Selenium 环境配置好之后,我们就可以使用 Selenium 来操作浏览器,做一些我们想做的事情了。在我们爬取网页过程中,经常发现我们想要获得的数据并不能简单的通过解析 HTML 代码获取,这些数据是通过 AJAX 异步加载方式或经过 JS 渲染后才呈现在页面上显示出来。这种情况下我们就可以使用 Selenium 来模拟浏览器浏览页面,进而解决 JavaScript 渲染的问题。
浏览器设置
打开浏览器
我们用最简洁的代码来打开 Chrome 浏览器,并访问 http://www.baidu.com 这个网站:
from selenium import webdriver# 声明浏览器对象driver = webdriver.Chrome()# 访问页面driver.get("http://www.baidu.com")
我们可以看到桌面会弹出一个浏览器窗口,并打开了百度的首页,如下图:
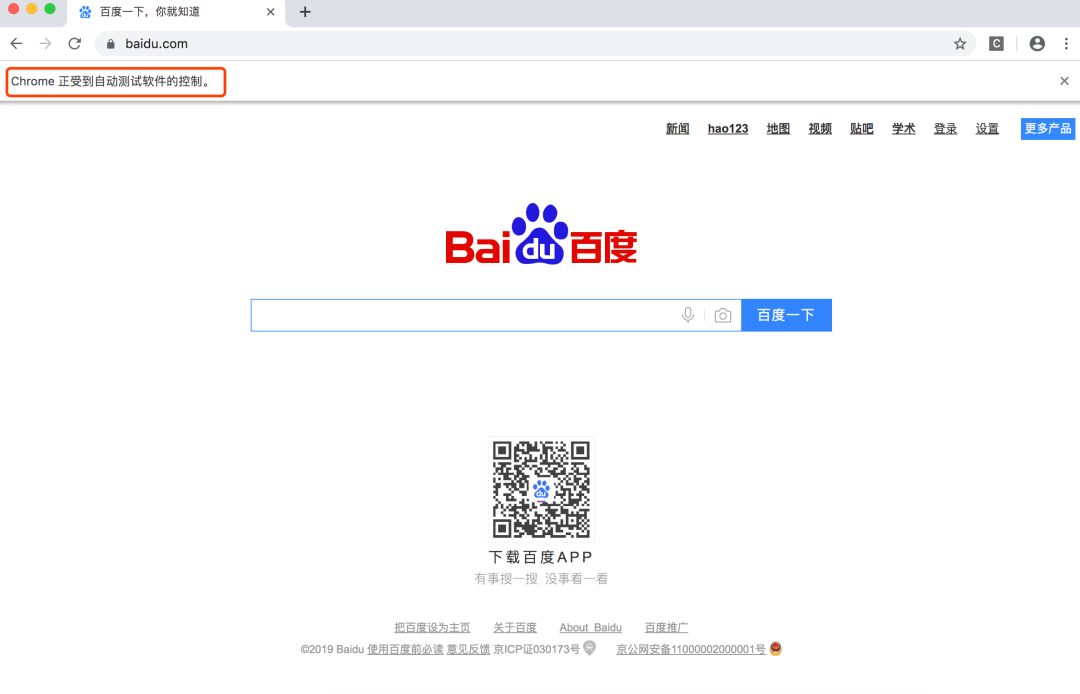
selenium-open-browser
注意红框圈住的部分,这表示这个窗口是我们程序打开的,现在浏览器的控制权在我们的程序中,我们可以用代码让浏览器摆出各种姿势了!
设置浏览器参数
为了避免每次运行程序都打开一个窗口,我们也可以设置无窗口访问,只需添加浏览器参数即可:
from selenium import webdriver# 设置无窗口chrome_options = webdriver.ChromeOptions()chrome_options.add_argument('--headless')# 声明浏览器对象driver = webdriver.Chrome(options=chrome_options)# 访问页面driver.get("http://www.baidu.com")
常见的浏览器参数还有:
# 启动就最大化--start-maximized# 指定用户文件夹 User Data 路径,可以把书签这样的用户数据保存在系统分区以外的分区–-user-data-dir=”[PATH]”# 指定缓存Cache路径–-disk-cache-dir=”[PATH]“# 指定Cache大小,单位Byte–-disk-cache-size=100# 隐身模式启动–-incognito# 禁用Javascript–-disable-javascript# 禁止加载所有插件,可以增加速度--disable-plugins# 禁用JavaScript--disable-javascript# 禁用弹出拦截--disable-popup-blocking# 禁用插件--disable-plugins# 禁用图像--disable-images
还有其他好多参数,具体可参见 https://peter.sh/experiments/chromium-command-line-switches/ ,该网站罗列了所有的参数。
设置代理
设置代理很简单,只需要添加一个浏览器参数就行:
chrome_options.add_argument('--proxy-server=http://{ip}:{port}')在参数里面加上代理的 IP 和端口号。
获取页面元素
获取单个元素
selenium 查找元素有两种方法:第一种是指定使用哪种方法去查找元素,比如指定 CSS 选择器或者根据 xpath 去查找;另一种是直接使用 find_element() ,传入的第一个参数为需要使用的元素查找方法,第二个参数为查找值。来看下例:
from selenium import webdriverfrom selenium.webdriver.common.by import By# 声明浏览器对象driver = webdriver.Chrome()# 访问页面driver.get("http://www.baidu.com")# 通过id查找element = driver.find_element_by_id("kw")print(element.tag_name)# 通过name查找element = driver.find_element_by_name("wd")print(element.tag_name)# 通过xpath查找element = driver.find_element_by_xpath('//*[@id="kw"]')print(element.tag_name)# 通过另一种方式查找element = driver.find_element(By.ID, "kw")print(element.tag_name)
上面例子中,我们通过不同的方式来获取百度的搜索框,并且打印 tag_name 属性,最终的结果都是一样的:input 。
获取多个元素
我们也可以通过 find_elements() 方法获取多个属性,结果会以 list 的形式返回。我们来看例子:
from selenium import webdriverfrom selenium.webdriver.common.by import By# 声明浏览器对象driver = webdriver.Chrome()# 访问页面driver.get("http://www.baidu.com")# 查找多个元素elements = driver.find_elements(By.CLASS_NAME, 'mnav')for e in elements:print(e.text)# 输出结果新闻hao123地图视频贴吧学术
上例中,我们通过 class_name 来获取百度首页上方的百度导航,接着将获取到的导航栏的名称打印了出来。
页面操作
我们可以使用 selenium 来模拟页面操作,例如鼠标点击事件,键盘事件等。我们来看一下例子:
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time# 声明浏览器对象driver = webdriver.Chrome()# 访问页面driver.get("http://www.baidu.com")# 获取百度搜索框元素element = driver.find_element(By.ID,"kw")# 在搜索框中输入关键词seleniumelement.send_keys("selenium")# 点击"百度一下"按钮driver.find_element(By.XPATH,'//*[@id="su"]').click()time.sleep(5)# 清空搜索框关键词element.clear()time.sleep(2)# 在搜索框中输入关键词python,并模拟键盘的enter操作element.send_keys("python", Keys.ENTER)time.sleep(5)driver.close()
在例子中,我们先是找到百度的搜索框对应的元素,然后模拟在搜索框中输入关键词 “selenium”,接下来模拟点击"百度一下"按钮,我们可以看到页面中出现了搜索 “selenium” 的结果。
接着我们使用 clear() 方法清空了搜索框,然后模拟输入关键词 “python” 并且模拟键盘的 enter 键操作,同样获得了搜索 “python” 的结果。
当然,我们还可以模拟鼠标右击、双击、拖拽等操作,就留给大家自己去探索了。
浏览器操作
等待加载
请求网页时,可能会存在 AJAX 异步加载的情况。而 selenium 只会加载主网页,并不会考虑到 AJAX 的情况。因此,使用时需要等待一些时间,让网页加载完全后再进行操作。
隐式等待
使用隐式等待时,如果 webdriver 没有找到指定的元素,将继续等待指定元素出现,直至超出设定时间,如果还是没有找到指定元素,则抛出找不到元素的异常。默认等待时间为 0。隐式等待是对整个页面进行等待。需要特别说明的是:隐性等待对整个 driver 的周期都起作用,所以只要设置一次即可。
我们来看下例:
from selenium import webdriverfrom selenium.webdriver.common.keys import Keys# 声明浏览器对象driver = webdriver.Chrome()# 设置隐式等待时间,单位为秒driver.implicitly_wait(0)# 访问页面driver.get("https://www.baidu.com/")# 设置搜索关键词element = driver.find_element(By.ID,"kw")element.send_keys("Selenium", Keys.ENTER)# 页面右边的"相关术语"element2 = driver.find_element(By.CLASS_NAME,"opr-recommends-merge-p")print(element2)
这个例子中,我先打开浏览器访问百度首页,然后在搜索框输入 “Selenium” 关键字,再回车查询。百度会根据输入的关键词在页面的右边展示“相关术语”,这一步是异步加载,需要时间来查询和传输,而我们设置的等待时间是 0,所以肯定会超时。运行后我们会看到报错:
# 报错信息selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":".opr-recommends-merge-p"}(Session info: chrome=77.0.3865.120)
当我们把等待时间设置为 10 秒时,我们会看到控制台的正确打印了。
显式等待
显式等待是对指定的元素进行等待。首先判定等待条件是否成立,如果成立,则直接返回;如果条件不成立,则等待最长时间为设置的等待时间,如果超过等待时间后仍然没有满足等待条件,则抛出异常。
我们来看一下例子:
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as EC# 声明浏览器对象driver = webdriver.Chrome()# 访问页面driver.get("https://www.baidu.com/")# 设置搜索关键词element = driver.find_element(By.ID,"kw")element.send_keys("selenium", Keys.ENTER)# 此时页面右边的"相关术语"还没有加载出来,肯定会报错#element1 = driver.find_element(By.CLASS_NAME,"opr-recommends-merge-p")#print(lement1)# 显示等待10秒,直到页面右边的"相关术语"出现WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "opr-recommends-merge-p")))# 获取页面右边的"相关术语"element2 = driver.find_element_by_class_name("opr-recommends-merge-p")print(element2)
运行这段代码,在打印 element1 的时候肯定会报错,因为此时页面右边的“相关术语”还没加载出来。我们注释掉获取和打印 element1 的这两行,然后设置一个显式的等待条件和 10 秒的等待时间,element2 就可以顺利打印出来了。
浏览器前进和后退
我们可以通过 selenium 来操纵浏览器的前进和后退,方法很简单,分别是 back() 和 forward()。来看下例:
from selenium import webdriverimport time# 声明浏览器对象driver = webdriver.Chrome()# 访问百度driver.get("http://www.baidu.com")time.sleep(2)# 访问微博driver.get("https://weibo.com")time.sleep(2)# 访问知乎driver.get("http://www.zhihu.com")time.sleep(2)# 返回上个页面driver.back()time.sleep(2)# 前进到下个页面driver.forward()# 退出driver.close()
我们首先依次打开百度、微博和知乎三个网站(中间设置的等待时间是为了更好地看演示效果)。然后我们调用返回上个页面方法,可以看到浏览器返回到了微博页面,接着我们调用前进到下个页面方法,可以看到浏览器回到了知乎页面。
操作 Cookie
我们可以通过 selenium 来设置浏览器的 cookie,包括添加 cookie ,删除 cookie ,获取 cookie 等操作。我们来看个例子:
from selenium import webdriver# 声明浏览器对象driver = webdriver.Chrome()# 访问百度driver.get("http://www.baidu.com")# 获取当前的cookieprint(driver.get_cookies())# 添加cookiedriver.add_cookie({'name': 'mycookie', 'value': 'world'})# 获取设置的cookieprint(driver.get_cookie('mycookie'))# 删除设置的cookiedriver.delete_cookie('mycookie')# 再次获取设置的cookieprint(driver.get_cookie('mycookie'))# 清除所有cookiedriver.delete_all_cookies()# 再次获取cookieprint(driver.get_cookies())# 退出driver.close()# 输出信息[{'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1422_21106_29721_29568_29221_26350_29589'}, {'domain': '.baidu.com', 'expiry': 1570877928.79997, 'httpOnly': False, 'name': 'BDORZ', 'path': '/', 'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598'}, {'domain': 'www.baidu.com', 'expiry': 1571655528, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '123253'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.baidu.com', 'expiry': 3718275175.123787, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1570791528'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'delPer', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.baidu.com', 'expiry': 3718275175.123763, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '5A2BAF0B0AE83FA189BE38C65DC65395'}, {'domain': 'www.baidu.com', 'expiry': 1570791529.123808, 'httpOnly': False, 'name': 'BD_LAST_QID', 'path': '/', 'secure': False, 'value': '10847283847030224144'}, {'domain': '.baidu.com', 'expiry': 3718275175.123643, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': '5A2BAF0B0AE83FA189BE38C65DC65395:FG=1'}]{'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'mycookie', 'path': '/', 'secure': True, 'value': 'world'}None[]
在上例中,我们通过 add_cookie() 方法,来设置 cookie 的名称和值,通过给 delete_cookie() 方法传递 cookie 的名称来删除 cookie,还可以通过 get_cookies() 和 delete_all_cookies() 来获取所有 cookie 以及删除所有 cookie 。
标签管理
有些时候我们需要在浏览器里切换标签页,或者增加一个新标签页,或者删除一个标签页,都可以使用 selenium 来实现。我们来看例子:
from selenium import webdriverimport time# 声明浏览器对象driver = webdriver.Chrome()# 访问百度driver.get("http://www.baidu.com")time.sleep(2)# 新增一个标签页driver.execute_script('window.open()')time.sleep(2)# 打印标签页print(driver.window_handles)# 切换至标签页1(当前标签页为0)driver.switch_to.window(driver.window_handles[1])time.sleep(2)# 在当前标签页访问知乎driver.get("http://www.zhihu.com")time.sleep(2)# 切换至标签页0driver.switch_to.window(driver.window_handles[0])time.sleep(2)# 在标签页0访问微博driver.get("http://www.weibo.com")time.sleep(2)# 关闭driver.close()# 退出driver.quit()
大家运行代码就可以体会到切换标签页和访问网页的变化,中间加了等待是为了延迟变化。另外,注意标签页从左往右是从 0 开始编号的。
总结
本节给大家介绍了 Selenium 的常见使用方法,利用这些方法我们可以很轻易地去操纵浏览器,让浏览器按照我们预设的规则来顺序执行操作指令。当然本文中列举的只是 selenium 的一部分操作,还有很多丰富的功能等着大家自己去探索。如果你能够熟练地运用和组合这些操作,你会发现还有更多复杂好玩的事情等着你去探索!