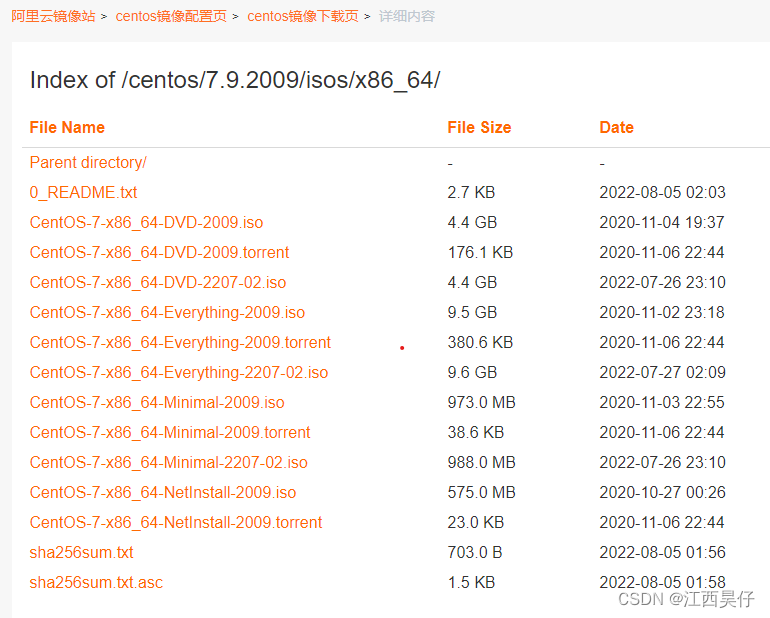
写在前面:最近我拿到一个CUB_200_2011鸟类训练模型,但是我想将他转为yolov的格式进行应用。看了些其他博主博客后,发现跳跃性有些强。再此记录转换过程,希望各位道友修得此法后,能有所收获!
一、获取数据集
官网下载:Perona Lab - CUB-200-2011Perona Lab -- CUB-200-2011
鸟类训练模型![]() https://pan.baidu.com/s/1ASDDX7h_SYBRJXPp2aZKqA?pwd=1234
https://pan.baidu.com/s/1ASDDX7h_SYBRJXPp2aZKqA?pwd=1234
二、数据集目录结构
创建存放转换结果的目录,结构如下:
- 在yolov5-master同级目录下创建datasets目录
- 进入datasets目录,创建birds目录,用来存放转后的数据集
- 进入birds目录,创建images和lables目录
- 在images和lables目录下,分别创建train和vla目录,如下所示:

下图是CUB_200_211鸟类数据集目录结构,放置的路径如上图中步骤所示。

三、数据集转换
梳理:我们想得到什么?
(1)上面分类好的yolov5数据集
(2)birds.yaml 数据配置文件
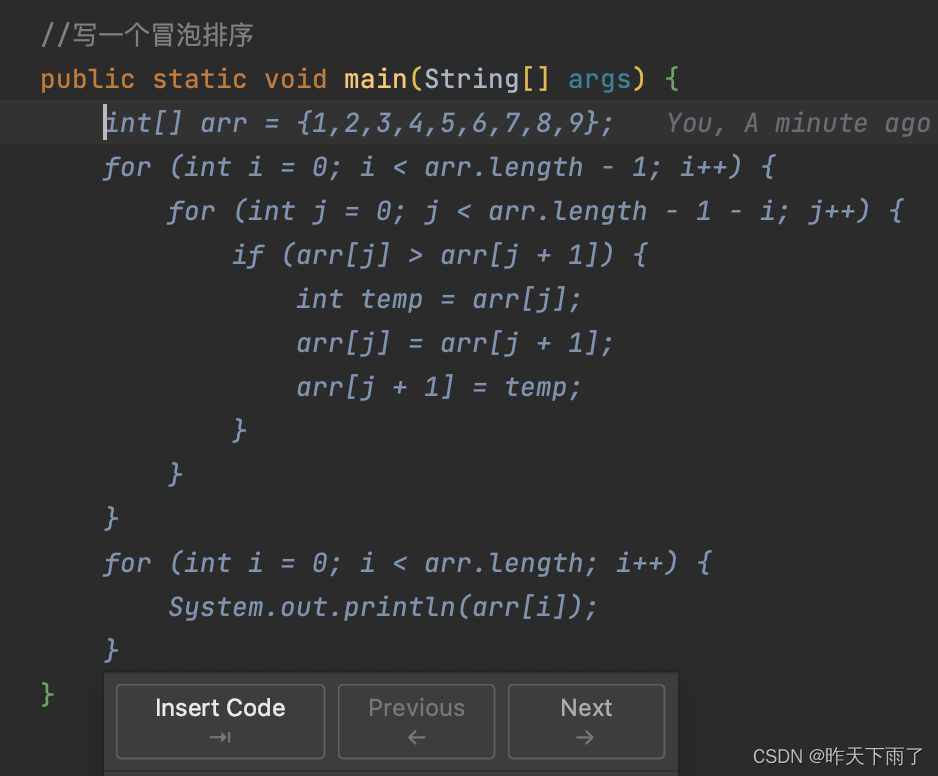
1. 在yolov5-master项目下创建datasetshub2yolo.py文件,如下图:

2. 执行文件代码
- labpath和imapath建议写绝对路径,相对路径容易报错
- 代码最后几行是调用方法,如果你多次执行的话,会累加,数据会重复。所以你想再次执行,最好把原来的数据删除。
import shutil
import cv2
path = '../CUB_200_2011'
labpath = 'D:/python/yolov5/datasets/birds/lables'
imapath = 'D:/python/yolov5/datasets/birds/images'
def get_yaml():
# get birds.yaml
with open(path + '/classes.txt', 'r') as fo, open('birds.yaml', "a") as fi: # r只读,w写,a追加写
for num, line in enumerate(fo): # enumerate为枚举,num为从0开始的序号,line为每一行的信息
s = ' ' + str(num) + ': ' + line.split(" ")[-1] # 以空格分隔,去掉末尾的换行
fi.write(s) # 追加写入目标文件
def get_alllab():
dataall = {} # 字典用于存放txt中的各种信息
with open(path + '/images.txt', 'r') as imagesall, open(path + '/image_class_labels.txt', 'r') as classall, \
open(path + '/train_test_split.txt', 'r') as splitall, open(path + '/bounding_boxes.txt', 'r') as boxall:
for num, line in enumerate(imagesall): # 值用列表存储,方便后续添加元素,-1去掉末尾的/n
s = line.split(" ")
dataall[s[0]] = [s[1][:-1]]
for num, line in enumerate(classall):
s = line.split(" ")
dataall[s[0]].append(s[1][:-1])
for num, line in enumerate(splitall):
s = line.split(" ")
dataall[s[0]].append(s[1][:-1])
for num, line in enumerate(boxall):
s = line.split(" ")
dataall[s[0]].extend([s[1], s[2], s[3], s[4][:-1]])
print('dataall have got...')
for item in dataall:
na = item.rjust(12, '0') # item为字典的键,左侧扩充0,改为所需名字格式(未看到明确要求)
image = cv2.imread(path + '/images/' + dataall[item][0]) # 读取图片,使用shape获取图片宽高
# 这两行代码为验证boundingbox信息,手动画框,图片存储至test文件夹,左上角和右下角坐标,image.shape[1] 宽度 image.shape[0] 高度
# cv2.rectangle(image, (int(float(dataall[item][3])), int(float(dataall[item][4]))), (int(float(dataall[item][3]))+\
# int(float(dataall[item][5])),int(float(dataall[item][4]))+int(float(dataall[item][6]))), (0, 0, 255), 3)
# cv2.imwrite(imapath+'/test2017/' + na + '.jpg', image) # 带小数的str需先转为float才能转为int
x = (float(dataall[item][3]) + float(dataall[item][5]) / 2) / image.shape[1]
y = (float(dataall[item][4]) + float(dataall[item][6]) / 2) / image.shape[0]
w = float(dataall[item][5]) / image.shape[1]
h = float(dataall[item][6]) / image.shape[0]
s = str(int(dataall[item][1]) - 1) + ' ' + str('%.6f' % x) + ' ' + str('%.6f' % y) + \
' ' + str('%.6f' % w) + ' ' + str('%.6f' % h) # 将cub的boundingbox转换为yolov5格式
if dataall[item][2] == '1': # 划分训练集验证集,shutil.copy(a,b)为复制图片,a为原路径,b为目标路径(带名字则自动重命名)
with open(labpath + '/train/{}.txt'.format(na), 'w') as lab:
lab.write(s) # 写入文件 已存在就覆盖,没有就生成
shutil.copy(path + '/images/' + dataall[item][0], imapath + '/train/' + na + '.jpg')
elif dataall[item][2] == '0':
with open(labpath + '/val/{}.txt'.format(na), 'w') as lab:
lab.write(s)
shutil.copy(path + '/images/' + dataall[item][0], imapath + '/val/' + na + '.jpg')
if __name__ == "__main__":
get_yaml()
get_alllab()
3. 转换后的结果展示
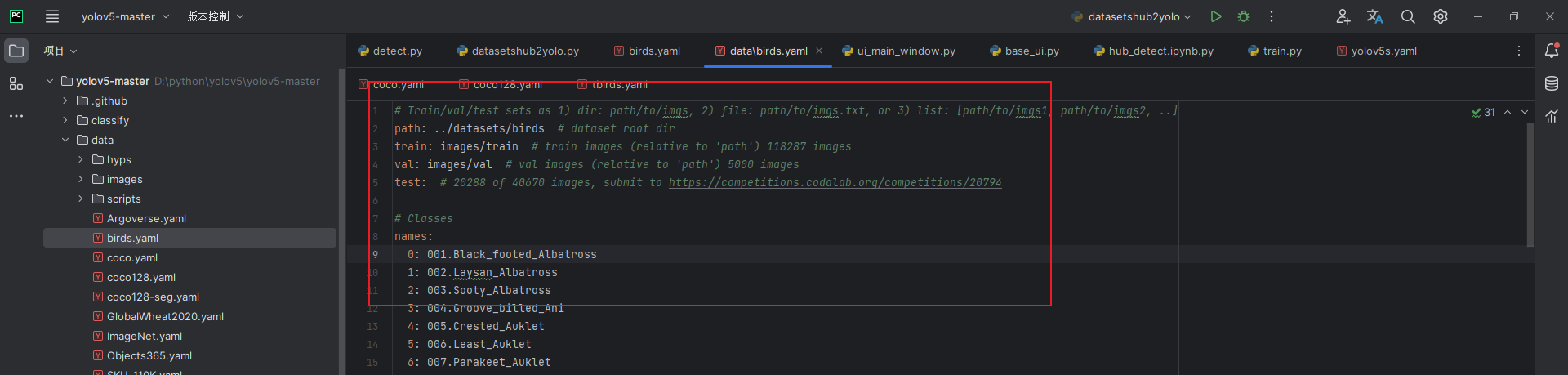
(1)birds.yaml

(2)数据集部分展示


4. 数据精细化处理
将转换后的birds.yaml文件拷贝到data目录下。参考coco128.yaml文件,将birds.yaml文件的上面配置替换了,可以参考我下面的配置。
至此,数据集的CUB数据集转换成yolov5格式的工作完毕,至于训练部分,我如果有时间就开一个yolov系列专栏慢慢更新把~希望道友能顺利通过本篇博客!!