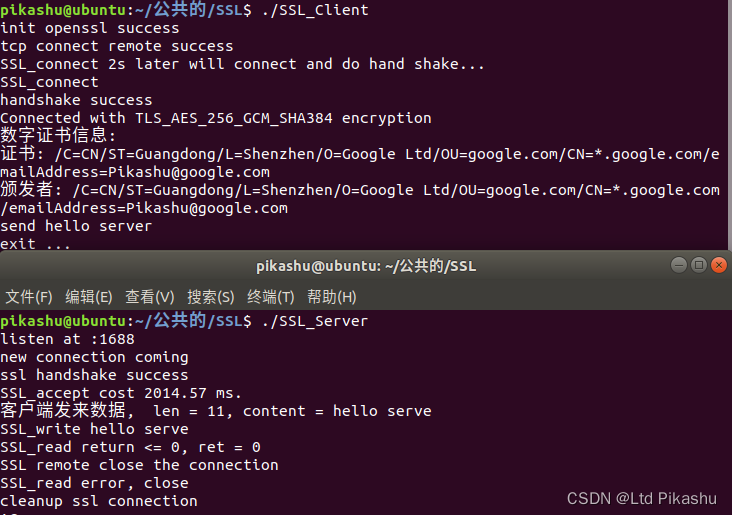
文章目录
- 前言
- 一、Prim算法原理
- 二、算法实现
- 1、生成图
- 2、Prim
- 总结
- 原创文章,未经许可,严禁转载
前言
在前文加权连通图的最小生成树(Kruskal)中已经用以边找点的方式实现最小生成树的生成。Prim算法也是一种常用的最小生成树算法,和Kruskal不同,Prim算法是以顶点找边实现的。
一、Prim算法原理
Prim算法的核心思想是:在加权连通图中,顶点的集合V,从图中某一顶点开始,得到子集M。重复得将连接到顶点集合M的权值最小的边加入到边集合,将新找到的顶点加入到顶点M集合,当M=V时,意味着所有顶点都已连通。也就得到了图的最小生成树。有加权连通图如下:

我们选中点A为起点,先将点A加入集合M。顶点A连接的权值最小的加为AB(4),我们选择这条边,将它加入边的集合,再将顶点B加入集合M。

然后,连接到M集合的权值最小的边是BC(8)和AH(8),可以任选一边,我们选择BC。同样将边加入边集合,顶点加入顶点集合。以此类推…

当满足了条件V=M后,就得到了此图的最小生成树。我们用C++代码实现它,下面代码还是用前文Kruskal已经使用的例子中的大部分代码,略有改动,再加上Prim算法的部分:
二、算法实现
我们需要有二个顶点集合,一个集合是已找到的顶点,另一个集合是未加入最小生成树的顶点。这样我们每次从已找到的顶点中的某一点出发,连接到未加入的顶点中权值最小的顶点。可以保证不会形成环,就无需判断是否形成环路。
1、生成图
代码如下(示例):
#include <iostream>
#include <vector>
#include <algorithm>
#include <bits/stdc++.h>
using namespace std;
typedef struct {
int start;
int end;
int val;
}edge;
class Graph{
private:
int vertex; //顶点数
int** matrix; //有向图关系矩阵
int* sign; //标记边所属集合
vector<edge> edges; //存储所有边
vector<edge> mst; //存储生成树的边
int weight = 0; //权重和
public:
Graph(const int n ,vector<vector<int>> &arr){
vertex = n;
matrix = new int* [vertex]; //生成有向图关系矩阵
sign = new int[vertex];
for (int i=0; i<vertex; i++) sign[i]=i; //初始顶点集合标记为自身,表示图是各点独立的森林
for (int i = 0; i < 9; ++i){
matrix[i] = new int[9];
for (int j=0; j<9; j++){
matrix[i][j] = 0;
}
}
edge tmp;
for (int i=0; i<15; ++i){
matrix[arr[i][0]][arr[i][1]] = arr[i][2]; //生成有向图矩阵
matrix[arr[i][1]][arr[i][0]] = arr[i][2]; //反向也有边,prim算法需要
tmp.start = arr[i][0]; //生成所有边
tmp.end = arr[i][1];
tmp.val = arr[i][2];
edges.push_back(tmp);
}
}
~Graph(){
delete[] matrix;
delete[] sign;
实际上与前文的图生成部分相比,只加了这一句matrix[arr[i][1]][arr[i][0]] = arr[i][2]; //反向也有边,prim算法需要因为是找边,边是双向的。所以要在矩阵中添加。
2、Prim
因为复用了前文的大量代码,所以实现此最小生成树的方式有点特殊。当然原理是一样的,就是代码有点奇怪的感觉,但是联系前文一起看可以更好地理解。代码如下(示例):
edge find_edge(list<int> va, list<int> v){
int min=100, st, en; //假设权值最大为100
for (auto i=v.begin(); i!=v.end(); i++){
for (auto j=va.begin(); j!=va.end(); j++){
if (matrix[*i][*j] != 0 && matrix[*i][*j] < min){
st = *i, en = *j;
min = matrix[st][en];
}
}
}
edge tmp;
tmp.start=st, tmp.end=en, tmp.val=min;
return tmp;
}
void prim(){
list<int> va; //所有顶点
list<int> v; //已加入的顶点
for (int i=0; i<vertex; i++) va.push_back(i); //生成所有顶点
v.push_back(0); //加入顶点0
va.remove(0);
while (va.size()){
edge e = find_edge(va, v);
mst.push_back(e);
v.push_back(e.end);
va.remove(e.end);
weight += e.val;
}
for (int i=0; i<mst.size(); i++) cout << mst[i].start << " -- " << mst[i].end << endl;
cout << "The weight of the MST tree: " << weight <<endl;
}
代码逻辑前面图示已经讲得很明白。va集合存储了所有的顶点,v是已加入生成树的顶点集合。不断循环遍历找出两个集合中相连顶点中权值最小的边,直到所有顶点都连通。要注意的顶点是加入v集合后,要在va集合中删除此顶点。
总结
最后的测试结果和Kruskal算法生成的略有不同,当然权值和是一样的。不然就至少有一个算法代码出错了,在此例中,只是生成边的顺序不同,实际上某些情况下,是很可能生成的树也不相同的,但二个算法生成的树的权值和肯定一样。
0 -- 3
3 -- 6
3 -- 1
6 -- 7
7 -- 8
8 -- 4
1 -- 5
5 -- 2
The weight of the MST tree: 36
这里是从顶点0开始生成的,实际上可以从任一个顶点开始。
Kruskal和Prim算法都是典型的贪心算法思想的应用,相对来说:Kruskal算法更适合边较少的稀疏图,Prim算法则更适用相反的情况,Kruskal算法的时间复杂度是O(ElogE),E是指边的数量,从这个复杂度就可以看出边越少越快。Prim算法的时间复杂度是O(ElogV),其中V是顶点的数量。