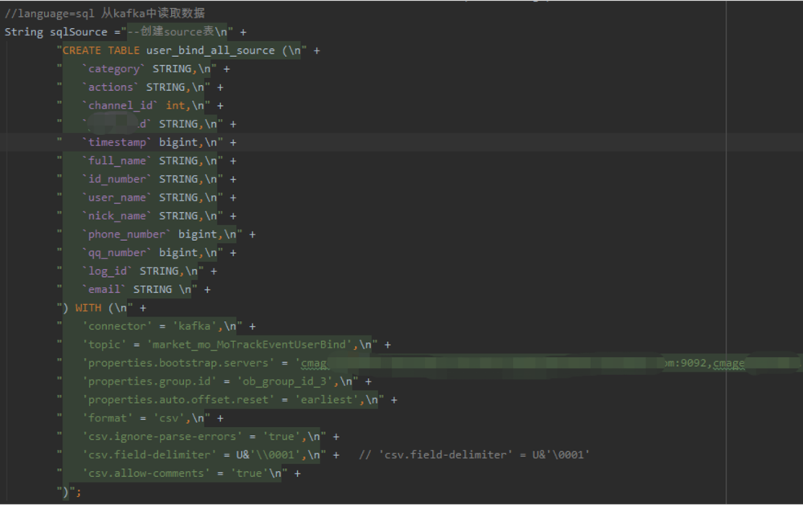
图4 使用Flink-kafka抽取实时数据
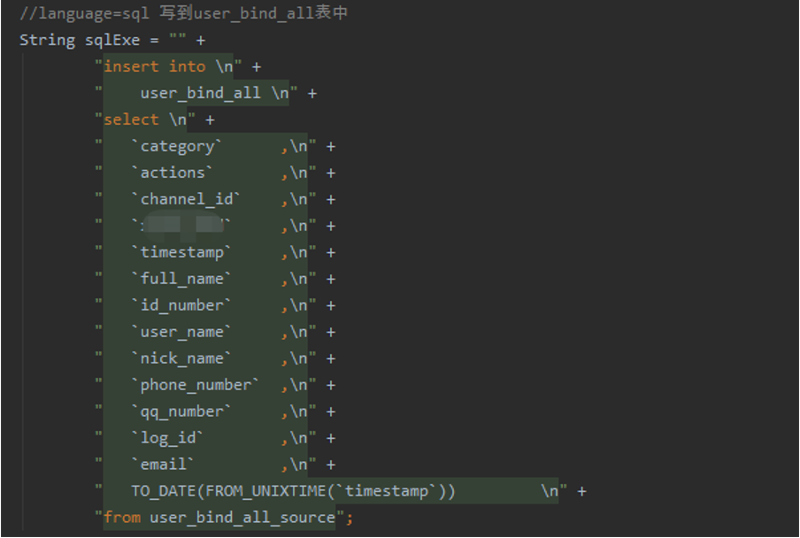
图5 使用FlinkSQL转换、加工整理实时数据
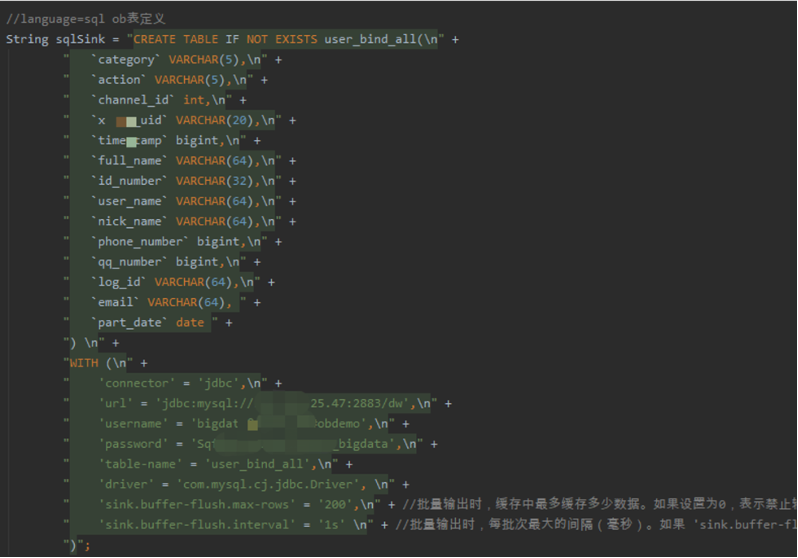
图6 使用FlinkSQL实时加载至OceanBase
我也对这些代码进行部分抽取,将其做成脚本成批量提交,在转化成脚本工具化后 Flink Source 数据源可以支持从Kafka、MySQL、Oracle、OceanBase、MongoDB、PostgreSQL、Sqlserver等数据源实时同步数据并加工后写入OceanBase 中,数据形成了闭环,OceanBase 作为数据中台核心/实时数仓的雏形初步完成。
以上代码我们已经部署到生产环境中,目前应用到两个应用场景中:一是通过用户身份证号查找用户ID,二是通过用户 ID 查找数据归因等信息,比如用户通过哪个广告渠道了解并注册到我们的产品。目前,OceanBase 在业务系统中的位置如图7所示。
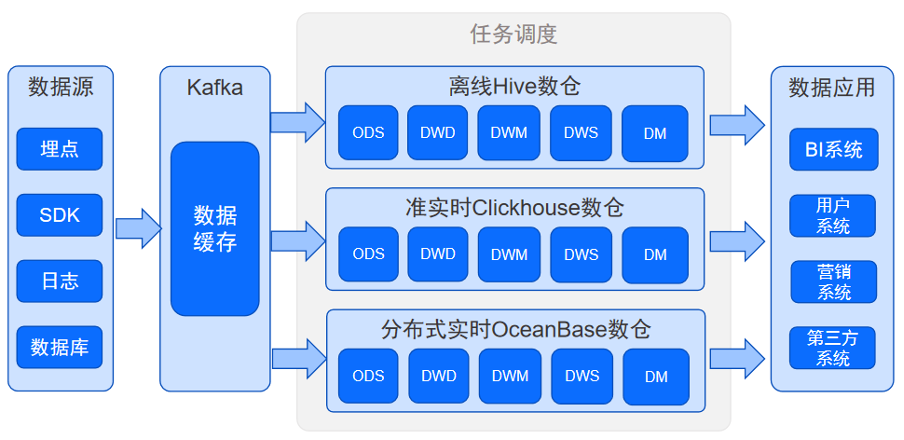
图7 使用OceanBase后的数仓架构
总结与展望:一个系统支撑TP与AP场景,解决所有问题
随着 OceanBase 在我们业务系统中的稳定落地,帮助我们解决了上文提到的四个固有问题。
实时性: 从Kafka到Flink再到 OceanBase,写入与导出的实时性没有任何问题。例如,使用 Flink SQL抽取实时数据并写入 OceanBase,能实时完成。对于flink-sql-connector-OceanBase-cdc工具,我希望它更好的支持历史数据再加工高效效率,以及不重不漏高效的历史数据、实时数据无缝对,我们期待 OceanBase 的CDC工具能够迭代出更完美的版本。我们更期待社区开发出 OceanBase 专有的flink-connector,实现不重不漏高效的写 OceanBase。做好flink-sql-connector-OceanBase-cdc读工具和flink-connector写工具,就可以不重不漏高效的进行数仓第二层,第三层的加工,将OceanBase的生态扩展到了大数据圈,顺带实现了大数据环境下的存算分离。
一致性: OceanBase 可以完美对接我们现有系统中的历史数据和实时数据,实现数据不重、不漏、不丢。
即席查询: 我们在对 OceanBase 未做分区优化只做索引优化的情况下,1.2 亿 Join查询 34亿条数据,初次查询用时0.23秒,数据预热后 0.01秒出数据查询结果,性能提升66/0.23=286倍。数据可以达到毫秒内可见。
可维护性: 以往我们需要维护ClickHouse和Hive这两套代码,未来我们计划将所有核心场景逐渐迁移至 OceanBase,简化架构,只需维护一套代码即可实现TP和AP的双重能力。
下一步,我们计划在用户系统、广告系统、数据分析系统,以及营销和渠道管理分析中推广和使用OceanBase(见图8),目前已经开始了代码开发与数据对接。我们的理想状态是将所有的业务数据放到 OceanBase 中进行分析、保存,实现数据闭环,一个系统解决所有问题。
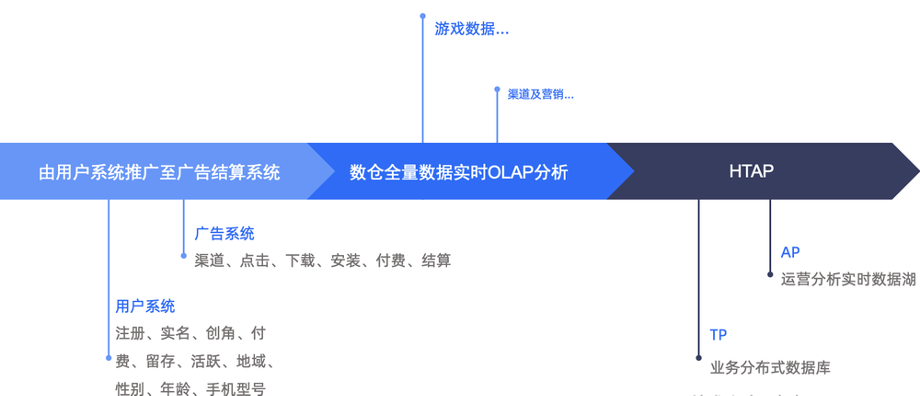
图8 将OceanBase应用至更多系统
此次 OceanBase 落地实践带给我们很多惊喜,正所谓千里之行始于足下,我们要敢于尝试,才能逐渐到达千里之外,感受更美丽的风景。最后,希望 OceanBase 能够越做越好。