selenium使用
- 一 bs4搜索文档树
- 二 css选择器
- 三 selenium基本使用
- 四 无界面浏览器
- 五 selenium其它用法
- 5.1 登录百度
- 5.2 获取位置属性大小,文本
- 5.3 元素操作
- 5.4 执行js代码
- 5.5 切换选项卡
- 5.6 浏览器前进后退
- 5.7 异常处理
- 六 selenium登录cnblogs获取cookie
- 七 抽屉半自动点赞
一 bs4搜索文档树
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title">asdfasdf<b id="bbb" class="boldest">The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# 1 字符串:可以按照标签名,属性名查找
# res = soup.find(name='a', id='link2')
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
# res = soup.find(href='http://example.com/tillie')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
# res = soup.find(class_='story')
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
# res = soup.body.find('p')
# <p class="title" id="my p">asdfasdf<b class="boldest" id="bbb">The Dormouse's story</b>
# </p>
# res = soup.body.find(string='Elsie')
# Elsie
res = soup.find(attrs={'class': 'sister'})
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(res)
二 css选择器
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title">asdfasdf<b id="bbb" class="boldest">The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# res = soup.select('a')
# res = soup.select('#link1')
# res = soup.select('.sister')
# res = soup.select('body>p>a')
# 只需要会了css选择,几乎所有的解析器[bs4,lxml...],都会支持css和xpath
# res = soup.select('body>p>a:nth-child(2)')
# res = soup.select('body>p>a:nth-last-child(1)')
# [attribute=value]
res = soup.select('a[href="http://example.com/tillie"]')
print(res)
三 selenium基本使用
selenium,可以操作浏览器,控制浏览器,模拟人的行为。
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题。
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
使用:
1.安装模块
pip3 install selenium
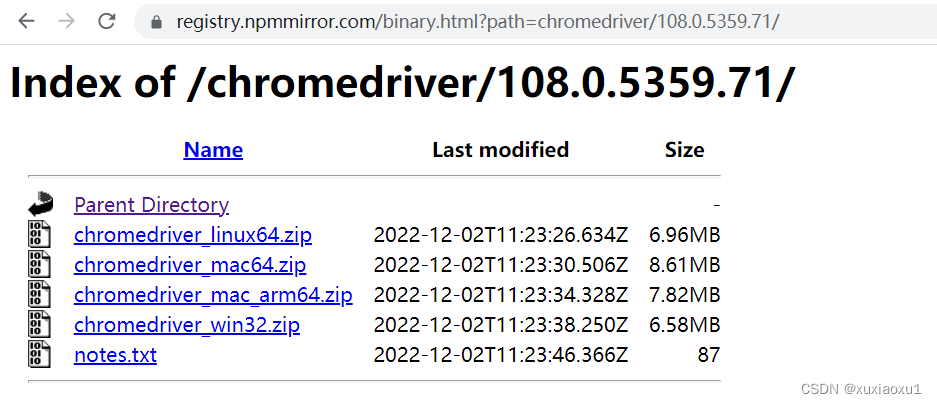
2.下载浏览器驱动:selenium操作浏览器,需要有浏览器(谷歌浏览器)。
谷歌浏览器驱动 https://registry.npmmirror.com/binary.html?path=chromedriver/
3.浏览器版本对应的驱动,找到相应的驱动。
4.简单使用
from selenium import webdriver
import time
# 驱动放到环境变量中,就不用传executable_path参数
# 打开一个浏览器
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 在地址栏输入网站
driver.get('https://www.baidu.com')
time.sleep(3)
# 关闭浏览器
driver.close()
四 无界面浏览器
做爬虫,不希望有一个浏览器打开,谷歌支持无头浏览器,后台运行,没有浏览器的图形化(GUI)界面。
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') # 指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
chrome_options.add_argument('--headless') # 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
# chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" # 手动指定使用的浏览器位置
driver = Chrome(executable_path='./chromedriver.exe', options=chrome_options)
driver.get('https://www.jd.com')
print(driver.page_source) # 浏览器中看到的页面的内容
time.sleep(3)
# 关闭tab页
driver.close()
# 关闭浏览器
driver.quit()
五 selenium其它用法
5.1 登录百度
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument('--disable-gpu')
drive = Chrome('./chromedriver.exe', options=chrome_options)
drive.implicitly_wait(10)
drive.get('https://www.baidu.com')
drive.implicitly_wait(10) # 隐式等待10s
drive.maximize_window() # 全屏
# 通过a标签文字内容查找标签的方式 找到登录按钮
a = drive.find_element(by=By.LINK_TEXT, value='登录')
# 点击标签
a.click()
# 找到用户名的输入框 并输入用户名
username_input = drive.find_element(by=By.ID, value='TANGRAM__PSP_11__userName')
username_input.send_keys('百度手机号')
# 找到密码的输入框 并输入密码
password_input = drive.find_element(by=By.ID, value='TANGRAM__PSP_11__password')
password_input.send_keys('百度密码')
# 找到登陆按钮 并点击
logon_btn = drive.find_element(by=By.ID, value='TANGRAM__PSP_11__submit')
logon_btn.click()
time.sleep(3)
drive.close()
drive.quit()
5.2 获取位置属性大小,文本
# 查找标签
drive.find_element(by=By.ID,value='id号')
drive.find_element(by=By.LINK_TEXT,value='a标签文本内容')
drive.find_element(by=By.PARTIAL_LINK_TEXT,value='a标签文本内容模糊匹配')
drive.find_element(by=By.CLASS_NAME,value='类名')
drive.find_element(by=By.TAG_NAME,value='标签名')
drive.find_element(by=By.NAME,value='属性name')
# 通用的
bro.find_element(by=By.CSS_SELECTOR,value='css选择器')
bro.find_element(by=By.XPATH,value='xpath选择器')
获取12306网站的扫码登陆二维码信息
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
driver = Chrome(executable_path='./chromedriver.exe')
driver.get('https://kyfw.12306.cn/otn/resources/login.html')
driver.implicitly_wait(10)
# 找到扫码登陆按钮并点击
sm_btn = driver.find_element(by=By.LINK_TEXT, value='扫码登录')
sm_btn.click()
# 找到登录二维码
code = driver.find_element(by=By.ID, value='J-qrImg')
code.screenshot('a.png')
# 获取标签位置,大小
print(code.location) # {'x': 836, 'y': 254}
print(code.size) # {'height': 158, 'width': 158}
print(code.tag_name) # img
print(code.id) # 96e7c537-3301-4e5b-a3db-208401f68dfe
time.sleep(60)
driver.close()
5.3 元素操作
# 点击
标签.click()
# input写文字
标签.send_keys('文字')
#input清空文字
标签.clear()
# 模拟键盘操作
from selenium.webdriver.common.keys import Keys
input_search.send_keys(Keys.ENTER)
5.4 执行js代码
from selenium.webdriver import Chrome
import time
driver = Chrome(executable_path='./chromedriver.exe')
driver.get('https://www.jd.com')
# driver.execute_script('alert(123)')
# 滚动页面,到最底部
for i in range(10):
y = 400 * (i + 1)
driver.execute_script(f'scrollTo(0,{y})')
time.sleep(1)
driver.close()
5.5 切换选项卡
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('https://www.jd.com/')
# 使用js打开新的选项卡
driver.execute_script('window.open()')
# 切换到这个选项卡上,刚刚打开的是第一个
driver.switch_to.window(driver.window_handles[1])
driver.get('https://www.taobao.com')
time.sleep(2)
driver.switch_to.window(driver.window_handles[0])
time.sleep(3)
driver.close()
driver.quit()
5.6 浏览器前进后退
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('https://www.jd.com/')
time.sleep(2)
driver.get('https://www.taobao.com/')
time.sleep(2)
driver.get('https://www.baidu.com/')
# 后退一下
driver.back()
time.sleep(1)
# 前进一下
driver.forward()
time.sleep(3)
driver.close()
5.7 异常处理
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
try:
pass
except Exception as e:
print(e)
finally:
bro.close()
六 selenium登录cnblogs获取cookie
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import json
# 登录过程
# bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# bro.get('https://www.cnblogs.com/')
# bro.implicitly_wait(10)
# try:
# # 找到登录按钮
# submit_btn = bro.find_element(By.LINK_TEXT, value='登录')
# submit_btn.click()
# time.sleep(1)
# username = bro.find_element(By.ID, value='mat-input-0')
# password = bro.find_element(By.ID, value='mat-input-1')
# username.send_keys("616564099@qq.com")
# password.send_keys('sadfasdfads')
#
# submit = bro.find_element(By.CSS_SELECTOR,
# value='body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
#
# time.sleep(20)
# submit.click()
# # 会有验证码,滑动,手动操作完了,敲回车,程序继续往下走
# input()
# # 已经登录成功了
#
# cookie = bro.get_cookies()
# print(cookie)
# with open('cnblogs.json', 'w', encoding='utf-8') as f:
# json.dump(cookie, f)
#
# time.sleep(5)
# except Exception as e:
# print(e)
# finally:
# bro.close()
# 打开cnblose,自动写入cookie,就是登录状态了
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('https://www.cnblogs.com/')
bro.implicitly_wait(10)
time.sleep(3)
# 把本地的cookie写入,就登录了
with open('cnblogs.json','r',encoding='utf-8') as f:
cookie=json.load(f)
for item in cookie:
bro.add_cookie(item)
# 刷新一下页面
bro.refresh()
time.sleep(10)
bro.close()
七 抽屉半自动点赞
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import json
import requests
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('https://dig.chouti.com/')
bro.implicitly_wait(10)
try:
submit = bro.find_element(by=By.ID, value='login_btn')
bro.execute_script("arguments[0].click()", submit)
# submit.click() # 有的页面button能找到,但是点击不了,报错,可以使用js点击它
time.sleep(2)
username = bro.find_element(by=By.NAME, value='phone')
username.send_keys('18953675221')
password = bro.find_element(by=By.NAME, value='password')
password.send_keys('lqz123')
time.sleep(3)
submit_button = bro.find_element(By.CSS_SELECTOR,
'body > div.login-dialog.dialog.animated2.scaleIn > div > div.login-footer > div:nth-child(4) > button')
submit_button.click()
# 验证码
input()
cookie = bro.get_cookies()
print(cookie)
with open('chouti.json', 'w', encoding='utf-8') as f:
json.dump(cookie, f)
# 找出所有文章的id号
div_list = bro.find_elements(By.CLASS_NAME, 'link-item')
l = []
for div in div_list:
article_id = div.get_attribute('data-id')
l.append(article_id)
except Exception as e:
print(e)
finally:
bro.close()
# 继续往下写,selenium完成它的任务了,登录---》拿到cookie,使用requests发送[点赞]
print(l)
with open('chouti.json', 'r', encoding='utf-8')as f:
cookie = json.load(f)
# 小细节,selenium的cookie不能直接给request用,需要有些处理
request_cookies = {}
for item in cookie:
request_cookies[item['name']] = item['value']
print(request_cookies)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
for i in l:
data = {
'linkId': i
}
res = requests.post('https://dig.chouti.com/link/vote', data=data, headers=header, cookies=request_cookies)
print(res.text)

![[附源码]计算机毕业设计JAVA圆梦山区贫困学生助学系统](https://img-blog.csdnimg.cn/487a2afd23324c34b53c4a239af39c79.png)