CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Realistic Saliency Guided Image Enhancement

标题:现实显着性引导图像增强
作者:S. Mahdi H. Miangoleh, Zoya Bylinskii, Eric Kee, Eli Shechtman, Yağız Aksoy
文章链接:https://arxiv.org/abs/2306.06092
项目代码:http://yaksoy.github.io/realisticEditing/




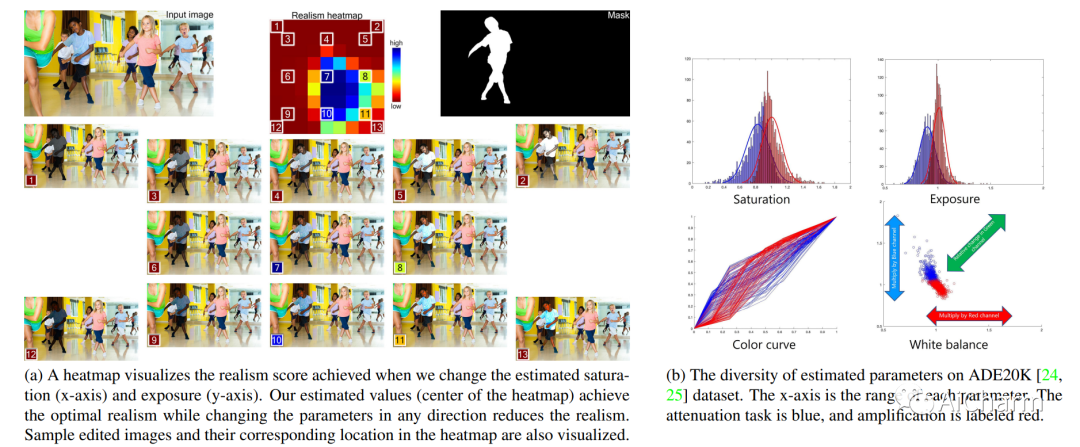
摘要:
专业摄影师执行的常见编辑操作包括清理操作:弱化分散注意力的元素并增强主题。这些编辑具有挑战性,需要在控制观众注意力和保持照片真实感之间取得微妙的平衡。虽然最近的方法可以吹嘘注意力衰减或放大的成功例子,但其中大多数也经常遭受不切实际的编辑。我们提出了显着性引导图像增强的真实感损失,以在不同图像类型中保持高度真实感,同时减弱干扰因素并放大感兴趣的对象。与专业摄影师的评估证实,我们实现了真实性和有效性的双重目标,并且在他们自己的数据集上优于最近的方法,同时需要更小的内存占用和运行时间。因此,我们为自动化图像增强和照片清理操作提供了一个可行的解决方案。
2.Multi-Modal Classifiers for Open-Vocabulary Object Detection(ICML 2023)

标题:用于开放词汇对象检测的多模态分类器
作者:Prannay Kaul, Weidi Xie, Andrew Zisserman
文章链接:https://arxiv.org/abs/2306.05493
项目代码:https://www.robots.ox.ac.uk/vgg/research/mm-ovod/
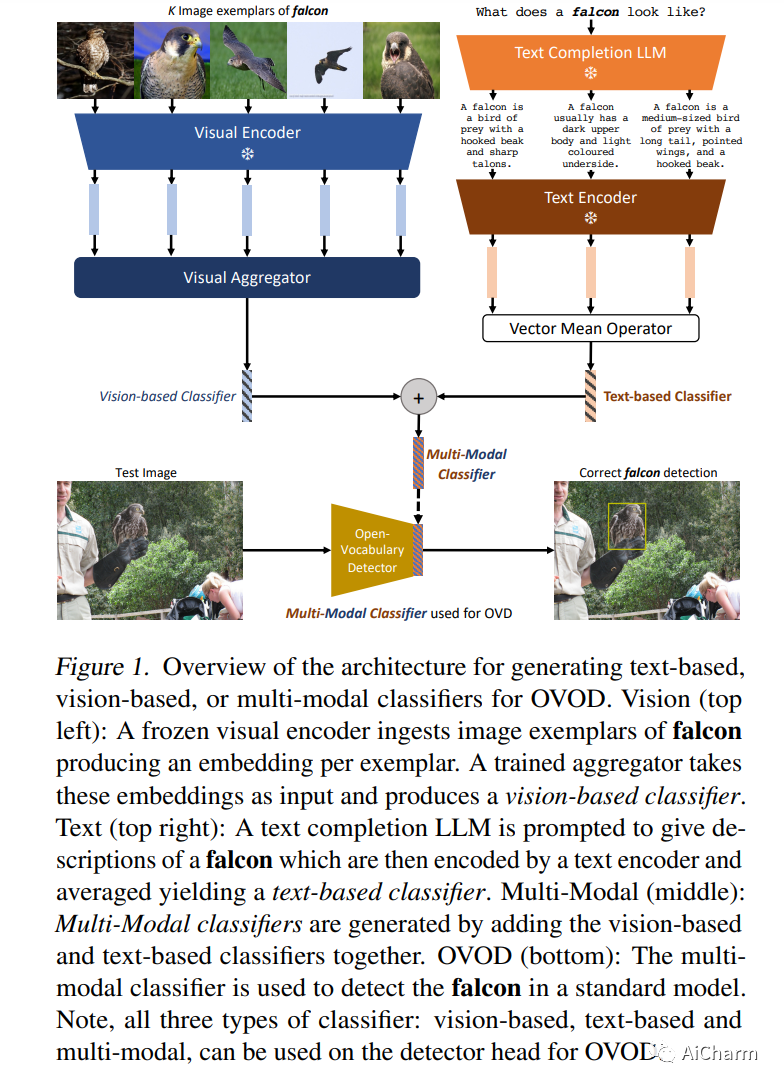
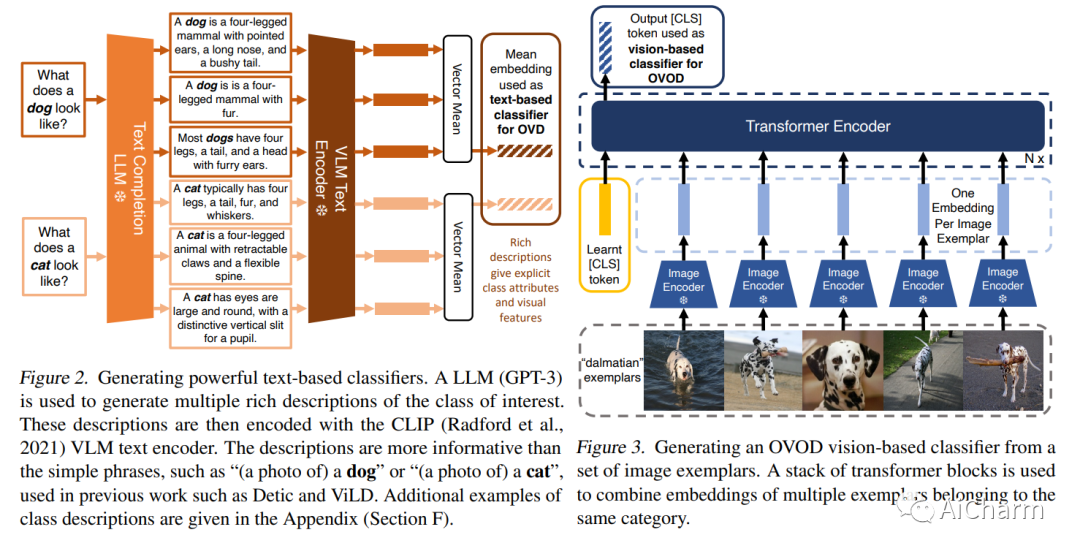

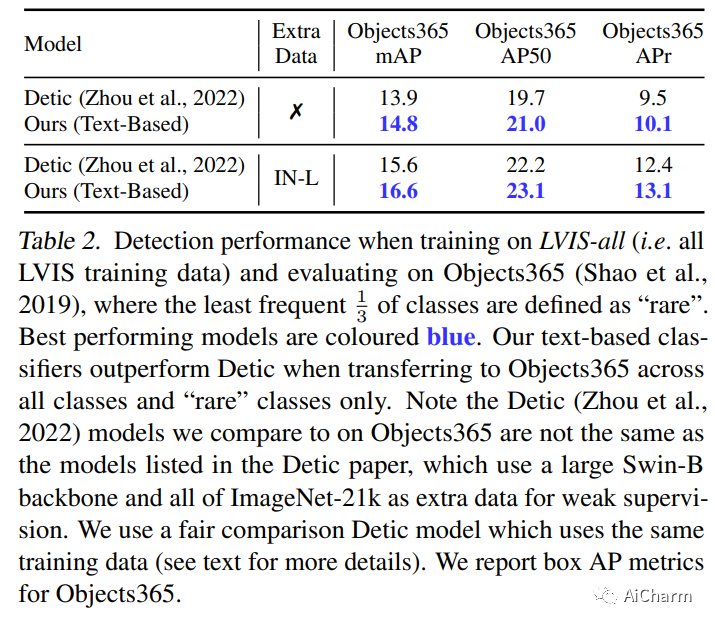

摘要:
本文的目标是开放词汇对象检测(OVOD) – 建立一个模型,该模型可以检测超出训练中所见类别集的对象,从而使用户能够在推理时指定感兴趣的类别,而无需重新训练模型.我们采用标准的两阶段对象检测器架构,并探索三种指定新类别的方法:通过语言描述、通过图像示例或通过两者的组合。我们做出了三个贡献:首先,我们提示大型语言模型(LLM)为对象类生成信息丰富的语言描述,并构建强大的基于文本的分类器;其次,我们在图像范例上使用视觉聚合器,可以摄取任意数量的图像作为输入,形成基于视觉的分类器;第三,我们提供了一种简单的方法来融合来自语言描述和图像样本的信息,从而产生多模态分类器。在评估具有挑战性的 LVIS 开放词汇基准时,我们证明:(i) 我们基于文本的分类器优于所有以前的 OVOD 作品;(ii) 我们基于视觉的分类器在之前的工作中表现与基于文本的分类器一样好;(iii) 使用多模式分类器比单独使用任何一种模式表现更好;最后,(iv) 我们的基于文本的多模式分类器比完全监督的检测器产生更好的性能。
3.GANeRF: Leveraging Discriminators to Optimize Neural Radiance Fields

标题:GANeRF:利用鉴别器优化神经辐射场
作者:Barbara Roessle, Norman Müller, Lorenzo Porzi, Samuel Rota Bulò, Peter Kontschieder, Matthias Nießner
文章链接:https://arxiv.org/abs/2306.06044
项目代码:https://www.youtube.com/watch?v=EUWW8nUxpl0&feature=youtu.be

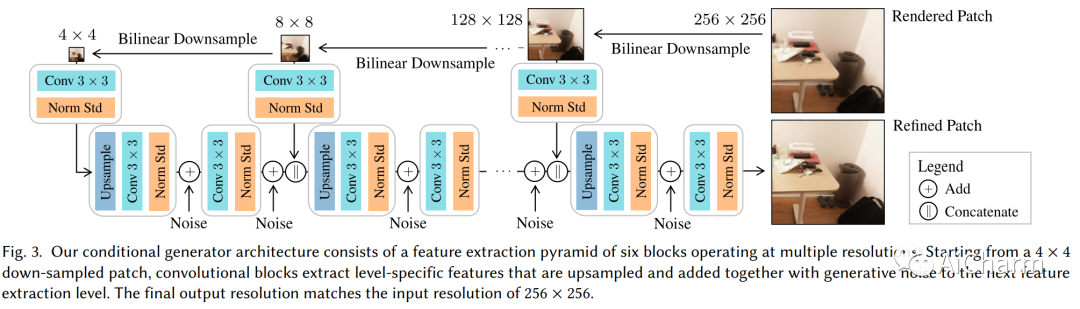
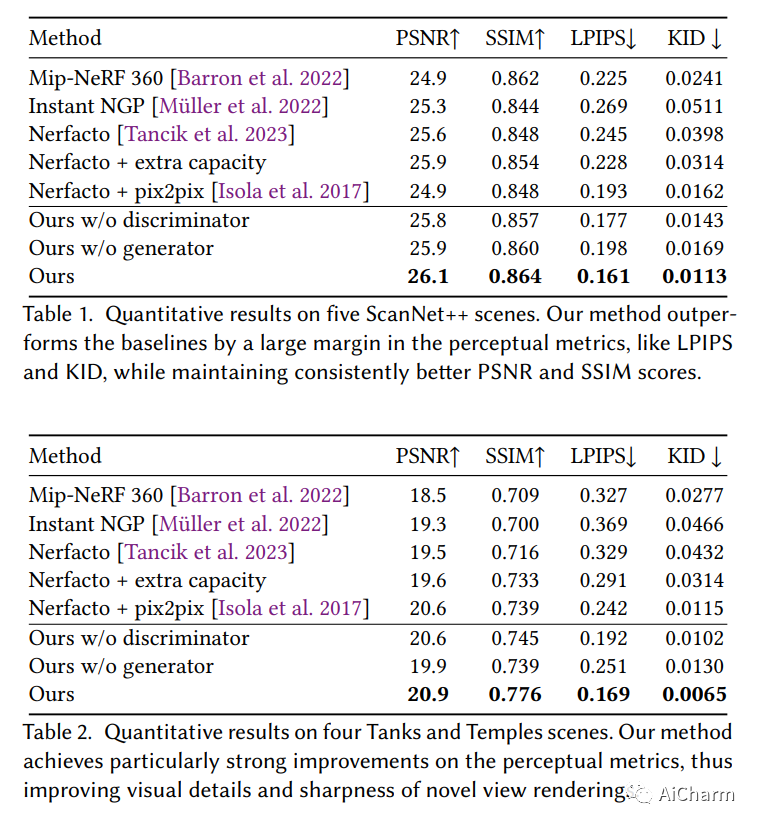
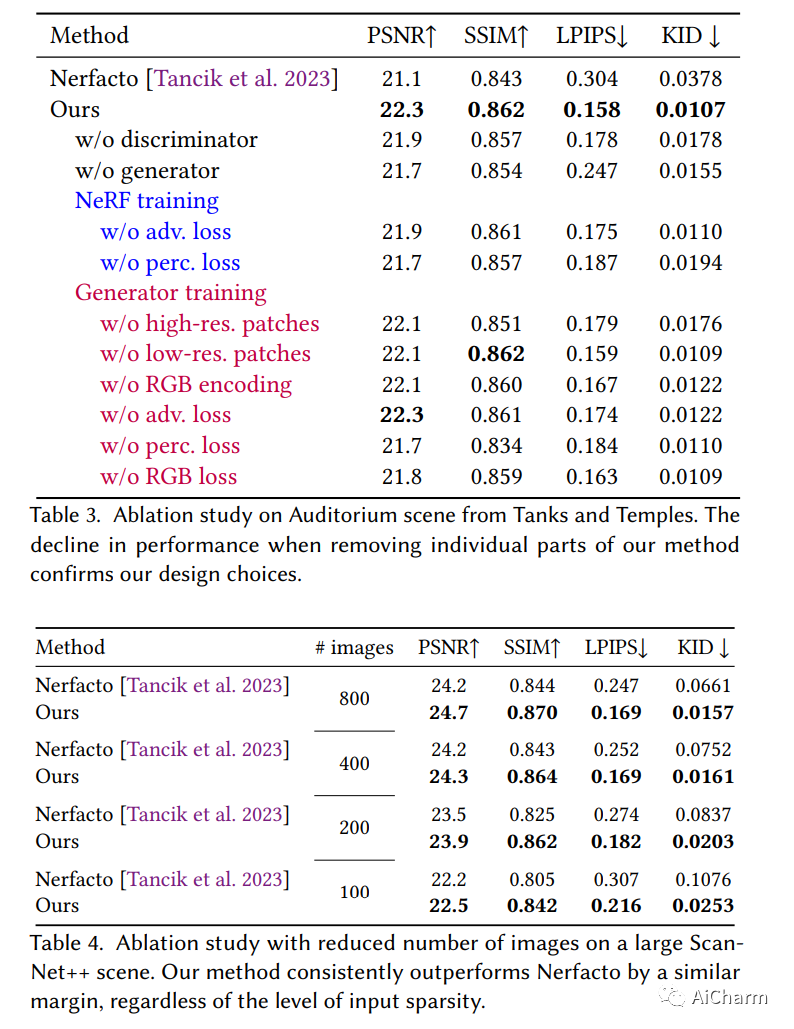
摘要:
神经辐射场 (NeRF) 已经显示出令人印象深刻的新颖视图合成结果;尽管如此,即使是彻底的记录也会在重建中产生缺陷,例如由于观察不佳的区域或轻微的照明变化。我们的目标是通过联合解决方案减轻来自各种来源的这些缺陷:我们利用生成对抗网络 (GAN) 的能力来生成逼真的图像,并使用它们来增强 NeRF 3D 场景重建的真实感。为此,我们使用对抗性鉴别器学习场景的补丁分布,该鉴别器为辐射场重建提供反馈,从而以 3D 一致的方式提高真实感。因此,通过施加多视图路径渲染约束,直接在底层 3D 表示中修复渲染伪像。此外,我们使用多分辨率 NeRF 渲染调节生成器,该生成器经过对抗训练以进一步提高渲染质量。我们证明我们的方法显着提高了渲染质量,例如,与 Nerfacto 相比,LPIPS 分数几乎减半,同时在 Tanks 和 Temples 的高级室内场景中将 PSNR 提高了 1.4dB。
更多Ai资讯:公主号AiCharm