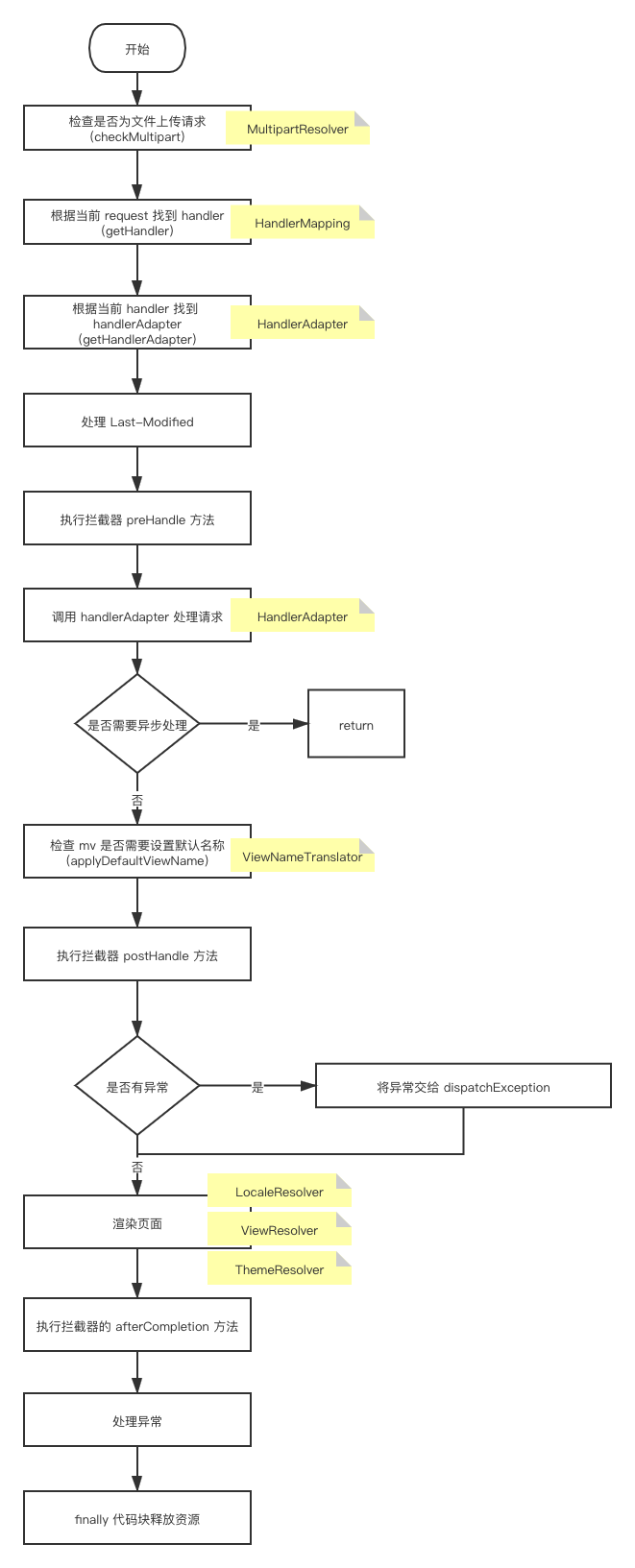
集群发现机制
Elasticsearch采用了master-slave模式, ES会在集群中选取一个节点成为主节点,只有Master节点有资格维护全局的集群状态,在有节点加入或者退出集群的时候,它会重新分配分片,并将集群最新状态发送给集群中其它节点,主节点会以周期性ping的方式以验证其它节点是否存活。
Elasticsearch的选举算法7.x之前基于Bully选举算法,7.x之后的ES,采用-种新的选主算法Raft ;
选举时机
-
集群初始化
-
集群的Master崩溃的时候
- 任何一个节点发现当前集群中的Master节点没有得到n/2 + 1节点认可的时候,触发选举;
选举的基本原则
ES针对当前集群中所有的Master Eligible Node进行选举得到master节点,为了避免出现Split-brain现象,ES选择了分布式系统常见的quorum(多数派)思想,也就是只有获得了超过半数选票的节点才能成为master。在ES中使用 discovery.zen.minimum_master_nodes 属性设置quorum,这个属性一般设置为 eligibleNodesNum / 2 + 1。
选举的流程说明如下
- 节点node向所有比自己大的节点发送选举消息(选举为election消息)
- 如果节点node得不到任何回复(回复为alive消息),那么节点node成为master,并向所有的其它节点宣布自己是master(宣布为Victory消息)
- 如果node得到了任何回复,node节点就一定不是master,同时等待Victory消息,如果等待Victory超时那么重新发起选举;
Bully算法
Leader选举的基本算法之一。
在bully算法中,每个节点都有一个编号,只有编号最大的存活节点才能成为master节点。
Discovery模块:负责发现集群中的节点,以及选择主节点。ES支持多种不同Discovery类型选择,内置的实现称为Zen Discovery。
Zen Discovery封装了节点发现(Ping)、选主等实现过程。
算法假定所有节点都有一个惟一的ID,该ID对节点进行排序。 任何时候的当前Leader都是参与集群的最高id节点。 该算法的优点是易于实现,但是,当拥有最大 id 的节点处于不稳定状态的场景下会有问题,例如 Master 负载过重而假死,集群拥有第二大id 的节点被选为 新主,这时原来的 Master 恢复,再次被选为新主,然后又假死…
elasticsearch 通过推迟选举直到当前的 Master 失效来解决上述问题;但是容易产生脑裂,再通过 法定得票人数过半 解决脑裂;

在 es 中,发送投票就是发送加入集群请求.在 handleJoinRequest 过程统计投票,收到的连接被存储到 pendingJoinRequests.
在 checkPendingJoinsAndElectIfNeeded 中检查投票是否足够,其中会过滤掉没有 Master 资格节点的投票;
代码实现逻辑:
1. 筛选activeMasters列表
Ping所有节点并获取PingResponse;
- 过滤有成为 Master 资格的节点
- 创建了三个列表;
其中,joinedOnceActiveNodes.size <= activeNodes.size,差别在于是否含有 localnode, 其他的内容都一样,都是来自ping 的结果
Es的master就是从activeMasters列表或者masterCandidates列表选举出来,所以选举之前es首先需要得到这两个列表。Elasticsearch节点成员首先向集群中的所有成员发送Ping请求,elasticsearch默认等待discovery.zen.ping_timeout时间,然后elasticsearch针对获取的全部response进行过滤,筛选出其中activeMasters列表,activeMaster列表是其它节点认为的当前集群的Master节点
2.筛选masterCandidates列表
masterCandidates列表是当前集群有资格成为Master的节点,如果我们在elasticsearch.yml中配置了如下参数,那么这个节点就没有资格成为Master节点,也就不会被筛选进入masterCandidates列表;
Elasticsearch的任意一个节点都可以设置node.master和node.data属性
配置某个节点没有成为master资格 node.master:false;
3. 从activeMasters列表选举Master节点
activeMaster列表是其它节点认为的当前集群的Master节点列表,如果activeMasters列表不为空,elasticsearch会优先从activeMasters列表中选举,也就是对应着流程图中的蓝色框,选举的算法是Bully算法,笔者在前文中详细介绍了Bully算法,Bully算法会涉及到优先级比较, 在activeMasters列表优先级比较的时候,如果节点有成为master的资格,那么优先级比较高,如果activeMaster列表有多个节点具有master资格,那么选择id最小的节点
代码如下
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {
if (o1.isMasterNode() && !o2.isMasterNode()) {
return -1;
}
if (!o1.isMasterNode() && o2.isMasterNode()) {
return 1;
}
return o1.getId().compareTo(o2.getId());
}
public DiscoveryNode tieBreakActiveMasters(Collection<DiscoveryNode> activeMasters) {
return activeMasters.stream().min(ElectMasterService::compareNodes).get();
}4. 从masterCandidates列表选举Master节点
这一节对应的是红色流程图中红色部分,如果activeMaster列表为空,那么会在masterCandidates中选举,masterCandidates选举也会涉及到优先级比较,masterCandidates选举的优先级比较和masterCandidates选举的优先级比较不同。它首先会判断masterCandidates列表成员数目是否达到了最小数目discovery.zen.minimum_master_nodes。如果达到的情况下比较优先级,优先级比较的时候首先比较节点拥有的集群状态版本编号,然后再比较id,这一流程的目的是让拥有最新集群状态的节点成为master
public static int compare(MasterCandidate c1, MasterCandidate c2) {
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}5. 本地节点是master
经过上述选举之后,会选举出一个准master节点, 准master节点会等待其它节点的投票,如果有discovery.zen.minimum_master_nodes-1个节点投票认为当前节点是master,那么选举就成功,准master会等待discovery.zen.master_election.wait_for_joins_timeout时间,如果超时,那么就失败。在代码实现上准master通过注册一个回调来实现,同时借助了AtomicReference和CountDownLatch等并发构建实现
if (clusterService.localNode().equals(masterNode)) {
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
joinThreadControl.markThreadAsDone(currentThread);
nodesFD.updateNodesAndPing(state); // start the nodes FD
}
@Override
public void onFailure(Throwable t) {
logger.trace("failed while waiting for nodes to join, rejoining", t);
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
);本地节点是Master的时候,Master节点会开启错误检测(NodeFaultDetection机制),它节点会定期扫描集群所有的成员,将失活的成员移除集群,同时将最新的集群状态发布到集群中,集群成员收到最新的集群状态后会进行相应的调整,比如重新选择主分片,进行数据复制等操作
6. 本地节点不是master
当前节点判定在集群当前状态下如果自己不可能是master节点,首先会禁止其他节点加入自己,然后投票选举出准Master节点。同时监听master发布的集群状态(MasterFaultDetection机制),如果集群状态显示的master节点和当前节点认为的master节点不是同一个节点,那么当前节点就重新发起选举。
非Master节点也会监听Master节点进行错误检测,如果成员节点发现master连接不上,重新加入新的Master节点,如果发现当前集群中有很多节点都连不上master节点,那么会重新发起选举。
Raft算法选主流程
Raft作为一种分布式一致性协议,其本身不止描述了选举过程,还提供了日志同步与安全性的相关行为的描述;
其设计原则如下:
- 容易理解
- 减少状态的数量,尽可能消除不确定性
在Raft中,节点可能的状态有三种,其转换关系如下:

正常情况下,集群中只有一个Leader,其他节点全是Follower。Follower 都是被动接收请求,从不主动发送任何请求。Candidate - 候选人,候补者;应试者 是从Follower到Leader的中间状态。
Raft中引入任期(term) 的概念,每个term内最多只有一个Leader。term 在Raft算法中充当逻辑时钟的作用。服务器之间通信的时候会携带这个term,如果节点发现消息中的term小于自己的term,则拒绝这个消息;如果大于本节点的term,则更新自己的term。如果一个Candidate或者Leader发现自己的任期过期了,它会立即回到Follower状态。
Raft选举流程为:
- 增加当前节点本地的current term,切换到Candidate状态;
- 当前节点投自己一票,并且并行给其他节点发送RequestVote RPC (让大家投他) ;
然后等待其他节点的响应,会有如下三种结果:
- 如果接收到大多数服务器的选票,那么就变成Leader。成为Leader后,向其他节点发送心跳消息来确定自己的地位并阻止新的选举。
- 如果收到了别人的投票请求,且别人的term比自己的大,那么候选者退化为Follower;
- 如果选举过程超时,再次发起一轮选举;
ES实现Raft算法选主流程
ES实现中,候选人不先投自己,而是直接并行发起RequestVote,这相当于候选人有投票给其他候选人的机会。这样的好处是可以在一定程度上避免3个节点同时成为候选人时,都投自己,无法成功选主的情况。
ES不限制每个节点在某个term上只能投一票, 节点可以投多票,这样会产生选出多个主的情况:
- Node2被选为主,收到的投票为:Node2、 Node3;
- Node3被选为主,收到的投票为:Node3、 Node1;
对于这种情况,ES的处理是让最后当选的Leader成功,作为Leader。如果收到RequestVote请求,他会无条件退出Leader状态。在本例中,Node2先被选为主,随后他收到Node3的RequestVote请求,那么他退出Leader状态,切换为CANDIDATE,并同意向发起RequestVote候选人投票。因此最终Node3成功当选为Leader。

动态维护参选节点列表
在此之前,我们讨论的前提是在集群节点数量不变的情况下,现在考虑下集群扩容、缩容、节点临时或永久离线时是如何处理的。在7.x之前的版本中,用户需要手工配置minimum_master_nodes, 来明确告诉集群过半节点数应该是多少,并在集群扩缩容时调整他。现在,集群可以自行维护。
在取消了discovery.zen.minimum_master_nodes 配置后,现在的做法不再记录“quorum”法定数量的具体数值,取而代之的是记录一个节点列表,这个列表中保存所有具备master资格的节点(有些情况下不是这样,例如集群原本只有1个节点,当增加到2个的时候,这个列表维持不变,因为如果变成2,当集群任意节点离线,都会导致无法选主。这时如果再增加一个节点,集群变成3个,这个列表中就会更新为3个节点),称为VotingConfiguration,他会持久化到集群状态中。
在节点加入或离开集群之后,Elasticsearch 会自动对VotingConfiguration 做出相应的更改,以确保集群具有尽可能高的弹性。在从集群中删除更多节点之前,等待这个调整完成是很重要的。你不能一次性停止半数或更多的节点。(感觉大面积缩容时候这个操作就比较感人了,一部分一部分缩)。默认情况下,ES自动维护VotingConfiguration。有新节点加入的时候比较好办,但是当有节点离开的时候,他可能是暂时的重启,也可能是永久下线。你也可以人工维护VotingConfiguration,配置项为:cluster.auto_shrink_voting_configuration,当你选择人工维护时,有节点永久下线,需要通过voting exclusions API将节点排除出去。如果使用默认的自动维护VotingConfiguration,也可以使用voting exclusions API来排除节点,例如一次性下线半数以上的节点。
如果在维护VotingConfiguration时发现节点数量为偶数,ES会将其中一个排除在外,保证VotingConfiguration是奇数。因为当是偶数的情况下,网络分区将集群划分为大小相等的两部分,那么两个子集群都无法达到“多数”的条件。
分片&副本机制
分片:Elasticsearch集群允许系统存储的数据量超过单机容量,这是通过shard实现的。在一个索引index中,数据(document)被分片处理(sharding)到多个分片上。也就是说:每个分片都保存了全部数据中的一部分。
一个分片是一个 Lucene 的实例,它本身就是一个完整的搜索引擎。文档被存储到分片内,但应用程序直接与索引而不是与分片进行交互。
副本:为了解决访问压力过大时单机无法处理所有请求的问题,Elasticsearch集群引入了副本策略replica。副本策略对index中的每个分片创建冗余的副本。
副本的作用如下:
1. 提高系统容错性
当分片所在的机器宕机时,Elasticsearch可以使用其副本进行恢复,从而避免数据丢失。
2. 提高ES查询效率
处理查询时,ES会把副本分片和主分片公平对待,将查询请求负载均衡到副本分片和主分片。
副本分片并不是越多越好,原因有以下两点:
(1)多个 replica 可以提升搜索操作的吞吐量和性能,但是如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少,这个时候你就需要增加更多的硬件资源来提升吞吐量。
(2)更多的副本分片数提高了数据冗余量,保证了数据的完整性,但是根据上边主副分片之间的交互原理可知,分片间的数据同步会占用一定的网络带宽,影响效率,所以索引的分片数和副本数也不是越多越好。
分片和副本机制
1、index包含多个shard;
2、每个shard都是一个最小工作单元,承担部分数据;每个shard都是一个lucene示例,有完整的建立索引和处理请求的能力;
3、增减节点时,shard会自动在nodes中负载均衡;
4、primary shard和replica shard,每个document只存在于某个primary shard以及其对应的replica shard中,不可能存在于多个primary shard;
5、replica shard是primary shard的副本,负责容错,以及承担读请求负载;
6、primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改。
7、primary shard的默认数量是5,replica默认是1,(总共默认有10个shard,5个primary shard,5个replica shard);
8、primary shard不能和自己的replica shard放在同一个 节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用,但是可以和其它primary shard的replica shard放在同一个节点上);
负载机制
容错机制
扩容机制
垂直扩容
买更牛逼的服务器,价钱没上限!!!而且瓶颈还会存在。比如你现在10T数据,磁盘满了,放不下了。现在业务数据总量能到达100T,那你再买个100T的磁盘?那你真有钱,100T满了咋办?
2、水平扩容
业界经常采用的方案,采购越来越多的10T服务器,性能比较一般,但是很多10T服务器组织在一起,就能构成强大的存储能力。(推荐。划算,还不会瓶颈)
分片路由原理
Elasticsearch 索引一条数据(一个文档)时,中如何知道一条应该存放到哪个分片中呢?
采用这个公式决定的:
shard = hash(routing) % number_of_primary_shards
Routing 是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。Routing 通过 Hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数。这个余数在 0 到 number_of_primary_shards-1 之间,它就是我们所寻求的文档所在分片的位置。
这就是为什么创建好索引后就无法改变分片数量。因为如果数量变化了,所有之前路由的值都会无效,文档也再也找不到了。
在 ES 集群中,每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。在一个写请求被发送到某个节点后,该节点即为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。
ES 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES 通过乐观锁的方式控制,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
写数据示例
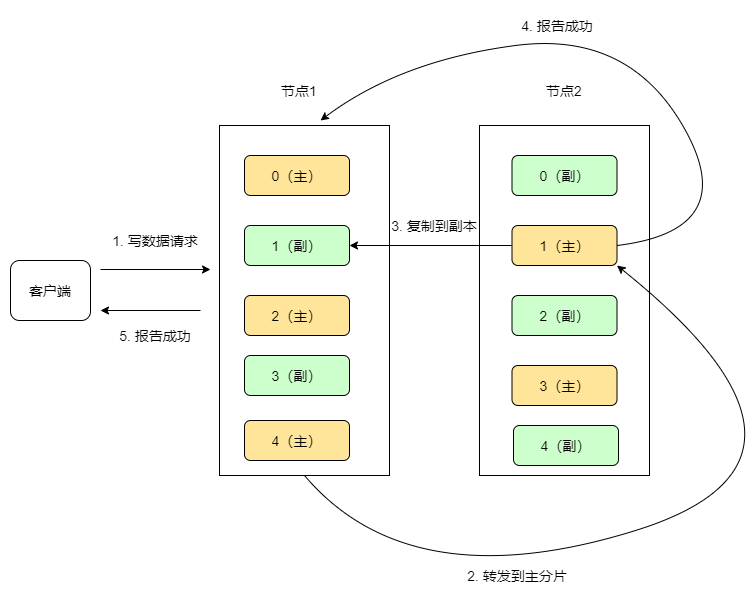
如上图所示,每个节点有5个分片,每个分片都在另一个节点上有一个副本。
1.客户端向节点1(协调节点)发送写请求,通过路由计算公式得到值为 1,则当前数据应被写到2.主分片(1(主)) 上。
2.节点1将请求转发到主分片(1(主))所在的节点(节点2),节点2接受请求并写入到磁盘。
3.并发将数据复制到副本分片(1(副))上,其中通过乐观并发控制数据的冲突。
4.一旦所有的副本分片都报告成功,则节点2将向协调节点(节点1)报告成功
5.协调节点(节点1)向客户端报告成功。
更新中。。。