同步容器
在 Java 中,同步容器主要包括 2 类:
- Vector、Stack、HashTable
- Vector 实现了 List 接口,Vector 实际上就是一个数组,和 ArrayList 类似,但是 Vector 中的方法都是 synchronized 方法,即进行了同步措施。
- Stack 也是一个同步容器,它的方法也用 synchronized 进行了同步,它实际上是继承于 Vector 类。
- HashTable 实现了 Map 接口,它和 HashMap 很相似,但是 HashTable 进行了同步处理,而 HashMap 没有。
- Collections 类中提供的静态工厂方法创建的类(由 Collections.synchronizedXxxx 等方法)
同步容器的缺陷
同步容器的同步原理就是在方法上用 synchronized 修饰。那么,这些方法每次只允许一个线程调用执行。
性能问题
由于被 synchronized 修饰的方法,每次只允许一个线程执行,其他试图访问这个方法的线程只能等待。显然,这种方式比没有使用 synchronized 的容器性能要差。
安全问题
同步容器真的一定安全吗?
答案是:未必。同步容器未必真的安全。在做复合操作时,仍然需要加锁来保护。
常见复合操作如下:
- 迭代:反复访问元素,直到遍历完全部元素;
- 跳转:根据指定顺序寻找当前元素的下一个(下 n 个)元素;
- 条件运算:例如若没有则添加等;
不安全的示例
public class Test {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) throws InterruptedException {
while(true) {
for(int i=0;i<10;i++)
vector.add(i);
Thread thread1 = new Thread(){
public void run() {
for(int i=0;i<vector.size();i++)
vector.remove(i);
};
};
Thread thread2 = new Thread(){
public void run() {
for(int i=0;i<vector.size();i++)
vector.get(i);
};
};
thread1.start();
thread2.start();
while(Thread.activeCount()>10) {
}
}
}
}复制
执行时可能会出现数组越界错误。
Vector 是线程安全的,为什么还会报这个错?很简单,对于 Vector,虽然能保证每一个时刻只能有一个线程访问它,但是不排除这种可能:
当某个线程在某个时刻执行这句时:
for(int i=0;i<vector.size();i++)
vector.get(i);复制
假若此时 vector 的 size 方法返回的是 10,i 的值为 9
然后另外一个线程执行了这句:
for(int i=0;i<vector.size();i++)
vector.remove(i);复制
将下标为 9 的元素删除了。
那么通过 get 方法访问下标为 9 的元素肯定就会出问题了。
安全示例
因此为了保证线程安全,必须在方法调用端做额外的同步措施,如下面所示:
public class Test {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) throws InterruptedException {
while(true) {
for(int i=0;i<10;i++)
vector.add(i);
Thread thread1 = new Thread(){
public void run() {
synchronized (Test.class) { //进行额外的同步
for(int i=0;i<vector.size();i++)
vector.remove(i);
}
};
};
Thread thread2 = new Thread(){
public void run() {
synchronized (Test.class) {
for(int i=0;i<vector.size();i++)
vector.get(i);
}
};
};
thread1.start();
thread2.start();
while(Thread.activeCount()>10) {
}
}
}
}复制
ConcurrentModificationException 异常
在对 Vector 等容器并发地进行迭代修改时,会报 ConcurrentModificationException 异常,关于这个异常将会在后续文章中讲述。
但是在并发容器中不会出现这个问题。
并发容器
JDK 的 java.util.concurrent 包(即 juc)中提供了几个非常有用的并发容器。
- CopyOnWriteArrayList - 线程安全的 ArrayList
- CopyOnWriteArraySet - 线程安全的 Set,它内部包含了一个 CopyOnWriteArrayList,因此本质上是由 CopyOnWriteArrayList 实现的。
- ConcurrentSkipListSet - 相当于线程安全的 TreeSet。它是有序的 Set。它由 ConcurrentSkipListMap 实现。
- ConcurrentHashMap - 线程安全的 HashMap。采用分段锁实现高效并发。
- ConcurrentSkipListMap - 线程安全的有序 Map。使用跳表实现高效并发。
- ConcurrentLinkedQueue - 线程安全的无界队列。底层采用单链表。支持 FIFO。
- ConcurrentLinkedDeque - 线程安全的无界双端队列。底层采用双向链表。支持 FIFO 和 FILO。
- ArrayBlockingQueue - 数组实现的阻塞队列。
- LinkedBlockingQueue - 链表实现的阻塞队列。
- LinkedBlockingDeque - 双向链表实现的双端阻塞队列。
ConcurrentHashMap
要点
- 作用:ConcurrentHashMap 是线程安全的 HashMap。
- 原理:JDK6 与 JDK7 中,ConcurrentHashMap 采用了分段锁机制。JDK8 中,摒弃了锁分段机制,改为利用 CAS 算法。
源码
JDK7
ConcurrentHashMap 类在 jdk1.7 中的设计,其基本结构如图所示:
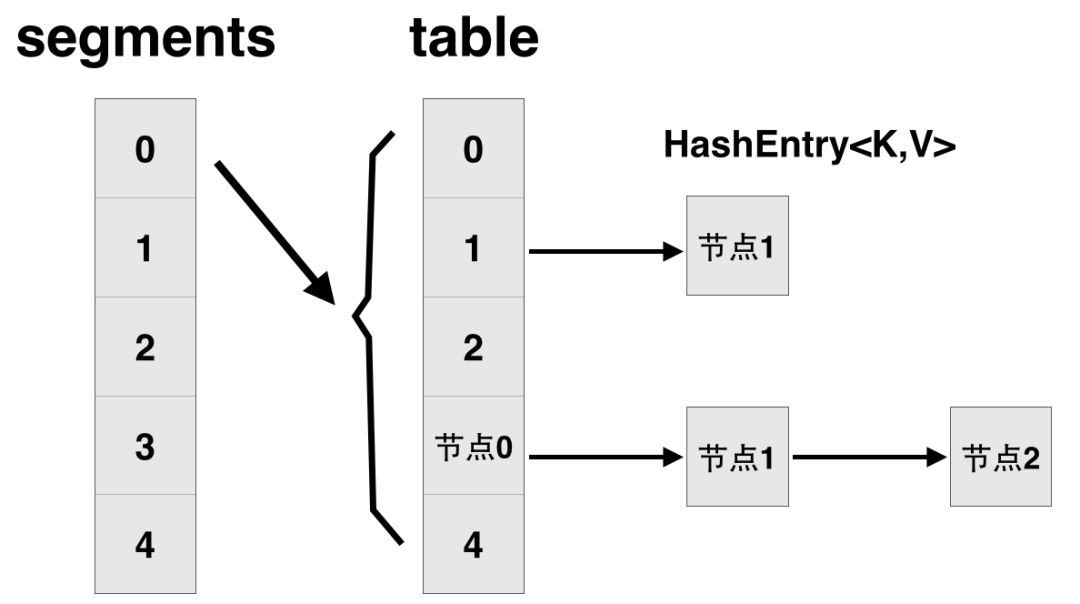
每一个 segment 都是一个 HashEntry<K,V>[] table, table 中的每一个元素本质上都是一个 HashEntry 的单向队列。比如 table[3]为首节点,table[3]->next 为节点 1,之后为节点 2,依次类推。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}复制
JDK8
- jdk8 中主要做了 2 方面的改进
- 取消 segments 字段,直接采用
transient volatile HashEntry<K,V>[] table保存数据,采用 table 数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。 - 将原先 table 数组+单向链表的数据结构,变更为 table 数组+单向链表+红黑树的结构。对于 hash 表来说,最核心的能力在于将 key hash 之后能均匀的分布在数组中。如果 hash 之后散列的很均匀,那么 table 数组中的每个队列长度主要为 0 或者 1。但实际情况并非总是如此理想,虽然 ConcurrentHashMap 类默认的加载因子为 0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为 O(n);因此,对于个数超过 8(默认值)的列表,jdk1.8 中采用了红黑树的结构,那么查询的时间复杂度可以降低到 O(logN),可以改进性能。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}复制
示例
public class ConcurrentHashMapDemo {
public static void main(String[] args) throws InterruptedException {
// HashMap 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// Map<Integer, Character> map = new HashMap<>();
Map<Integer, Character> map = new ConcurrentHashMap<>();
Thread wthread = new Thread(() -> {
System.out.println("写操作线程开始执行");
for (int i = 0; i < 26; i++) {
map.put(i, (char) ('a' + i));
}
});
Thread rthread = new Thread(() -> {
System.out.println("读操作线程开始执行");
for (Integer key : map.keySet()) {
System.out.println(key + " - " + map.get(key));
}
});
wthread.start();
rthread.start();
Thread.sleep(1000);
}
}复制
CopyOnWriteArrayList
要点
- 作用:CopyOnWrite 字面意思为写入时复制。CopyOnWriteArrayList 是线程安全的 ArrayList。
- 原理:
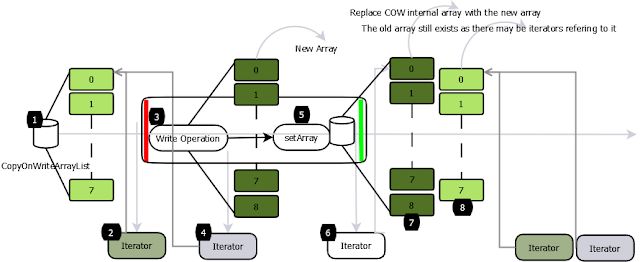
- 在 CopyOnWriteAarrayList 中,读操作不同步,因为它们在内部数组的快照上工作,所以多个迭代器可以同时遍历而不会相互阻塞(1,2,4)。
- 所有的写操作都是同步的。他们在备份数组(3)的副本上工作。写操作完成后,后备阵列将被替换为复制的阵列,并释放锁定。支持数组变得易变,所以替换数组的调用是原子(5)。
- 写操作后创建的迭代器将能够看到修改的结构(6,7)。
- 写时复制集合返回的迭代器不会抛出 ConcurrentModificationException,因为它们在数组的快照上工作,并且无论后续的修改(2,4)如何,都会像迭代器创建时那样完全返回元素。
源码
重要属性
- lock - 执行写时复制操作,需要使用可重入锁加锁
- array - 对象数组,用于存放元素
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;复制
重要方法
- 添加操作
- 添加的逻辑很简单,先将原容器 copy 一份,然后在新副本上执行写操作,之后再切换引用。当然此过程是要加锁的。
public boolean add(E e) {
//ReentrantLock加锁,保证线程安全
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//拷贝原容器,长度为原容器长度加一
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新副本上执行添加操作
newElements[len] = e;
//将原容器引用指向新副本
setArray(newElements);
return true;
} finally {
//解锁
lock.unlock();
}
}复制
- 删除操作
- 删除操作同理,将除要删除元素之外的其他元素拷贝到新副本中,然后切换引用,将原容器引用指向新副本。同属写操作,需要加锁。
public E remove(int index) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
//如果要删除的是列表末端数据,拷贝前len-1个数据到新副本上,再切换引用
setArray(Arrays.copyOf(elements, len - 1));
else {
//否则,将除要删除元素之外的其他元素拷贝到新副本中,并切换引用
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
//解锁
lock.unlock();
}
}复制
- 读操作
- CopyOnWriteArrayList 的读操作是不用加锁的,性能很高。
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}复制
示例
public class CopyOnWriteArrayListDemo {
static class ReadTask implements Runnable {
List<String> list;
ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
static class WriteTask implements Runnable {
List<String> list;
int index;
WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
// ArrayList 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// List<String> list = new ArrayList<>();
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();
}
}