Hive
- Hive简介
- Hive架构
- HiveSQL语法不同之处
- 建表语句
- 查询语句
- Hive查看执行计划
- Hive文件格式
Hive简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
通过Hive可以将mapreduce程序的复杂编写过程抽象为简单的sql语句,它提供一种sql语句到mapreduce程序的映射,提高了开发效率。
另外:
(1)Hive中每张表的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
(3)执行程序运行在Yarn上
Hive架构
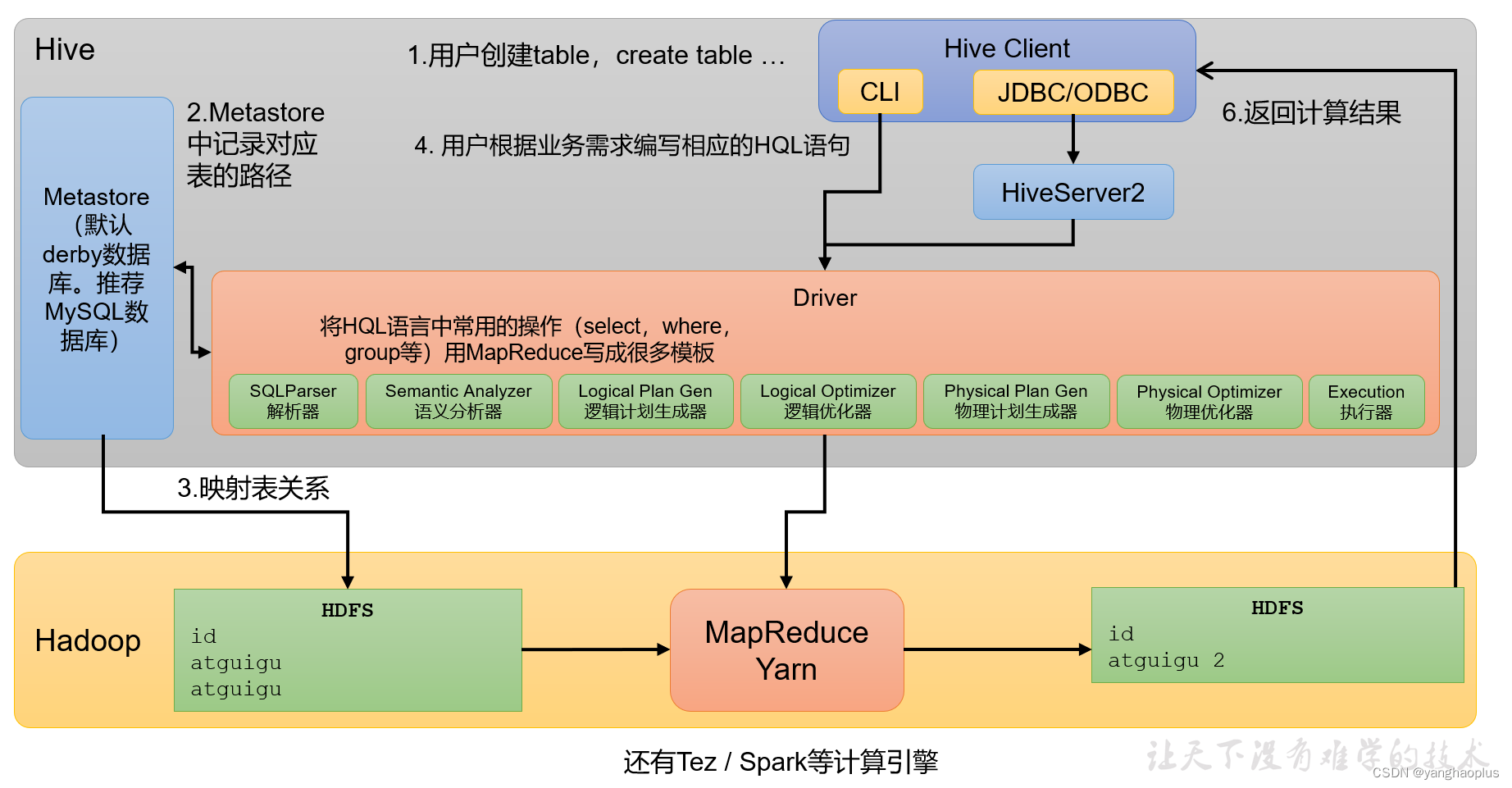
其架构如下图所示,
-
Hive Client
其中Hive Client就代表我们的客户端,如同mysql的client一样,不同的是这里有两种客户端,一种是本地的命令行接口CLI(command-line interface),另一种是远程通过JDBC等连接的客户端,这种远程连接的需要使用HiveServer2来统一代理,在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。 -
Metastore
元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。注意:这里只存储抽线出来的表的信息,真正的元数据还是保存在HDFS上的。(可以只有空表,也可以在hdfs上有数据,但是没有对应的元数据表,这两个的映射是通过hive实现的)元数据默认保存在一个自带的derby数据库中,但是derby数据库只支持单客户端访问,生产环境中为了多人开发,推荐使用MySQL存储Metastore。 -
Driver
对sql语句做语法分析,解析,优化,然后交给对应执行引擎(可以是mapreduce,也可以是spark,tez等)执行的一个模块,包含以下几部分:
(1)解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
(2)语义分析(Semantic Analyzer):将AST进一步划分为QeuryBlock
(3)逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
(4)逻辑优化器(Logical Optimizer):对逻辑计划进行优化
(5)物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
(6)物理优化器(Physical Optimizer):对物理计划进行优化
(7)执行器(Execution):执行该计划,得到查询结果并返回给客户端 -
Hadoop
数据使用HDFS进行存储,可以选择MapReduce/Tez/Spark进行计算。资源的调度基于Yarn。Hadoop中HDFS,Yarn和MapReduce部分见之前的文章。
HiveSQL语法不同之处
和普通sql语法不同的几个在于窗口函数,炸裂函数,以及用户自定义函数UDF等,当然,建表语句也有很多不同的,包括分区,分桶等。此外,对应的数据类型也更为复杂,包括array,map和struct等。
建表语句
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
查询语句
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference -- 从什么表查
[WHERE where_condition] -- 过滤
[GROUP BY col_list] -- 分组查询
[HAVING col_list] -- 分组后过滤
[ORDER BY col_list] -- 排序
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
Hive查看执行计划
Hive查看执行计划的语句和sql类似,
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql
注:FORMATTED、EXTENDED、DEPENDENCY关键字为可选项,各自作用如下。
- FORMATTED:将执行计划以JSON字符串的形式输出
- EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
- DEPENDENCY:输出执行计划读取的表及分区
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
Hive文件格式
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。
text file和sequence file是基于行存储的,默认是text file,文本文件中的一行内容,就对应Hive表中的一行记录。
ORC和parquet都是基于列存储的,基于列存储方便对数据指定压缩算法, 减少网络io和磁盘占用,且sql语句中往往只需要特定列。
这两种基于列存储的文件格式类似,解析式都需要从末尾先读取特定字段的一个代表长度的数据,然后向前解析,且列数据和列的元数据信息(数据信息包含了该列的数据类型、该列的编码方式、位置等信息。)也单独存放的。
其中parquet是目前使用的主流格式。