根据jar名称动态打包带版本的镜像以及容器
利用shell脚本, 实现根据jar名称中的项目名和版本号来动态制作带版本的Docker镜像以及带版本的容器
背景
人人都逃不过的墨菲定律
事情的原因来自最近发生的一次生产环境事故: 我们在甲方那里环境中有两个服务器, 一个用于灰度测试另一个用于盛传. 我负责的某项目在完成缺陷修复并测试通过后, 产品便提交生产环境发版流程. 流程走到我这里时, 我找到流程中负责现场发版的运维要求发版, 而他也发了版, 并且把脚本启动的成功截图给我了, 但是截图中没有当前服务器的ip, 这就为后来问题的暴露埋下伏笔…
在 ‘新版本’ 运行约一周之后, 实施反映之前修复的bug又复现了. 于是让运维下载下日志给我, 结果发现当前业务并没有走新版本修复后的逻辑, 并且未显示新版本追加的日志信息. 因此我推测包没有发上, 于是让运维比对下docker容器创建时间和jar包上传时间发现, 真的没有发上去. 于是我查了之前的聊天记录, 恰好发现之前运维截的图没有截到服务器的ip地址. 正如墨菲定律说的那样: 凡是可能出错的事情就一定出错.
事件反思
事后通过和运维和其他同事沟通了解到: 其实在工作中, 运维每天的量也很大. 即使之前帮过你发过包, 由于时间和个人的原因, 仍会导致再次发包时会忘记一些环境配置的情况. 而我这边也存在问题, 在发布后没有仔细确认…
基于以上反思, 我决定:
- 在每次需要运维协助发包前, 整理好发包文档, 让其严格按照文档来发包
- 优化原有启动脚本, 根据jar名称动态打包带版本的镜像,
让运维那边也可以看到新版本jar是否发送成功
辛路历程
整个脚本制作过程结合了ChatGPT使用, 中间过程有些曲折且漫长,
因此特地花点时间复盘一下, 希望能够带给自己和大家一些启发.
如果想要直接看最终脚本请直接跳转至最终脚本部分即可
前提准备
在idea开启远程调试这一章节, 我就分享过docker打包jar包环境的脚本.
这个脚本的核心是利用DockerFIle, 将jar制作成镜像, 然后利用启动脚本将镜像生成容器并启动.
但因为之前分享的jar都是0.0.1版本(图1), 因此无论是镜像的tag(图2), 还是启动时容器中的镜像信息(图3)都是0.0.1.
那么如何动态的将jar包中的版本信息动态的打入镜像的tag和容器名称中呢?
图1
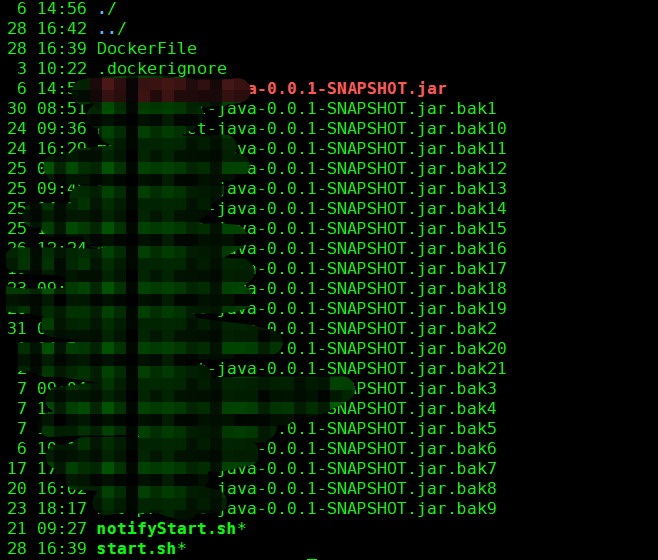
图2

图3

再次将该脚本再一次分享与大家
# 1.DockerFIle
FROM java:8
COPY 待启动jar-0.0.1-SNAPSHOT.jar 待启动jar-0.0.1-SNAPSHOT.jar
EXPOSE 项目对外端口
ENTRYPOINT ["java","-Duser.timezone=GMT+8","-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=远程调试端口","-jar","待启动jar-0.0.1-SNAPSHOT.jar"]
# 2.start.sh
sudo docker build --no-cache -f DockerFile -t 待启动jar:0.0.1 .;
sudo docker stop 待启动jar;
sudo docker rm 待启动jar;
sudo docker run -d --restart=always --name 待启动jar \
-p 项目对外端口:项目对外端口 -p 远程调试端口:远程调试端口 \
-v /home:/home \
-v /home/待启动jar/logs:/logs \
待启动jar:0.0.1 --spring.profiles.active=sit
1. 脚本启动顺序
在这里需要梳理下脚本的启动顺序, 这对我们后面问问题有所帮助, 正确的顺序为
->运行脚本start.sh
->通过DockerFIle制作新版本镜像
->停止并删除原来镜像对应的容器
->根据新的镜像创建容器
->执行根据DockerFIle中ENTRYPOINT关键字添加的, 启动容器所需执行的命令
2. 前置知识
本文的编写用到了大量的DockerFIle的关键字和shell脚本的基础知识.
如果后续阅读遇到了困难可以点击这里的链接, 来简单了解下(或者通过ChatGPT来简单了解下)
PS: 如果不理解上面的脚本是干什么的, 可以直接让ChatGPT为你翻译
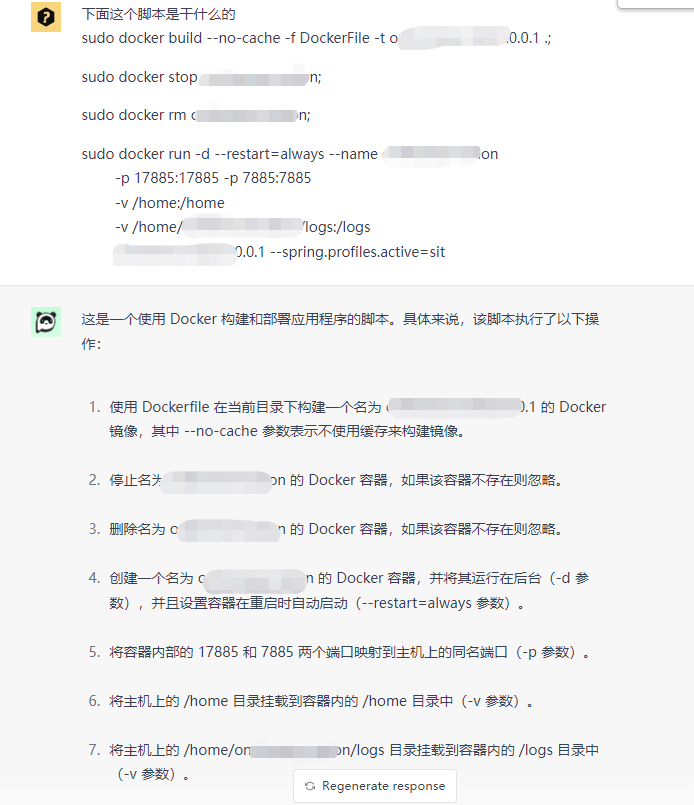
一股脑提问法
-
在一开始, 我便选择最"简单粗暴的方式", 直接提问

-
可以看到, 给出DockerFIle文件看起来还是没有问题的, 但是继续往下看
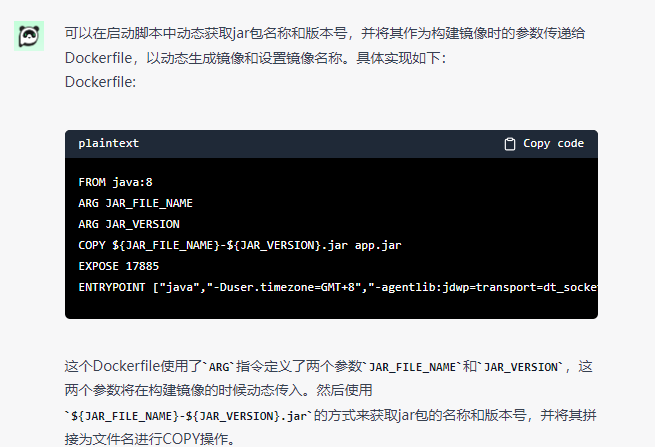
-
可以看到启动脚本这里就有问题了, 我想要的是根据jar名称动态获取项目名称和版本号
但这里提供的脚本是在一开始就写死的, 也就是说GPT并没有正确理会我这个动态读取的意思,
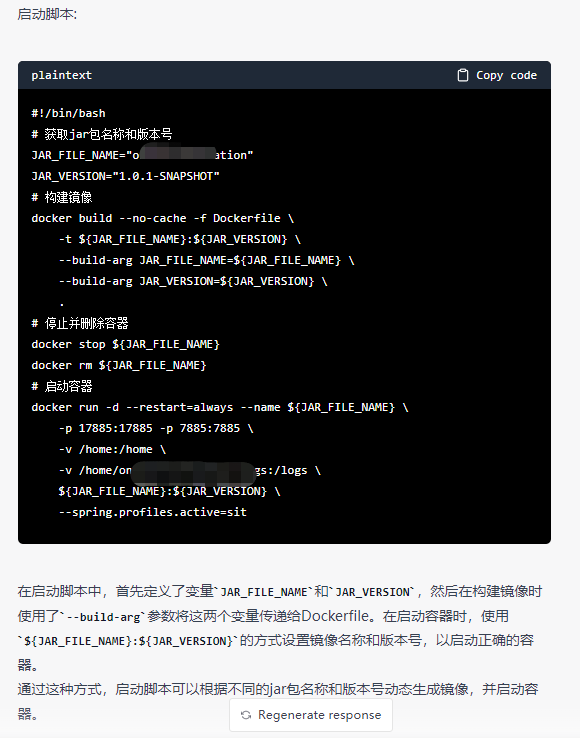
-
并且, 我即使使用上面的方式, 运行ChatGPT提供给我的DockerFIle和启动脚本,
发现还是未成功. 原因是启动脚本中的参数的值虽然被--build-arg传入到DockerFIle,
但是在ENTRYPOINT中在替换jar名称后依然执行报错,
并且DockerFIle中通过arg定义的参数, 在ENTRYPOINT通过${}获取不到,
我尝试用CMD来执行该参数, 但是这种方式下仍然失败.
因此, 发现在整体上一点点调试, 不如重头在细节上一点点攻破.
所以我调整了提问策略: 由整体提问, 改为分步骤提问
分步骤提问法
在规划步骤时, 核心就是动态获取jar包版本号和jar名称,
因此在一开始时, 我把主要步骤分为3步:动态读取jar包名称中的信息->动态打包镜像->动态创建并运行容器
在后续的思考中, 我又添加了: 获取服务器ip-> 删除原有容器, 镜像 这两步.
如果时间有限的同学, 想直接获取最终脚本, 可以跳转至"最终脚本"这一部分.
下面就开始介绍如何分步提问, 来让ChatGP解决问题
1. 动态读取jar包名称中的信息
根据上面前提准备-脚本启动顺序那部分我们归纳得到启动顺序, 我决定先对启动文件start.sh进行改造,
将动态获取jar名称和版本好的问题交给ChatGPT, 可以看到很快就得到了一个方案
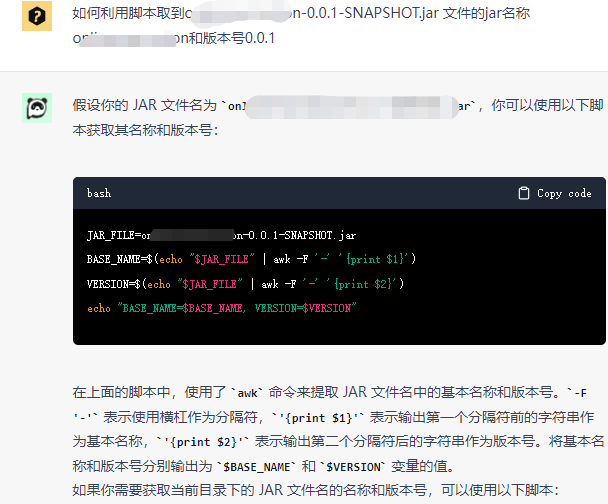
通过阅读上面脚本发现, 提供脚本还是存在瑕疵, 因为jar包名称JAR_FILE还是在脚本里面写死的,
而不是动态获取的, 可以看出来当前ChatGPT并没有理解我的需求.
因此我们需要将问题继续抛给ChatGPT
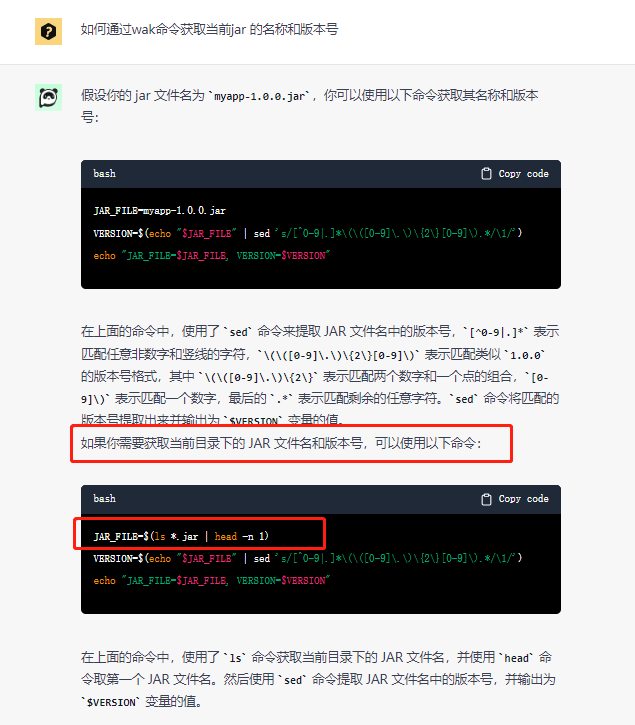
可以看到之前的问题已经得以解决
至此, 整个脚本最核心的三行脚本已经获取完毕
# 获取当前jar全称
JAR_FILE=$(ls *.jar | head -n 1)
# 获取当前jar实际名称(通过-分隔的第1列信息, 这里后续需要根据自己jar的格式进行调整)
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}')
# 获取当前jar的版本号(通过-分隔的第2列信息, 这里后续需要根据自己jar的格式进行调整)
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}')
2. 动态创建并运行容器
根据上一步的结果, 我们便可以改造启动脚本:
# start.sh
JAR_FILE=$(ls *.jar | head -n 1)
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}')
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}')
sudo docker build --no-cache -f DockerFile -t ${BASE_NAME}:${VERSION} .;
sudo docker stop ${BASE_NAME};
sudo docker rm ${BASE_NAME};
sudo docker run -d --restart=always --name ${BASE_NAME} \
-p 项目对外端口:项目对外端口 -p 远程调试端口:远程调试端口 \
-v /home:/home \
-v /home/${BASE_NAME}/logs:/logs \
${BASE_NAME}:${VERSION} --spring.profiles.active=sit
启动脚本修改完毕了, 那么DockerFIle如何通过jar的名称, 动态获取项目名称和版本号呢?
3. 动态打包镜像
我这里尝试着在DockerFIle通过RUN关键字执行shell指令, 然后将参数通过export输出,
需要注意的是: COPY *.jar /是将当前根目录下的jar复制到镜像容器的根目录
FROM java:8
COPY *.jar /
RUN JAR_FILE=$(ls *.jar | head -n 1) && \
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}') && \
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}') && \
echo "BASE_NAME=$BASE_NAME, VERSION=$VERSION" && \
export BASE_NAME=$BASE_NAME && \
export VERSION=$VERSION
EXPOSE 17885
ENTRYPOINT ["java","-Duser.timezone=GMT+8","-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=7885","-jar","${BASE_NAME}:${VERSION}"]
然后在ENTRYPOINT中填充再运行, 结果仍然执行失败, 被
原因是填充的参数${BASE_NAME},${VERSION}仍无法获取到. 我这里采取了很多方法仍无法解决,
可能是由于我提问方式的原因, 多次询问ChatGPT无果, 之后我便决定改用搜索引擎,
然后就看到了这个大佬的博客: Dockerfile中通过ENV指定动态参数在RUN时传递参数(部署后台jar包时指定端口为例), 文章核心是利用docker run -e 将参数在创建容器时传入到DockerFIle中, 通过ENV关键字定义的变量来接收
然后利CMD定义容器启动时的执行命令,然后通过${}来获取ENV定义的参数
至此, 两个脚本文件start.sh和DockerFIle文件就改造完毕
# start.sh
JAR_FILE=$(ls *.jar | head -n 1)
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}')
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}')
sudo docker build --no-cache -f DockerFile -t ${BASE_NAME}:${VERSION} .;
sudo docker stop ${BASE_NAME};
sudo docker rm ${BASE_NAME};
sudo docker run -d --restart=always --name ${BASE_NAME} \
-p 项目对外端口:项目对外端口 -p 远程调试端口:远程调试端口 \
-e JAR_NAME=${JAR_FILE} \
-v /home:/home \
-v /home/${BASE_NAME}/logs:/logs \
${BASE_NAME}:${VERSION} --spring.profiles.active=sit
# DockerFIle
FROM java:8
COPY *.jar /
ENV JAR_NAME=${JAR_NAME}
EXPOSE 17885
CMD java -Duser.timezone=GMT+8 -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=7885 -jar ${JAR_NAME} --spring.profiles.active=sit
4. 获取服务器ip
其实步骤3已经实现了主要功能. 但仅仅是根据jar名称动态打包带版本的镜像, 并创建了对应容器
启动成功后, 通过docker ps和docker images也确实可以动态获取带版本的jar的消息.
但如果恰好两台不同的服务器都部署了该项目, 那么即使启动信息显示正常, 但由于无法判断是在哪个服务器上启动的
也会影响你对项目是否在指定的环境启动成功的判断 . 因此, 我决定在脚本上追加获取当前服务器内网ip的功能
(主要是因为生产服务器部署在内网, 如果项目部署在外网, 可以选择获取外网地址).
老样子, 先问ChatGPT
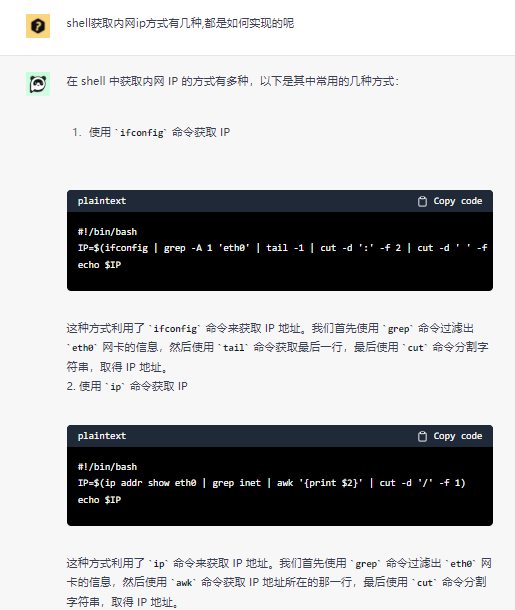
在使用提供的前两种方式, 发现结果输出为null ,
究其原因, 是因为在本机电脑上未配置eth0的网卡信息, 直到运行第3种方式才得以解决
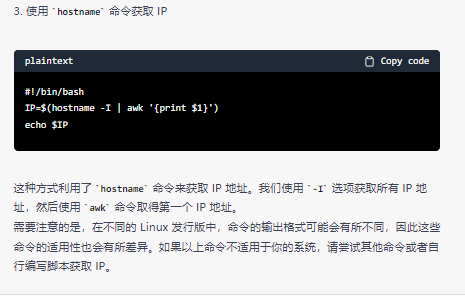
第3种方式命令执行情况

因此, 我这里便对启动脚本再次进行修改
# start.sh
JAR_FILE=$(ls *.jar | head -n 1)
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}')
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}')
sudo docker build --no-cache -f DockerFile -t ${BASE_NAME}:${VERSION} .;
sudo docker stop ${BASE_NAME};
sudo docker rm ${BASE_NAME};
sudo docker run -d --restart=always --name ${BASE_NAME} \
-p 项目对外端口:项目对外端口 -p 远程调试端口:远程调试端口 \
-e JAR_NAME=${JAR_FILE} \
-v /home:/home \
-v /home/${BASE_NAME}/logs:/logs \
${BASE_NAME}:${VERSION} --spring.profiles.active=sit
IP=$(hostname -I | awk '{print $1}')
echo "在 $IP 服务器上执创建镜像并启动容器完成, 请使用 docker ps 查看启动情况"
5. 删除原有容器, 镜像
一般的镜像删除都是根据镜像id来删除镜像, 但是每次运行DockerFIle新建镜像时, 镜像id都会重新生成,
那每次重新启动脚本时, 如何通过获取上一个镜像的镜像id来删除上个镜像就成了一个棘手的问题
这时, 翻看自己之前的docker文章->第三章 常用命令->镜像命令中, 还有一种镜像的删除方式,
就是通过docker images image_name来获取指定镜像信息(需要将之前创建的同名但未删除的镜像删除),
然后利用awk 'NR==2{print $3}获取镜像id, 结合docker rmi来删除之前的命令.
最后根据镜像名称删除镜像命令就变成了docker rmi $( docker images image_name | awk 'NR==2{print $3}
结合docker容器和镜像的删除顺序: 停止容器->删除容器->删除镜像 , 此脚本修改后如下
# start.sh
JAR_FILE=$(ls *.jar | head -n 1)
BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}')
VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}')
IMAGE_ID=$(docker images "${BASE_NAME}" | awk 'NR==2{print $3}' )
sudo docker build --no-cache -f DockerFile -t ${BASE_NAME}:${VERSION} .;
sudo docker stop ${BASE_NAME};
sudo docker rm ${BASE_NAME};
docker rmi ${IMAGE_ID}
docker rmi $( docker images image_name | awk 'NR==2{print $3}'
sudo docker run -d --restart=always --name ${BASE_NAME} \
-p 项目对外端口:项目对外端口 -p 远程调试端口:远程调试端口 \
-e JAR_NAME=${JAR_FILE} \
-v /home:/home \
-v /home/${BASE_NAME}/logs:/logs \
${BASE_NAME}:${VERSION} --spring.profiles.active=sit
IP=$(hostname -I | awk '{print $1}')
echo "在 $IP 服务器上执创建镜像并启动容器完成, 请使用 docker ps 查看启动情况"
最终脚本
在脚本中输出的关键信息进行打印以及维护后, 最终脚本终于出炉啦!
下面, 我们就来揭开他神秘的面纱:
-
启动脚本start.sh
需要注意的是, 当前目录只能有一个.jar结尾的jar,
如果想要留存历史版本的jar需要在后面额外增加一个后缀, 例如.bak123…, 如下图1#!/bin/bash JAR_FILE=$(ls *.jar | head -n 1) BASE_NAME=$(echo "$JAR_FILE" | awk -F '-' '{print $1}') VERSION=$(echo "$JAR_FILE" | awk -F '-' '{print $2}') IMAGE_ID=$(docker images "${BASE_NAME}" | awk 'NR==2{print $3}' ) sudo docker stop ${BASE_NAME}; sudo docker rm ${BASE_NAME}; docker rmi ${IMAGE_ID}; echo "删除镜像名为:${BASE_NAME},镜像id为: ${IMAGE_ID}"; sudo docker build --no-cache -f DockerFile -t ${BASE_NAME}:${VERSION} .; echo "创建并启动 $BASE_NAME 容器, 容器启动依赖的jar名称: $JAR_FILE, jar版本: $VERSION"; sudo docker run -d --restart=always --name ${BASE_NAME} \ -p 17885:17885 -p 7885:7885 \ -e JAR_NAME=${JAR_FILE} \ -v /home:/home \ -v /home/${BASE_NAME}/logs:/logs \ ${BASE_NAME}:${VERSION} ip=`ifconfig -a|grep inet|grep -v 127.0.0.1 |grep -v inet6| grep -v 172.* | awk '{print $2}'|tr -d "addr:" | head -1` echo "在 $ip 服务器上执创建镜像并启动容器完成, 请使用 docker ps 查看启动情况" -
DockerFIle文件
FROM java:8 MAINTAINER "时间静止不是简史" LABEL description="开始生成xx项目镜像文件" WORKDIR app COPY *.jar /app ENV JAR_NAME=${JAR_NAME} EXPOSE 项目对外端口 CMD java -Duser.timezone=GMT+8 -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=远程调试端口 -jar ${JAR_NAME} --spring.profiles.active=项目启动环境
反思
受限于博主技术水平以及向ChatGPT提问方式的原因, 大概花费了近1天的时间在将整个脚本调试完毕.
ChatGPT 3.5 依旧如我预想的一样只能作为工具(ChatGPT 4可能会在一定程度上解决问题但仍不可能完全解决),
由于其不能完全理解我们的想法(虽然沟通占一部分原因, 但更主要原因是可能是的训练参数量)
加上无法对其代码的正确性进行验证, 以及所存储的知识具有时间局限性等等原因,
在当下不可能完全替代人类去写代码…
但是作为工具来说, 在细节的处理上, ChatGPT要比搜索引擎优秀得多. 因此在遇到工程问题时,
如果想从大方向上找解决方案, 可以选择搜索引擎. 例如本篇文章的标题这种解决方案
如果自己有能力将该工程问题分解为具体的技术细节, 可以将具体的细节交由ChatGPT实现, 然后再人工进行组装和优化.
这便是我通过这次脚本编写过程复盘, 所得到的收获.
越使用它, 越了解它, 便越不惧怕它. 与其惧怕技术会取代人类, 不如主动去拥抱和学习技术.
不知道大家对ChatGPT的看法又是如何呢?







![[进阶]Java:线程安全问题、取钱模拟](https://img-blog.csdnimg.cn/81584d4bbf0c4691bf3cc76037ad811d.png)