前言:
语言模型(LM)起源于语音识别(speech recognition),输入一段音频数据,语音识别系统通常会生成多个句子作为候选,究竟哪个句子更合理?就需要用到语言模型对候选句子进行排序。
language models 应用场景如下:
| LM 应用场景 |
| Suggestions in messengers |
| Spelling correction |
| Machine translation |
| Speech recognition |
| Handwriting recognition |
LM模型输入的是语音,文字
这个时候就需要对输入的语音,文字进行编码,方便模型处理
这里面介绍最简单的两种one-hot, 以及N-gram
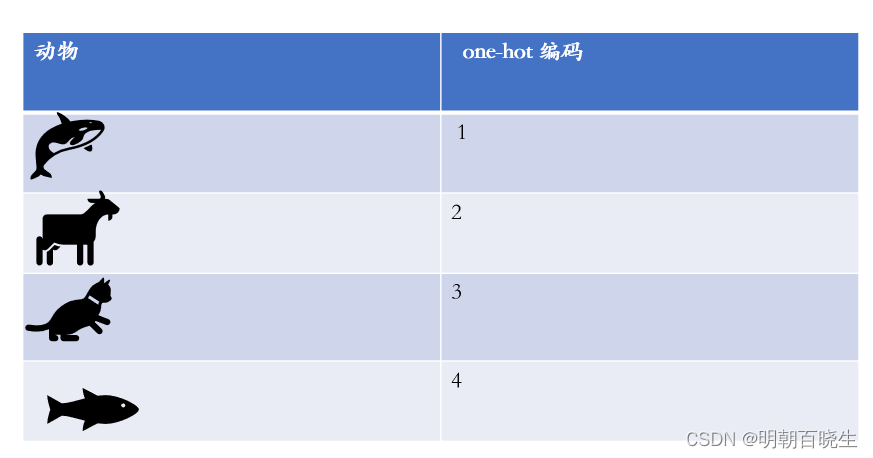
一 one-hot 编码
把语料中的词汇去重取出,按照一定的顺序(字典序、出现顺序等)排列为词汇表,则每一个单词都可以表示为一个长度为N的向量,N为词汇表长度,即单词总数。该向量中,除了该词所在的分量为1,其余均置为0
如下五个单词,N=5,则one-hot 编码如下:
| 单词 | 编码 |
| Hello | 10000 |
| Moto | 01000 |
| Are | 00100 |
| You | 00010 |
| ready | 00001 |
one-hot局限性:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
- 语义的相似性,“woman”、“madam”、“lady”从语义上将可能是相近的,one-hot无法表示
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 19 14:16:03 2023
@author: chengxf2
"""
import torch
word_index = {"hello":1,"moto":2,"are":3,"you":4, "ready":5}
one_hot = torch.tensor(word_index["you"],dtype=torch.long)
print("\n one_hot",one_hot)二 整数编码
但是在NLP 里面,整数编码的缺点如下:
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
代码实现
用词典直接实现
三 n-gram(toy corpus)
2.1 简介
假设S 是一个句子,由 n个单词组成,
的概率模型就是语言模型,其中为单词(house,rat,malt,rat,did)
例
如下 p(this is the house)?
| 当前输入 | 下一个单词 |
| This is the …. | house |
| Rat | |
| Malt | |
| Rat | |
| did |
通过链式法则(条件贝叶斯原理)
上面公式,每个单词出现的概率率都是依赖它之前的所有单词出现过的概率来计算,这个计算量是指数级上涨的
马尔可夫简化了这个计算方法,提出其实某个时刻词出现的概率只和它之前的N个单词字有关,不用计算它之前的所有字,可以往前推导1-3个单词的概率即可,这样计算量不大而且效果并不算太差。
2.2 N-gram模型:
是一种基于马尔科夫链的统计语言模型。它假设一个词的出现只与前面N个词有关,即一个词的出现只与它前面N个词的出现概率相关。因此,N-gram模型被称为是一个N阶马尔科夫链模型。
在实际应用中,N一般取1、2、3等较小的值。
当N=2的时候
其中
当N=3的时候
其中:
里面要注意的是,这里面利用了大数定理,频率和概率的概念
实际上是有误差的,所以是约等于。
2.4 例子
| toy corpus(微信语料库) |
| The girl bought a chocolate |
| The boy ate the chocolate |
| The girl bought a toy |
| The girl played with a toy |
vocabulary
{the,girl,bought ,a chocolate, boy,ate ,the toy, played,with}
输入: the girl ...,
下面一个可能的单词是什么?
利用N-gram 模型,N=3
| 词组 | 数量 |
| The girl | 3 |
| The girl bought | 2 |
| P(bought |The girl) = count(the girl bought)/count(the girl)=2/3 | |
| 词组 | 数量 |
| The girl | 3 |
| The girl played | 1 |
| P(played |The girl) = count(the girl bought)/count(the girl)=1/3 | |

N-gram模型缺点:
数据稀疏性:由于自然语言具有复杂的结构和多样的表达方式,N-gram模型在处理稀疏数据时可能会出现问题。
上下文依赖性:N-gram模型只考虑当前词的前N-1个词作为上下文,无法捕捉长距离依赖关系,这可能会导致模型的准确性受到限制。
参数过多:对于大规模的文本数据,N-gram模型需要维护大量的参数,这可能会导致模型的计算复杂度和存储开销过大
三 代码
根据词频 CounterVectorizer 将单词, 句子, 文章变成向量
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 20 13:44:52 2023
@author: chengxf2
"""
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import numpy as np
def gram(N=2):
'''
ngram_range=(2, 2)表明适应2-gram,
decode_error="ignore"忽略异常字符,
token_pattern按照单词切割
'''
toy_corpus =["The girl bought a chocolate",
"The boy ate the chocolate",
"The girl bought a toy",
"The girl played with a toy"]
vectorizer = CountVectorizer(ngram_range=(N, N+1), decode_error="ignore",min_df=0)
x_trans = vectorizer .fit_transform(toy_corpus)
print("\n get_feature_names ",vectorizer .get_feature_names())
print("\n vocabulary 词典 ",vectorizer.vocabulary_)
print("\n 每个句子中 单词出现的次数 \n",x_trans)
print("\n 是将结果转化为稀疏矩阵矩阵的表示方式 \n ",x_trans.toarray())
print(np.shape(x_trans.toarray()))
print("\n toarray \n",x_trans.toarray()) #.toarray() 是将结果转化为稀疏矩阵矩阵的表示方式;
print("\n sum \n",x_trans.toarray().sum(axis=0)) #每个词在所有文档中的词频
return vectorizer.vocabulary_,x_trans.toarray().sum(axis=0)
if __name__:
vocabulary,count_array=gram(2)
input_word = 'the girl'
for key ,value in vocabulary.items():
if input_word in key:
idx = vocabulary[key]
count = count_array[idx]
print("\n key ",key,"\t count", count)最后我们可以看到
key the girl count 3
key the girl bought count 2
key the girl played count 1
可以得到 the girl bought 的概率最高位2/3
说明:
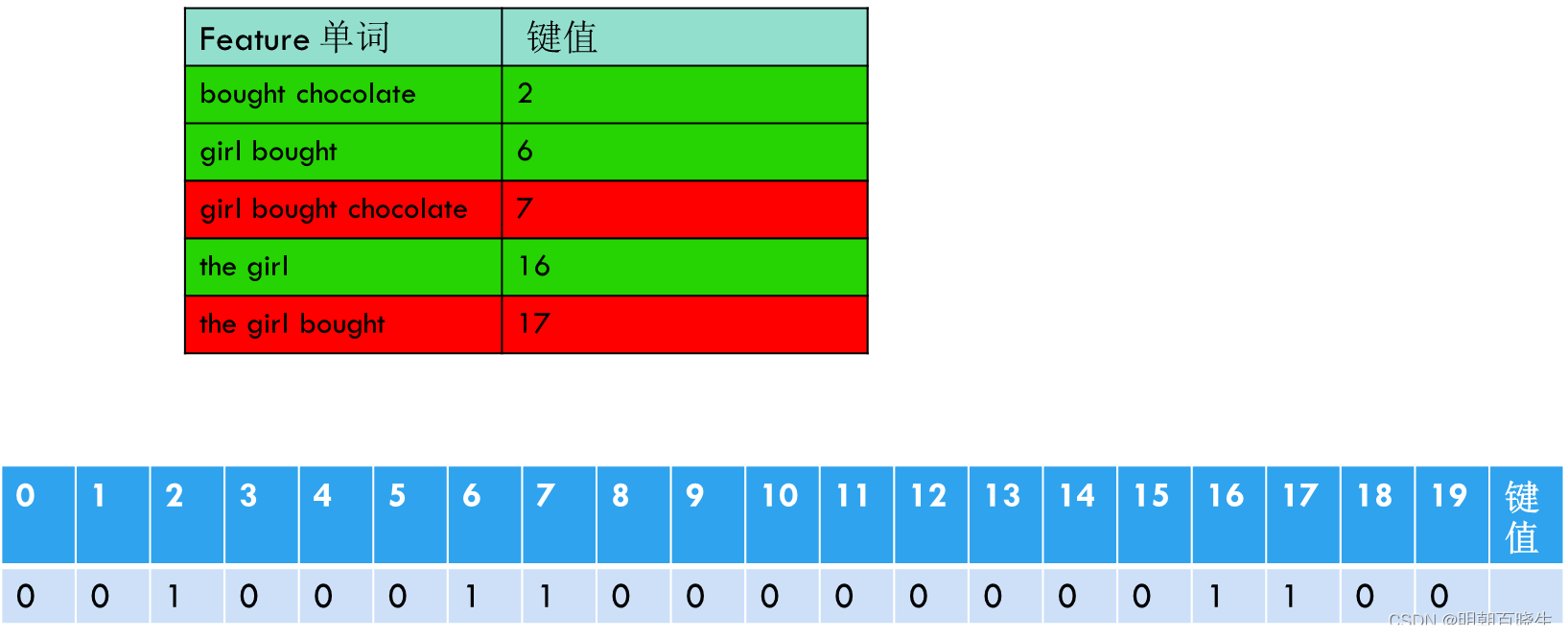
1 print("\n vocabulary 词典 ",vectorizer.vocabulary_)
根据ngram_range=(2, 3) ,统计每句中单词长度为2,3的词组,分配对应的键值
| Feature 单词 | 键值 |
| ate the | 0 |
| ate the chocolate | 1 |
| bought chocolate | 2 |
| bought toy | 3 |
| boy ate | 4 |
| boy ate the | 5 |
| girl bought | 6 |
| girl bought chocolate | 7 |
| girl bought toy | 8 |
| girl played | 9 |
| girl played with | 10 |
| played with | 11 |
| played with toy | 12 |
| the boy | 13 |
| the boy ate | 14 |
| the chocolate | 15 |
| the girl | 16 |
| the girl bought | 17 |
| the girl played | 18 |
| with toy | 19 |
2 print("\n 每个句子中 单词出现的次数 \n",x_trans)
每个句子中 单词出现的次数
(0, 16) 1
(0, 6) 1
(0, 2) 1
(0, 17) 1
(0, 7) 1
(1, 13) 1
(1, 4) 1
(1, 0) 1
(1, 15) 1
(1, 14) 1
(1, 5) 1
(1, 1) 1
(2, 16) 1
(2, 6) 1
(2, 17) 1
(2, 3) 1
(2, 8) 1
(3, 16) 1
(3, 9) 1
(3, 11) 1
(3, 19) 1
(3, 18) 1
(3, 10) 1
(3, 12) 1
这是一个tuple元组数据,第一个参数代表第几个句子,如下0 ,代表“The girl bought a chocolate”
16 代表上面vectorizer.vocabulary_ 里面的键值
(0, 16) 1
(0, 6) 1
(0, 2) 1
(0, 17) 1
(0, 7) 1
代表 “The girl bought a chocolate” 由下面的键值组成
| Feature 单词 | 键值 |
| bought chocolate | 2 |
| girl bought | 6 |
| girl bought chocolate | 7 |
| the girl | 16 |
| the girl bought | 17 |
3 print("\n 是将结果转化为稀疏矩阵矩阵的表示方式 \n ",x_trans.toarray())
是将结果转化为稀疏矩阵矩阵的表示方式
[[0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0]
[1 1 0 0 1 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0]
[0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 1 1 0 0]
[0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 1 0 1 1]]
[4,20]例的array
每一行代表一个句子,列对应索引为键值,位置为1,代表存在该feature
例如“The girl bought a chocolate” 第一个句子
[0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0]
参考:
CountVectorizer详解_zttbee的博客-CSDN博客
https://www.youtube.com/watch?v=GiyMGBuu45w
探索N-gram模型:语言模型中的基础算法_Chaos_Wang_的博客-CSDN博客
一文看懂 Word2vec(基本概念+2种训练模型+5个优缺点)
一文看懂词嵌入 word embedding(2种主流算法+与其他文本表示比较)
课时85 时间序列表示方法_哔哩哔哩_bilibili
Deep Learning in NLP (一)词向量和语言模型 – licstar的博客
word2vec 中的数学原理详解(一)目录和前言_皮果提的博客-CSDN博客
(全)Word Embedding_wordembedding_薛定谔的炼丹炉!的博客-CSDN博客