从Pytorch框架下YOLOv5的模型训练,到Flask框架的模型加载,再到Vue框架的界面设计到最后的服务器部署。
实验环境
1.Windows10系统
2.编辑器pycharm
3.GPU 1080Ti
4.anaconda虚拟环境安装相应的安装包
5.pytorch版本1.7.1
6.Python3.7.15
实验数据集
在实际场景下采集和标注的草莓果实数据集,如果有需要的可以和本人联系。
YOLOv5模型的训练
目前开源的YOLOv5有很多版本,我这里采用的是YOLOv5 3.0版本
这里需要注意的是训练的模型结构必须与Flask加载的模型结构保持一致。如果尝试改进模型结构需要在后端代码块中相应的位置进行更改。
这里给出YOLOv5 3.0的yolov5s.yaml
# parameters
nc: 2 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
YOLOv5如何训练,相关教程很多,不在详述,主要注意与加载模型结构保持一致。
Flask后端加载模型
新建AIDetector_pytorch.py文件。
import torch
import numpy as np
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords, letterbox
from utils.torch_utils import select_device
import cv2
from random import randint
class Detector(object):
def __init__(self):
self.img_size = 640
self.threshold = 0.4
self.max_frame = 160
self.init_model()
def init_model(self):
self.weights = 'weights/best.pt'#加载模型,注意模型结构一定要与model文件中模型结构代码一致
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
# torch.save(model, 'test.pt')
self.m = model
self.names = model.module.names if hasattr(
model, 'module') else model.names
self.colors = [
(randint(0, 255), randint(0, 255), randint(0, 255)) for _ in self.names
]
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() # 半精度
img /= 255.0 # 图像归一化
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def plot_bboxes(self, image, bboxes, line_thickness=None):
tl = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) / 2) + 1 # line/font thickness
for (x1, y1, x2, y2, cls_id, conf) in bboxes:
color = self.colors[self.names.index(cls_id)]
c1, c2 = (x1, y1), (x2, y2)
cv2.rectangle(image, c1, c2, color,
thickness=tl, lineType=cv2.LINE_AA)
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(
cls_id, 0, fontScale=tl / 3, thickness=tf)[0]
c=int(cls_id)
class_indict = {'0': 'immature', '1': 'Ripe strawberry'}#通过元祖返回检测框的检测结果封装接口
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(image, '{} ID-{:.2f}'.format(class_indict[str(c)], conf), (c1[0], c1[1] - 2), 0, tl / 3,
[225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
return image
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.3)
pred_boxes = []
image_info = {}
count = 0
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
print(lbl)
class_indict = {'0': 'immature', '1': 'Ripe strawberry'}
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
pred_boxes.append(
(x1, y1, x2, y2, lbl, conf))
count += 1
key = '{}-{:02}'.format(class_indict[str(lbl)], count)
image_info[key] = ['{}×{}'.format(
x2-x1, y2-y1), np.round(float(conf), 3)]#这里同样是后端检测结果的接口封装
im = self.plot_bboxes(im, pred_boxes)
return im, image_info
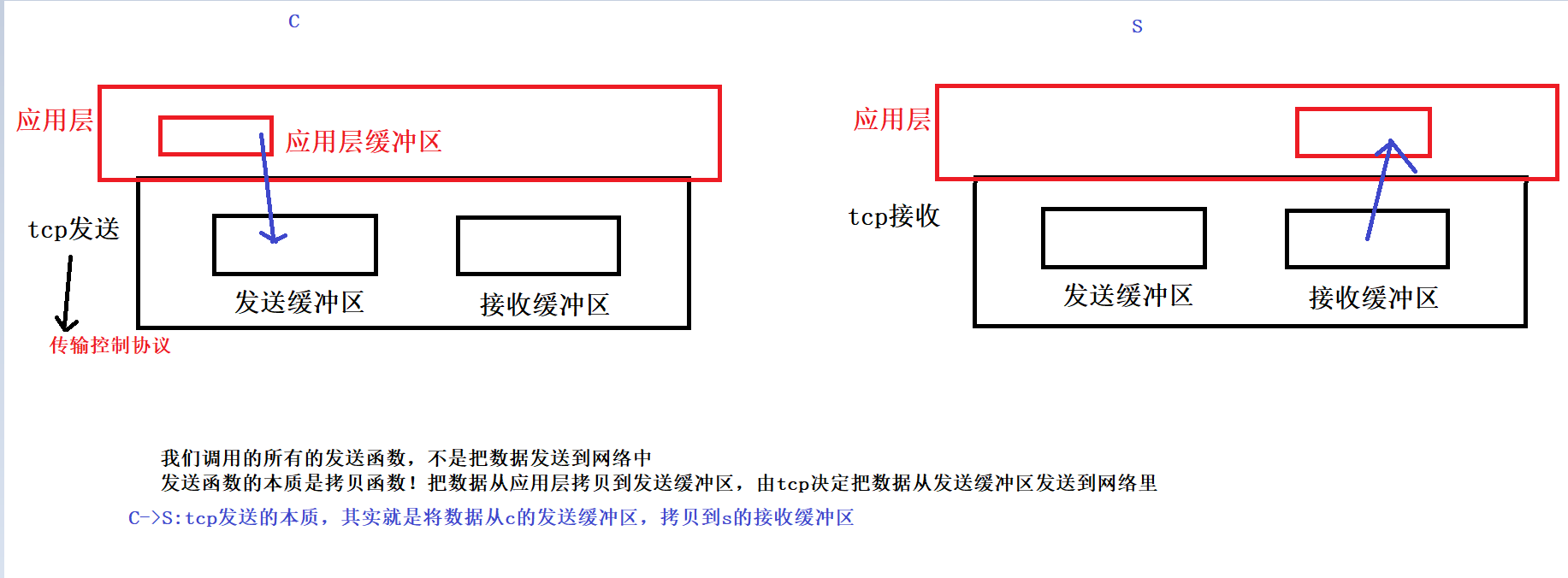
由于本系统是一个典型的前后端分离的系统,所以需要在后端完成所有的检测,以及相应的接口函数的封装,在上传到前端。
新建app.py进行前后端交互。
import datetime
import logging as rel_log
import os
import shutil
from datetime import timedelta
from flask import *
from processor.AIDetector_pytorch import Detector
import core.main
UPLOAD_FOLDER = r'./uploads'
ALLOWED_EXTENSIONS = set(['png', 'jpg'])
app = Flask(__name__)
app.secret_key = 'secret!'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
werkzeug_logger = rel_log.getLogger('werkzeug')
werkzeug_logger.setLevel(rel_log.ERROR)
# 解决缓存刷新问题
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = timedelta(seconds=1)
# 添加header解决跨域
@app.after_request
def after_request(response):
response.headers['Access-Control-Allow-Origin'] = '*'
response.headers['Access-Control-Allow-Credentials'] = 'true'
response.headers['Access-Control-Allow-Methods'] = 'POST'
response.headers['Access-Control-Allow-Headers'] = 'Content-Type, X-Requested-With'
return response
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
@app.route('/')
def hello_world():
return redirect(url_for('static', filename='./index.html'))
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
file = request.files['file']
print(datetime.datetime.now(), file.filename)
if file and allowed_file(file.filename):
src_path = os.path.join(app.config['UPLOAD_FOLDER'], file.filename)
file.save(src_path)
shutil.copy(src_path, './tmp/ct')
image_path = os.path.join('./tmp/ct', file.filename)
pid, image_info = core.main.c_main(
image_path, current_app.model, file.filename.rsplit('.', 1)[1])
return jsonify({'status': 1,
'image_url': 'http://127.0.0.1:5003/tmp/ct/' + pid,
'draw_url': 'http://127.0.0.1:5003/tmp/draw/' + pid,
'image_info': image_info})
return jsonify({'status': 0})
@app.route("/download", methods=['GET'])
def download_file():
# 需要知道2个参数, 第1个参数是本地目录的path, 第2个参数是文件名(带扩展名)
return send_from_directory('data', 'testfile.zip', as_attachment=True)
# show photo
@app.route('/tmp/<path:file>', methods=['GET'])
def show_photo(file):
if request.method == 'GET':
if not file is None:
image_data = open(f'tmp/{file}', "rb").read()
response = make_response(image_data)
response.headers['Content-Type'] = 'image/png'
return response
if __name__ == '__main__':
files = [
'uploads', 'tmp/ct', 'tmp/draw',
'tmp/image', 'tmp/mask', 'tmp/uploads'
]
for ff in files:
if not os.path.exists(ff):
os.makedirs(ff)
with app.app_context():
current_app.model = Detector()
app.run(host='127.0.0.1', port=5003, debug=True)
Vue前端界面设计
本界面设计分为三个部分分别是Header.vue、Footer.vue、以及Content.vue。
Header.vue
<template>
<div id="Header">
<div class="top-left-edition">
<span style="color: #21b3b9; font-weight: bold">
<i class="el-icon-star-off" style="font-size: 23px"></i
>草莓成熟检测
</span>
<span>
<i class="el-icon-time" style="font-size: 23px"></i>胡涛、黄琼娇
</span>
</div>
<div id="word">
<h1>{{ msg }}</h1>
</div>
</div>
</template>
<script>
export default {
name: "Header",
data() {
return {
msg: "草莓表型识别",
activeIndex: "1",
};
},
methods: {},
};
</script>
<style scoped>
#Header {
padding: 30px 110px 0 150px;
width: 90%;
margin: 10px auto;
}
#word {
margin-left: 45%;
margin-top: -35px;
margin-bottom: 37px;
height: 60px;
line-height: 3.2em;
letter-spacing: 8px;
}
h1 {
/*text-align: center;*/
color: #21b3b9;
letter-spacing: 30px;
font-size: 2.3em;
}
.el-menu-demo {
width: 80%;
margin: 0px auto;
padding: 0px auto;
}
.top-left-edition span i {
float: left;
margin-right: 10px;
}
i,
input,
label {
vertical-align: middle;
}
i {
border: 0;
display: block;
cursor: pointer;
}
.top-left-edition span {
float: left;
font-size: 16px;
color: #999999;
line-height: 24px;
margin-right: 40px;
}
</style>
Footer.vue
<template>
<div id="Footer">
<p>{{ msg }}</p>
</div>
</template>
<script>
export default {
name: "Footer",
data() {
return {
msg: "Copyright @不要和我港话",
};
},
};
</script>
<style scoped>
#Footer {
/*background:#F2F6FC;*/
padding: 6px;
border-radius: 5px;
width: 80%;
height: 80px;
margin: 20px auto;
margin-top: 140px;
}
p {
color: #21b3b9;
text-align: center;
margin: 30px auto;
font-size: 1.1em;
}
</style>
服务器部署
1.启动后端代码,在后端代码目录下运行app.py
 2.此时后端代码运行成功,再新建terminal在前端代码目录下运行前端代码
2.此时后端代码运行成功,再新建terminal在前端代码目录下运行前端代码
注意:后端代码不能关停
运行结果如下

部署效果
在浏览器中打开生成的网址

这里根据需要可以对界面进行简单改动和设计(可以根据自己的喜好),本项目是对草莓的叶子、花朵和果实进行检测,因此设计了三个界面。下面展示识别结果。

 最左侧设计一个回到主菜单的按钮;中间的曲线图是草莓生长周期曲线,并且统计检测结果;最右侧是识别结果以及相应的类别、检测框的尺寸和置信度。
最左侧设计一个回到主菜单的按钮;中间的曲线图是草莓生长周期曲线,并且统计检测结果;最右侧是识别结果以及相应的类别、检测框的尺寸和置信度。
总结
回顾一下本项目的完整实现步骤:
1.配置相应训练环境,安装必要的安装包以及npm;
2.整理草莓叶子、花朵、果实数据集,以及无人机拍摄的数据集,进行人工标注;
3.采用YOLO网络训练模型(可以选择任意版本的网络结构,但是需要在本代码中进行相应更改);
4.模型训练完成在后端加载,所有检测识别结果在后端检测完成,然后上传到前端(前端界面也可以进行任意的设计);
最后有需要完完整代码和数据集,可以加微信号wxid_cn1zsaudo0pn22付费获取,也可以一起交流。