1、概览
在CM3上编程,既可以使用C也可以使用汇编,keil也支持C++,但是大多数人还是会在C与汇编。C与汇编都“尺有所短,寸有所长”,不能互相取代。使用C能开发大型程序,而汇编则用于执行特种任务。
1.1 使用汇编
如果工程比较小,使用纯汇编常常是可行的,而且能使我们随心所欲地优化和控制程序。不过,这么一来的开发周期会变长。尤其是当工程变大,需要处理比较复杂的数据结构,以及要管理函数库时,汇编那狰狞的真面目就会渐显出来:各种地址和间接引用千头万绪;bug劈头盖脸;甚至好几天都改不完,工作量激增,简直就是自虐。(汇编狗都不用,有时候,我们连狗都不如)
不论如何,时间宝贵。我们应该以C来实现程序的大框架,而本着好钢用在刀刃上的原则来使用汇编,因为只有在不多的特殊场合是适合使用汇编,甚至是非使用汇编语言不可的,它们包括:
无法用C写成的函数,如操作特殊功能寄存器,以及实施互斥访问。
在危急关头执行处理的子程序(如,NMI服务例程)。
存储器极度受限,只有使用汇编才可能把程序或数据挤进去。
执行频率非常高的子程序,如操作系统的调度程序。
与处理器体系结构相关的子程序,如上下文切换。
对性能要求极高的应用,如防空炮的火控系统。
1.2 使用C
用C写的程序可以移植,并且操作复杂数据结构时远远比汇编方便。但因为C是一种通用语言——至少是低等高级语言,它并不指定如何初始化具体的处理器(用于在main执行前准备好执行环境)。解决这个问题时,不同的工具链都有自己的一套方法。
尽管在使用了C后,大大加速了开发,但是底层的系统控制往往还需要汇编代码。很多编译器都允许我们直接在C代码中插汇编,称为“内联汇编”;另外还允许我们写独立的汇编模块,与编译后的C模块一起连接。以往,使用内联汇编的作法比较多,但是在ARM编译器中,不支持对Thumb-2指令的内联汇编。取而代之的,是从RealView C编译器的3.0版开始,新增了所谓“嵌入式汇编”的功能,它支持Thumb-2指令。它让我们可以在C程序中插入使用汇编语言编写的函数,例如:
_asm void SetFaultMask(unsigned int new_value)
{
//在这里使用汇编代码实现本函数
MSR FAULTMASK, new_value //把new_value写入FAULTMASK中BX LR //返回主程序(不可省略)
}RealView C编译器对嵌入式汇编的详细论述,在《RVCT 3.0 Compiler and LibraryGuide(Ref6)》中给出。在CM3中,嵌入式汇编还是比较需要的,因为常常会有访问特殊功能寄存器的时候。比如,在设置堆栈时,就要使用MRS/MSR指令。对于其它不能由编译器产生的指令,比如WFI/WFE、互斥访问、存储器隔离等指令,也必须用汇编显式给出。
在以前的ARM处理器中,因为支持ARM/Thumb双重状态,往往需要所谓的“interworking”,且不同的源文件可能需要编译成不同状态下的代码。在CM3中不再有此需求,因为只使用了Thumb状态,从而工程管理方便多了。
当使用C开发程序时,推荐开启CM3的双字对齐管理机制(在NVIC配置与控制寄存器中,把STKALIGN置位),这是用于确保系统能严格遵守AAPCS过程调用标准,代码形如:
#define NVIC_CCR ((volatile unsigned long *)(0xE000ED14))
*NVIC_CCR = *NVIC_CCR | 0x200; //设置STKALIGN位2、汇编与C的接口
在很多情况下,都需要让C程序模块与汇编程序模块互相交互,它们包括:
在C代码中使用了嵌入式汇编(或者是在GNU工具下,使用了内联汇编)
C程序呼叫了汇编程序,这些汇编程序是在独立的汇编源文件中实现的
汇编程序调用了C程序
在这些情况下,必须知晓参数是如何传递的,以及值是如何返回的,才能在主调函数与子程序之间协同工作。这些交互的机制在ARM中有明确的规定,由文档《ARM Architecture ProcedureCall Standard(AAPCS, Ref5)》给出。
不过,在大多数场合下的情况都比较简单:当主调函数需要传递参数(实参)时,它们使用R0-R3。其中R0传递第一个,R1传递第2个……在返回时,把返回值写到R0中。在子程序中,可以随心所欲地使用R0-R3,以及R12。但若使用R4-R11,则必须在使用之前先PUSH它们,使用后POP回来。
可见,汇编程序使用R0-R3, R12时会很舒服。但是如果换个立场——汇编要呼叫C函数,则考虑问题的方式就有所不同:必须意识到子程序可以随心所欲地改写R0-R3, R12,却决不会改变R4-R11。因此,如果在调用后还需要使用R0-R3,R12,则在调用之前,必须先PUSH,从C函数返回后再POP它们,对R4-R11则不用操心。
3、典型的开发流程
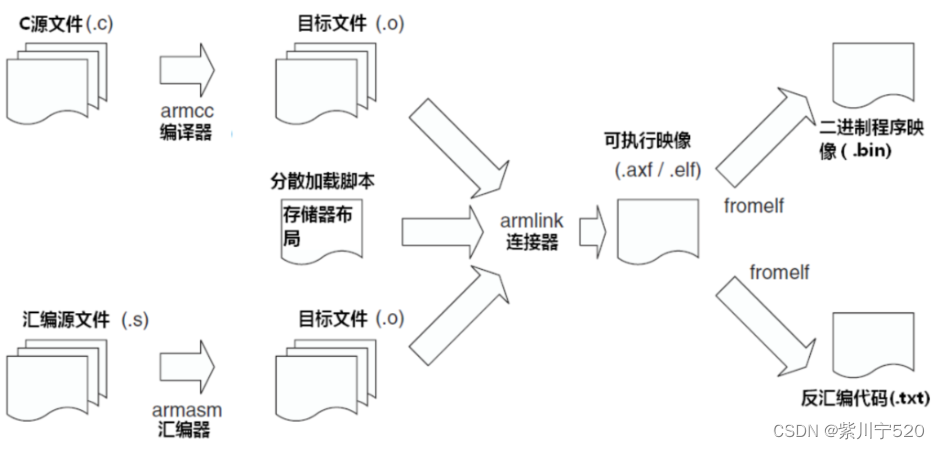
在开发基于CM3的应用程序时,常常有多种源程序和库,有些是自己写的,有些是别人已经写好的(尤其是底层的软件)。上述这些开发工具生成代码的流程都差不离。对于最基本的应用,也至少需要C编译器,连接器以及二进制文件处理工具。如果使用的是ARM的工具,如RVDS或RealView编译器工具(RVCT),则它们的流程如图所示。其中的“分散加载脚本”是可选的,但是当存储器映射变得比较复杂时,则需要它。
4、使用互斥访问实现信号量操作
专门用于信号量的操作中。最常见的用途,就是确保需要互斥使用的共享资源只被一个任务拥有。互斥锁本身的操作是原子访问的。
在单处理机系统中,互斥访问主要用在ISR与主程序之间,用以保护它们共享的,并且需要互斥访问的资源(如,一块内存,一个外设)。此时,引起互斥写失败的唯一原因,就是在读写期间曾响应过中断。如果代码在特权级下运行,还可以通过设置PRIMASK,在“测试——置位”期间暂时把中断给掐了。
在多处理机系统中,情况会变得更复杂。此时,除了本机的中断,其它处理机对同一块内存的访问也可以使互斥写操作失败。为了检测到其它处理机对内存的访问,总线系统中必须加入一个“互斥访问监视”的硬件基础设施。它负责检测在互斥读写期间,总线上是否有其它主机访问了互斥锁及其临近的“高危地带”。事实上,在绝大多数低成本的CM3单片机中,都只包含了一个核,因此无需此监视器。
有了这个机制,我们就可以确信共享资源一定能互斥地使用,不会发生紊乱危象。如果一个共享资源在多次尝试时依然无法获取,则可能必须放弃对此资源的请求,有可能先前锁住该资源的任务已经崩溃了。
5、使用位带实现互斥锁操作
如果存储器系统支持“锁定传送”(locked transfers),或者总线上只有一个主机,还可以使用CM3的位带功能来实现互斥锁的操作。通过使用位带,则可以在C程序中实现互斥锁,但是操作过程与互斥访问是不同的。在使用位带来做资源分配的控制机制时,需要使用位带存储区的内存单元(比如,一个字),该内存单元的每个位表示资源正被特定的任务使用。
在位带别名区的读写实质上是锁定的“读-改-写”(在传送期间总线不能被其它主机占有)。因此,只要每个任务都仅修改分配给它们自己的锁定位,其它任务锁定位的值就不会丢失,即使是两个任务同时写自己的锁定位也不怕。
对于“测试并设置”这种互斥锁的简单操作,也可以使用“关中临界区”来保护——也就是在操作前关中断,操作后开中断。这种关中的时间是很短的,因为其它原因导致的关中通常都比这个长得多。只是有时为了无限追求实时性,有一丝希望也会尽最大的努力,就像这两种互斥锁操作那样。
6、使用位段提取与查表跳转
位段提取指令(UBFX)和查表跳转指令(TBB/TBH)。这两条指令可以配合工作,以构建一个非常强大的“跳转树”。这对于电表及数据通信应用程序非常有意义,常使这类程序得到戏剧般地优化。这类程序在工作时,经常要判断各种各样的情况,并且“分类讨论”。有时,还需要进一步细化,作二级甚至多级的比较判断。