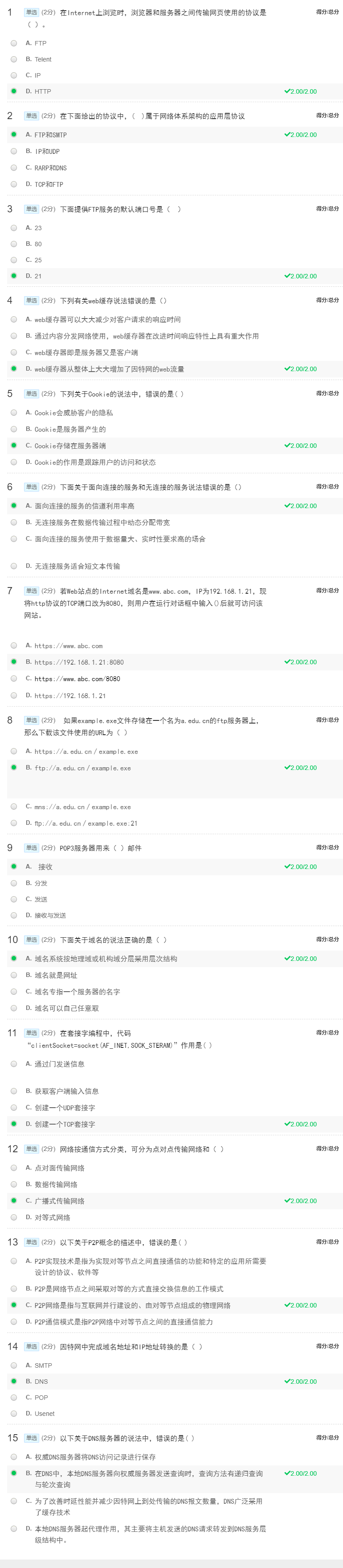
| 『2023北京智源大会』开幕式以及基础模型前沿技术论坛 |
文章目录
- 一. 黄铁军丨智源研究院院长
- 1. 大语言模型
- 2. 大语言模型评测体系FlagEval
- 3. 大语言模型生态(软硬件)
- 4. 三大路线通向 AGI(另外2条路径)
- 二. Towards Machines that can Learn, Reason, and Plan(杨立昆丨图灵奖得主)
- 三. 基础大模型——工程化打造Al中的“CPU" | 林咏华 | 智源研究院副院长
- 四. Build an Al system: Applying Reinforcement learning withhuman feedback (RLHF) on LLM to advance customization
- 五. 多模态预训练的进展回顾与展望丨中科院自动化所研究员丨刘静
- 1. 多模态预训练的研究背景一为什么关注?
- 2. 多模态预训练的研究进展 一 当前怎么做?
- 3. 多模态预训练的几点思考一以后怎么做?
- 六. Scaling Large Language Models: From Power Law to Sparsity丨谷歌研究科学家丨周彦祺
- 1. Moore's Law and Power Law(摩尔定律和幂律)
- 2. T5: Unified Text-to-Text Transformer T5(统一的文本到文本转换器)
- 3. Scaling LLM with MoE(使用MoE扩展LLM)
- 4. Advanced MoE techniques(先进的MoE技术)
- 5. Q&A(谷歌周彦祺:LLM浪潮中的女性科学家多面手)
- 参考文章
一. 黄铁军丨智源研究院院长
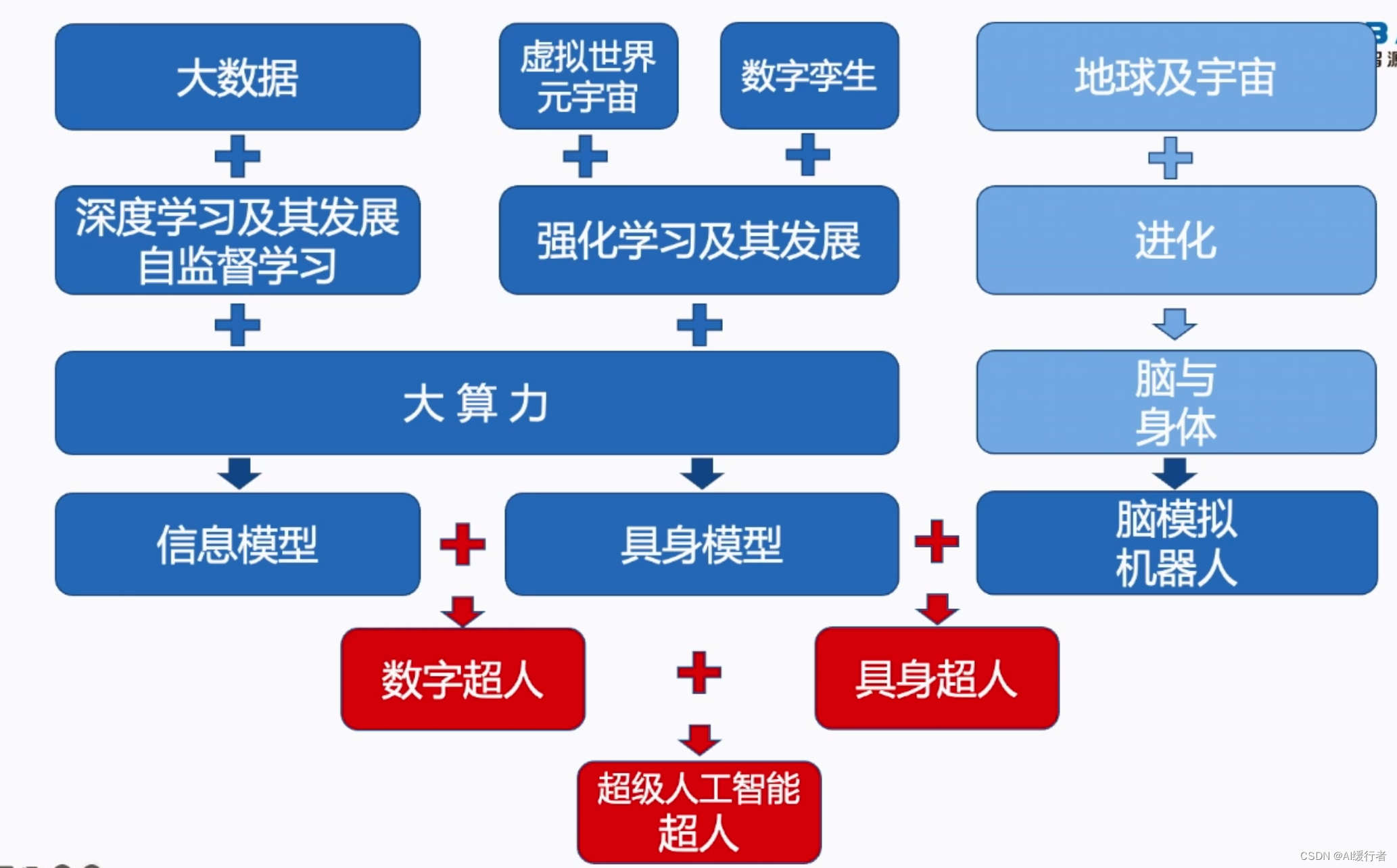
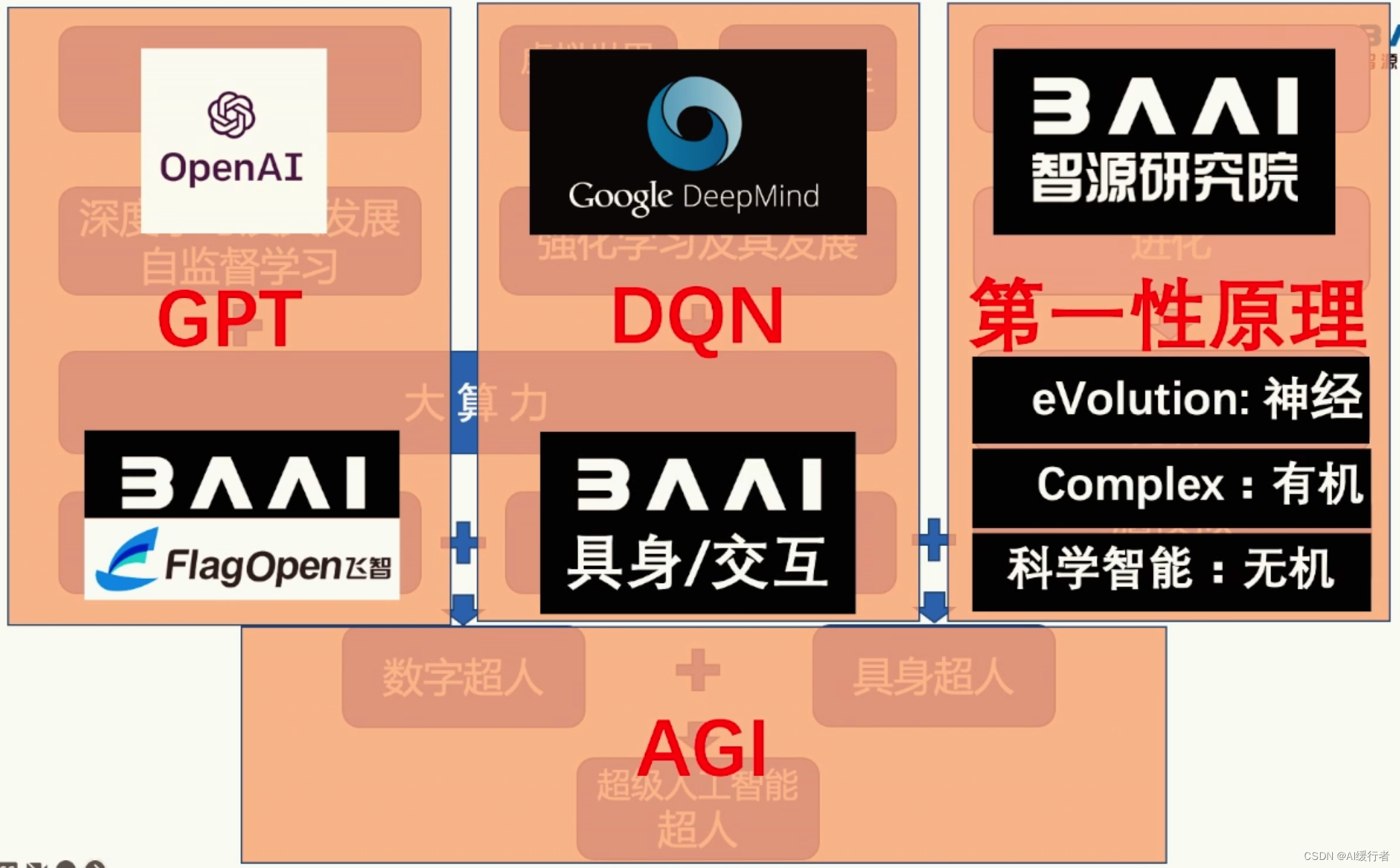
- 通用人工智能(AGI)的三条技术路线:信息论模型(目前主流)、具身模型以及自然进化。
1. 大语言模型
- 大模型大该2018年我们就开始了,大模型这个词在国内也是智源2021年首次提出。

- 何为大模型?

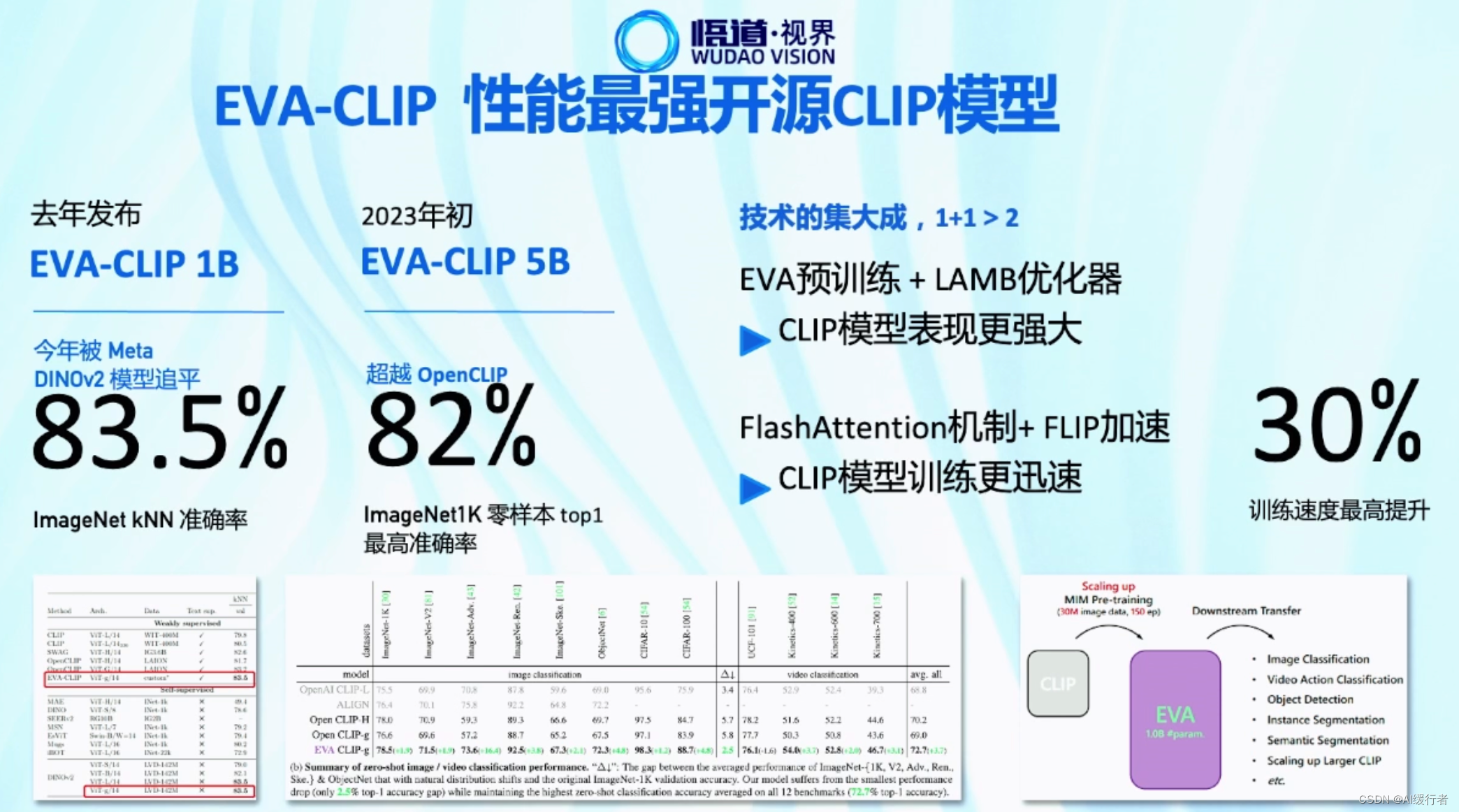
- 智源发布的大模型

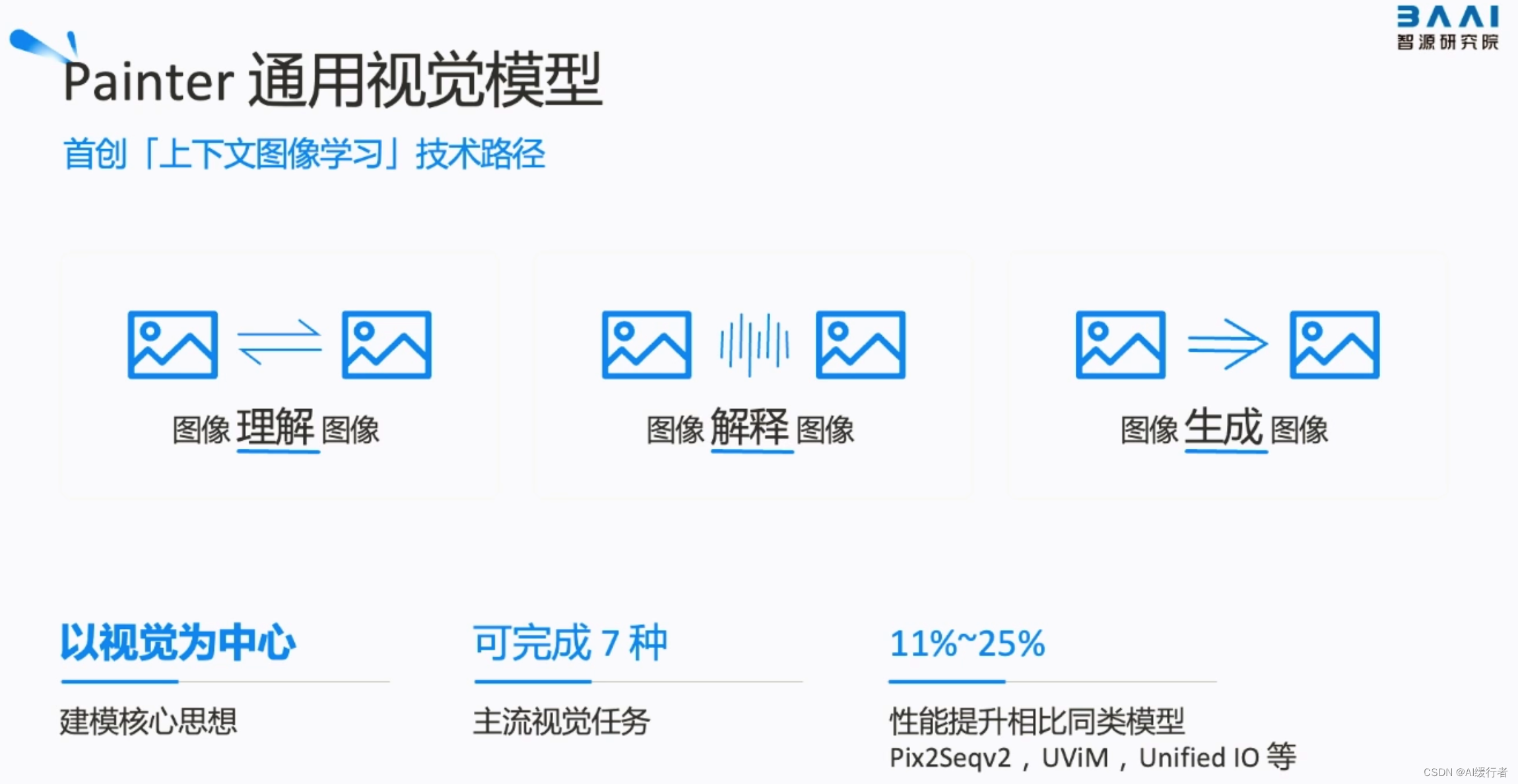
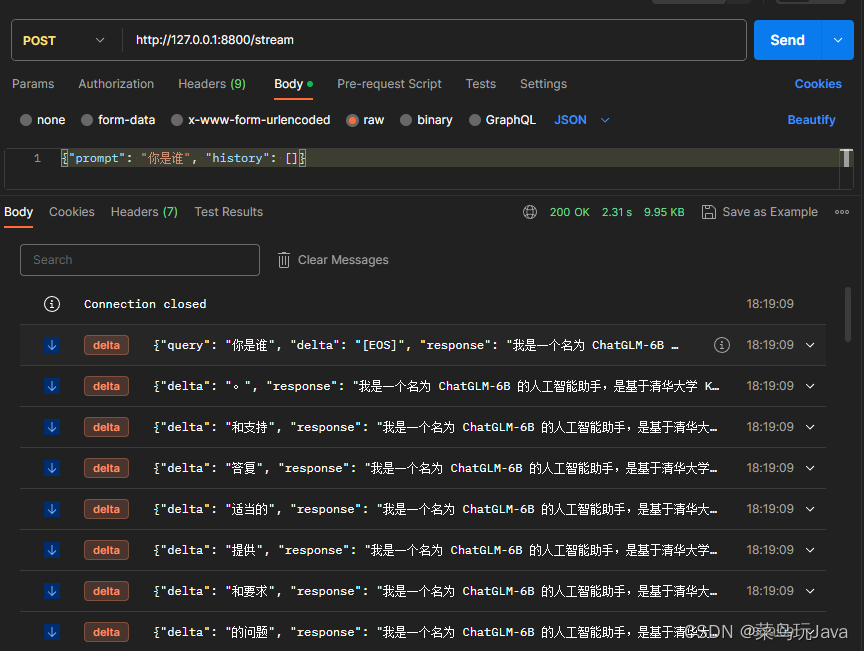
- 智源通用分割模型和meta的segment anything同一天发布


- 视频目标分割与追踪:第一帧图像和对应的物体掩码作为上下文示例,自动对后续视频帧进行分割并追踪

- 这样一个模型在自动驾驶、机器人等领域发挥基础性的作用


- 零样本的视频编辑:简单 prompt(提示)即可视频编辑,提示需要做什么。

- 在此基础上,进一步扩展了一个新模型Emu


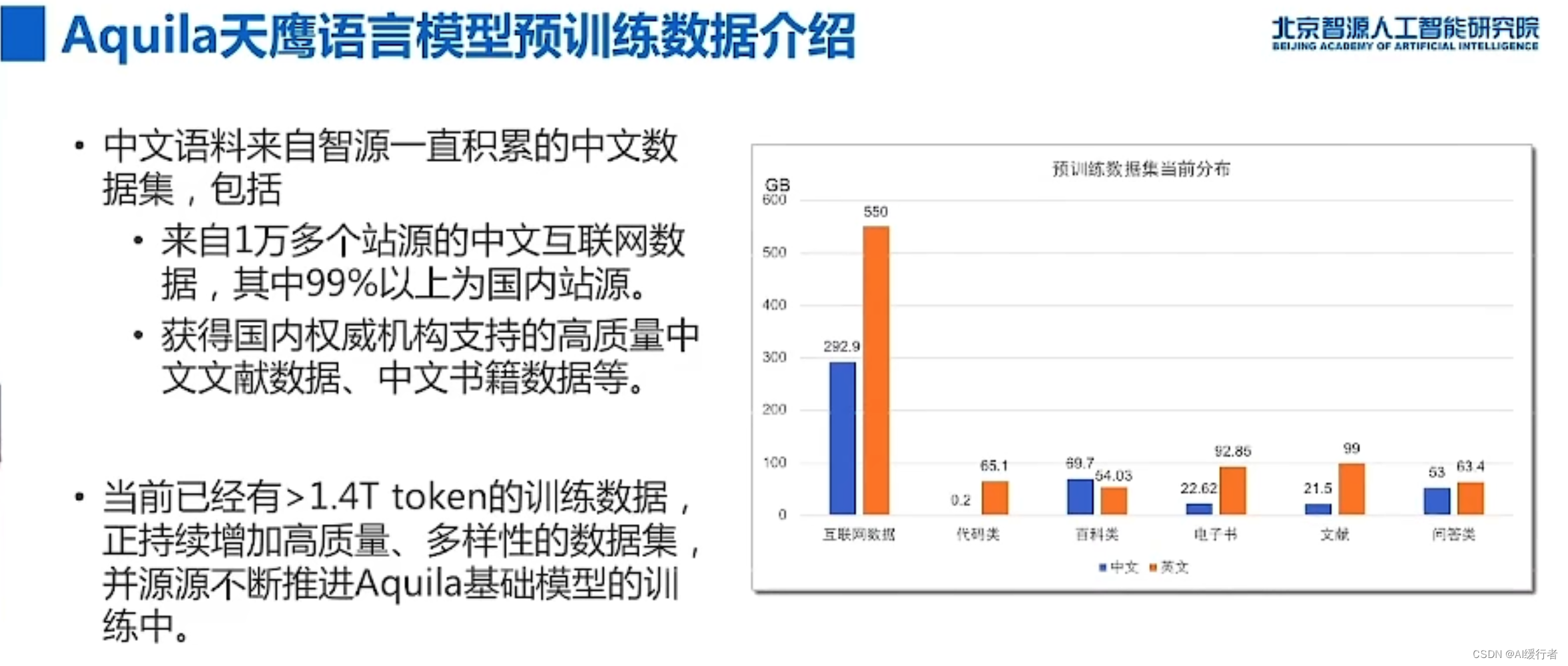
- 悟道.天鹰大模型,目前开源的模型参数量7B+33B,后续会陆续更新…

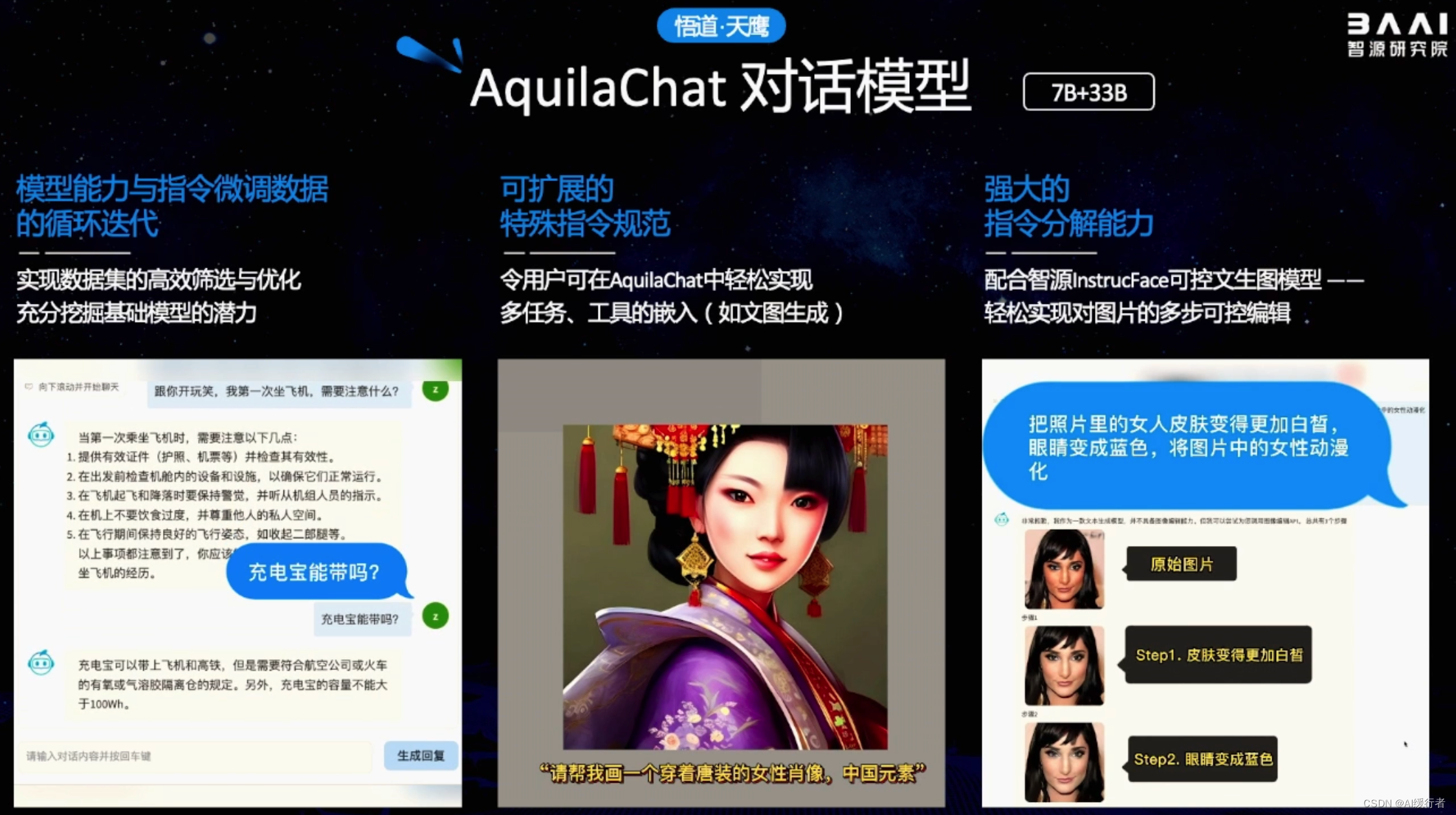
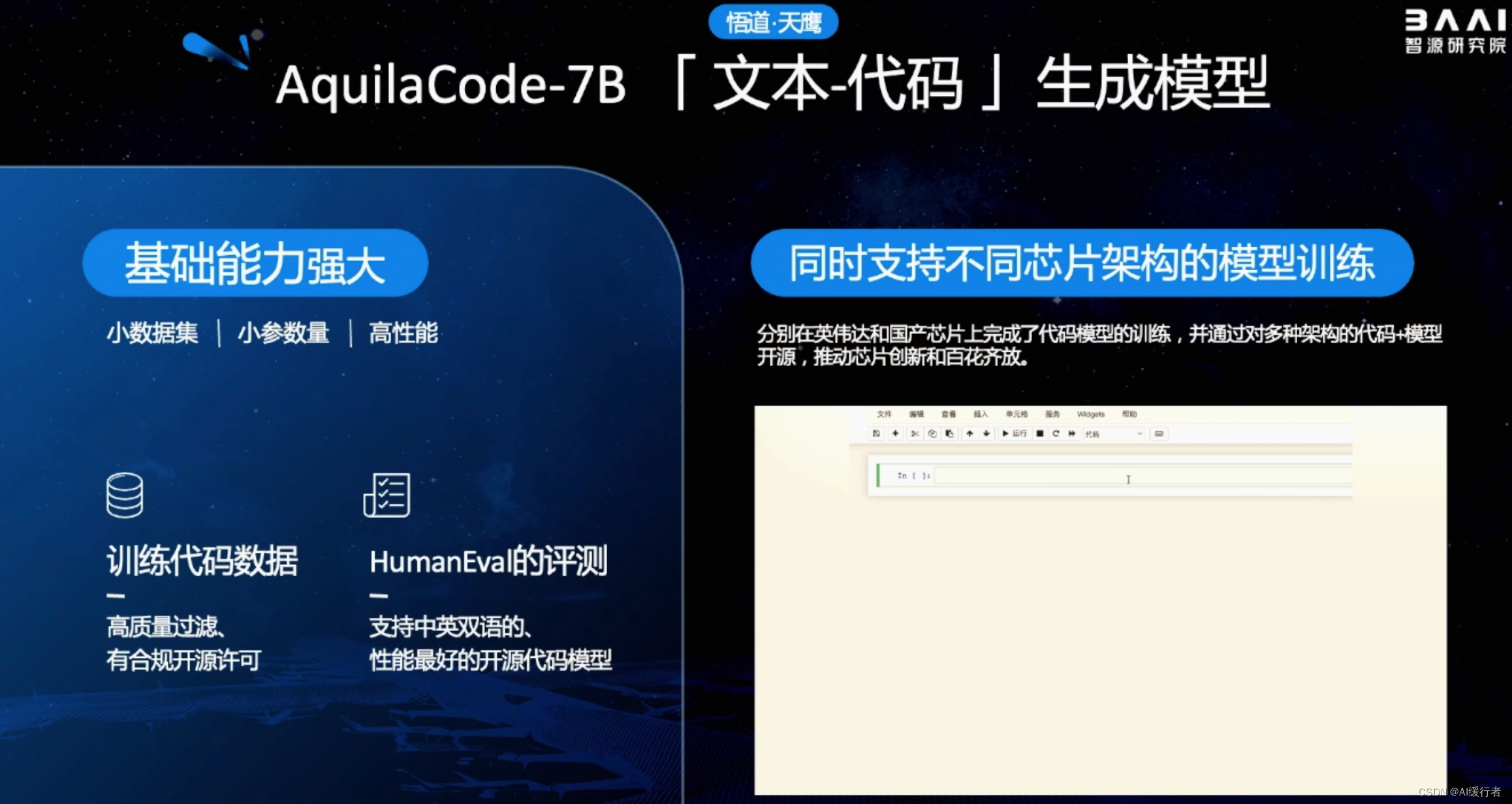
- 前面提及的模型升级
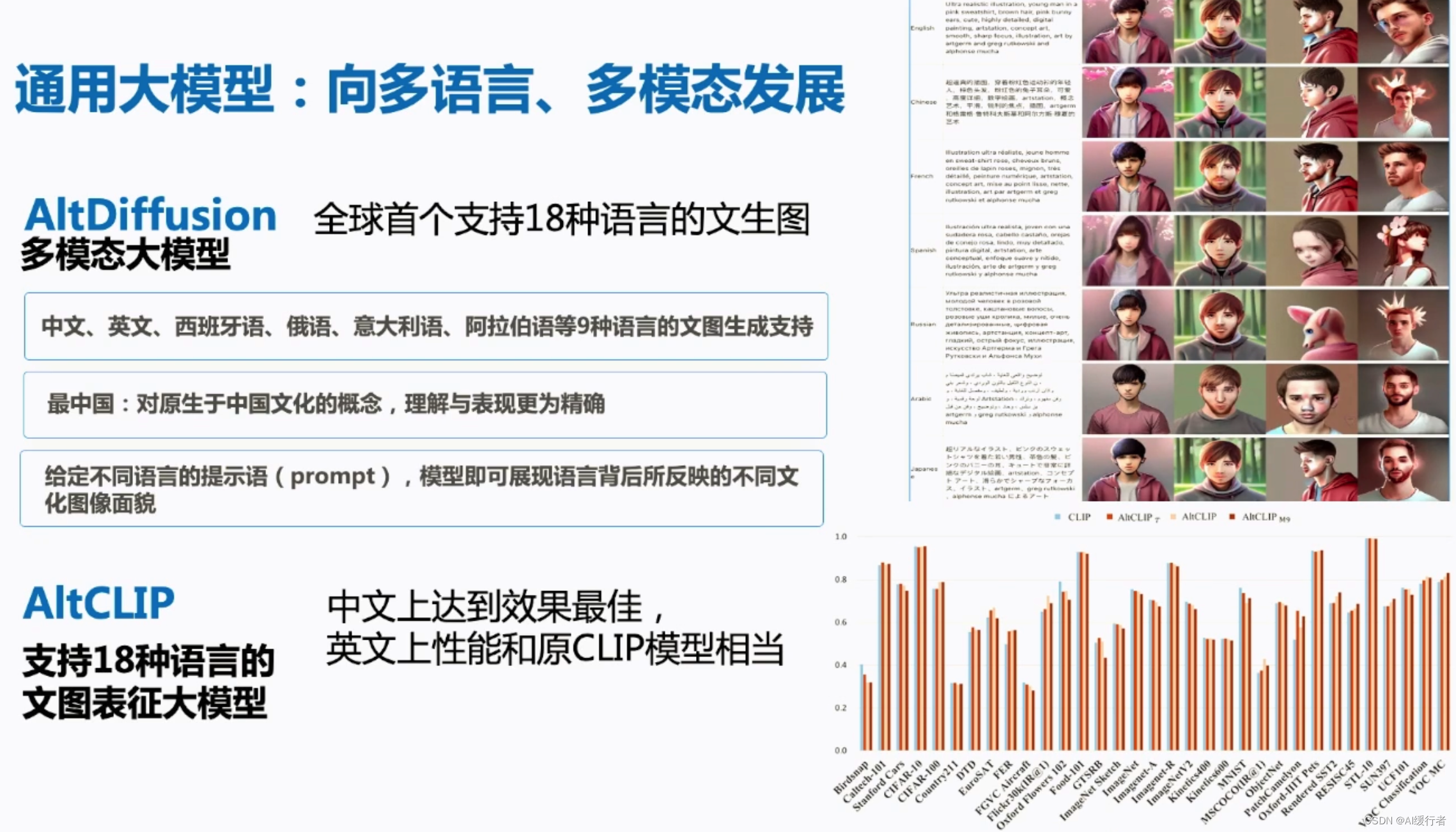
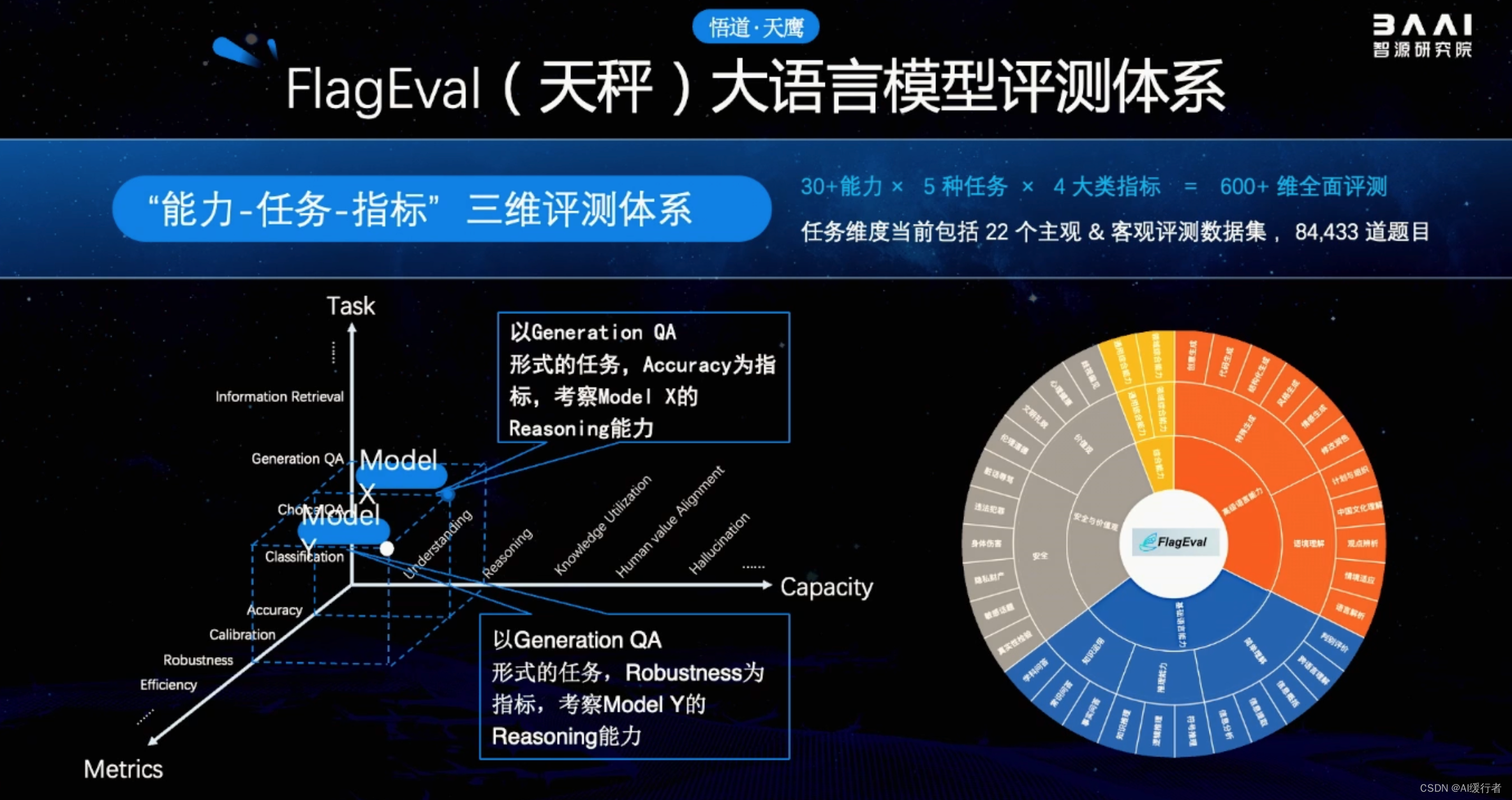
2. 大语言模型评测体系FlagEval
- 大语言模型评测体系FlagEval:






3. 大语言模型生态(软硬件)




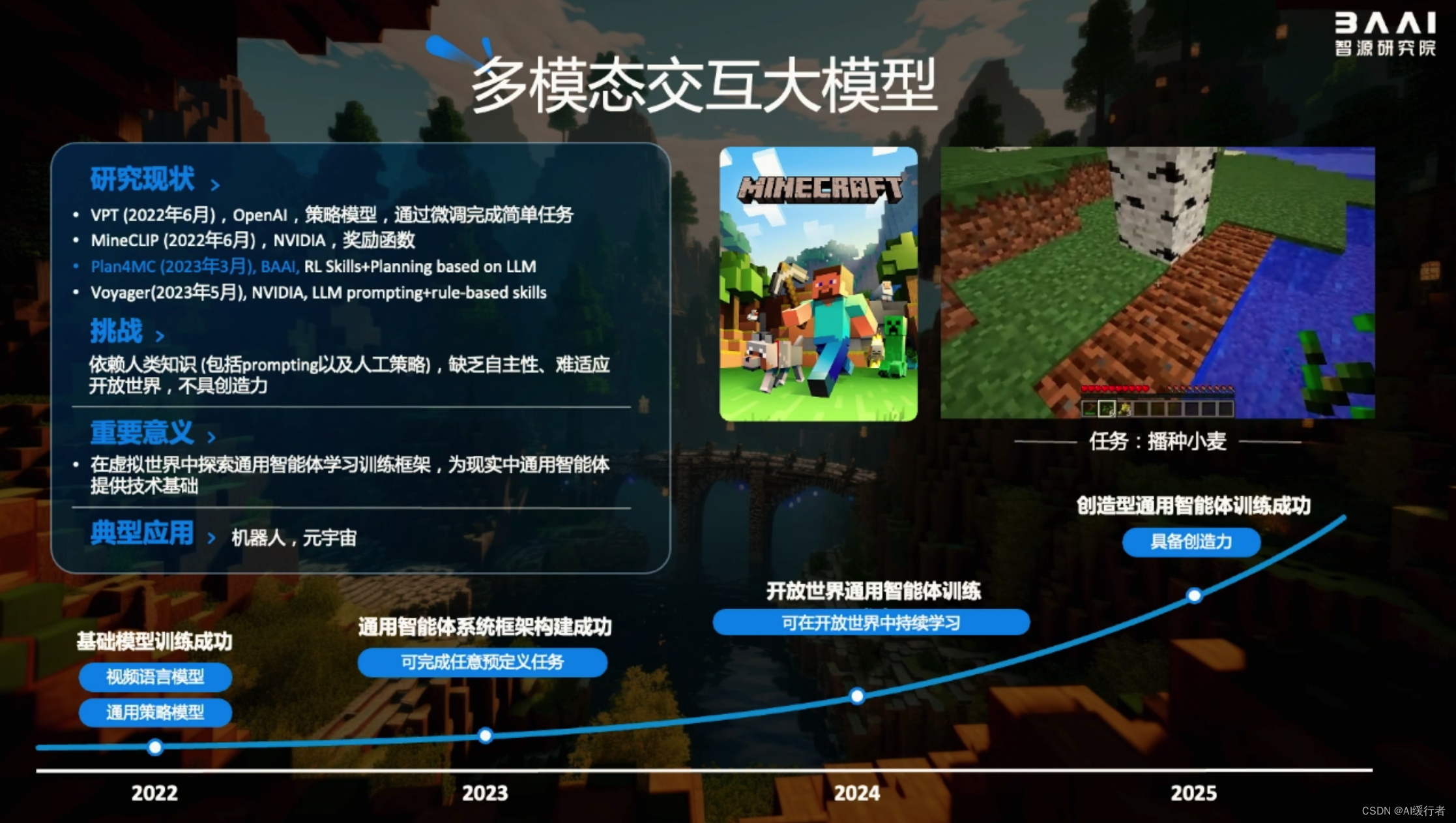
4. 三大路线通向 AGI(另外2条路径)



二. Towards Machines that can Learn, Reason, and Plan(杨立昆丨图灵奖得主)
- 图灵奖得主杨立昆:GPT模式五年就不会有人用了,世界模型才是AGI未来:https://mp.weixin.qq.com/s/a58hZLxo-1Hxlz5KvsJkBw
三. 基础大模型——工程化打造Al中的“CPU" | 林咏华 | 智源研究院副院长

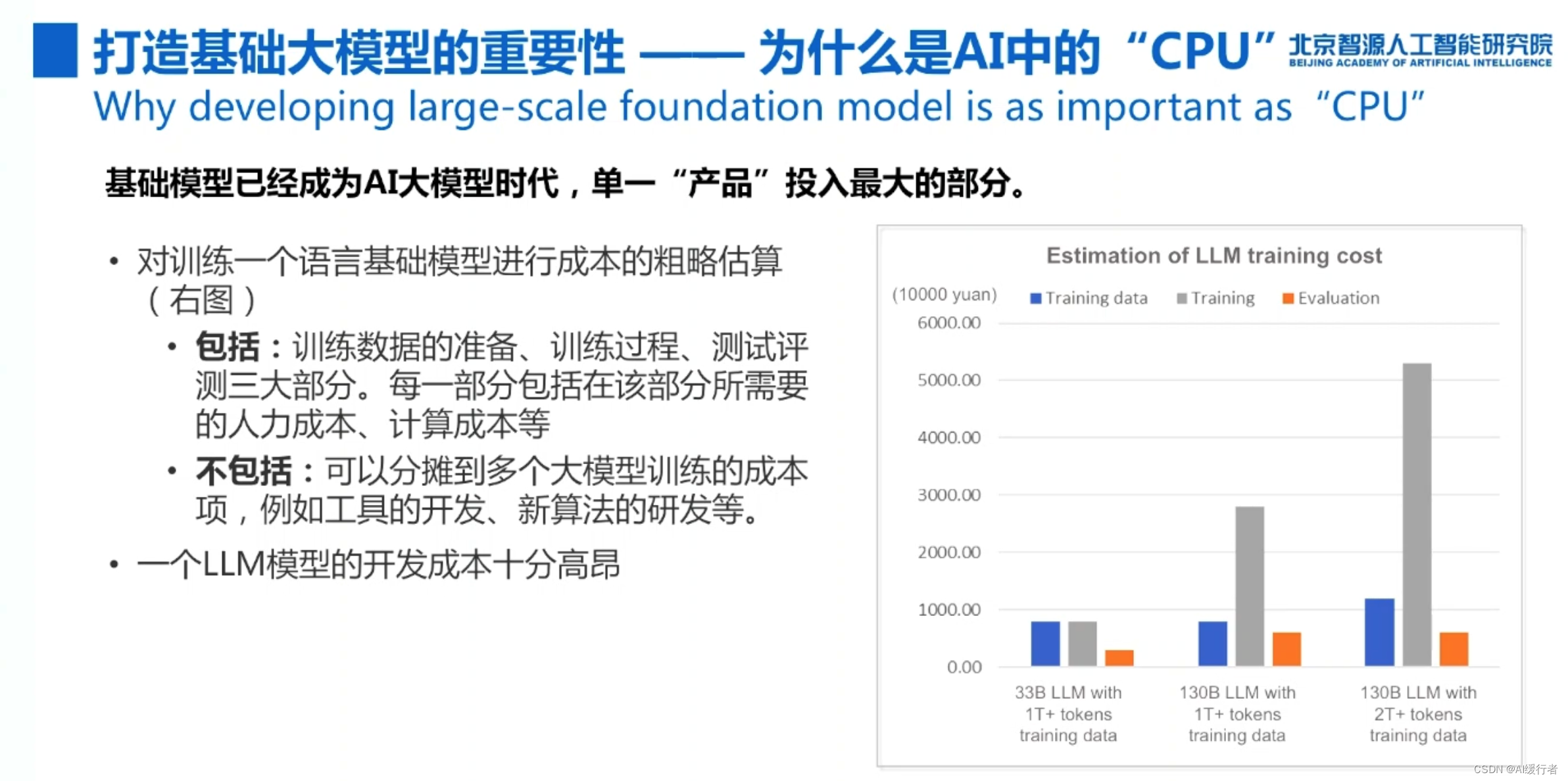


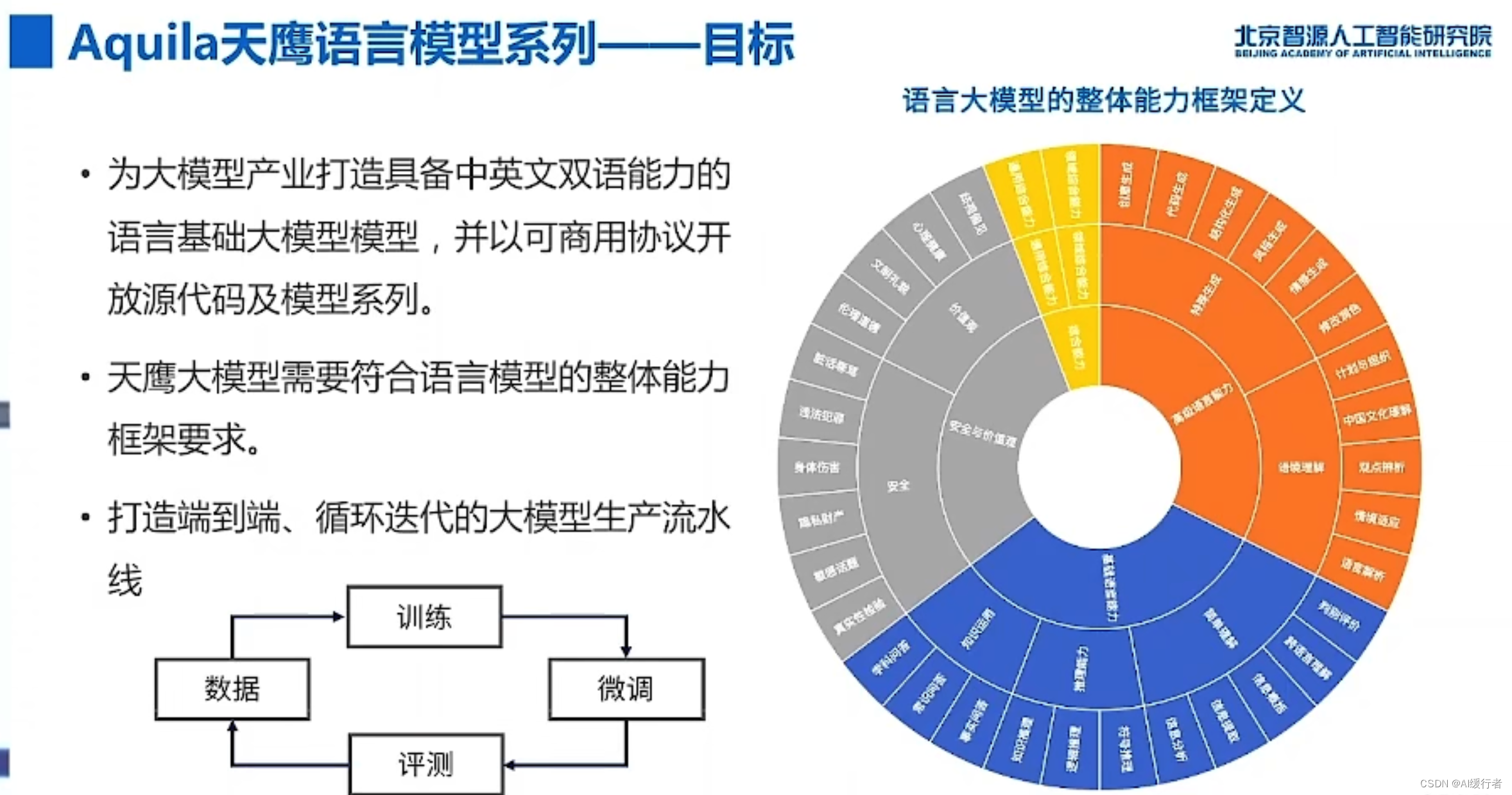
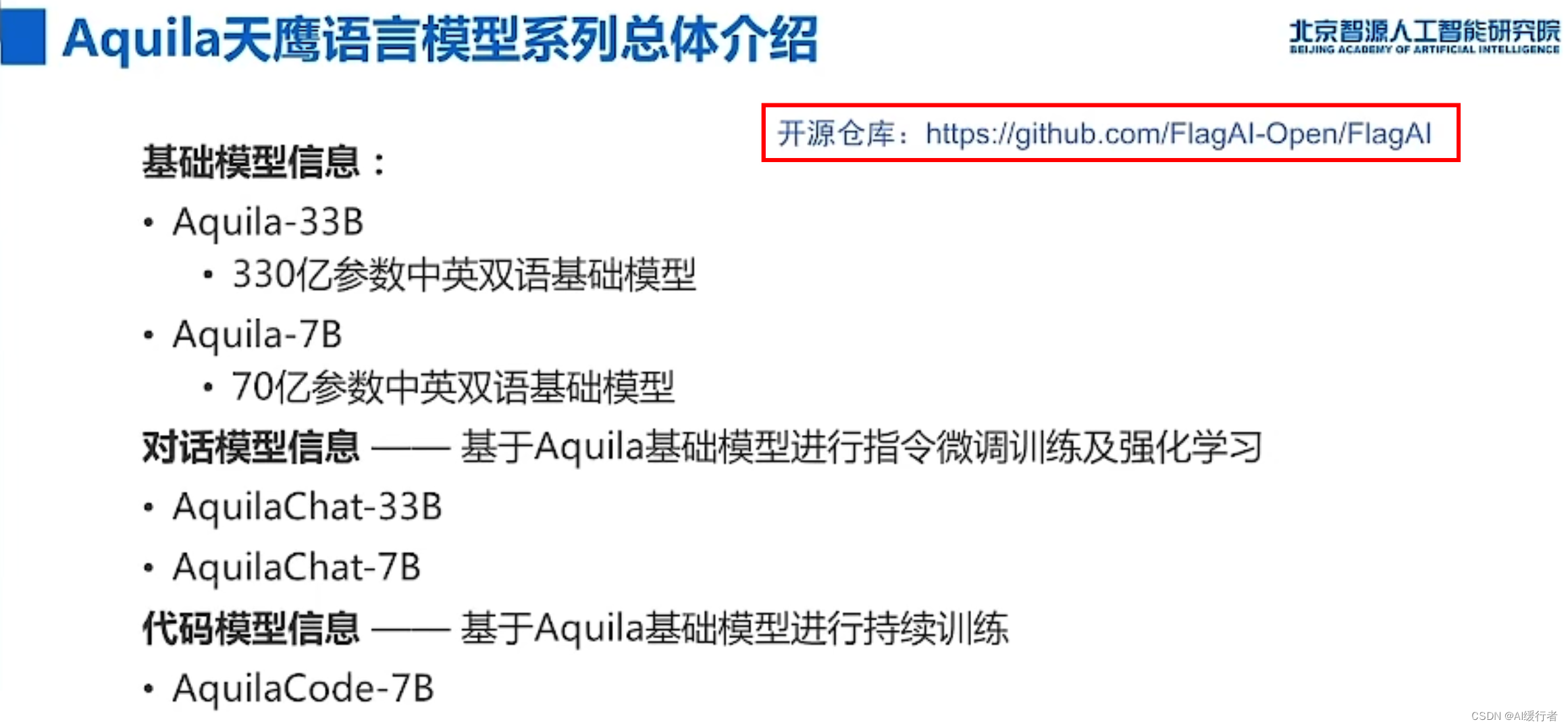
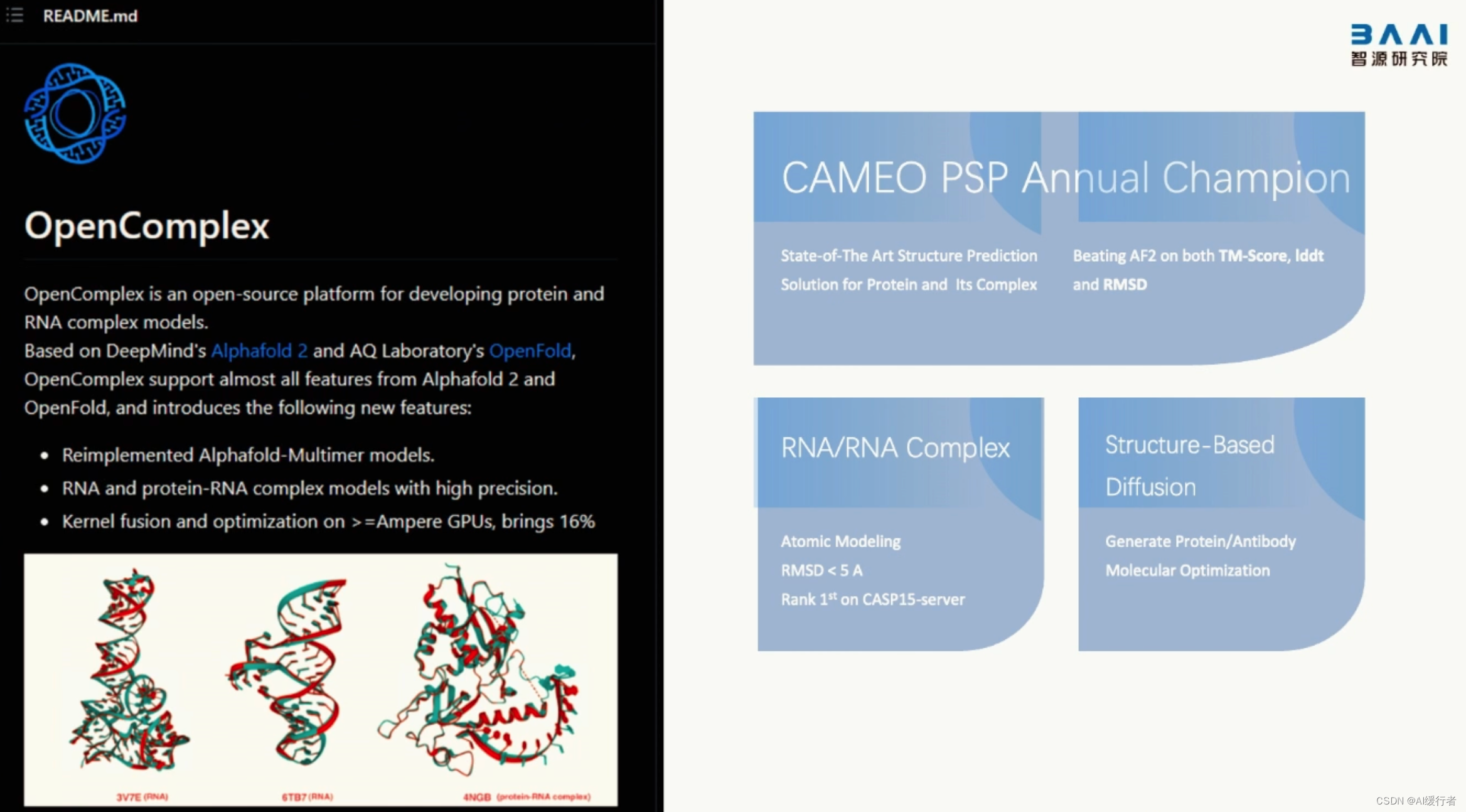
- AI:2023年6月9日北京智源大会演讲分享之基础模型前沿技术论坛—《工程化打造AI中的CPU》、《构建一个AI系统:在LLM上应用带有RLHF来推进定制》、《多模态预训练的进展回顾与展望》:https://blog.csdn.net/qq_41185868/article/details/131137542
四. Build an Al system: Applying Reinforcement learning withhuman feedback (RLHF) on LLM to advance customization

大语言模型近期取得了极大的突破,受到广泛关注。新的技术进步有效地提高了人们的生产力。然而, 如果我们想进一步提升其价值,还需要在个性化定制大语言模型上发力, 使其更贴切的输出我们想要的内容。我们需要建立这样一个产品:它可以高效地收集专业人士对大语言模型的反馈 (
humans-in-the-loop), 利用人类反馈的强化学习(RLHF)技术, 让大语言模型在不同领域变得更专业化。
- 构建一个人工智能系统:在LLM上应用带有人类反馈的强化学习(RLHF)来推进定制
- 14:05-14:50—《Build an Al system: Applying Reinforcement learning withhuman feedback (RLHF) on LLM to advance customization构建一个人工智能系统:在LLM上应用带有人类反馈的强化学习(RLHF)来推进定制》:https://blog.csdn.net/qq_41185868/article/details/131137542
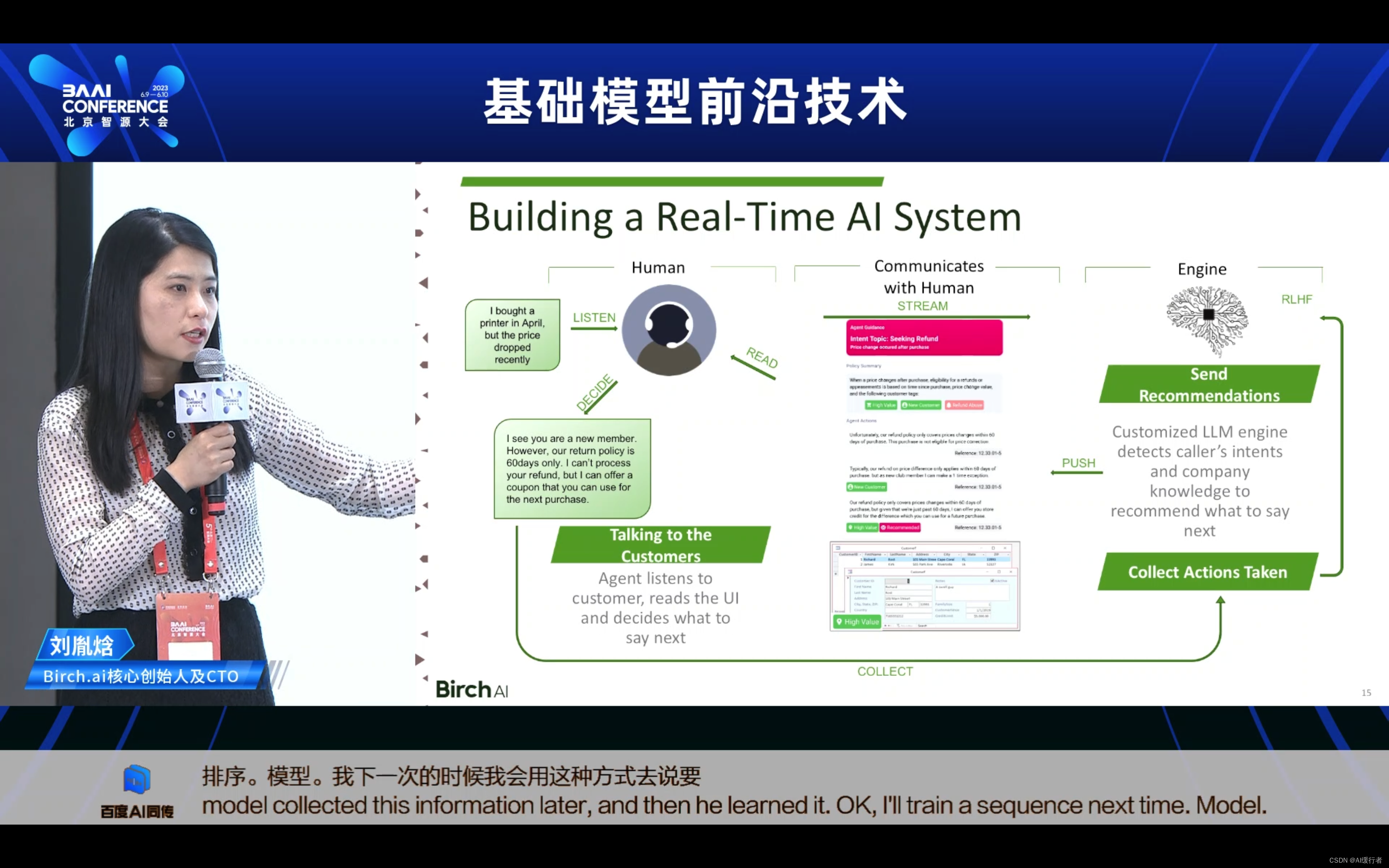
- Building a Real-Time Al System:如何利用大语言模型,人类的反馈信息搭建一个实时的系统?来收集反馈信息,去train更好的model,这是一个很贴近生活的例子 。
- 一个客户打电话说,4月份的时候买了1个打印机,然后呢现在降价了,然后这个时候接话员会做两件事情。第一件事,我要调出这个客户的信息,确定他确实在4月份购买了商品。然后我要看这个客户他是一个什么样的客户,他的消费频率是什么?他是不是会员,他每次消费的额度是多少?当我确定这是一个非常高价值的客户,我想让他开心,我像留住他,想让他持续的在这里消费。第二件事这个接听员要去查一下公司内部的政策,那公司的退款政策是什么?可能是60天内降价可以退款,但是60天以后就不可以退款,那结合这2者信息,接线员做出最后的决定,首先先抑后扬,60天退款政策已经过了不能退款,但是你非常的特别,我们为了你愿意更该政策,所以我们决定给你一个代金券,你可以下次使用。
- 这个情况下,大语言模型会做到什么样的应用呢?首先大语言模型有聆听这段对话,大语言模型语义理解根据交流谈话判断出事退款的想法,同时它又走到database中,查询出客户是1个高质量的客户。结合这两种信息,大语言模型推荐给接话员一个回应,可以给一个代金券供下次使用。接线员采纳了大语言模型的推荐,我不可以退款,但是可以给一个代金券,但是他用一种更愉悦的方式传达出了这份信息,让客户更开心。这个时候大语言模型会在后面收集到了这份信息,然后他学会了下次去训练一个排序模型,我下一次的时候会用这种方式去说,这种方式会让客户更满意,这个时候会进行强化学习,收集这些信息。
五. 多模态预训练的进展回顾与展望丨中科院自动化所研究员丨刘静
- 14:50-15:35—多模态预训练的进展回顾与展望刘静:https://blog.csdn.net/qq_41185868/article/details/131137542

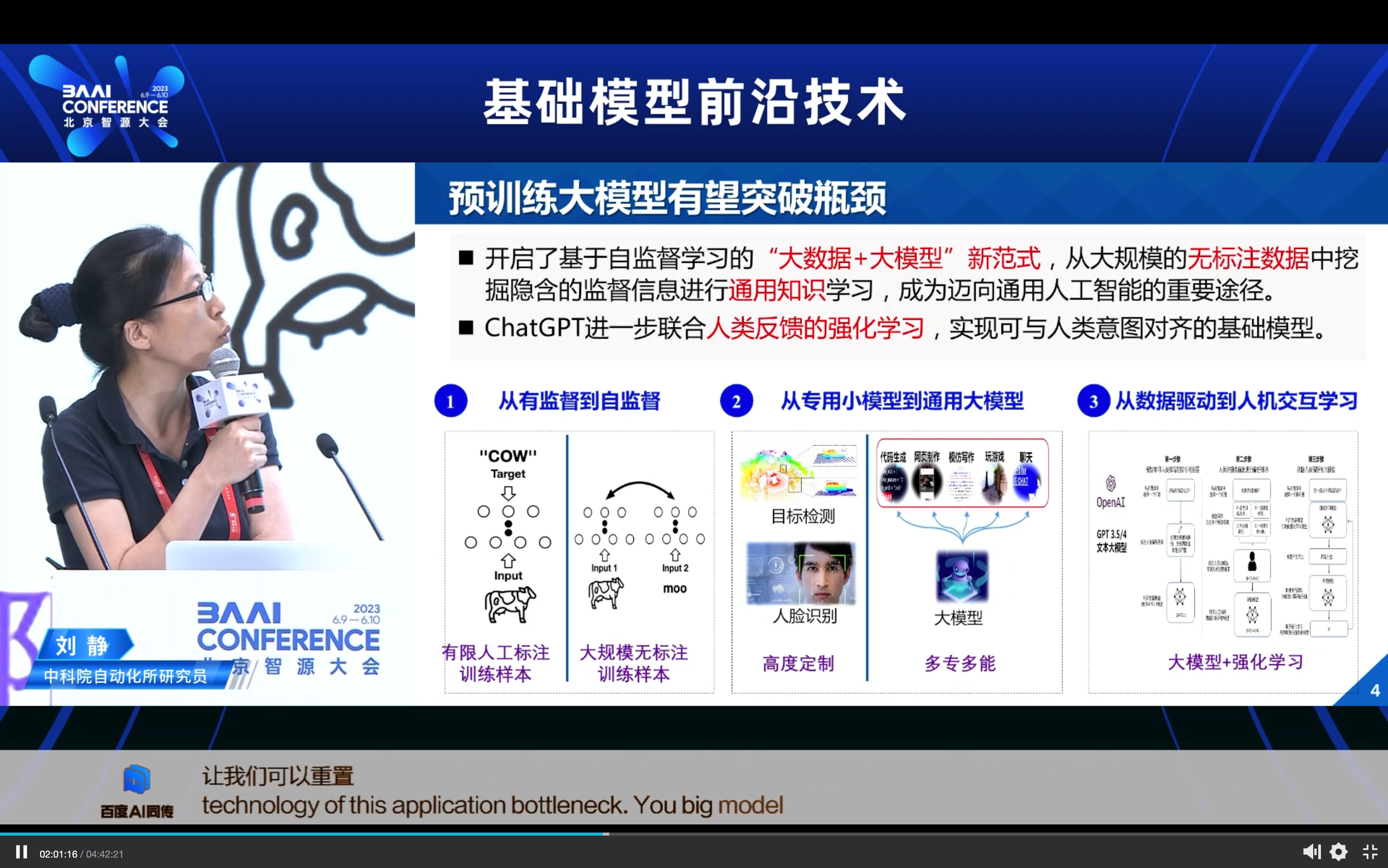
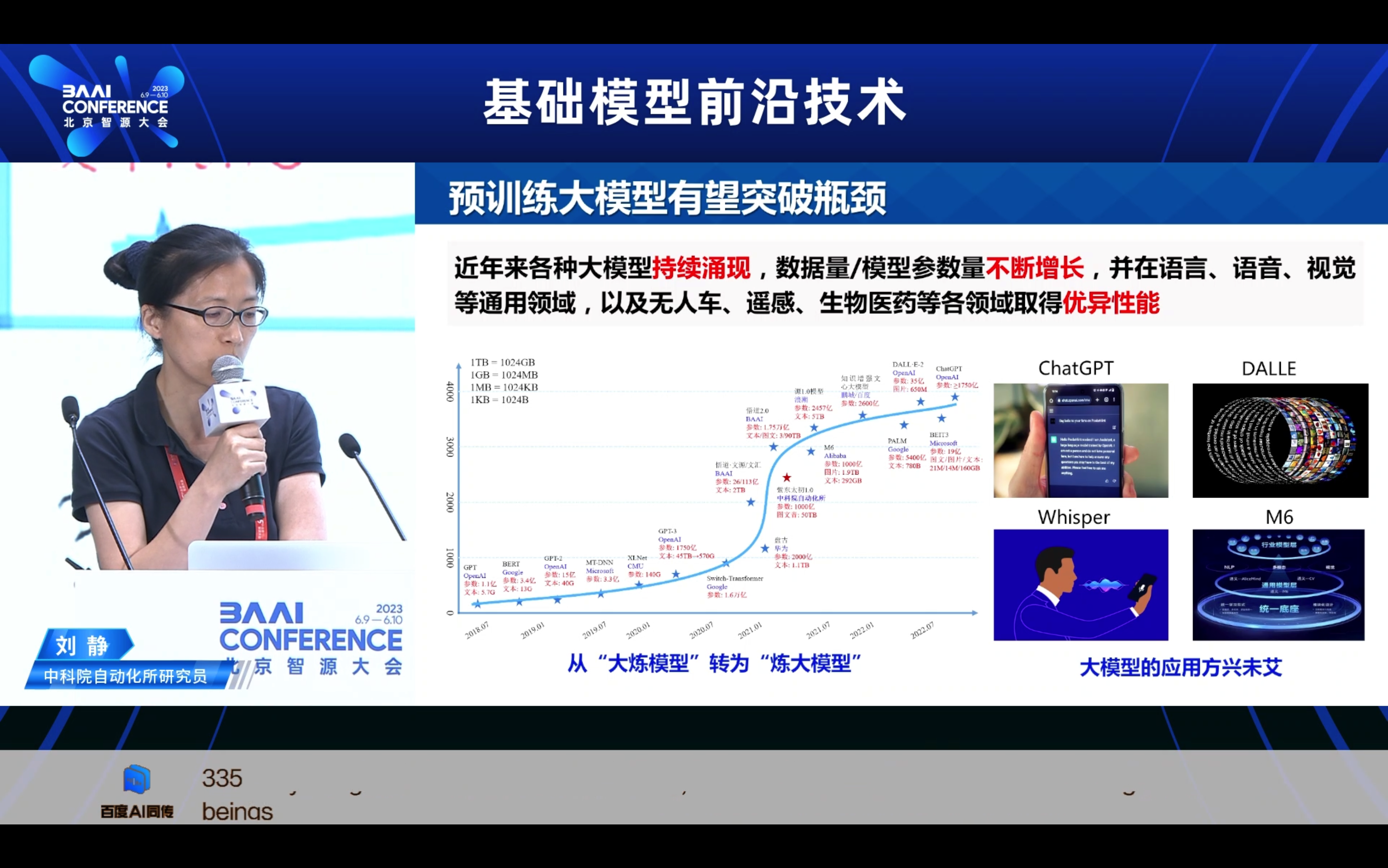
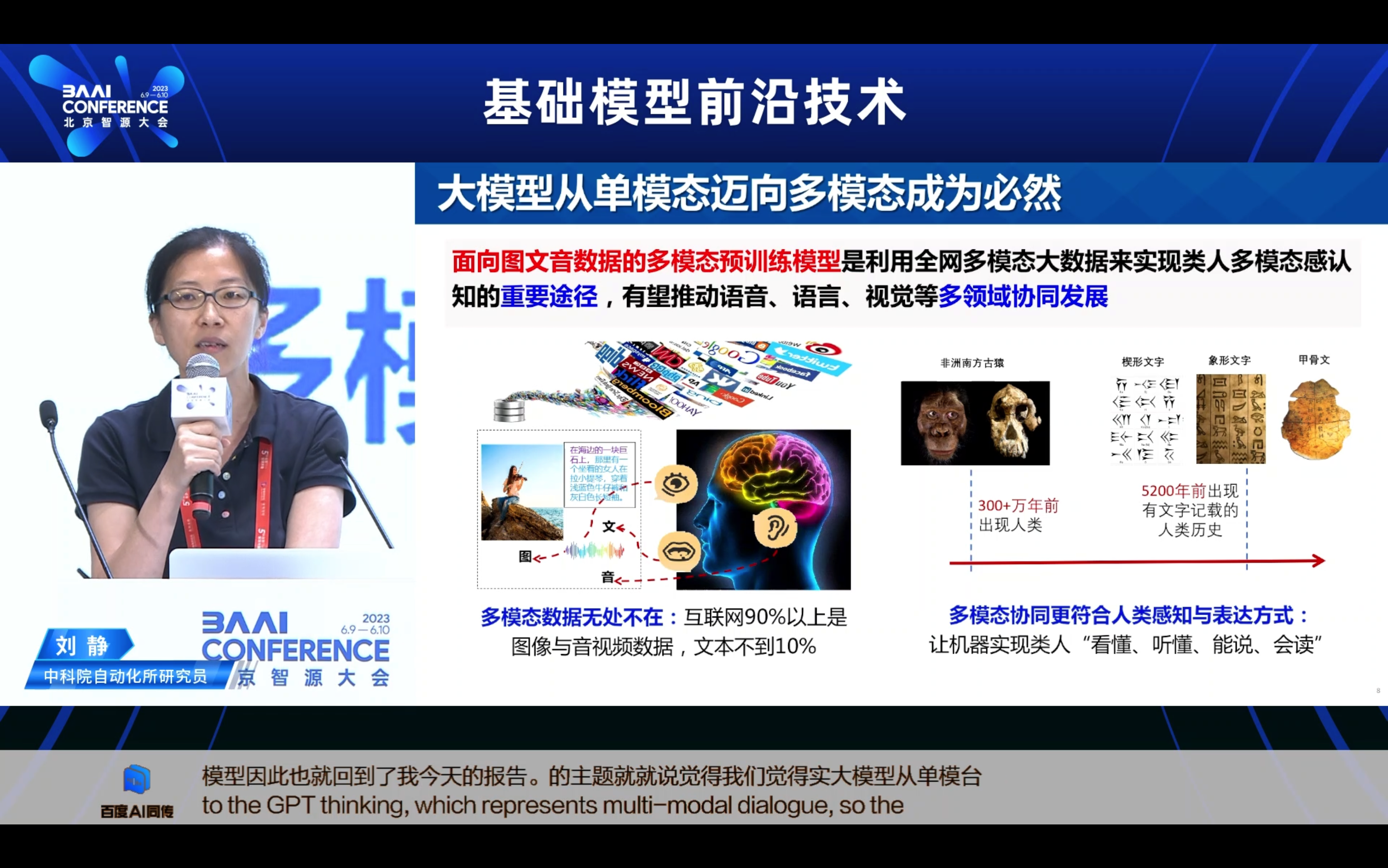
近年来,从预训练模型到预训练大模型,从文本、音频、视觉等单模态大模型,到现在的图文、图文音等多模态预训练大模型,无论在学术界还是企业界预训练模型都得到了广泛关注与爆发式发展。多模态预训练通过联合图文音等多模态内容进行模型学习,其发展在多模态理解、搜索、推荐、问答,语音识别与合成,人机交互等应用领域中具有潜力巨大的市场价值。本报告主要包含三方面内容:分析多模态预训练模型的重要性与必要性;回顾当前多模态预训练的最新研究进展;多模态预训练模型主要应用场景与未来展望。
1. 多模态预训练的研究背景一为什么关注?




2. 多模态预训练的研究进展 一 当前怎么做?
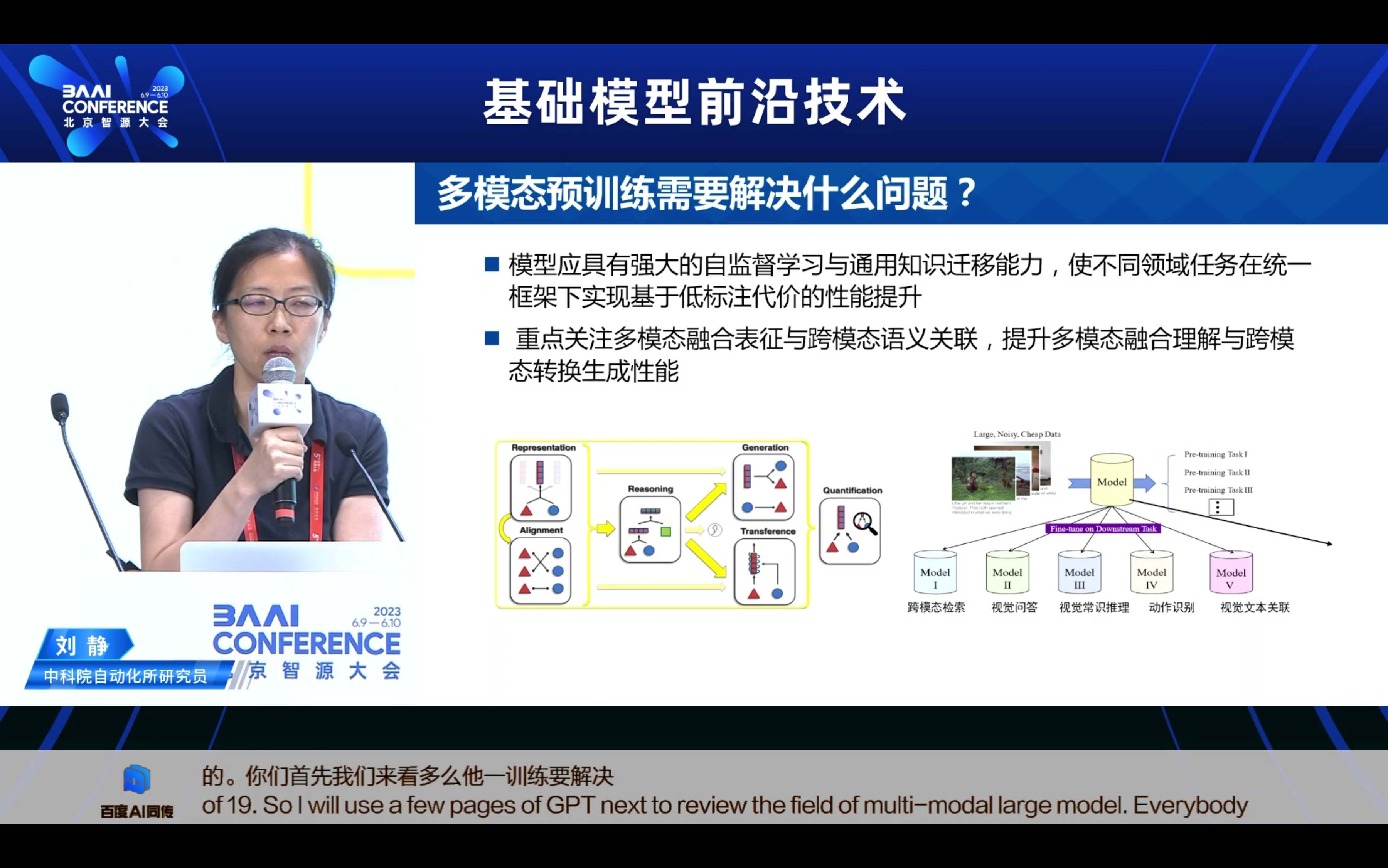
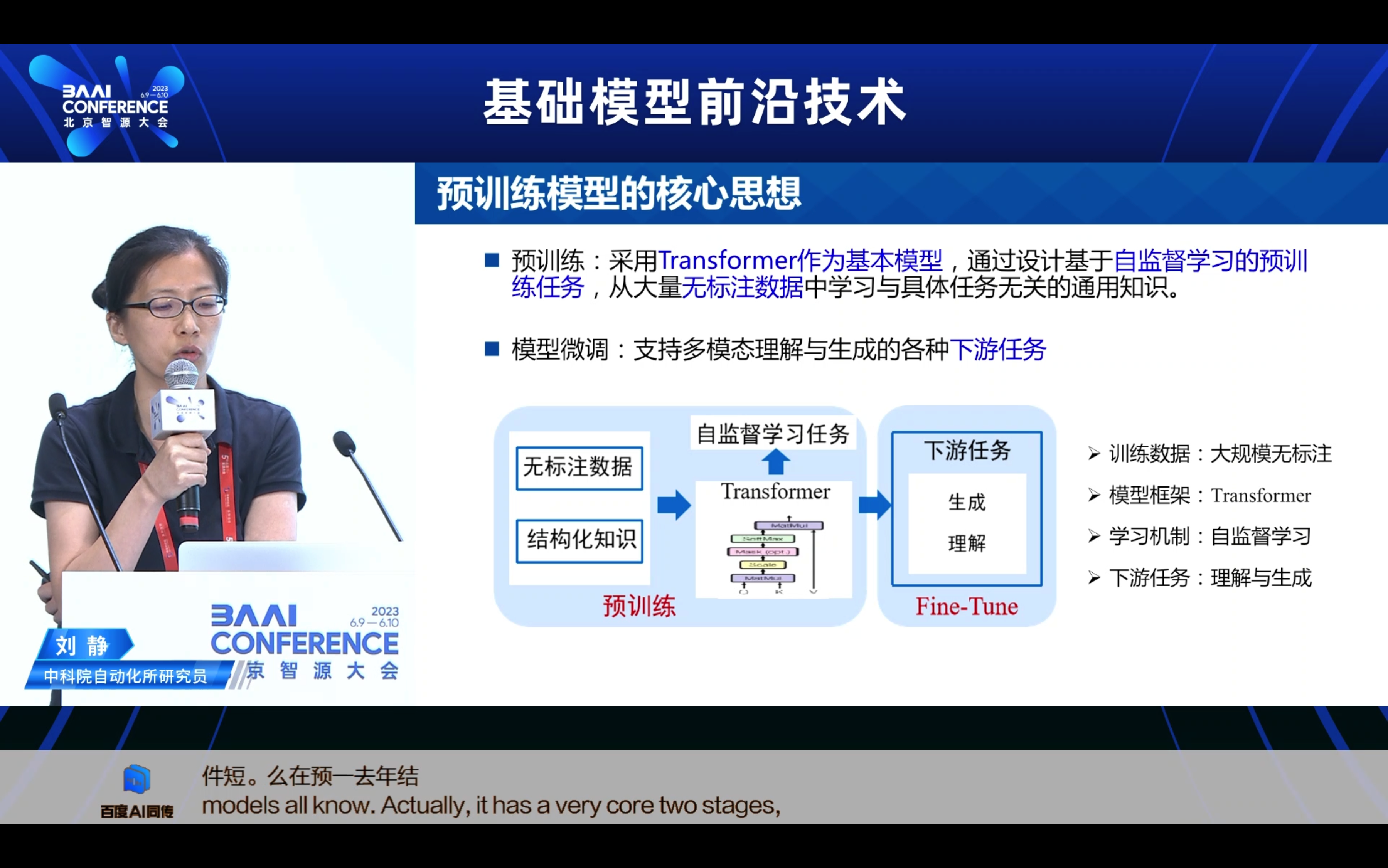


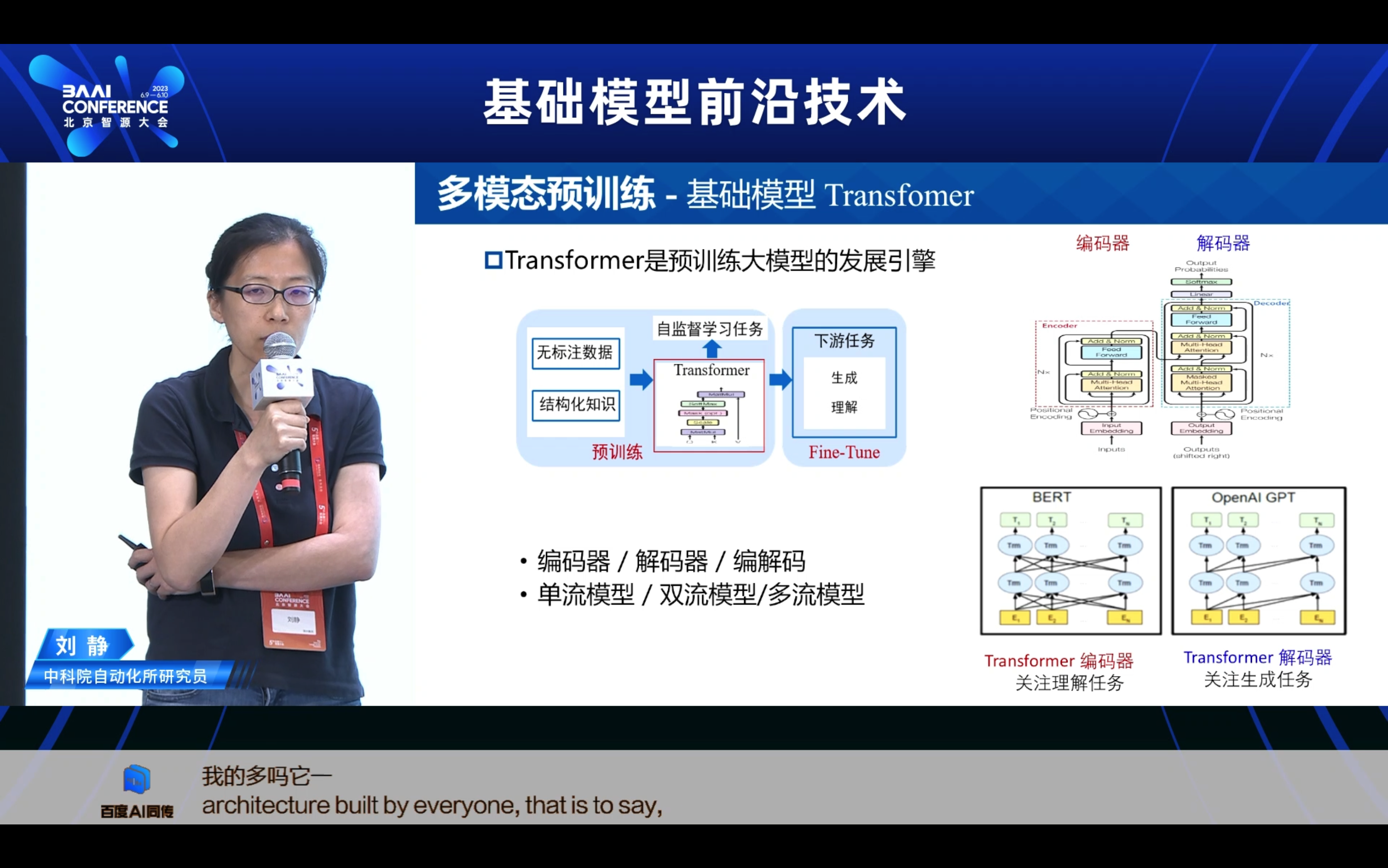
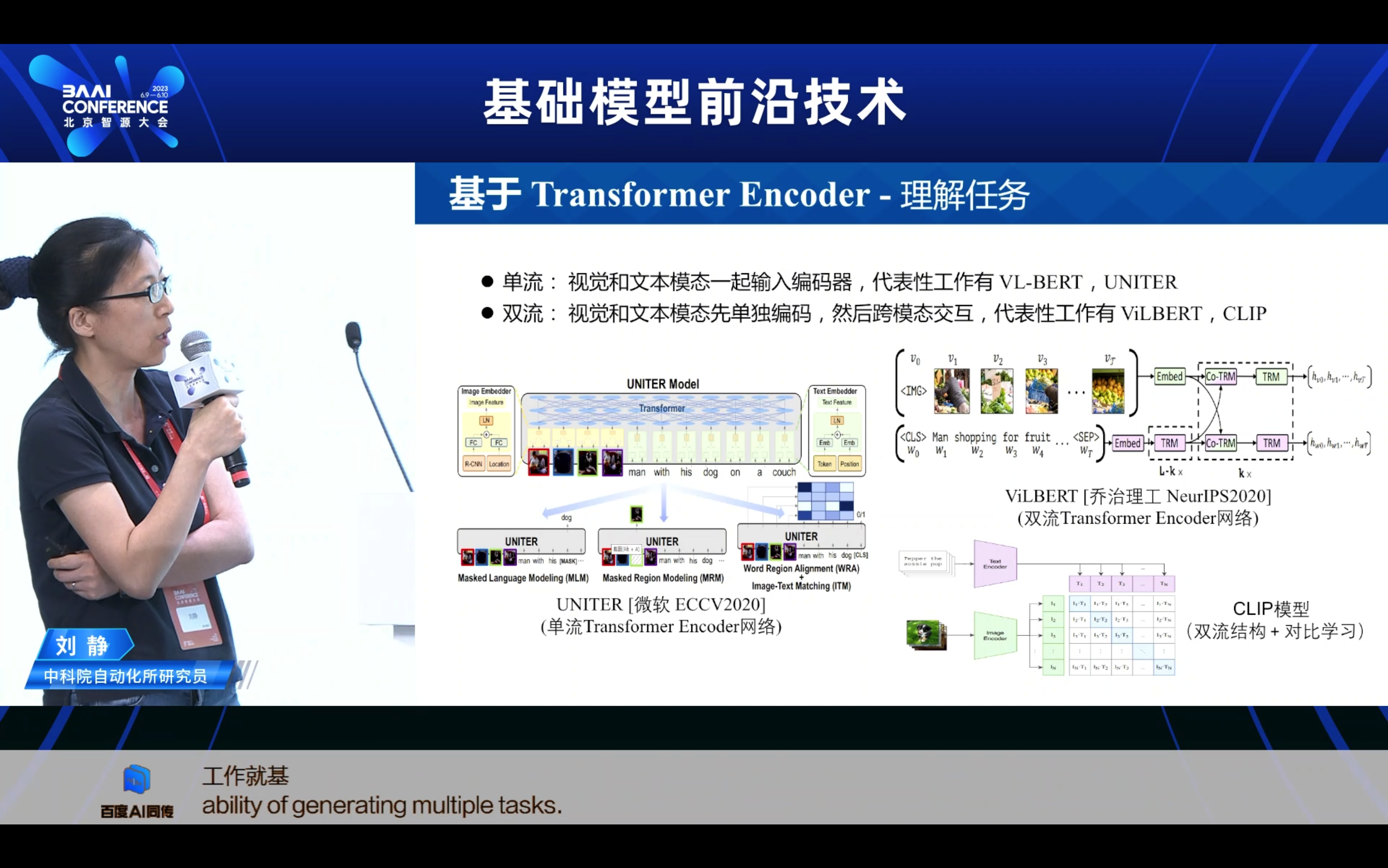


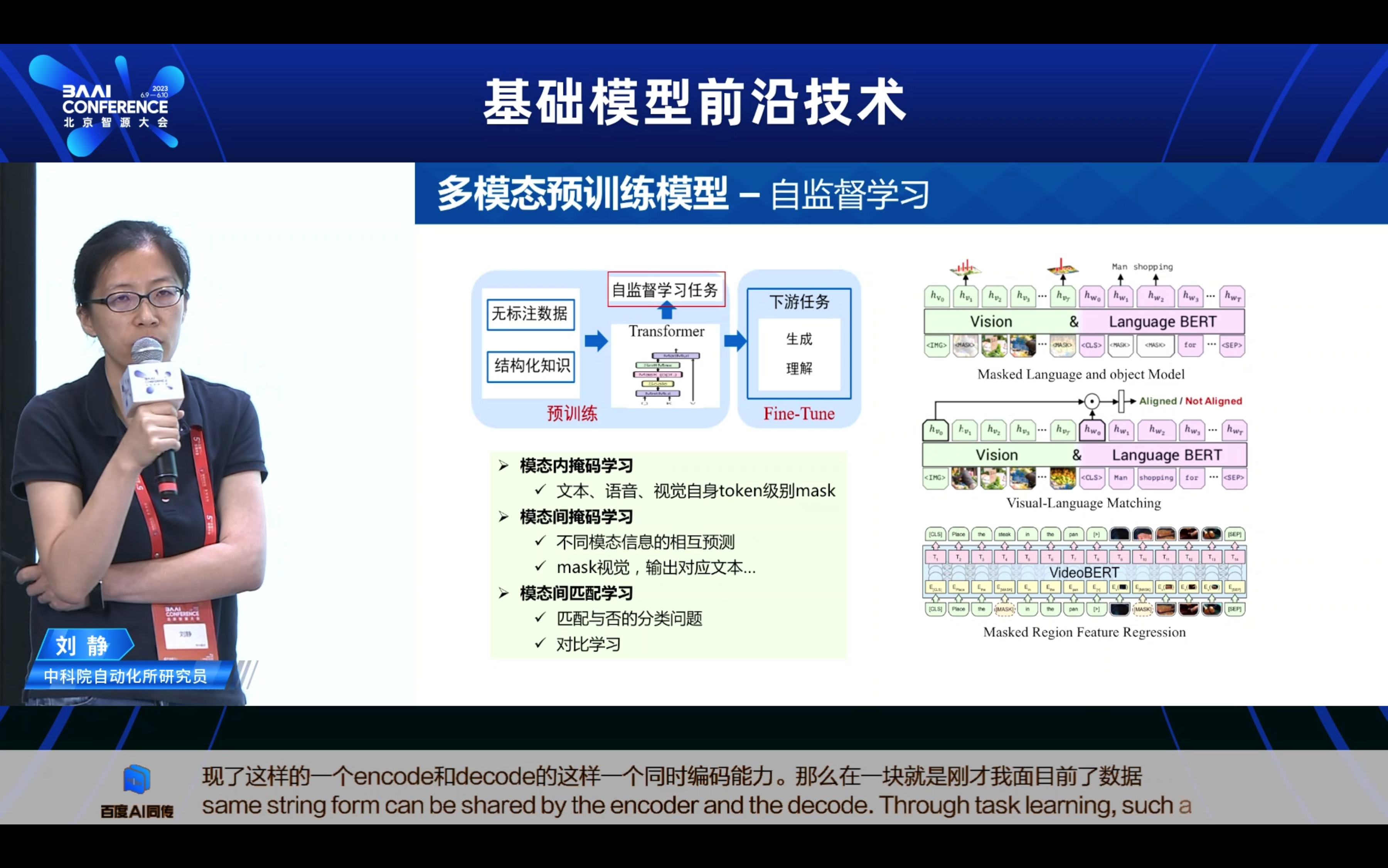
- 模型如何迁移适配到下游任务? 这里的研究范式又分为几个阶段,从最早期的Pretraining + Finetune,也就是通过下游任务的小样本全监督的学习,来实现这样一个的全参数的微调。随着模型规模越来越大,比如百亿千亿万亿,那我其实在少量的这样的下游任务数据上,其实经很难全监督的微调了。因此业内大家就想怎么够去更高效,低代价的去微调这样的模型又变为了一个重要的方向,因此业内不断提出包括Prompt-Tuning、Adaptor-Tuning、LORA,希望去实现这种低代价的这样的一种增量式的微调。
- 希望模型在微调的过程中,既不要忘记它大模垫该具备的能力,同时能够很好的去适配下午任务,从而实现增量的学习。
- 另外一块,多模态下游任务可想象的空间是非常大的,简单理解下游任务都是生成类和理解类。





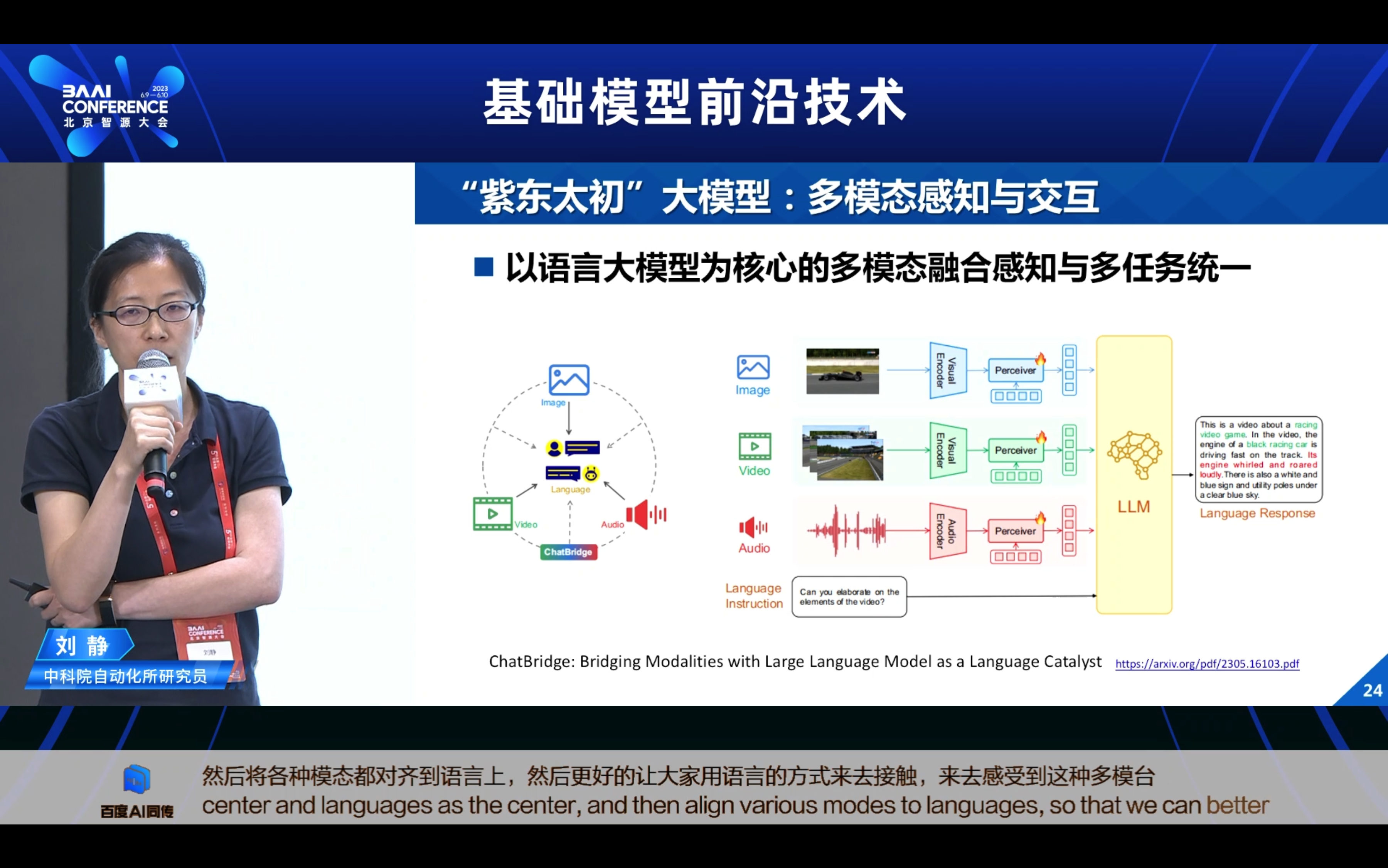




3. 多模态预训练的几点思考一以后怎么做?







六. Scaling Large Language Models: From Power Law to Sparsity丨谷歌研究科学家丨周彦祺

深度学习的模型容量和训练时间的加倍均可导致模型质量的线性提升,这个被堪称新摩尔定律的Power Law直接促使了各大科技公司在模型容量和训练时长上的军备竞赛(
e.g T5, Megatron, PaLM, GPT, etc.) 该讲座将围绕大语言模型的scaling展开,深入浅出的讨论如何用mixture-of-experts方法在不增加运算量的前提下提高模型的容量,以及如何用AutoML搜索出一款最适配目标硬件的的稀疏模型来。
- LLM缩放:从幂律到稀疏性


1. Moore’s Law and Power Law(摩尔定律和幂律)
- 戈登·摩尔提出,在给定空间中可以装入的晶体管数量每两年翻一番。现在我们正接近摩尔定律的物理极限,因为晶体管的高温使得创建更小的电路成为不可能。当然,芯片的性能不仅受到晶体管的限制,还受到内存带宽(内存墙)等其他原因的限制。
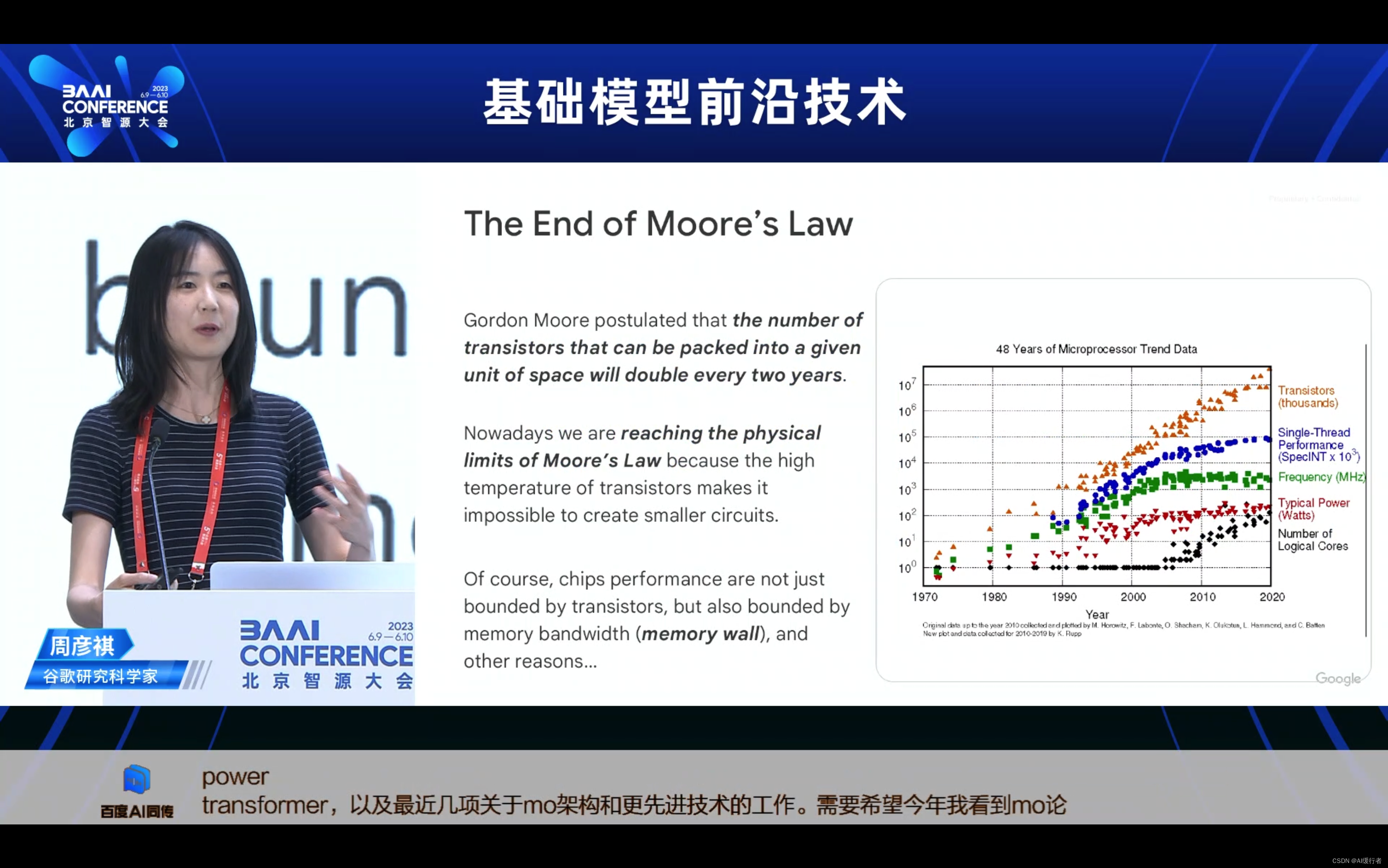
- 幂律规则深度学习

- 通过统一的文本到文本转换器探索迁移学习的极限

2. T5: Unified Text-to-Text Transformer T5(统一的文本到文本转换器)
- 文本到文本的简单运作,将每个问题都定义为以文本作为输入并生成文本作为输出。

- C4 Dataset:
- 从公开可用的Common Crawl获取源数据,这是一个网络爬取的数据集。
- Common Crawl包含很多嘈杂的“网页提取文本”
- 数据集在外部是完全可用和可再现的。
- 应用大量的过滤:
- 删除不以. , ! " … 结尾的行
- 删除短行
- 删除带有不良短语(例如冒犯性词语,“服务条款”,"lorem ipsum"等)的行
- 在文档之间进行句子级去重复
- 等等
- 生成约750 GB的干净英文文本+其他语言中的大量文本。

- Experiment实验: 我们选择参数和策略,以尽可能简化流程。

- Objective目标

- Model Architectures模型架构: 深灰色线表示完全可见掩码,浅灰色线表示因果掩码。

- Comparing High Level Approaches for UnsupervisedObjectives对无监督目标的高级方法进行比较

- What should you do with 4x compute? 有了4倍的计算能力应该做什么? 更长时间的训练、训练更大的模型和集成都可以提供性能上的正交增强

- Scalling Up: 扩展
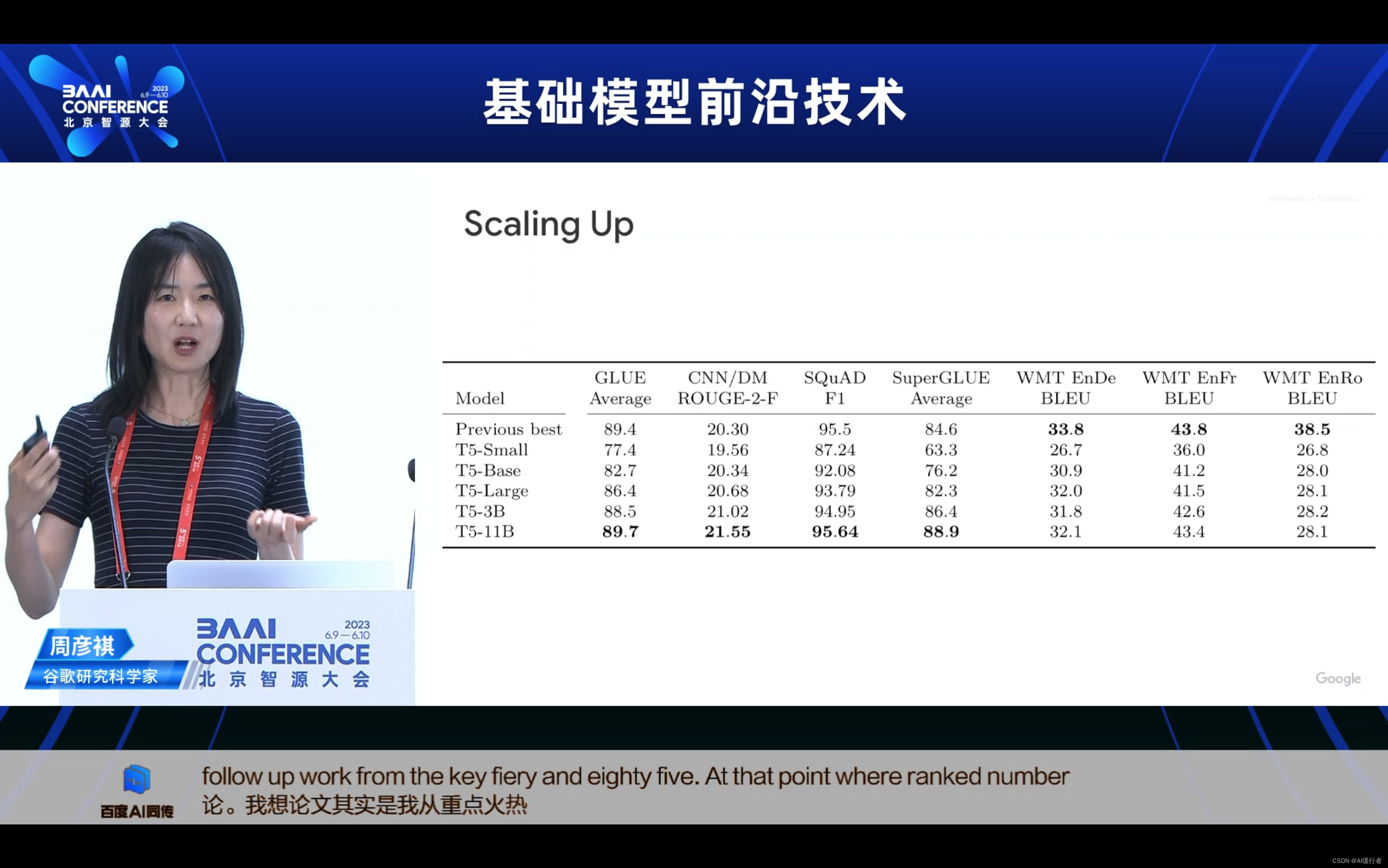
- Hitting and End of Dense Model Scaling:密集模型扩展的极限

3. Scaling LLM with MoE(使用MoE扩展LLM)

- Hitting an End of Dense Model Scaling(达到密集模型扩展的极限)
- “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts", Nan Du and others, ICML 2022.
- “GLaM:用混合专家的方式有效扩展语言模型”,Nan Du等人,ICML 2022。

- Efficient Scaling of Language Models with MoE(使用MoE进行高效扩展语言模型)
- 仅解码器
- ln-context少样本学习
- 使用GShard Top2路由的稀疏门控网络
- 总参数量扩展到1.2T,激活参数量为970B

- GLaM Model Architecture(GLaM模型架构)
- 稀疏激活的前馈神经网络
- GShard Top2门控函数
- 将密集层与稀疏层交替排列。

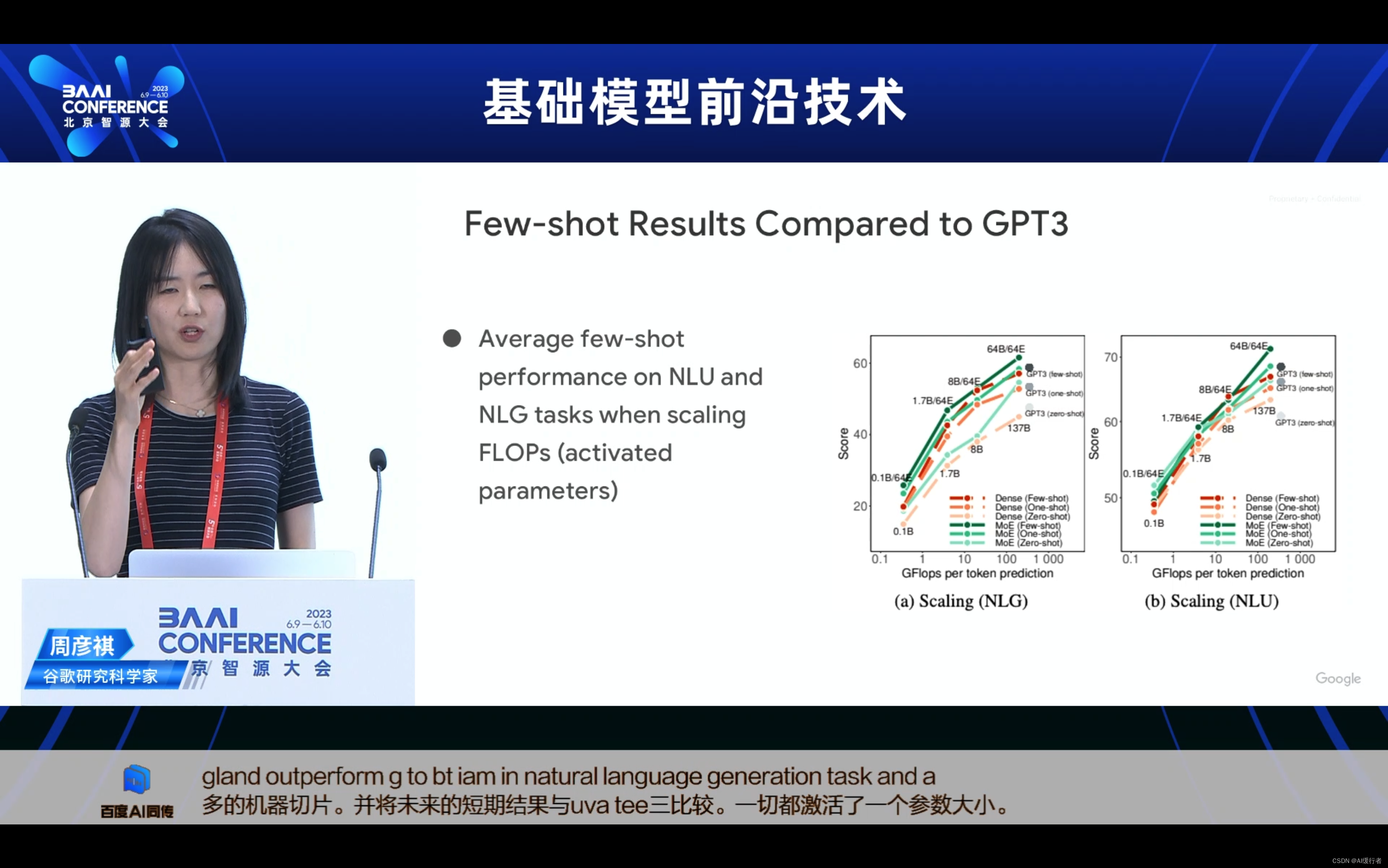
- Few-shot Results Compared toGPT3(与GPT3相比的少样本结果)
- 在缩放FLOPs(激活参数)时的NLU和NLG任务的平均少样本性能
- Token-Based MoE hasLimitations…(基于标记的MoE有局限性…)

- MoE with Expert Choice Routing(具有专家选择Routing的MoE)
- 每个专家独立选择前k个标记。
- 完美的负载均衡
- 标记可以由可变数量的专家接收。

- Expert Choice Gather(专家选择聚合)

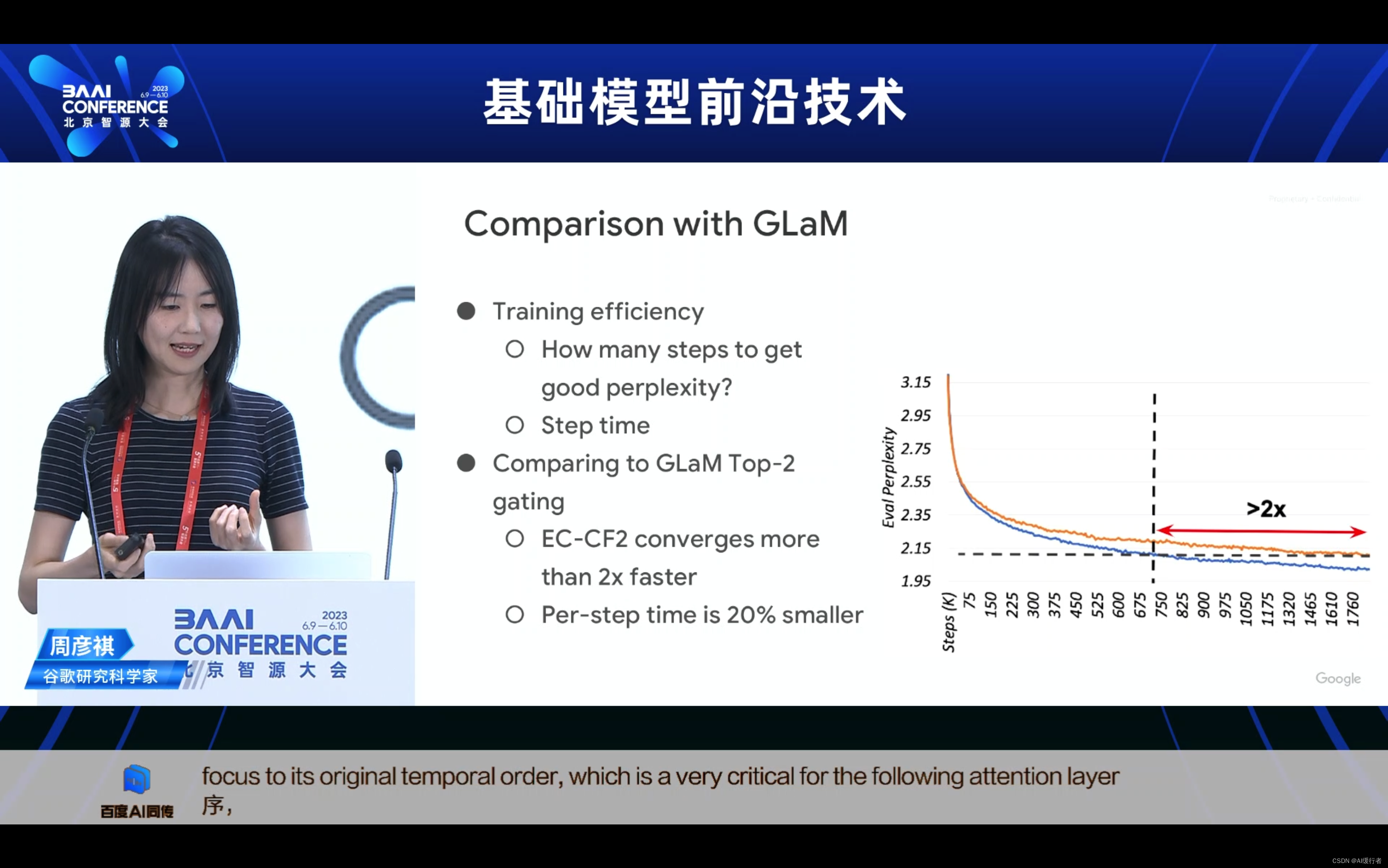
- Comparison with GLaM 与GLaM的比较
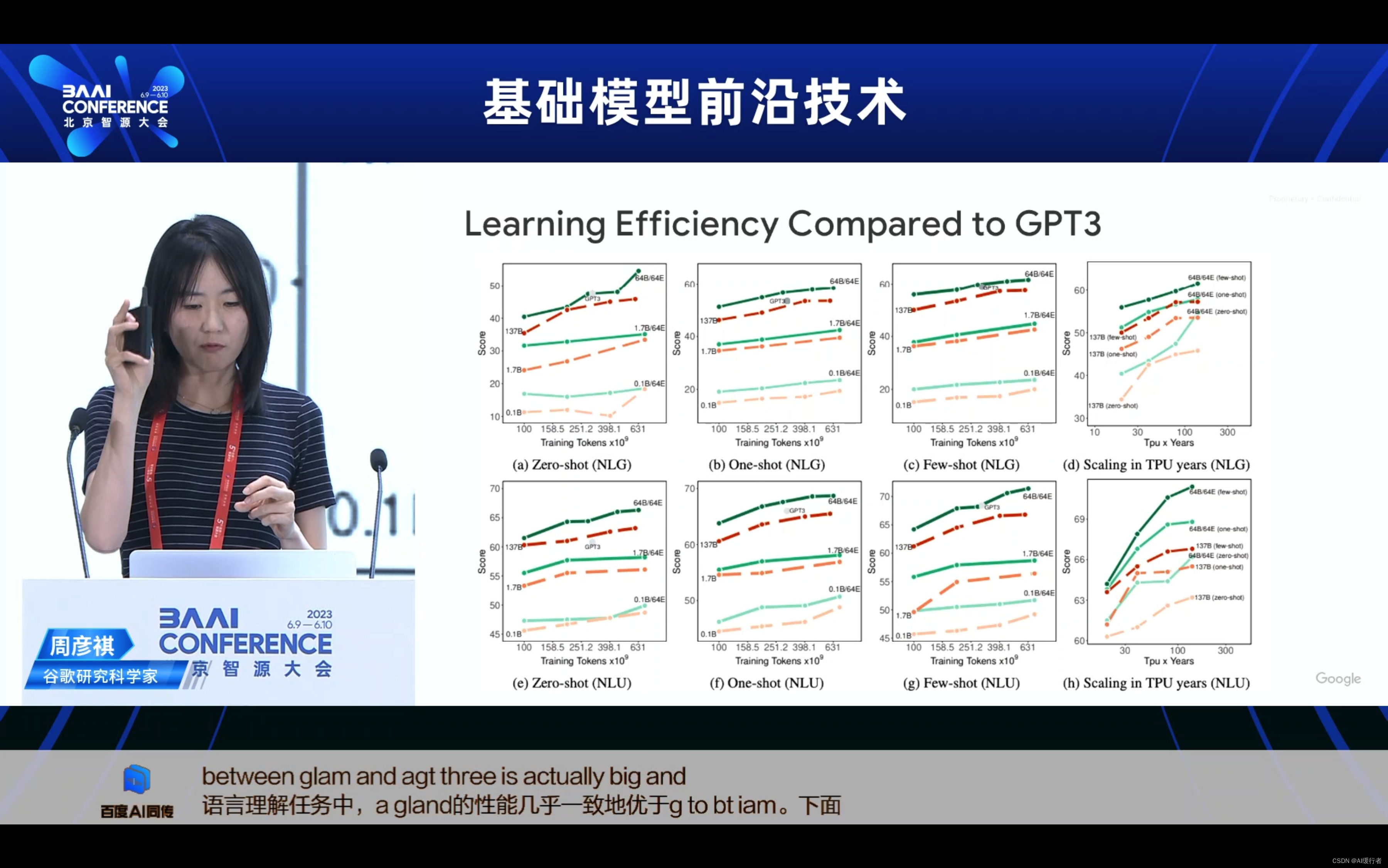
- 训练效率
- 达到良好困惑度需要多少步骤?
- 步骤时间
- 达到良好困惑度需要多少步骤?
- EC-CF2的收敛速度比2倍快
- 每步时间减少20%

4. Advanced MoE techniques(先进的MoE技术)


- Brainformers: Trading Simplicity for Efficiency Brainformers(以效率换取简单性)
- 现有的MoE架构在步骤时间上扩展性差。
- 提出一种非均匀架构,以低秩多专家原语为基础。
- 展示比GLaM更快的训练收敛速度和更快的步骤时间,速度提升5倍。

- How we derive the model search space?(我们如何得出模型搜索空间?)
- Transformer是从低秩和多专家派生出来的特殊情况!

- Brainformer Search(Brainformer搜索)
- 基于块的架构搜索空间
- 计算高效的搜索目标

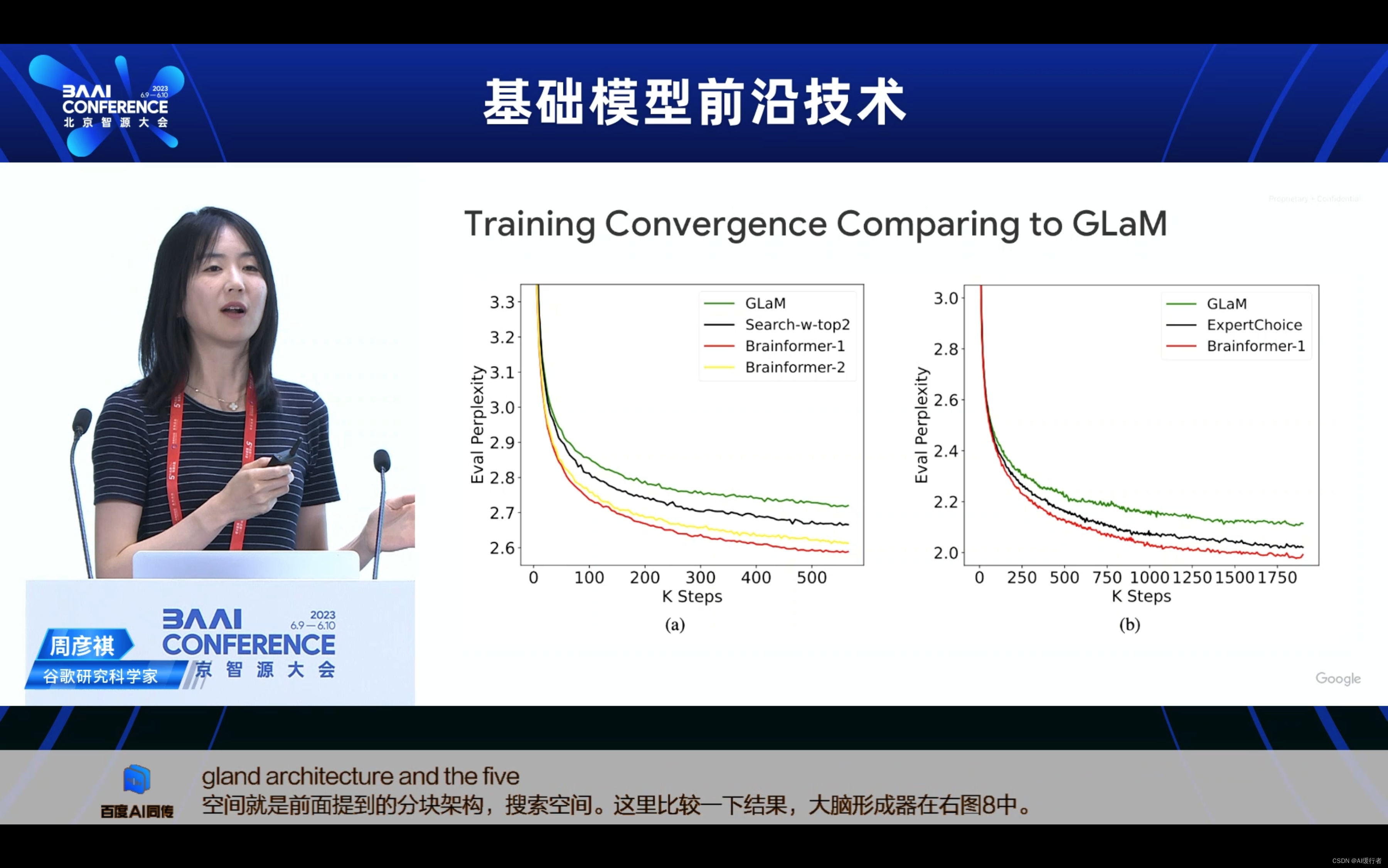
- Training Convergence Comparing to GLaM与GLaM相比的训练收敛速度
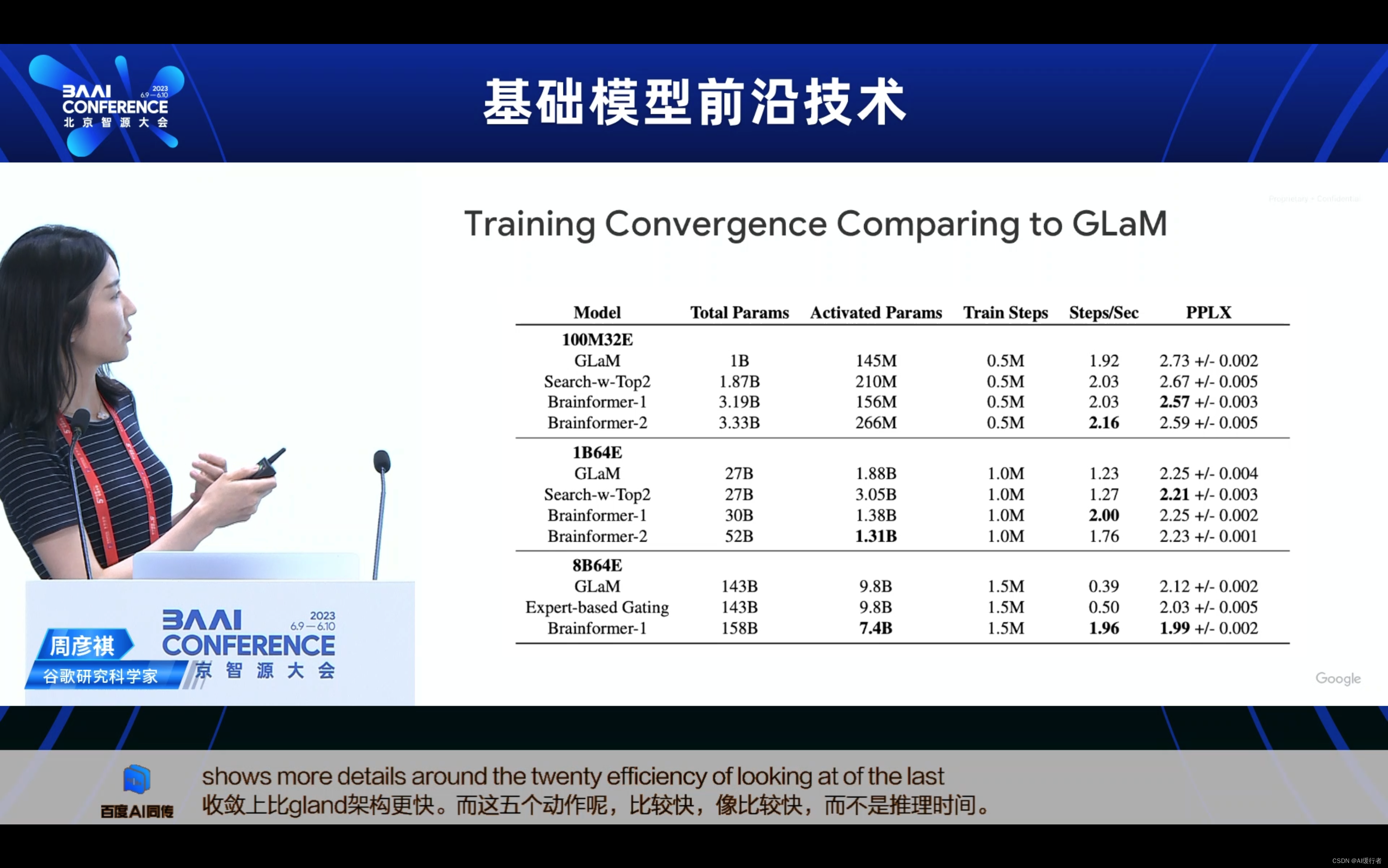
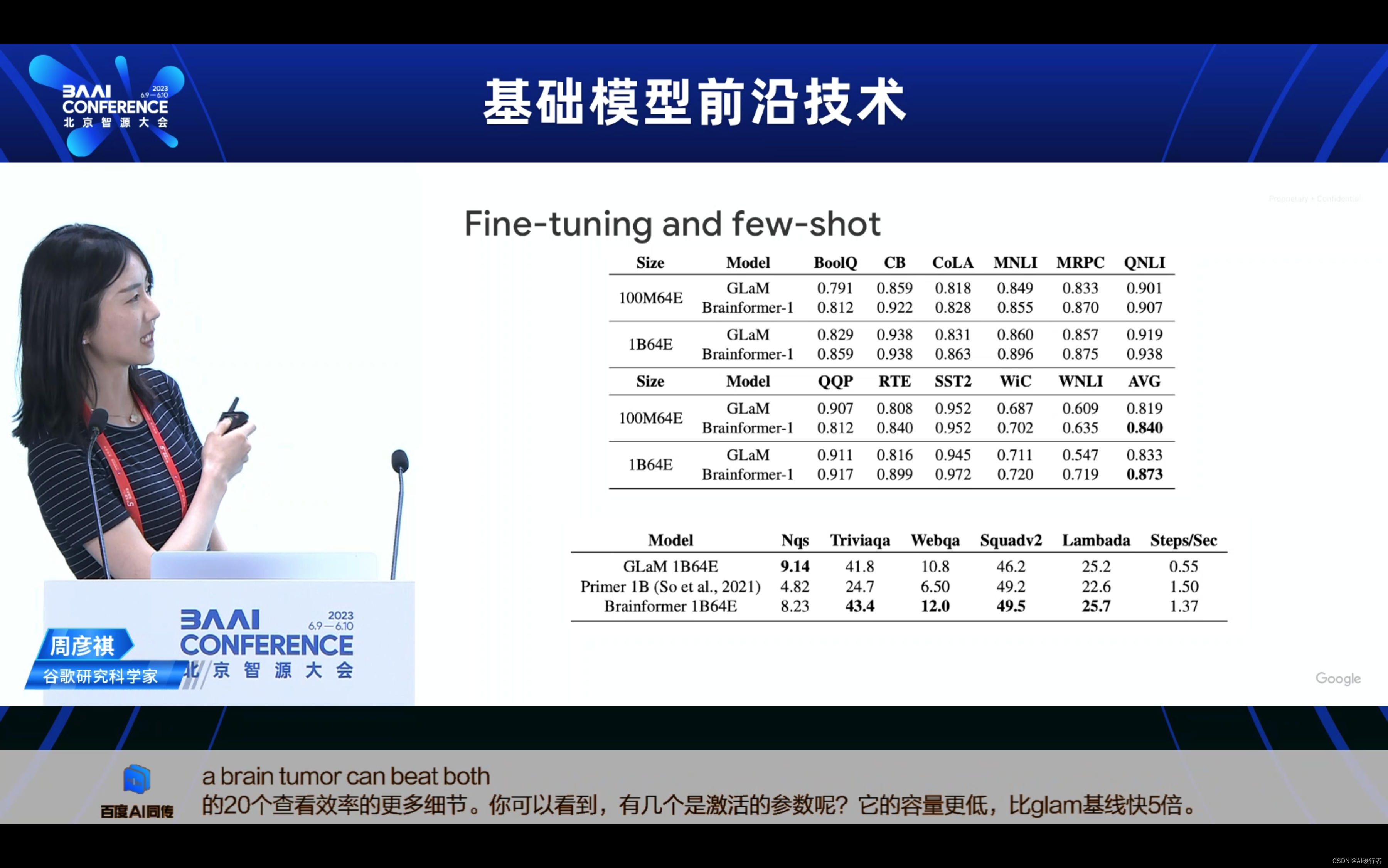
- LLM training is expensive…(LLM的训练成本高昂…)

- 动机
- 用例1:时间相关数据集
- 跟踪语言趋势,保持数据集更新
①每隔几个月收集新样本
②谷歌搜索、论坛、对话、维基百科、GitHub等等。- 在大型数据集上训练耗时资源
- 在新样本上训练将更加廉价
- 用例2:通用预训练数据集->用于对话的数据集
- 需要在针对目标领域的新数据混合中进行微调,比如聊天机器人。
- 会出现遗忘现象。

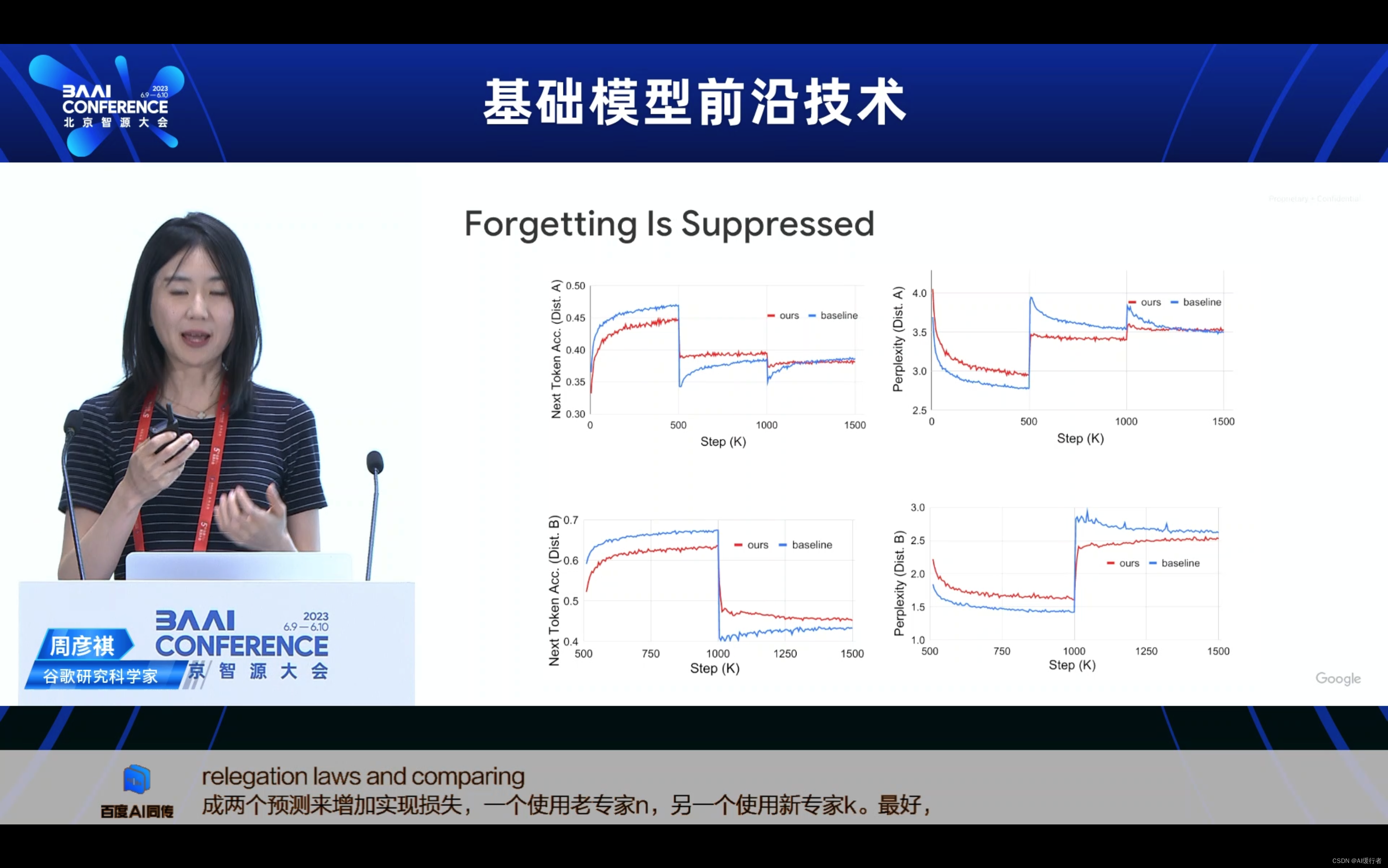
- Forgetting遗忘
- 原始数据集的分布:A
- 新样本的分布:B
- 分布从A到B发生变化
- A和B上的性能都很重要!
- 构建通用模型是趋势。
- “遗忘问题”:如果我们只在B上进行训练,A上的性能会下降,假设:新数据按序列进入,我们可能无法“访问”旧数据。

- Lifelong Language Pretraining with Distribution-specialized Experts使用专门化分布的专家进行终身语言预训练
- 基于分布的MoE
- 逐渐增加更多专家以适应新数据分布
- 添加正则化以减轻遗忘。

- 分布A → B=c
- 在Tarzan上进行模拟:“A”= 维基/网络,“B”= 非英语,“C”= 对话
- “正则化”
- 我们不希望模型过度拟合B
- 我们不希望模型权重过于偏离A
- 在适应B的同时对模型进行正则化
- “扩展”
- 允许模型在适应新分布时扩展(专家)层

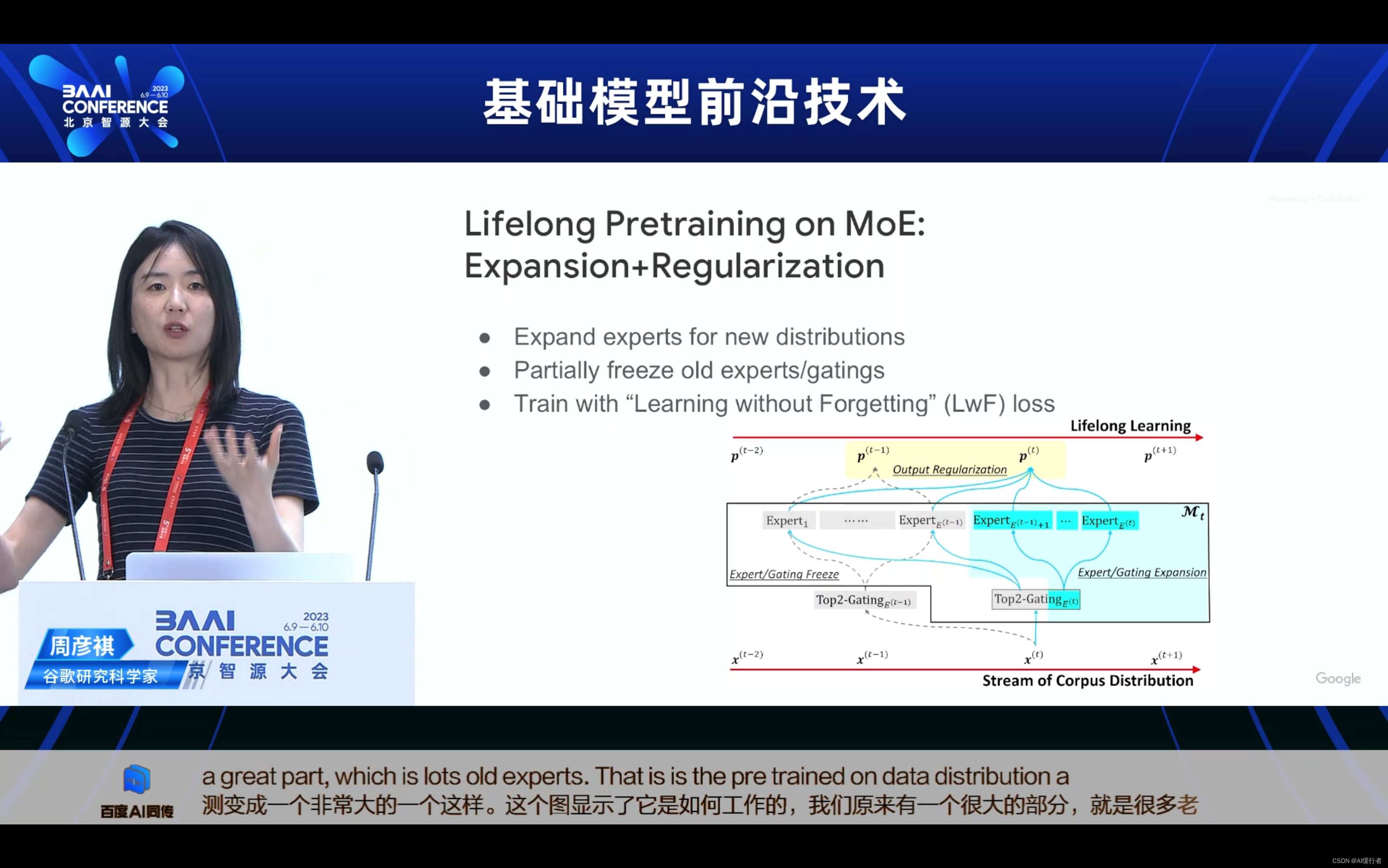
- Lifelong Pretraining on MoE:Expansion+Regularization(MoE上的终身预训练:扩展+正则化)
- 为新分布扩展专家
- 部分冻结旧的专家/门控
- 使用“无遗忘学习”(LwF)损失进行训练

- Final Thoughts & QA(最后的思考和问答)
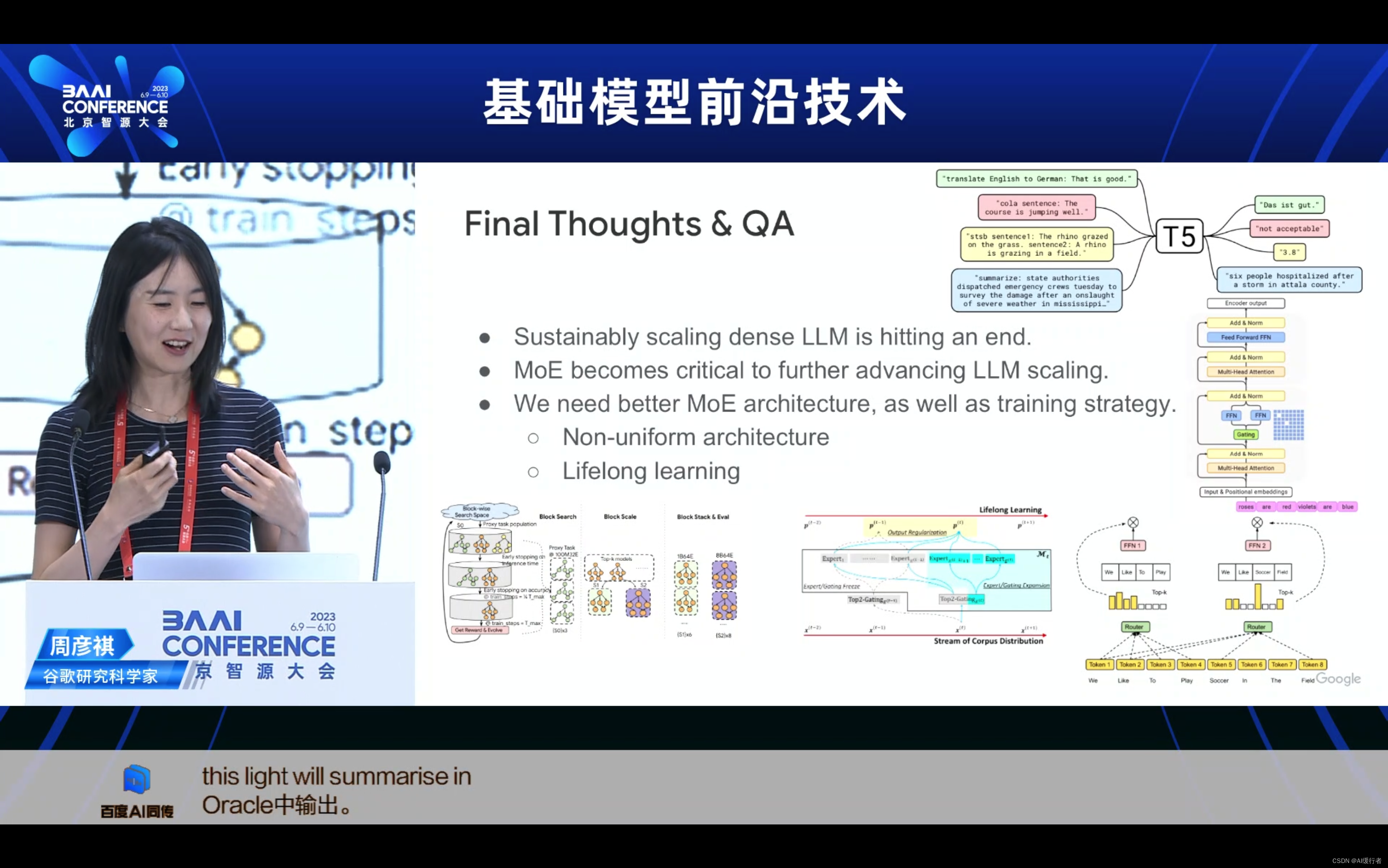
- 持续扩展密集LLM已经达到了极限。
- MoE变得对进一步推进LLM扩展至关重要。
- 我们需要更好的MoE架构,以及训练策略。①非均匀架构;②终身学习
5. Q&A(谷歌周彦祺:LLM浪潮中的女性科学家多面手)
- 谷歌周彦祺:LLM浪潮中的女性科学家多面手: https://new.qq.com/rain/a/20230529A07QOQ00
参考文章
- 北京智源大会:https://2023.baai.ac.cn/schedule