你好,我是郭震(zhenguo)
今天重新发布强化学习第10篇:强化学习Q-learning求解迷宫问题 代码实现
我想对此篇做一些更加详细的解释。
1 创建地图
创建迷宫地图,包括墙网格,走到墙网格就是负奖励。
注意:空白可行走网格奖励值设置为负数,比如-1, 是为减少路径中所经点数;如果设置为大于0的奖励值,路线中会出现冗余点。
import numpy as np
# 创建迷宫地图
exit_coord = (3, 3)
row_n, col_n = 4, 4
maze = np.zeros((row_n, col_n)) - 1
# 走出迷宫奖励10个积分
maze[exit_coord] = 10
# 走到墙网格,扣除10个积分
maze[(0, 3)] = -10
maze[(1, 0)] = -10
maze[(1, 2)] = -10
maze[(2, 2)] = -10
maze[(3, 0)] = -10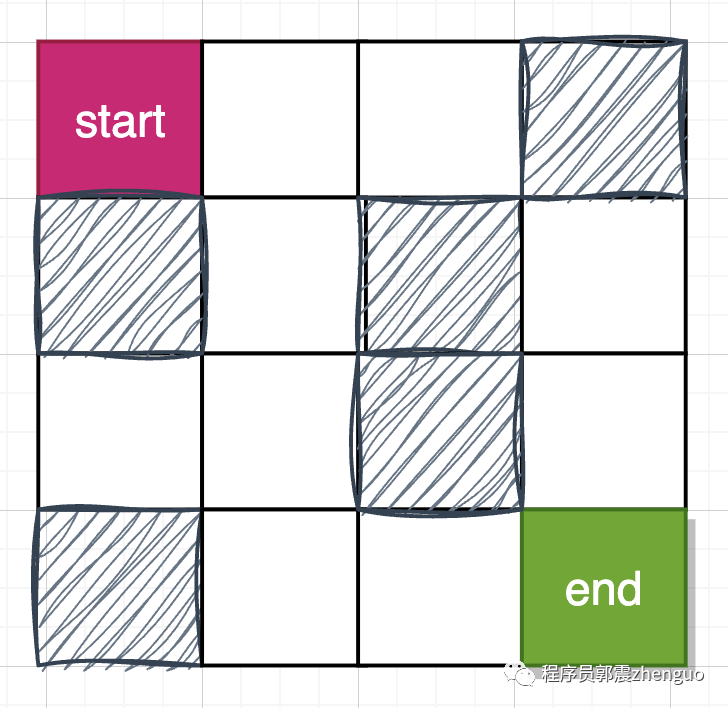
2 定义动作
定义动作集合
# 定义动作集合
action_n = 4
actions = [0, 1, 2, 3] # 上、下、左、右3 算法参数
定义参数
# 定义参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # ε-greedy策略的ε值4 初始化Q表
初始化Q表,三维数组。
# 初始化Q表
Q = np.zeros((row_n, col_n, action_n))5 算法迭代
进行Q-learning算法迭代更新,包括步骤:
选择动作
执行动作,更新状态
更新Q值
算法实现中一些细节处理包括:
智能体走到边界时,排除一些action
每次episode后,根据路线所经点的reward求和,判断是否找到更优路线。
# 进行Q-learning算法迭代更新
begin_cord = (0, 0)
max_reward_route = float("-inf")
for episode in range(200):
# 初始化起始位置
state = begin_cord
route = [state]
while state != exit_coord: # 终止条件:到达终点位置
tmp = actions.copy()
# 排除一些可能
if state[0] == 0: # 不能向上
tmp.remove(0)
if state[1] == 0: # 不能向左
tmp.remove(2)
if state[0] == row_n - 1: # 不能向下
tmp.remove(1)
if state[1] == col_n - 1: # 不能向右
tmp.remove(3)
# 选择动作
if np.random.uniform() < epsilon:
action = np.random.choice(tmp) # ε-greedy策略,以一定概率随机选择动作
else:
action = np.argmax(Q[state[0], state[1], tmp]) # 选择Q值最大的动作
action = tmp[action]
# 执行动作,更新状态
next_state = state
if action == 0: # 上
next_state = (state[0] - 1, state[1])
elif action == 1: # 下
next_state = (state[0] + 1, state[1])
elif action == 2: # 左
next_state = (state[0], state[1] - 1)
elif action == 3: # 右
next_state = (state[0], state[1] + 1)
# 获取即时奖励
reward = maze[next_state]
# 更新Q值
Q[state][action] = (1 - alpha) * Q[state][action] + alpha * (reward + gamma * np.max(Q[next_state]))
# 更新状态
state = next_state
route.append(state)
route_reward = sum(maze[state] for state in route)
if max_reward_route < route_reward:
max_reward_route = route_reward
best_route = route.copy()
print(f"episode: {episode}, 新发现最优路线:{best_route}")
route.clear()
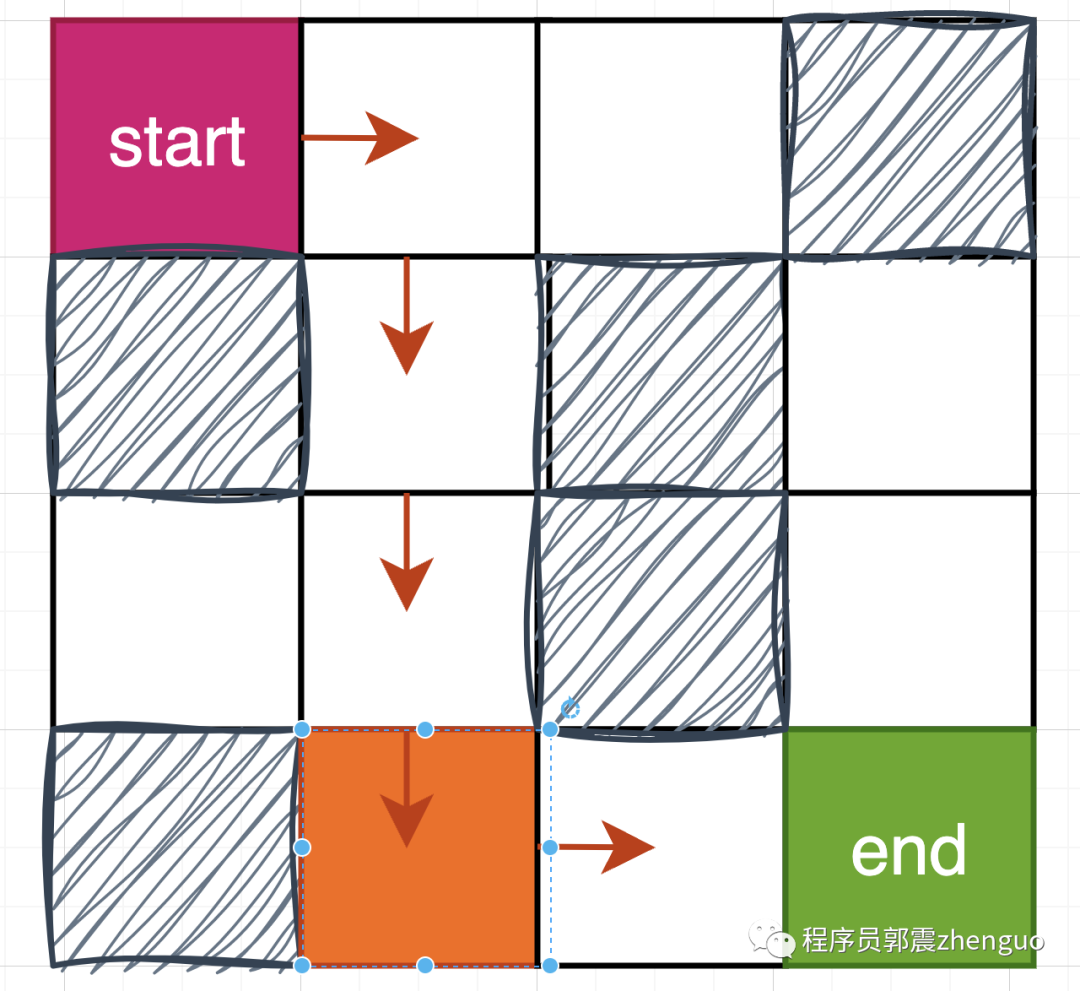
cur_reward_route = 0迭代完成,得到最佳路线,就如上图所示环境,最佳路线如下所示。大概在第50-80迭代步便可搜索到:
[(0, 0), (0, 1), (1, 1), (2, 1), (3, 1), (3, 2), (3, 3)]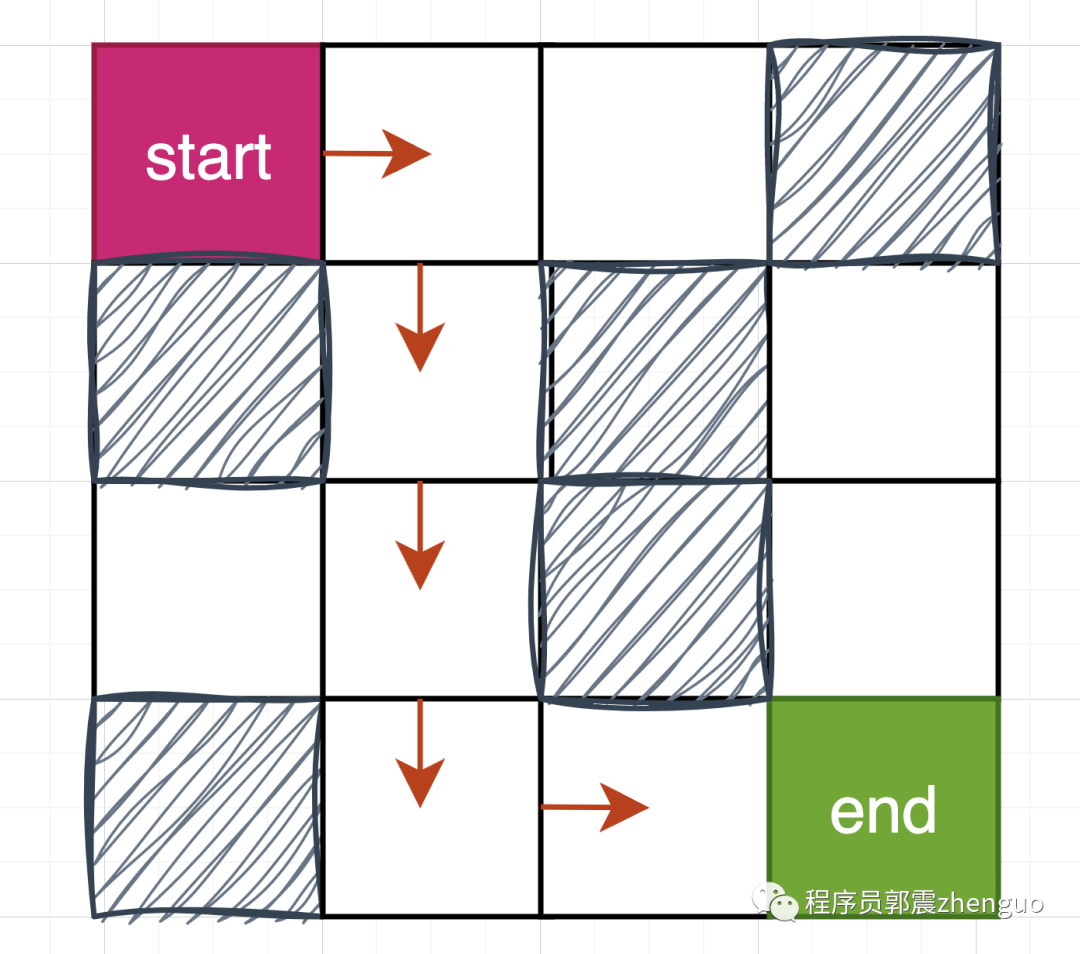
Q表如下所示,可以看到红框所示为下面粉丝网格的Q值,第三个元素就是向左的奖励值,看到是最低的,因为是墙体。
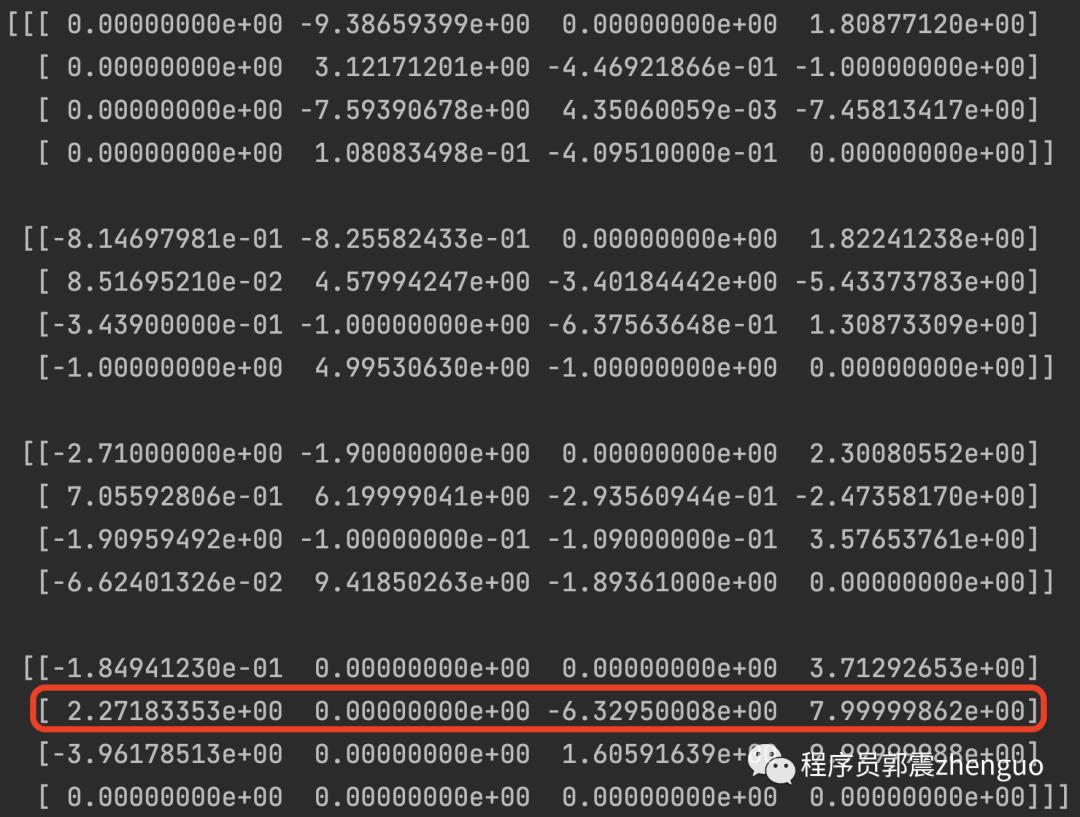
根据此Q表,我们可预测出从任意位置出发的最佳路线,大家自行尝试。
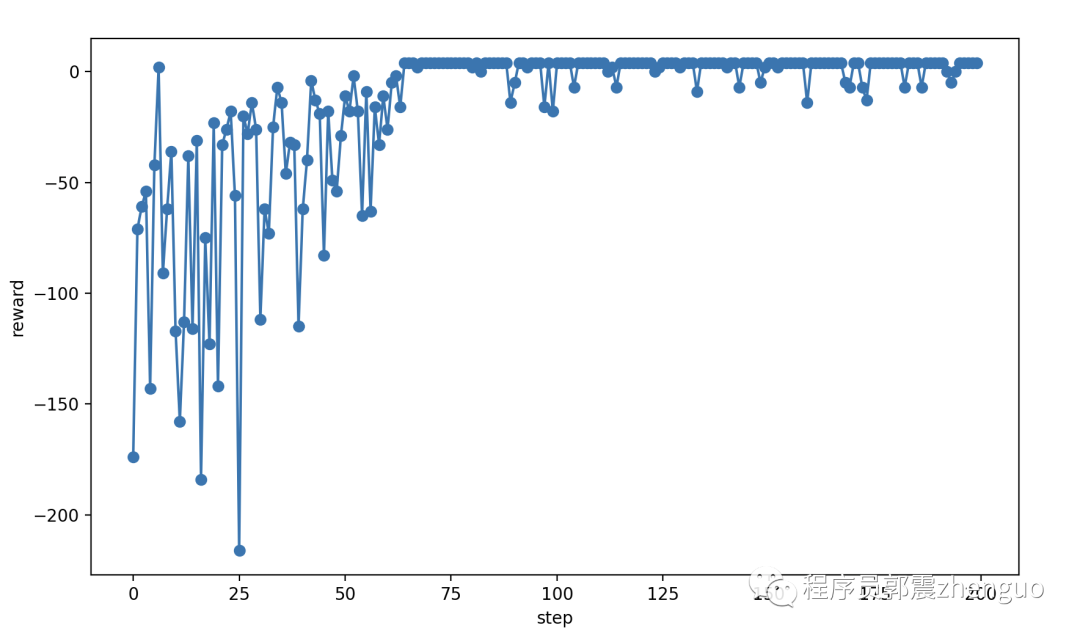
最后分析训练时步与路线奖励值关系图,看到逐渐收敛。
以上,Q-learning算法求迷宫问题,代码实现。
感谢你的点赞和转发,让我更新更有动