今天,我们一起聊聊进行 HTTP 调用需要注意的超时、重试、并发等问题。
与执行本地方法不同,进行 HTTP 调用本质上是通过 HTTP 协议进行一次网络请求。网络请求必然有超时的可能性,因此我们必须考虑到这三点:
-
首先,框架设置的默认超时是否合理;
-
其次,考虑到网络的不稳定,超时后的请求重试是一个不错的选择,但需要考虑服务端接口的幂等性设计是否允许我们重试;
-
最后,需要考虑框架是否会像浏览器那样限制并发连接数,以免在服务并发很大的情况下,HTTP 调用的并发数限制成为瓶颈。
Spring Cloud 是 Java 微服务架构的代表性框架。如果使用 Spring Cloud 进行微服务开发,就会使用 Feign 进行声明式的服务调用。如果不使用 Spring Cloud,而直接使用 Spring Boot 进行微服务开发的话,可能会直接使用 Java 中最常用的 HTTP 客户端 Apache HttpClient 进行服务调用。
接下来,我们就看看使用 Feign 和 Apache HttpClient 进行 HTTP 接口调用时,可能会遇到的超时、重试和并发方面的坑。
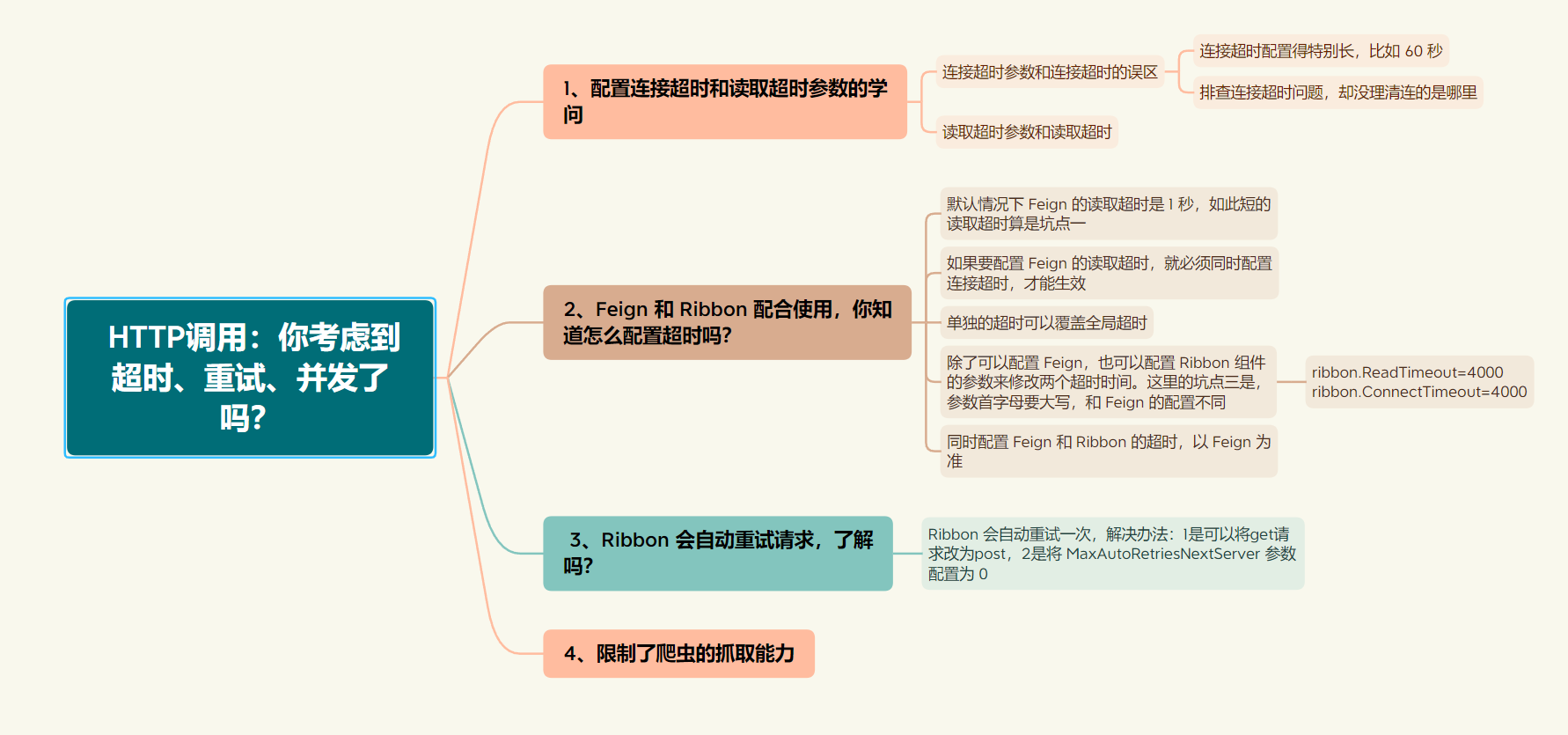
1、配置连接超时和读取超时参数的学问
对于 HTTP 调用,虽然应用层走的是 HTTP 协议,但网络层面始终是 TCP/IP 协议。TCP/IP 是面向连接的协议,在传输数据之前需要建立连接。几乎所有的网络框架都会提供这么两个超时参数:
-
连接超时参数
ConnectTimeout,让用户配置建连阶段的最长等待时间; -
读取超时参数
ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。
这两个参数看似是网络层偏底层的配置参数,不足以引起开发同学的重视。但,正确理解和配置这两个参数,对业务应用特别重要,毕竟超时不是单方面的事情,需要客户端和服务端对超时有一致的估计,协同配合方能平衡吞吐量和错误率。
连接超时参数和连接超时的误区有这么两个:
- **连接超时配置得特别长,比如 60 秒。**一般来说,TCP 三次握手建立连接需要的时间非常短,通常在毫秒级最多到秒级,不可能需要十几秒甚至几十秒。如果很久都无法建连,很可能是网络或防火墙配置的问题。这种情况下,如果几秒连接不上,那么可能永远也连接不上。因此,设置特别长的连接超时意义不大,将其配置得短一些(比如 1~5 秒)即可。如果是纯内网调用的话,这个参数可以设置得更短,在下游服务离线无法连接的时候,可以快速失败。
- **排查连接超时问题,却没理清连的是哪里。**通常情况下,我们的服务会有多个节点,如果别的客户端通过客户端负载均衡技术来连接服务端,那么客户端和服务端会直接建立连接,此时出现连接超时大概率是服务端的问题;而如果服务端通过类似 Nginx 的反向代理来负载均衡,客户端连接的其实是 Nginx,而不是服务端,此时出现连接超时应该排查 Nginx。
读取超时参数和读取超时则会有更多的误区,我将其归纳为如下三个。
**第一个误区:**认为出现了读取超时,服务端的执行就会中断。
我们来简单测试下。定义一个 client 接口,内部通过 HttpClient 调用服务端接口 server,客户端读取超时 2 秒,服务端接口执行耗时 5 秒。
@RestController
@RequestMapping("clientreadtimeout")
@Slf4j
public class ClientReadTimeoutController {
private String getResponse(String url, int connectTimeout, int readTimeout) throws IOException {
return Request.Get("http://localhost:45678/clientreadtimeout" + url)
.connectTimeout(connectTimeout)
.socketTimeout(readTimeout)
.execute()
.returnContent()
.asString();
}
@GetMapping("client")
public String client() throws IOException {
log.info("client1 called");
//服务端5s超时,客户端读取超时2秒
return getResponse("/server?timeout=5000", 1000, 2000);
}
@GetMapping("server")
public void server(@RequestParam("timeout") int timeout) throws InterruptedException {
log.info("server called");
TimeUnit.MILLISECONDS.sleep(timeout);
log.info("Done");
}
}
调用 client 接口后,从日志中可以看到,客户端 2 秒后出现了 SocketTimeoutException,原因是读取超时,服务端却丝毫没受影响在 3 秒后执行完成。
[11:35:11.943] [http-nio-45678-exec-1] [INFO ] [.t.c.c.d.ClientReadTimeoutController:29 ] - client1 called
[11:35:12.032] [http-nio-45678-exec-2] [INFO ] [.t.c.c.d.ClientReadTimeoutController:36 ] - server called
[11:35:14.042] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception
java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
...
[11:35:17.036] [http-nio-45678-exec-2] [INFO ] [.t.c.c.d.ClientReadTimeoutController:38 ] - Done
我们知道,类似 Tomcat 的 Web 服务器都是把服务端请求提交到线程池处理的,只要服务端收到了请求,网络层面的超时和断开便不会影响服务端的执行。因此,出现读取超时不能随意假设服务端的处理情况,需要根据业务状态考虑如何进行后续处理。
**第二个误区:**认为读取超时只是 Socket 网络层面的概念,是数据传输的最长耗时,故将其配置得非常短,比如 100 毫秒。
其实,发生了读取超时,网络层面无法区分是服务端没有把数据返回给客户端,还是数据在网络上耗时较久或丢包。
但,因为 TCP 是先建立连接后传输数据,对于网络情况不是特别糟糕的服务调用,通常可以认为出现连接超时是网络问题或服务不在线,而出现读取超时是服务处理超时。确切地说,读取超时指的是,向 Socket 写入数据后,我们等到 Socket 返回数据的超时时间,其中包含的时间或者说绝大部分的时间,是服务端处理业务逻辑的时间。
**第三个误区:**认为超时时间越长任务接口成功率就越高,将读取超时参数配置得太长。
进行 HTTP 请求一般是需要获得结果的,属于同步调用。如果超时时间很长,在等待服务端返回数据的同时,客户端线程(通常是 Tomcat 线程)也在等待,当下游服务出现大量超时的时候,程序可能也会受到拖累创建大量线程,最终崩溃。
对定时任务或异步任务来说,读取超时配置得长些问题不大。但面向用户响应的请求或是微服务短平快的同步接口调用,并发量一般较大,我们应该设置一个较短的读取超时时间,以防止被下游服务拖慢,通常不会设置超过 30 秒的读取超时。
你可能会说,如果把读取超时设置为 2 秒,服务端接口需要 3 秒,岂不是永远都拿不到执行结果了?的确是这样,因此设置读取超时一定要根据实际情况,过长可能会让下游抖动影响到自己,过短又可能影响成功率。甚至,有些时候我们还要根据下游服务的 SLA,为不同的服务端接口设置不同的客户端读取超时。
2、Feign 和 Ribbon 配合使用,你知道怎么配置超时吗?
刚才我强调了根据自己的需求配置连接超时和读取超时的重要性,你是否尝试过为 Spring Cloud 的 Feign 配置超时参数呢,有没有被网上的各种资料绕晕呢?
在我看来,为 Feign 配置超时参数的复杂之处在于,Feign 自己有两个超时参数,它使用的负载均衡组件 Ribbon 本身还有相关配置。那么,这些配置的优先级是怎样的,又哪些什么坑呢?接下来,我们做一些实验吧。
为测试服务端的超时,假设有这么一个服务端接口,什么都不干只休眠 10 分钟:
@PostMapping("/server")
public void server() throws InterruptedException {
//睡眠10分钟
TimeUnit.MINUTES.sleep(10);
}
首先,定义一个 Feign 来调用这个接口:
@FeignClient(name = "clientsdk")
public interface Client {
@PostMapping("/feignandribbon/server")
void server();
}
然后,通过 Feign Client 进行接口调用:
@GetMapping("client")
public void timeout() {
long begin=System.currentTimeMillis();
try{
client.server();
}catch (Exception ex){
log.warn("执行耗时:{}ms 错误:{}", System.currentTimeMillis() - begin, ex.getMessage());
}
}
在配置文件仅指定服务端地址的情况下:
clientsdk.ribbon.listOfServers=localhost:45678
结果如下:
[15:40:16.094] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:1007ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
从这个输出中,我们可以得到结论一,默认情况下 Feign 的读取超时是 1 秒,如此短的读取超时算是坑点一。
我们来分析一下源码。打开 RibbonClientConfiguration 类后,会看到 DefaultClientConfigImpl 被创建出来之后,ReadTimeout 和 ConnectTimeout 被设置为 1 s:
**
* Ribbon client default connect timeout.
*/
public static final int DEFAULT_CONNECT_TIMEOUT = 1000;
/**
* Ribbon client default read timeout.
*/
public static final int DEFAULT_READ_TIMEOUT = 1000;
@Bean
@ConditionalOnMissingBean
public IClientConfig ribbonClientConfig() {
DefaultClientConfigImpl config = new DefaultClientConfigImpl();
config.loadProperties(this.name);
config.set(CommonClientConfigKey.ConnectTimeout, DEFAULT_CONNECT_TIMEOUT);
config.set(CommonClientConfigKey.ReadTimeout, DEFAULT_READ_TIMEOUT);
config.set(CommonClientConfigKey.GZipPayload, DEFAULT_GZIP_PAYLOAD);
return config;
}
如果要修改 Feign 客户端默认的两个全局超时时间,你可以设置 feign.client.config.default.readTimeout 和 feign.client.config.default.connectTimeout 参数:
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
可见,3 秒读取超时生效了。注意:这里有一个大坑,如果你希望只修改读取超时,可能会只配置这么一行:
feign.client.config.default.readTimeout=3000
测试一下你就会发现,这样的配置是无法生效的!
结论二,也是坑点二,如果要配置 Feign 的读取超时,就必须同时配置连接超时,才能生效。
打开 FeignClientFactoryBean 可以看到,只有同时设置 ConnectTimeout 和 ReadTimeout,Request.Options 才会被覆盖:
if (config.getConnectTimeout() != null && config.getReadTimeout() != null) {
builder.options(new Request.Options(config.getConnectTimeout(),
config.getReadTimeout()));
}
更进一步,如果你希望针对单独的 Feign Client 设置超时时间,可以把 default 替换为 Client 的 name:
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
feign.client.config.clientsdk.readTimeout=2000
feign.client.config.clientsdk.connectTimeout=2000
可以得出结论三,单独的超时可以覆盖全局超时,这符合预期,不算坑:
[15:45:51.708] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:2006ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
结论四,除了可以配置 Feign,也可以配置 Ribbon 组件的参数来修改两个超时时间。这里的坑点三是,参数首字母要大写,和 Feign 的配置不同。
ribbon.ReadTimeout=4000
ribbon.ConnectTimeout=4000
可以通过日志证明参数生效:
[15:55:18.019] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:4003ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
最后,我们来看看同时配置 Feign 和 Ribbon 的参数,最终谁会生效?如下代码的参数配置:
clientsdk.ribbon.listOfServers=localhost:45678
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
ribbon.ReadTimeout=4000
ribbon.ConnectTimeout=4000
日志输出证明,最终生效的是 Feign 的超时:
[16:01:19.972] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:3006ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
结论五,同时配置 Feign 和 Ribbon 的超时,以 Feign 为准。这有点反直觉,因为 Ribbon 更底层所以你会觉得后者的配置会生效,但其实不是这样的。
在 LoadBalancerFeignClient 源码中可以看到,如果 Request.Options 不是默认值,就会创建一个 FeignOptionsClientConfig 代替原来 Ribbon 的 DefaultClientConfigImpl,导致 Ribbon 的配置被 Feign 覆盖:
IClientConfig getClientConfig(Request.Options options, String clientName) {
IClientConfig requestConfig;
if (options == DEFAULT_OPTIONS) {
requestConfig = this.clientFactory.getClientConfig(clientName);
} else {
requestConfig = new FeignOptionsClientConfig(options);
}
return requestConfig;
}
但如果这么配置最终生效的还是 Ribbon 的超时(4 秒),这容易让人产生 Ribbon 覆盖了 Feign 的错觉,其实这还是因为坑二所致,单独配置 Feign 的读取超时并不能生效:
clientsdk.ribbon.listOfServers=localhost:45678
feign.client.config.default.readTimeout=3000
feign.client.config.clientsdk.readTimeout=2000
ribbon.ReadTimeout=4000
3、 Ribbon 会自动重试请求,了解吗?
一些 HTTP 客户端往往会内置一些重试策略,其初衷是好的,毕竟因为网络问题导致丢包虽然频繁但持续时间短,往往重试下第二次就能成功,但一定要小心这种自作主张是否符合我们的预期。
之前遇到过一个短信重复发送的问题,但短信服务的调用方用户服务,反复确认代码里没有重试逻辑。那问题究竟出在哪里了?我们来重现一下这个案例。
首先,定义一个 Get 请求的发送短信接口,里面没有任何逻辑,休眠 2 秒模拟耗时:
@RestController
@RequestMapping("ribbonretryissueserver")
@Slf4j
public class RibbonRetryIssueServerController {
@GetMapping("sms")
public void sendSmsWrong(@RequestParam("mobile") String mobile, @RequestParam("message") String message, HttpServletRequest request) throws InterruptedException {
//输出调用参数后休眠2秒
log.info("{} is called, {}=>{}", request.getRequestURL().toString(), mobile, message);
TimeUnit.SECONDS.sleep(2);
}
}
配置一个 Feign 供客户端调用:
@FeignClient(name = "SmsClient")
public interface SmsClient {
@GetMapping("/ribbonretryissueserver/sms")
void sendSmsWrong(@RequestParam("mobile") String mobile, @RequestParam("message") String message);
}
Feign 内部有一个 Ribbon 组件负责客户端负载均衡,通过配置文件设置其调用的服务端为两个节点:
SmsClient.ribbon.listOfServers=localhost:45679,localhost:45678
编写一个客户端接口,通过 Feign 调用服务端:
@RestController
@RequestMapping("ribbonretryissueclient")
@Slf4j
public class RibbonRetryIssueClientController {
@Autowired
private SmsClient smsClient;
@GetMapping("wrong")
public String wrong() {
log.info("client is called");
try{
//通过Feign调用发送短信接口
smsClient.sendSmsWrong("13600000000", UUID.randomUUID().toString());
} catch (Exception ex) {
//捕获可能出现的网络错误
log.error("send sms failed : {}", ex.getMessage());
}
return "done";
}
}
在 45678 和 45679 两个端口上分别启动服务端,然后访问 45678 的客户端接口进行测试。因为客户端和服务端控制器在一个应用中,所以 45678 同时扮演了客户端和服务端的角色。
在 45678 日志中可以看到,29 秒时客户端收到请求开始调用服务端接口发短信,同时服务端收到了请求,2 秒后(注意对比第一条日志和第三条日志)客户端输出了读取超时的错误信息:
[12:49:29.020] [http-nio-45678-exec-4] [INFO ] [c.d.RibbonRetryIssueClientController:23 ] - client is called
[12:49:29.026] [http-nio-45678-exec-5] [INFO ] [c.d.RibbonRetryIssueServerController:16 ] - http://localhost:45678/ribbonretryissueserver/sms is called, 13600000000=>a2aa1b32-a044-40e9-8950-7f0189582418
[12:49:31.029] [http-nio-45678-exec-4] [ERROR] [c.d.RibbonRetryIssueClientController:27 ] - send sms failed : Read timed out executing GET http://SmsClient/ribbonretryissueserver/sms?mobile=13600000000&message=a2aa1b32-a044-40e9-8950-7f0189582418
而在另一个服务端 45679 的日志中还可以看到一条请求,30 秒时收到请求,也就是客户端接口调用后的 1 秒:
[12:49:30.029] [http-nio-45679-exec-2] [INFO ] [c.d.RibbonRetryIssueServerController:16 ] - http://localhost:45679/ribbonretryissueserver/sms is called, 13600000000=>a2aa1b32-a044-40e9-8950-7f0189582418
客户端接口被调用的日志只输出了一次,而服务端的日志输出了两次。虽然 Feign 的默认读取超时时间是 1 秒,但客户端 2 秒后才出现超时错误。显然,这说明客户端自作主张进行了一次重试,导致短信重复发送。
翻看 Ribbon 的源码可以发现,MaxAutoRetriesNextServer 参数默认为 1,也就是 Get 请求在某个服务端节点出现问题(比如读取超时)时,Ribbon 会自动重试一次:
// DefaultClientConfigImpl
public static final int DEFAULT_MAX_AUTO_RETRIES_NEXT_SERVER = 1;
public static final int DEFAULT_MAX_AUTO_RETRIES = 0;
// RibbonLoadBalancedRetryPolicy
public boolean canRetry(LoadBalancedRetryContext context) {
HttpMethod method = context.getRequest().getMethod();
return HttpMethod.GET == method || lbContext.isOkToRetryOnAllOperations();
}
@Override
public boolean canRetrySameServer(LoadBalancedRetryContext context) {
return sameServerCount < lbContext.getRetryHandler().getMaxRetriesOnSameServer()
&& canRetry(context);
}
@Override
public boolean canRetryNextServer(LoadBalancedRetryContext context) {
// this will be called after a failure occurs and we increment the counter
// so we check that the count is less than or equals to too make sure
// we try the next server the right number of times
return nextServerCount <= lbContext.getRetryHandler().getMaxRetriesOnNextServer()
&& canRetry(context);
}
解决办法有两个:
-
一是,把发短信接口从 Get 改为 Post。其实,这里还有一个 API 设计问题,有状态的 API 接口不应该定义为 Get。根据 HTTP 协议的规范,Get 请求用于数据查询,而 Post 才是把数据提交到服务端用于修改或新增。选择 Get 还是 Post 的依据,应该是 API 的行为,而不是参数大小。这里的一个误区是,Get 请求的参数包含在 Url QueryString 中,会受浏览器长度限制,所以一些同学会选择使用 JSON 以 Post 提交大参数,使用 Get 提交小参数。
-
二是,将 MaxAutoRetriesNextServer 参数配置为 0,禁用服务调用失败后在下一个服务端节点的自动重试。在配置文件中添加一行即可:
ribbon.MaxAutoRetriesNextServer=0
看到这里,你觉得问题出在用户服务还是短信服务呢?
在我看来,双方都有问题。就像之前说的,Get 请求应该是无状态或者幂等的,短信接口可以设计为支持幂等调用的;而用户服务的开发同学,如果对 Ribbon 的重试机制有所了解的话,或许就能在排查问题上少走些弯路。
4、并发限制了爬虫的抓取能力
除了超时和重试的坑,进行 HTTP 请求调用还有一个常见的问题是,并发数的限制导致程序的处理能力上不去。
我之前遇到过一个爬虫项目,整体爬取数据的效率很低,增加线程池数量也无济于事,只能堆更多的机器做分布式的爬虫。现在,我们就来模拟下这个场景,看看问题出在了哪里。
假设要爬取的服务端是这样的一个简单实现,休眠 1 秒返回数字 1:
@GetMapping("server")
public int server() throws InterruptedException {
TimeUnit.SECONDS.sleep(1);
return 1;
}
爬虫需要多次调用这个接口进行数据抓取,为了确保线程池不是并发的瓶颈,我们使用一个没有线程上限的 newCachedThreadPool 作为爬取任务的线程池(再次强调,除非你非常清楚自己的需求,否则一般不要使用没有线程数量上限的线程池),然后使用 HttpClient 实现 HTTP 请求,把请求任务循环提交到线程池处理,最后等待所有任务执行完成后输出执行耗时:
private int sendRequest(int count, Supplier<CloseableHttpClient> client) throws InterruptedException {
//用于计数发送的请求个数
AtomicInteger atomicInteger = new AtomicInteger();
//使用HttpClient从server接口查询数据的任务提交到线程池并行处理
ExecutorService threadPool = Executors.newCachedThreadPool();
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, count).forEach(i -> {
threadPool.execute(() -> {
try (CloseableHttpResponse response = client.get().execute(new HttpGet("http://127.0.0.1:45678/routelimit/server"))) {
atomicInteger.addAndGet(Integer.parseInt(EntityUtils.toString(response.getEntity())));
} catch (Exception ex) {
ex.printStackTrace();
}
});
});
//等到count个任务全部执行完毕
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
log.info("发送 {} 次请求,耗时 {} ms", atomicInteger.get(), System.currentTimeMillis() - begin);
return atomicInteger.get();
}
首先,使用默认的 PoolingHttpClientConnectionManager 构造的 CloseableHttpClient,测试一下爬取 10 次的耗时:
static CloseableHttpClient httpClient1;
static {
httpClient1 = HttpClients.custom().setConnectionManager(new PoolingHttpClientConnectionManager()).build();
}
@GetMapping("wrong")
public int wrong(@RequestParam(value = "count", defaultValue = "10") int count) throws InterruptedException {
return sendRequest(count, () -> httpClient1);
}
虽然一个请求需要 1 秒执行完成,但我们的线程池是可以扩张使用任意数量线程的。按道理说,10 个请求并发处理的时间基本相当于 1 个请求的处理时间,也就是 1 秒,但日志中显示实际耗时 5 秒:
[12:48:48.122] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.h.r.RouteLimitController :54 ] - 发送 10 次请求,耗时 5265 ms
查看 PoolingHttpClientConnectionManager 源码,可以注意到有两个重要参数:
-
defaultMaxPerRoute=2,也就是同一个主机 / 域名的最大并发请求数为 2。我们的爬虫需要 10 个并发,显然是默认值太小限制了爬虫的效率。 -
maxTotal=20,也就是所有主机整体最大并发为 20,这也是 HttpClient 整体的并发度。目前,我们请求数是 10 最大并发是 10,20 不会成为瓶颈。举一个例子,使用同一个 HttpClient 访问 10 个域名,defaultMaxPerRoute 设置为 10,为确保每一个域名都能达到 10 并发,需要把 maxTotal 设置为 100。
public PoolingHttpClientConnectionManager(
final HttpClientConnectionOperator httpClientConnectionOperator,
final HttpConnectionFactory<HttpRoute, ManagedHttpClientConnection> connFactory,
final long timeToLive, final TimeUnit timeUnit) {
...
this.pool = new CPool(new InternalConnectionFactory(
this.configData, connFactory), 2, 20, timeToLive, timeUnit);
...
}
public CPool(
final ConnFactory<HttpRoute, ManagedHttpClientConnection> connFactory,
final int defaultMaxPerRoute, final int maxTotal,
final long timeToLive, final TimeUnit timeUnit) {
...
}}
HttpClient 是 Java 非常常用的 HTTP 客户端,这个问题经常出现。你可能会问,为什么默认值限制得这么小。
其实,这不能完全怪 HttpClient,很多早期的浏览器也限制了同一个域名两个并发请求。对于同一个域名并发连接的限制,其实是 HTTP 1.1 协议要求的,这里有这么一段话:
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
HTTP 1.1 协议是 20 年前制定的,现在 HTTP 服务器的能力强很多了,所以有些新的浏览器没有完全遵从 2 并发这个限制,放开并发数到了 8 甚至更大。如果需要通过 HTTP 客户端发起大量并发请求,不管使用什么客户端,请务必确认客户端的实现默认的并发度是否满足需求。
既然知道了问题所在,我们就尝试声明一个新的 HttpClient 放开相关限制,设置 maxPerRoute 为 50、maxTotal 为 100,然后修改一下刚才的 wrong 方法,使用新的客户端进行测试:
httpClient2 = HttpClients.custom().setMaxConnPerRoute(10).setMaxConnTotal(20).build();
输出如下,10 次请求在 1 秒左右执行完成。可以看到,因为放开了一个 Host 2 个并发的默认限制,爬虫效率得到了大幅提升:
发送 10 次请求,耗时 1023 ms
5、总结
今天,我和你分享了 HTTP 调用最常遇到的超时、重试和并发问题。
连接超时代表建立 TCP 连接的时间,读取超时代表了等待远端返回数据的时间,也包括远端程序处理的时间。在解决连接超时问题时,我们要搞清楚连的是谁;在遇到读取超时问题的时候,我们要综合考虑下游服务的服务标准和自己的服务标准,设置合适的读取超时时间。此外,在使用诸如 Spring Cloud Feign 等框架时务必确认,连接和读取超时参数的配置是否正确生效。
对于重试,因为 HTTP 协议认为 Get 请求是数据查询操作,是无状态的,又考虑到网络出现丢包是比较常见的事情,有些 HTTP 客户端或代理服务器会自动重试 Get/Head 请求。如果你的接口设计不支持幂等,需要关闭自动重试。但,更好的解决方案是,遵从 HTTP 协议的建议来使用合适的 HTTP 方法。
最后我们看到,包括 HttpClient 在内的 HTTP 客户端以及浏览器,都会限制客户端调用的最大并发数。如果你的客户端有比较大的请求调用并发,比如做爬虫,或是扮演类似代理的角色,又或者是程序本身并发较高,如此小的默认值很容易成为吞吐量的瓶颈,需要及时调整。