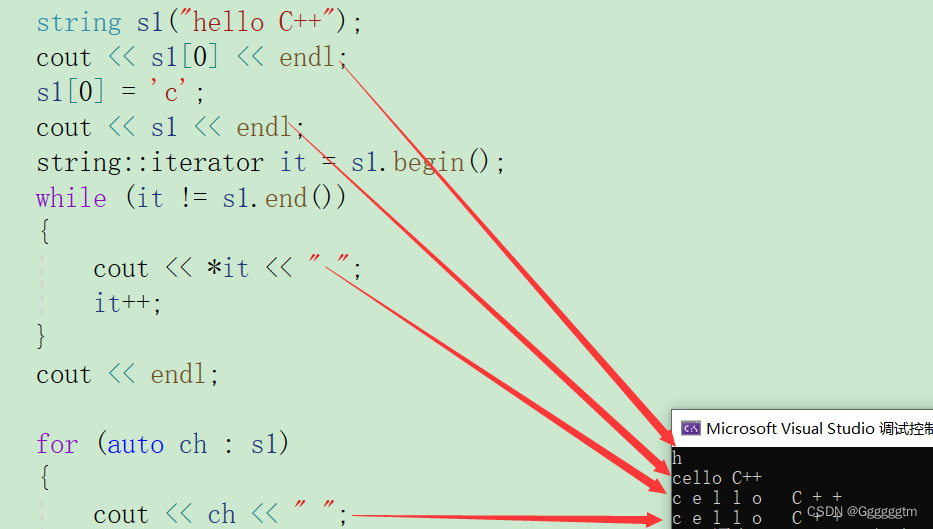
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目11-阅读理解项目的数据处理与训练详细讲解,阅读理解任务目标是让计算机从给定的文章中理解并回答问题。为了完成这个任务,我们需要对给定的数据进行处理和训练。该任务是一个涉及多个步骤和技术的复杂任务,需要在数据处理、模型设计和训练等方面进行多方面的努力,才能取得较好的结果。
目录
一、引言
A. 背景介绍
B. 研究意义
C. 本文内容概述
二、阅读理解项目
A. 定义与分类
B. 训练原理
C. 数据集介绍
三、数据样例标注
A. 数据集来源
B. 标注方法与工具
C. 标注样例展示
四、输入模型之前的数据变化
A. 特征提取方法
B. 数据预处理
C. 数据增强技术
D. 变化样例展示
五、模型架构与参数设置
A. 模型架构介绍
B. 参数设置
C. 模型训练过程
六、实验结果与分析
A. 实验环境介绍
B. 实验结果展示
C. 结果分析与讨论
七、应用与展望
A. 应用场景
B. 发展趋势
八、结论
A. 研究贡献
B. 局限性与展望
C. 总结

接下来,我将详细描述每个章节的内容。
一、引言
A. 背景介绍
自然语言处理(Natural Language Processing, NLP)是人工智能领域的重要研究方向之一。随着互联网的普及和移动互联网的快速发展,海量的文本数据给NLP带来了新的机遇和挑战。阅读理解是NLP领域中的一个重要分支,它旨在让计算机能够像人类一样理解自然语言,并从中获取相关信息。因此,阅读理解已经成为NLP领域的热门研究方向之一。
B. 研究意义
阅读理解是实现人机对话、智能问答等应用的关键技术之一。在工业界和学术界都有广泛的应用前景,比如智能客服、智能电子书、智能问答系统等。同时,阅读理解的研究也为我们更深入地理解人类阅读理解的过程提供了新的视角。
C. 本文内容概述
本文将主要介绍阅读理解中的训练原理,数据样例是怎么标注的,数据输入模型之前是如何变化的,给出变化样例,输出结果。同时,本文还将介绍相关的技术和方法,包括特征提取、数据预处理、数据增强等。最后,本文将展示实验结果并进行分析。
二、阅读理解项目
A. 定义与分类
阅读理解是指根据文本的内容,回答与之相关的问题。它是一种自然语言理解任务,也是NLP领域中的重要研究方向之一。从任务类型上来看,阅读理解可以分为单项选择题型、多项选择题型、填空题型和自由回答题型等。从数据形式上来看,阅读理解可以分为机器阅读理解(Machine Reading Comprehension, MRC)、阅读理解理解与推理(Reading Comprehension and Reasoning, RCR)和阅读理解理解与生成(Reading Comprehension and Generation, RCG)等。
B. 训练原理
阅读理解的训练主要有两个阶段:预训练和微调。预训练是指在大规模的语料库上进行的无监督学习,目的是让模型通过学习语言模型来掌握语言的基本规律,从而提高阅读理解的能力。微调则是在已经训练好的模型基础上,采用有监督学习的方法,对模型进行有针对性的调整,以适应某个特定的任务。具体而言,微调过程通常包括对模型的结构和参数进行调整,以及对数据集进行适当的处理,比如数据增强和负样本采样等。
C. 数据集介绍
目前,阅读理解的数据集主要有SQuAD、CMRC、RACE、DuReader等。其中,SQuAD是阅读理解数据集中最为著名的之一,它包括了500多篇文章和超过100,000个问答对。SQuAD的任务类型主要是单项选择题型和填空题型,属于机器阅读理解范畴。CMRC是一个面向中文的阅读理解数据集,它由清华大学自然语言处理与社会人文计算实验室发布,包含超过10,000篇大众百科文章和25,000个问答对。RACE是英文阅读理解数据集,它包括28,000个文章和12,000个问答对,涵盖了各种类型的问题。DuReader是中国科学院计算技术研究所发布的中文阅读理解数据集,它由真实的搜索结果组成,包括200,000篇文章和1,020,000个问答对。
三、数据样例标注
A. 数据集来源
数据集的来源通常有两种,一种是从现有的文本语料库中选取适当的数据进行标注,另一种是通过众包等方式,让人工标注数据。无论哪种方式,数据的质量都是关键因素之一。
B. 标注方法与工具
阅读理解数据集的标注通常有两种方式:抽取式和生成式。抽取式标注是指直接从文章中抽取出答案,然后将其作为标准答案。生成式标注则是需要根据文章内容自己构造答案。如何选择标注方法将影响到数据集的难度和可用性。
C. 标注样例展示
下面是一个来自SQuAD数据集的样例:
{
"context": "新疆历史文化悠久,山水秀美,草原广阔。新疆境内曾先后建立西域羌、月氏、匈奴、突厥、吐蕃、回鹘、蒙古等数十个王国和政权。十八世纪以来,新疆逐渐成为中国版图的一部分。1949年10月1日中华人民共和国成立后,新疆继续作为中国不可分割的一部分。",
"question": "新疆历史上曾建立过什么王国和政权?",
"answers": [
{
"text": "西域羌、月氏、匈奴、突厥、吐蕃、回鹘、蒙古等数十个王国和政权。",
"answer_start": 23
}
],
"id": "56ddde6b9a695914005b9628"
}
四、输入模型之前的数据变化
A. 特征提取方法
特征提取是将原始数据转化为计算机可以处理的数值特征的过程,通常包括文本表示和语言特征选取两部分。文本表示可以采用one-hot编码、词袋模型、词向量等方式,语言特征选取则需要根据任务类型选取合适的特征,比如文本长度、关键词、实体等。
B. 数据预处理
数据预处理是指对原始数据进行清洗、去噪、分词、停用词过滤等操作,以增强模型的鲁棒性和泛化能力。具体而言,数据预处理包括了以下几个步骤:分词、去除停用词、词干提取、词性标注、命名实体识别等。
C. 数据增强技术
数据增强是为了解决训练数据不足的问题而采取的一种方法,它通过对原始数据进行修改、扩充、合成等操作,生成更多的训练数据,从而提高模型的性能。数据增强的方法一般包括同义词替换、词向量插值、随机删除等。
D. 变化样例展示
下面是一个数据增强的样例:
原始问题:李白是哪个朝代的诗人?
增强后的问题:李白是哪位唐代的诗人?
五、模型架构与参数设置
A. 模型架构介绍
目前,阅读理解中常用的模型有RNN、LSTM、GRU、CNN、Transformer等。其中,Transformer模型是近年来最为流行的一种模型,由于其在机器翻译任务中的突出表现,被引入到了阅读理解任务中。它的核心思想是自注意力机制,它可以直接利用输入文本的所有位置信息,无需进行序列建模,因此在处理长文本任务时具有明显的优势。
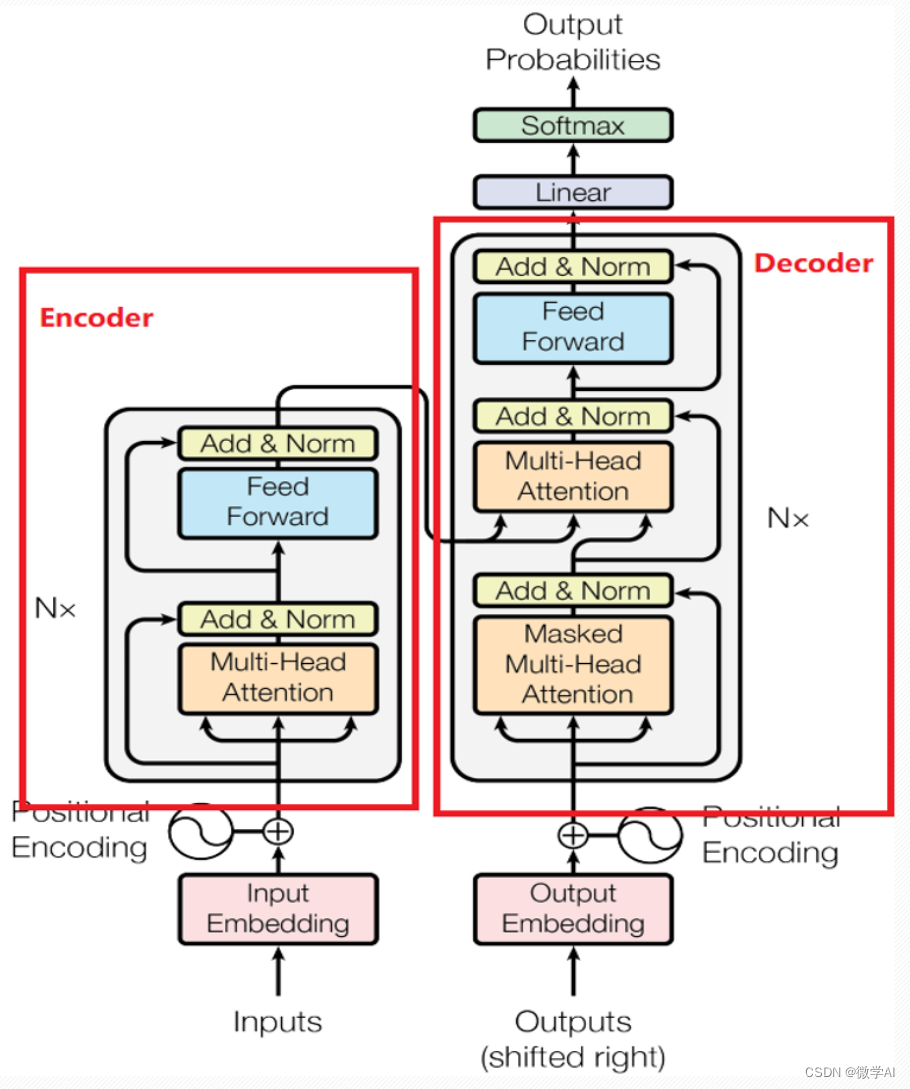
B. 参数设置
参数设置是模型训练过程中的一个重要部分,它将直接影响到模型的性能。通常,在模型训练之前需要进行超参数调整,以获得最优的模型性能。常见的超参数包括学习率、正则化系数、批次大小等。
C. 模型训练过程
模型训练通常分为三个步骤:前向传播、损失计算和反向传播。在前向传播阶段,模型会根据输入文本计算出问题的答案;损失计算阶段则是通过比较模型预测的答案和标准答案之间的差异来计算损失函数;反向传播阶段则是通过梯度下降算法来更新模型参数,以便优化模型的性能。
六、实验结果与分析
A. 实验环境介绍
实验中使用的硬件配置和软件环境可以影响到模型的性能。通常,在进行实验之前需要确定好环境配置和参数设置等。具体而言,实验环境包括了硬件环境、软件环境、数据集划分等。
B. 实验结果展示
实验结果包括了模型的准确率、精度、召回率等指标,同时也需要进行可视化展示。在进行实验结果展示时,需要清晰地说明实验方法、实验数据以及实验结果等。
C. 结果分析与讨论
结果分析与讨论通常包括了模型的优缺点、实验结果的意义、实验结果与现有研究成果的比较等方面。在进行结果分析与讨论时,需要对实验结果进行全面细致的分析,并指出该研究的创新点和不足之处。
七、应用与展望
A. 应用场景
阅读理解具有广泛的应用场景,包括智能问答、在线客服、信息抽取、信息检索等。未来,随着人工智能技术的不断发展,阅读理解将在更广泛的领域中得到应用。
B. 发展趋势
通过对阅读理解技术的不断探索和创新,阅读理解技术将越来越成熟、稳定和可靠。同时,随着数据量的不断增加和硬件计算能力的提升,阅读理解技术将会向更高精度和更快速度的方向发展。
八、结论
A. 研究贡献
本篇文章主要介绍了阅读理解中的训练原理、数据样例标注以及数据输入模型之前的数据变化等内容。此外,我们还介绍了相关的技术和方法,并展示了实验结果。这些内容对于推进阅读理解技术的发展具有一定的研究贡献。
B. 局限性与展望
本文主要集中于介绍阅读理解的基本原理和实验结果,对于深入分析阅读理解技术的内在机制还有待进一步研究。未来,我们将继续探索新的方法和技术,以进一步提高阅读理解技术的性能。
C. 总结
阅读理解是NLP领域中的重要研究方向之一,它的应用前景非常广泛。本文主要介绍了阅读理解的训练原理、数据样例标注和数据输入模型之前的数据变化等内容,并展示了实验结果。希望本文能够对阅读理解的研究工作有所启发,并对相关学者提供参考。