Linux文件中的特殊换行符
大数据项目做数据etl工作时,无可避免的会遇到Linux文件中的一些特殊换行符。在做这些特殊符号的处理的时候往往就相当麻烦,这里详细记录一下怎么这些特殊字符,并转换成能识别的普通字符或者是符合项目数据规范的分隔符。
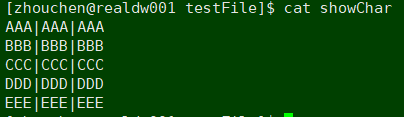
以下面和这个文件为例:
查看隐形的分隔符
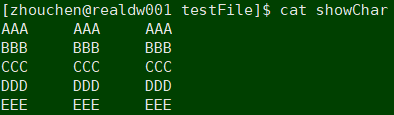
首先进入vim编辑模式,然后输入: set list查看文件中隐藏的符号
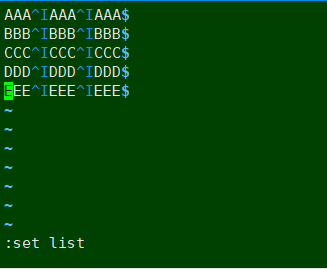
这里显示的特殊字符是^I , 但是直接示例中直接cat的时候是看不见这个^I ,并且直接用^I去搜索也是不存在的
查看特殊字符对照表
首先进入vim编辑模式,然后输入: help digraph-table查看隐藏的符号对照表
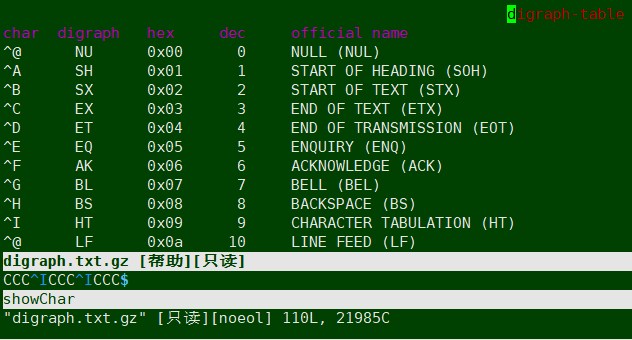
这里可以看到,^I 实际上是个二拼字符,在vim模式下按住ctrl+k,再输入HT即可输出一个^I。但是想要处理替换掉这个字符,是没法用HT去处理的。好消息是,查到对应的hex和dec了
查看ASCII码对照表
由以上步骤已经查到该字符的dec和hex,就可以在ascII码中查到对应的八进制十进制十六进制的码值。这里贴的是不分码值表,完整的表格自行百度
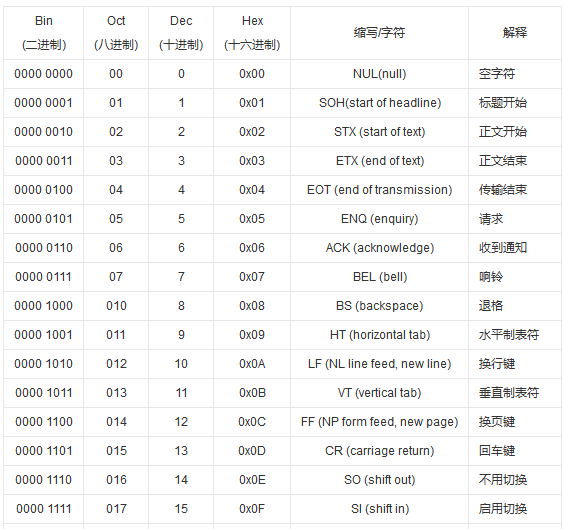
通过对照表可以查到^I对应的八进制码是011,dec是9,十六进制码值是0x09
替换字符
这里以八进制码值为例,处理转换^I,替换成普通分隔符|,直接用sed转换整个文件
sed -i 's/\o011/|/g' showChar
需要转义\
需要特殊前缀o识别是八进制