2021年见证了vision transformer的大爆发,随着谷歌提出ViT之后,一大批的vision transformer的工作席卷计算机视觉任务。除了vision transformer,另外一个对计算机视觉影响比较大的工作就是Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型,这两个工作也像ViT一样带动了一波新的研究高潮。这篇文章将首先介绍CLIP的原理以及如何用CLIP实现zero-shot分类,然后我们将讨论CLIP背后的动机,最后文章会介绍CLIP的变种和其它的一些应用场景。
CLIP是如何工作的
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
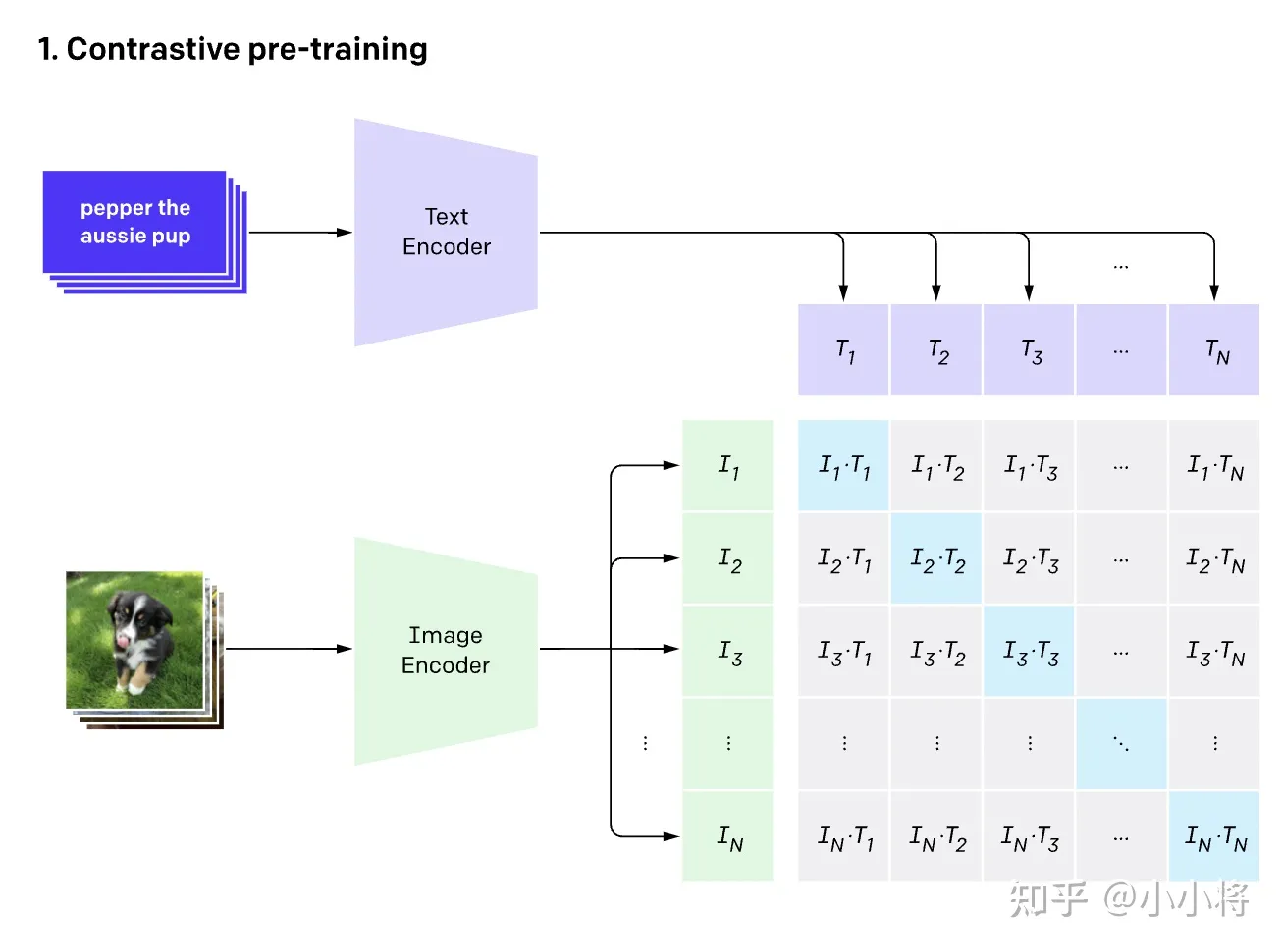
这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N2个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的N2−N个文本-图像对为负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N2−N个负样本的相似度,对应的伪代码实现如下所示:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WebImageText,如果按照文本的单词量,它和训练GPT-2的WebText规模类似,如果从数量上对比的话,它还比谷歌的JFT-300M数据集多一个亿,所以说这是一个很大规模的数据集。CLIP虽然是多模态模型,但它主要是用来训练可迁移的视觉模型。论文中Text Encoder固定选择一个包含63M参数的text transformer模型,而Image Encoder采用了两种的不同的架构,一是常用的CNN架构ResNet,二是基于transformer的ViT,其中ResNet包含5个不同大小的模型:ResNet50,ResNet101,RN50x4,RN50x16和RNx64(后面三个模型是按照EfficientNet缩放规则对ResNet分别增大4x,16x和64x得到),而ViT选择3个不同大小的模型:ViT-B/32,ViT-B/16和ViT-L/14。所有的模型都训练32个epochs,采用AdamW优化器,而且训练过程采用了一个较大的batch size:32768。由于数据量较大,最大的ResNet模型RN50x64需要在592个V100卡上训练18天,而最大ViT模型ViT-L/14需要在256张V100卡上训练12天,可见要训练CLIP需要耗费多大的资源。对于ViT-L/14,还在336的分辨率下额外finetune了一个epoch来增强性能,论文发现这个模型效果最好,记为ViT-L/14@336,论文中进行对比实验的CLIP模型也采用这个。
如何用CLIP实现zero-shot分类
上面我们介绍了CLIP的原理,可以看到训练后的CLIP其实是两个模型,除了视觉模型外还有一个文本模型,那么如何对预训练好的视觉模型进行迁移呢?与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。用CLIP实现zero-shot分类很简单,只需要简单的两步:
- 根据任务的分类标签构建每个类别的描述文本:
A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征; - 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
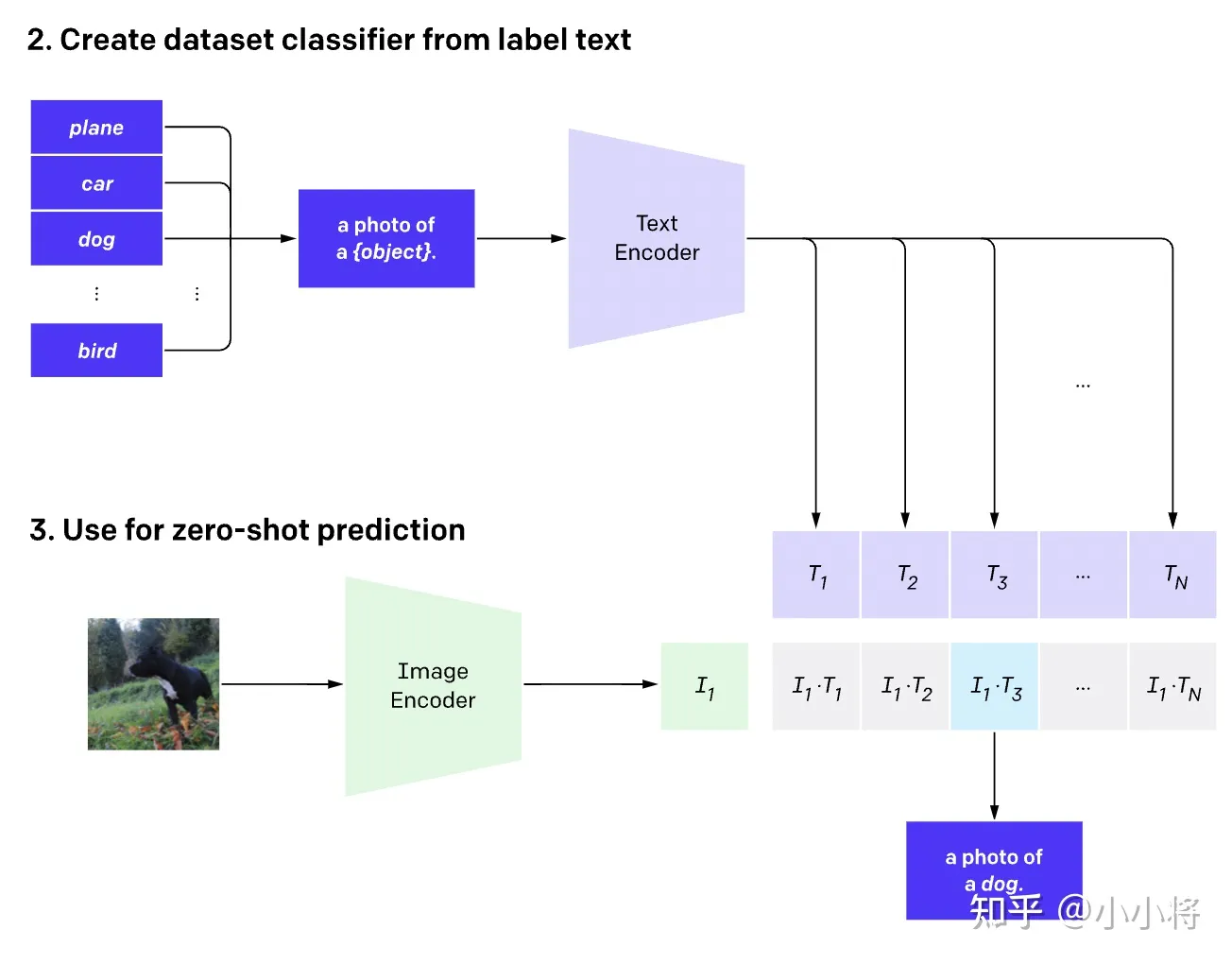
可以看到,我们是利用CLIP的多模态特性为具体的任务构建了动态的分类器,其中Text Encoder提取的文本特征可以看成分类器的weights,而Image Encoder提取的图像特征是分类器的输入。这里我们给出了一个基于CLIP的一个实例(参考官方notebook),这里任务共有6个类别:"dog", "cat", "bird", "person", "mushroom", "cup",首先我们创建文本描述,然后提取文本特征:
# 首先生成每个类别的文本描述
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()
# 提取文本特征
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)然后我们读取要预测的图像,输入Image Encoder提取图像特征,并计算与文本特征的余弦相似度:
# 读取图像
original_images = []
images = []
texts = []
for label in labels:
image_file = os.path.join("images", label+".jpg")
name = os.path.basename(image_file).split('.')[0]
image = Image.open(image_file).convert("RGB")
original_images.append(image)
images.append(preprocess(image))
texts.append(name)
image_input = torch.tensor(np.stack(images)).cuda()
# 提取图像特征
with torch.no_grad():
image_features = model.encode_image(image_input).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
# 计算余弦相似度(未缩放)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T相似度如下所示,可以看到对于要预测的6个图像,按照最大相似度,其均能匹配到正确的文本标签:
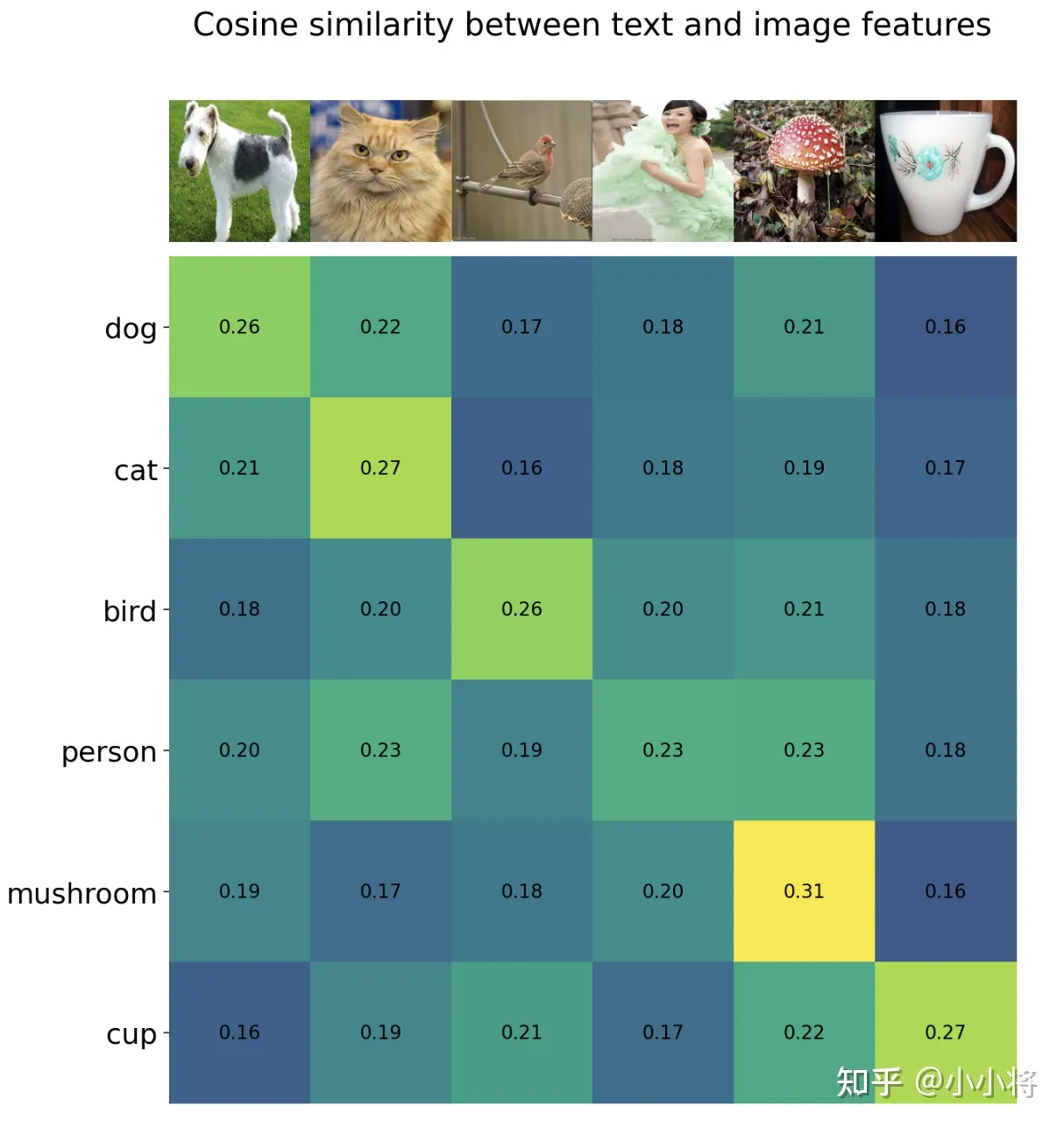
进一步地,我们也可以对得到的余弦相似度计算softmax,得到每个预测类别的概率值,注意这里要对相似度进行缩放:
logit_scale = np.exp(model.logit_scale.data.item())
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)得到的预测概率如下所示,可以看到6个图像,CLIP模型均能够以绝对的置信度给出正确的分类结果:
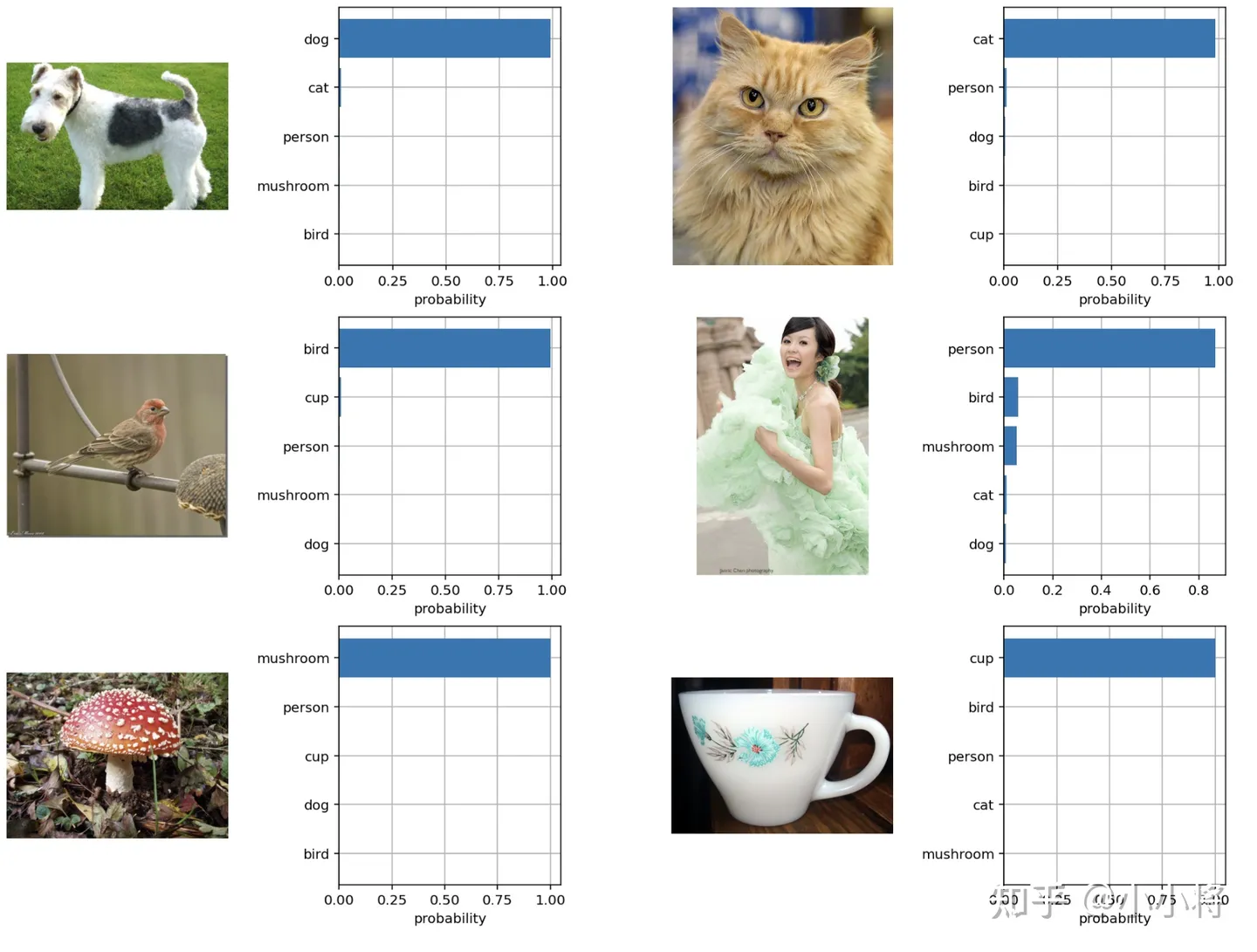
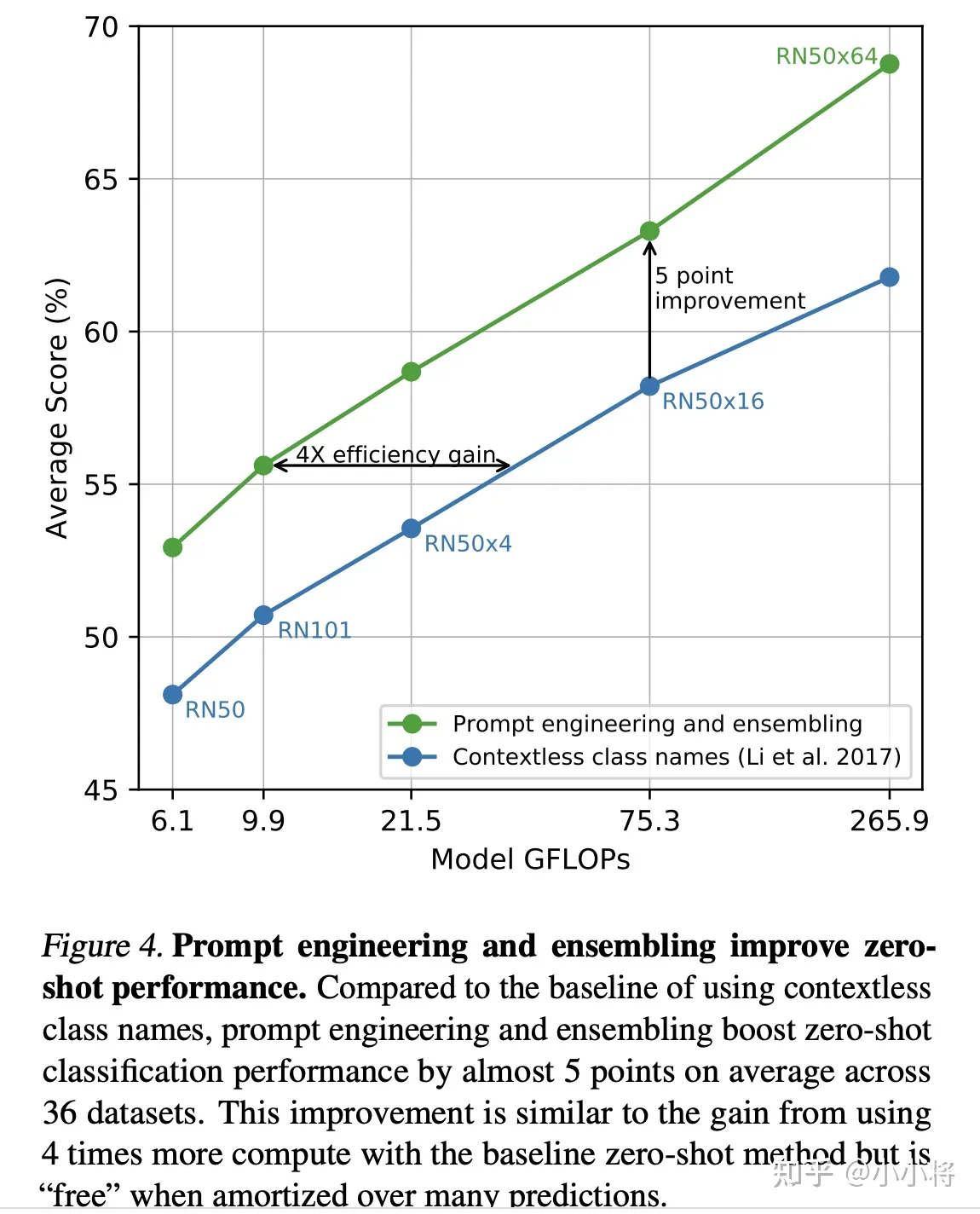
使用CLIP进行zero-shot分类,另外一个比较重要的地方是文本描述的生成,上面的例子我们采用A photo of {label},但其实也有其它选择,比如我们直接用类别标签,这其实属于最近NLP领域比较火的一个研究:prompt learning或者prompt engineering,具体可以见这篇综述论文:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,简单来说,prompt learning的核心是通过构建合适prompt(提示)来使预训练模型能够直接应用到下游任务,这和之前的预训练+微调属于不同的范式。论文也说了,如果我们直接采用类别标签作为文本描述,那么很多文本就是一个单词,缺少具体的上下文,而且也和CLIP的训练数据不太一致,效果上会不如采用A photo of {label}(ImageNet数据集上可以提升1.3%)。论文也实验了采用80个不同的prompt来进行集成,发现在ImageNet数据集上能带来3.5%的提升,具体见CLIP公开的notebook。下图对比了基于ResNet的CLIP模型直接采用类别名与进行prompt engineering和ensembling的效果对比:
上面我们介绍了如何用CLIP实现zero-shot分类,下面将简单介绍CLIP与其它方法的效果对比,这个也是论文中篇幅最多的内容。首先是CLIP和17年的一篇工作Learning Visual N-Grams from Web Data的在3个分类数据集上zero-shot效果对比,如下表所示,可以看到CLIP模型在效果上远远超过之前的模型,其中在ImageNet数据集可以达到76.2,这和全监督的ResNet50效果相当,不用任何训练数据就能达到这个效果是相当惊艳的。

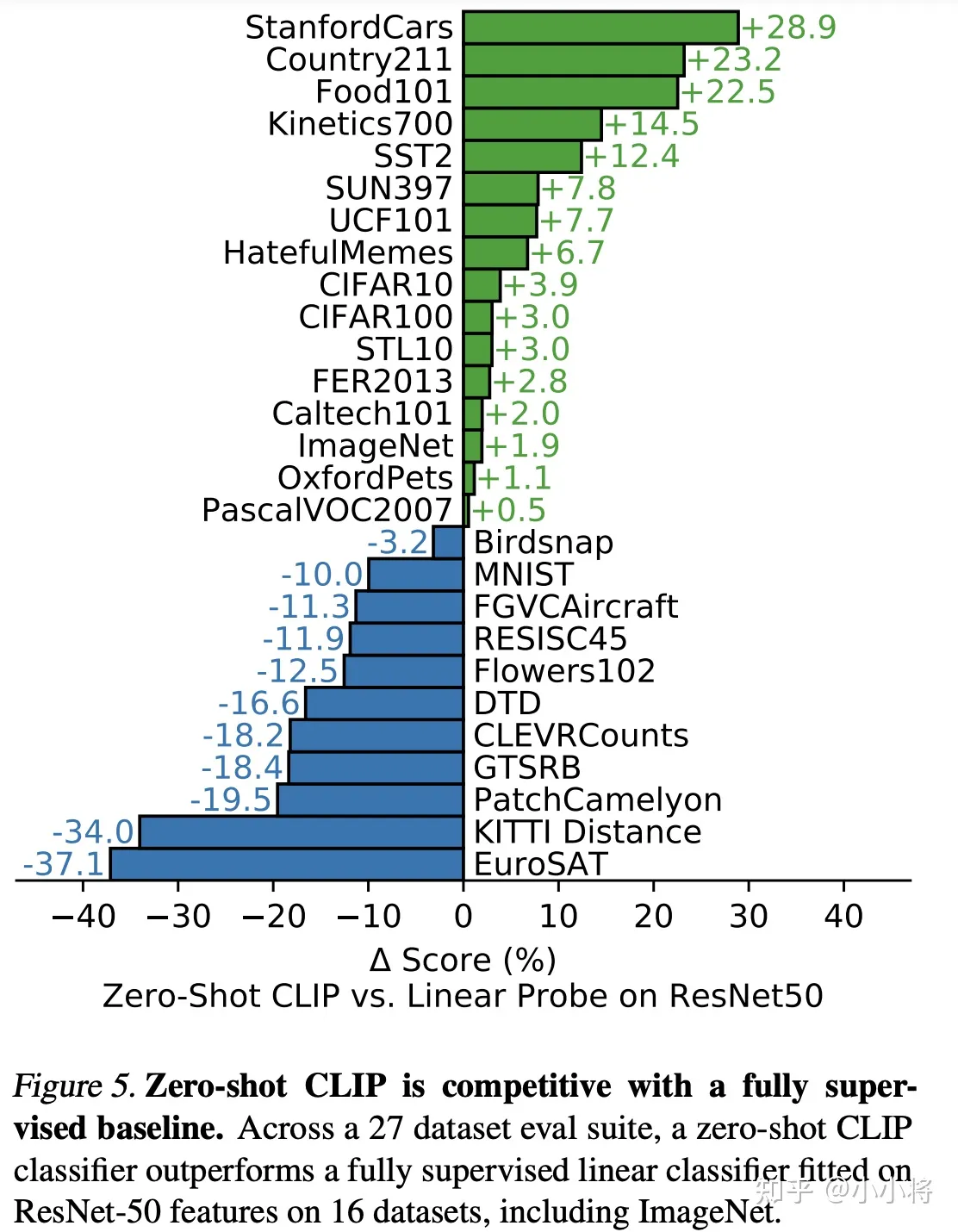
更进一步地,论文还对比了zero-shot CLIP和ResNet50 linear probing(ImageNet数据上预训练,在加上线性分类层进行finetune)在27个数据集上表现,如下图所示,其中在16个数据集上CLIP可以超过ResNet50。但是在一些特别的,复杂的或者抽象的数据集上CLIP表现较差,比如卫星图像分类,淋巴结转移检测,在合成场景中计数等,CLIP的效果不如全监督的ResNet50,这说明CLIP并不是万能的,还是有改进的空间。如果认真看下图的话,CLIP表现较差的竟然还有MNIST数据集,分类准确度只有88%,这是不可思议的,因为这个任务太简单了,通过对CLIP训练数据进行分析,作者发现4亿的训练数据中基本上没有和MNIST比较相似的数据,所以这对CLIP来说就属于域外数据了,表现较差就比较容易理解了。这也表明:CLIP依然无法解决域外泛化这个深度学习难题。
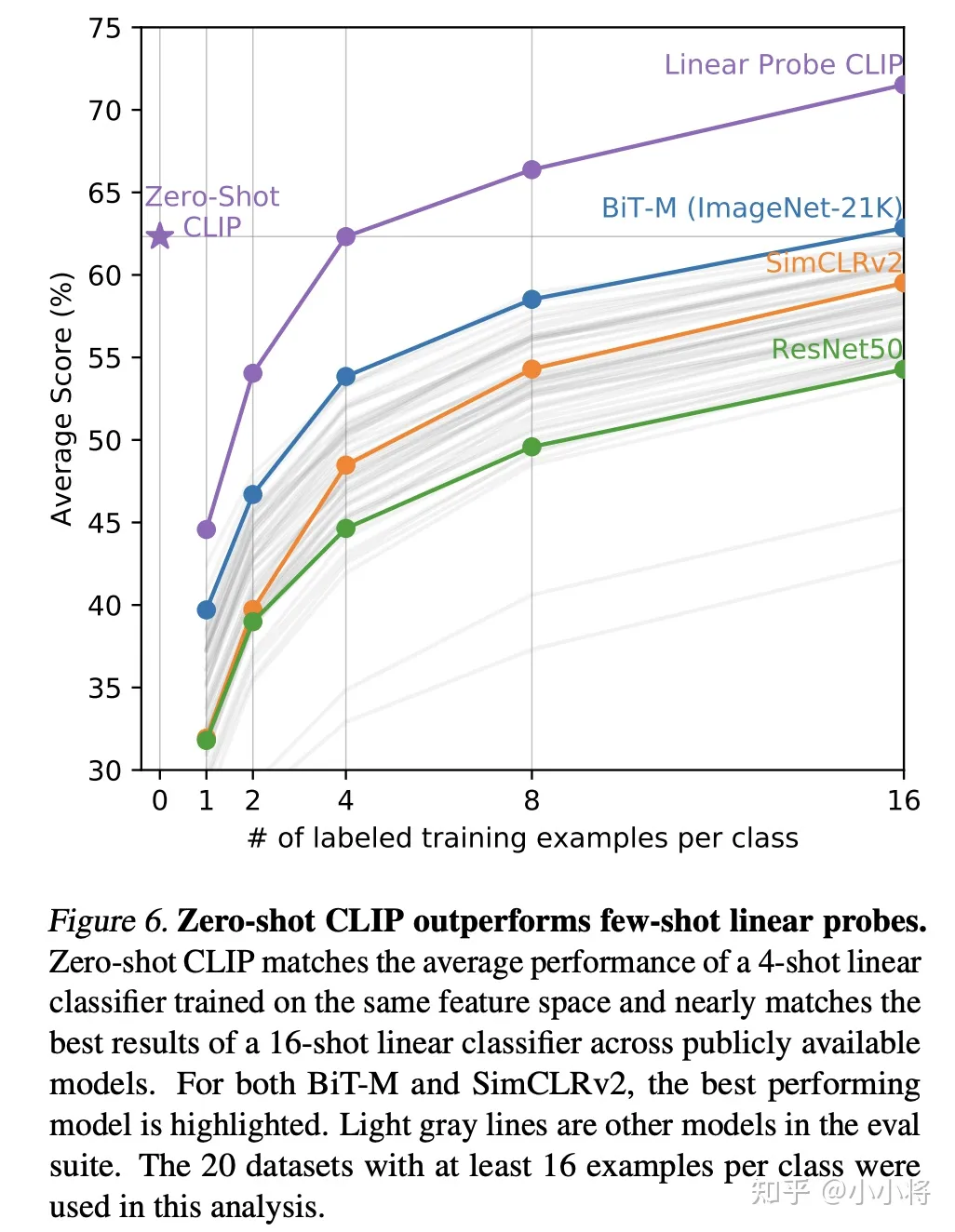
除了zero-shot对比,论文还对比few-shot性能,即只用少量的样本来微调模型,这里对比了3个模型:在ImageNet21K上训练的BiT-M ResNet-152x2,基于SimCLRv2训练的ResNet50,以及有监督训练的ResNet50。可以看到CLIP的zero-shot和最好的模型(BiT-M)在16-shot下的性能相当,而CLIP在16-shot下效果有进一步的提升。另外一个比较有意思的结果是:虽然CLIP在few-shot实验中随着样本量增加性能有提升,但是1-shot和2-shot性能比zero-shot还差,这个作者认为主要是CLIP的训练和常规的有监督训练存在一定的差异造成的。
除此之外,论文还进行了表征学习(representation Learning)实验,即自监督学习中常用的linear probe:用训练好的模型先提取特征,然后用一个线性分类器来有监督训练。下图为不同模型在27个数据集上的average linear probe score对比,可以看到CLIP模型在性能上超过其它模型,而且计算更高效:
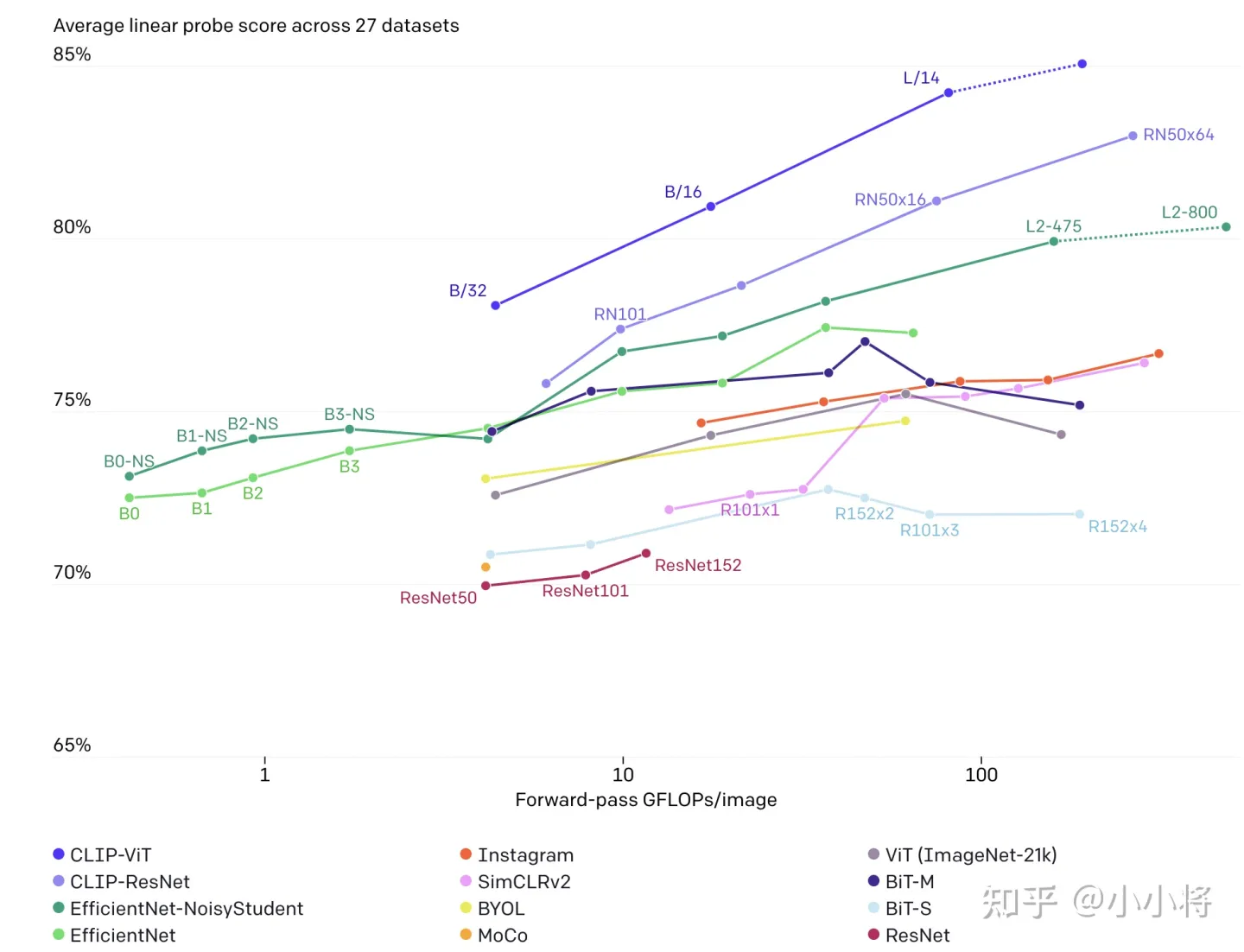
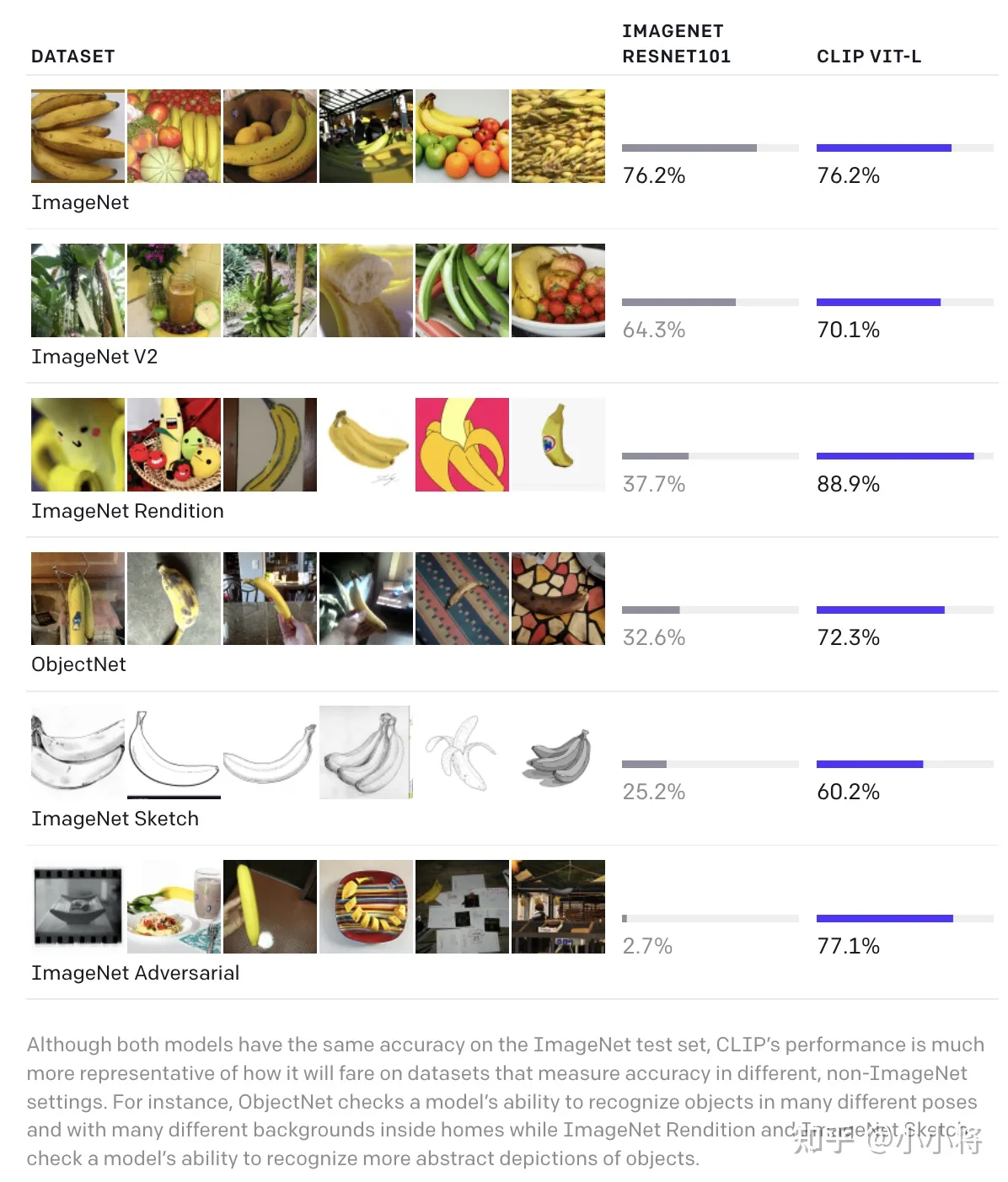
另外,论文还发现CLIP在自然分布漂移上表现更鲁棒,比如CLIP和基于ImageNet上有监督训练的ResNet101在ImageNet验证集都能达到76.2%,但是在ImageNetV2数据集上,CLIP要超过ResNet101。在另外的4个分布漂移的数据集上,ResNet101性能下降得比较厉害,但是CLIP能依然保持较大的准确度,比如在ImageNet-A数据集上,ResNet101性能只有2.7%,而CLIP能达到77.1%。
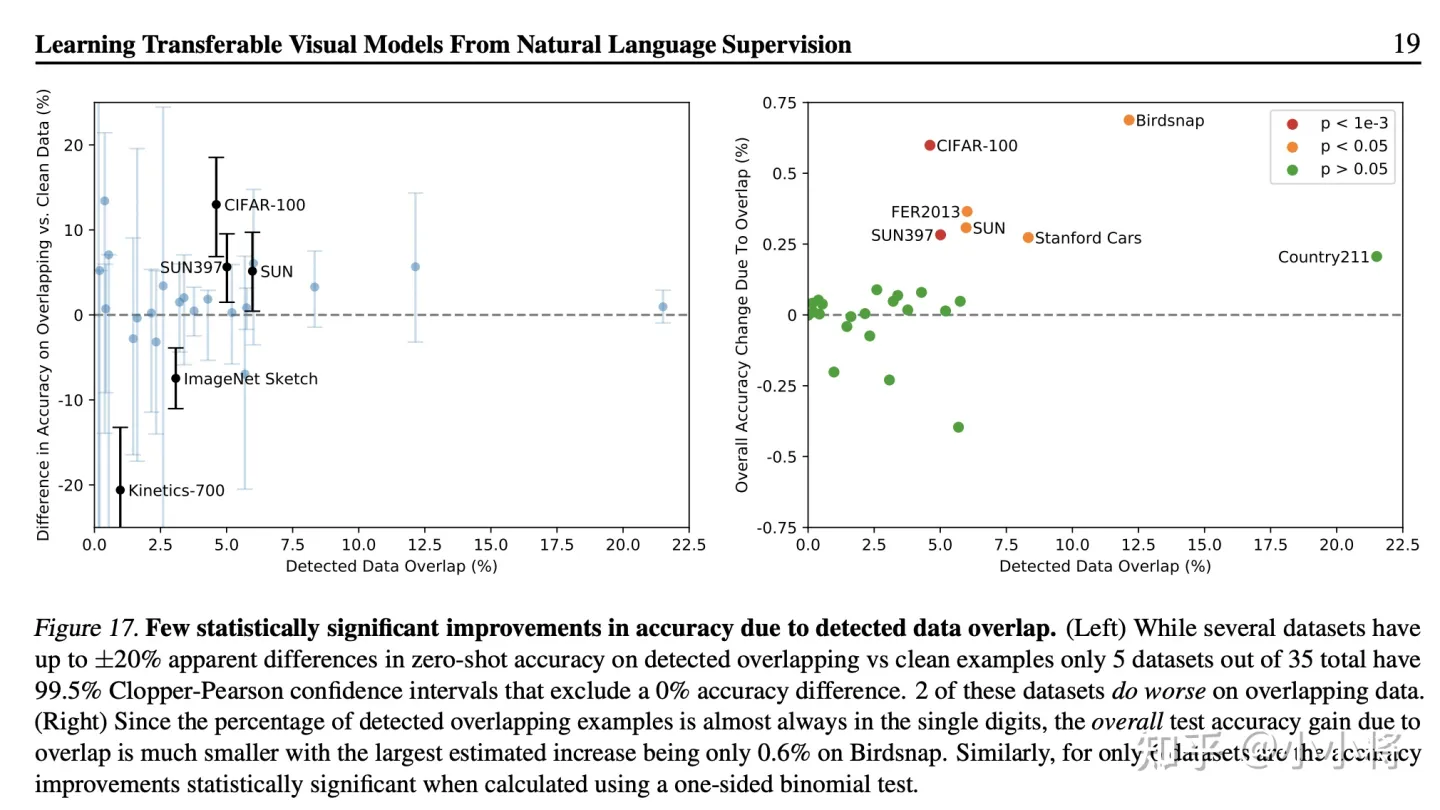
CLIP能实现这么好的zero-shot性能,大家很可能质疑CLIP的训练数据集可能包含一些测试数据集中的样例,即所谓的数据泄漏。关于这点,论文也采用一个重复检测器对评测的数据集重合做了检查,发现重合率的中位数为2.2%,而平均值在3.2%,去重前后大部分数据集的性能没有太大的变化,如下所示:
论文的最后也对CLIP的局限性做了讨论,这里简单总结其中比较重要的几点:
- CLIP的zero-shot性能虽然和有监督的ResNet50相当,但是还不是SOTA,作者估计要达到SOTA的效果,CLIP还需要增加1000x的计算量,这是难以想象的;
- CLIP的zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等;
- CLIP在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差;
- CLIP并没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据;
为什么是CLIP
前面介绍了CLIP的原理和应用,这里我们再回过头来看另外一个问题:为什么是CLIP,即CLIP这篇工作的motivation。 在计算机视觉领域,最常采用的迁移学习方式就是先在一个较大规模的数据集如ImageNet上预训练,然后在具体的下游任务上再进行微调。这里的预训练是基于有监督训练的,需要大量的数据标注,因此成本较高。近年来,出现了一些基于自监督的方法,这包括基于对比学习的方法如MoCo和SimCLR,和基于图像掩码的方法如MAE和BeiT,自监督方法的好处是不再需要标注。但是无论是有监督还是自监督方法,它们在迁移到下游任务时,还是需要进行有监督微调,而无法实现zero-shot。对于有监督模型,由于它们在预训练数据集上采用固定类别数的分类器,所以在新的数据集上需要定义新的分类器来重新训练。对于自监督模型,代理任务往往是辅助来进行表征学习,在迁移到其它数据集时也需要加上新的分类器来进行有监督训练。但是NLP领域,基于自回归或者语言掩码的预训练方法已经取得相对成熟,而且预训练模型很容易直接zero-shot迁移到下游任务,比如OpenAI的GPT-3。这种差异一方面是由于文本和图像属于两个完全不同的模态,另外一个原因就是NLP模型可以采用从互联网上收集的大量文本。那么问题来了:能不能基于互联网上的大量文本来预训练视觉模型?
那么其实之前已经有一些工作研究用文本来作为监督信号来训练视觉模型,比如16年的工作Learning Visual Features from Large Weakly Supervised Data将这转化成一个多标签分类任务来预测图像对应的文本的bag of words;17年的工作Learning Visual N-Grams from Web Data进一步扩展了这个方法来预测n-grams。最近的一些工作采用新的模型架构和预训练方法来从文本学习视觉特征,比如VirTex基于transformer的语言模型,ICMLM基于语言掩码的方法,ConVIRT基于对比学习的方法。整体来看,这方面的工作不是太多,这主要是因为这些方法难以实现较高的性能,比如17年的那篇工作只在ImageNet上实现了11.5%的zero-shot性能,这远远低于ImageNet上的SOTA。另外,还有另外的是一个方向,就是基于文本弱监督来提升性能,比如谷歌的BiT和ViT基于JFT-300M数据集来预训练模型在ImageNet上取得SOTA,JFT-300M数据集是谷歌从互联网上收集的,通过一些自动化的手段来将web text来转化成18291个类别,但是存在一定的噪音。虽然谷歌基于JFT-300M数据集取得了较好的结果,但是这些模型依然采用固定类别的softmax分类器进行预训练,这大大限制了它的迁移能力和扩展性。
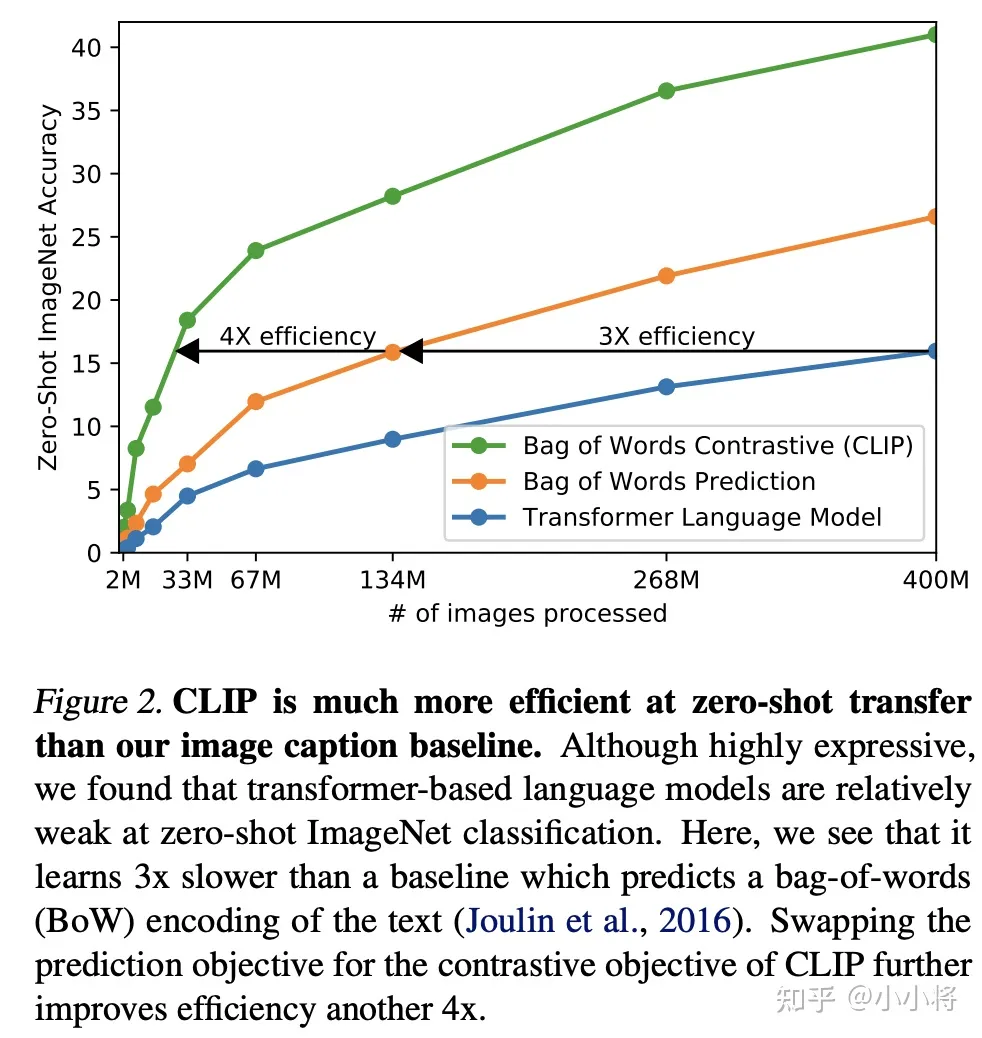
作者认为谷歌的弱监督方法和之前的方法的一个重要的区别在于规模,或者说算力和数据的规模不同。JFT-300M数据量达到了上亿级别,而且谷歌用了强大的算力来进行预训练。而VirTex,ICMLM和ConVIRT只在10万级别的数据上训练了几天。为了弥补数据上的差异,OpenAI从网上收集了4亿的数据来实验。但是新的问题来了:采用什么样的方法来训练。OpenAI首先尝试了VirTex模型,即联合训练一个CNN和文本transformer来预测图像的文本(image caption),但是发现这种方法的训练效率(用ImageNet数据集上的zero-shot性能来评估)还不如直接预测bag of words,如下图所示,两者的训练效率能相差3倍。如果进一步采用ConVIRT,即基于对比学习的方法,训练效率可以进一步提升4倍。之所出现这个差异,这不难理解,训练数据所包含的文本-图像对是从互联网收集来的,它们存在一定的噪音,就是说文本和图像可能并不完全匹配,这个时候适当的降低训练目标,反而能取得更好的收敛。而从任务难度来看:Transformer Language Model > Bag of Words Prediction > Bag of Words Contrastive (CLIP)。由于训练数据量和模型计算量较大,训练效率成为一个至关重要的因素。这就是作者最终选择对比学习的方法来训练的原因。
从本质上来讲,CLIP其实并没有太大的创新,它只是将ConVIRT方法进行简化,并采用更大规模的文本-图像对数据集来训练。
在论文的最后,作者也谈到了由于训练效率的制约,他们采用了对比学习的方法,但是他们依然想做的是直接用图像生成文本,这个如果能成功,那么就和DALL-E这个工作形成闭环了:文本 -> 图像 -> 文本。而且基于生成式训练出来的模型,同样可以实现zero-shot分类,我们可以通过预测句子中的单词(标签)来实现:A photo of [?]。
CLIP还可以做什么
虽然论文中只对用CLIP进行zero-shot分类做了实验,但其实CLIP的应用价值远不止此,CLIP之后出现了很多基于CLIP的应用研究,这里我们列出一些应用场景
zero-shot检测
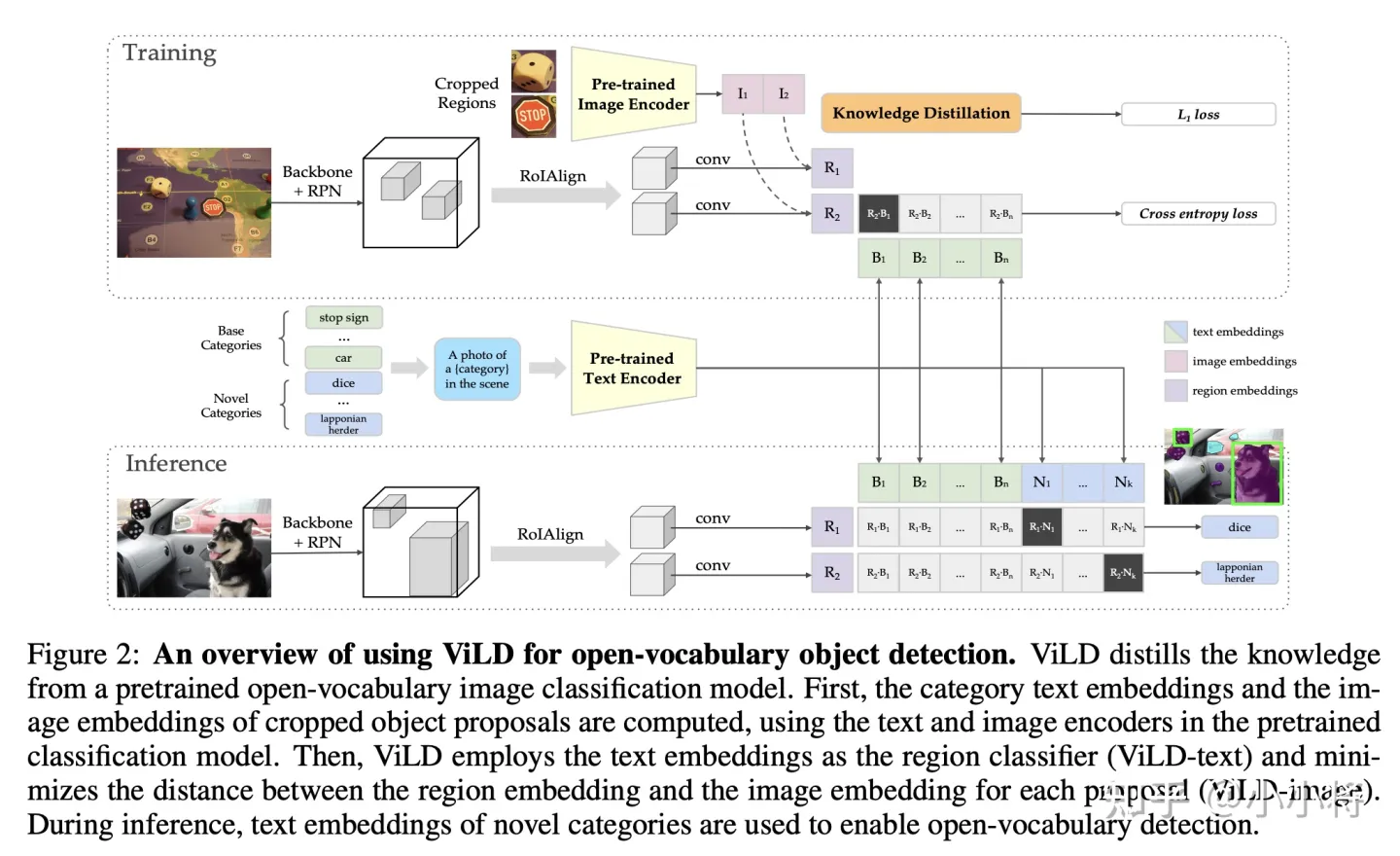
CLIP可以应用在目标检测任务上,实现zero-shot检测,即检测训练数据集没有包含的类别,比如谷歌提出的ViLD基于CLIP实现了开放词汇的物体检测,其主体架构如下所示,其基本思路和zero-shot分类相似,只不过这里是用文本特征和ROI特征来计算相似度。
Meta AI的最新工作Detic可以检测2000个类,背后也用到了CLIP:
图像检索
基于文本来搜索图像是CLIP最能直接实现的一个应用,其实CLIP也是作为DALL-E的排序模型,即从生成的图像中选择和文本相关性较高的。
视频理解
CLIP是基于文本-图像对来做的,但是它可以扩展到文本-视频,比如VideoCLIP就是将CLIP应用在视频领域来实现一些zero-shot视频理解任务。
图像编辑
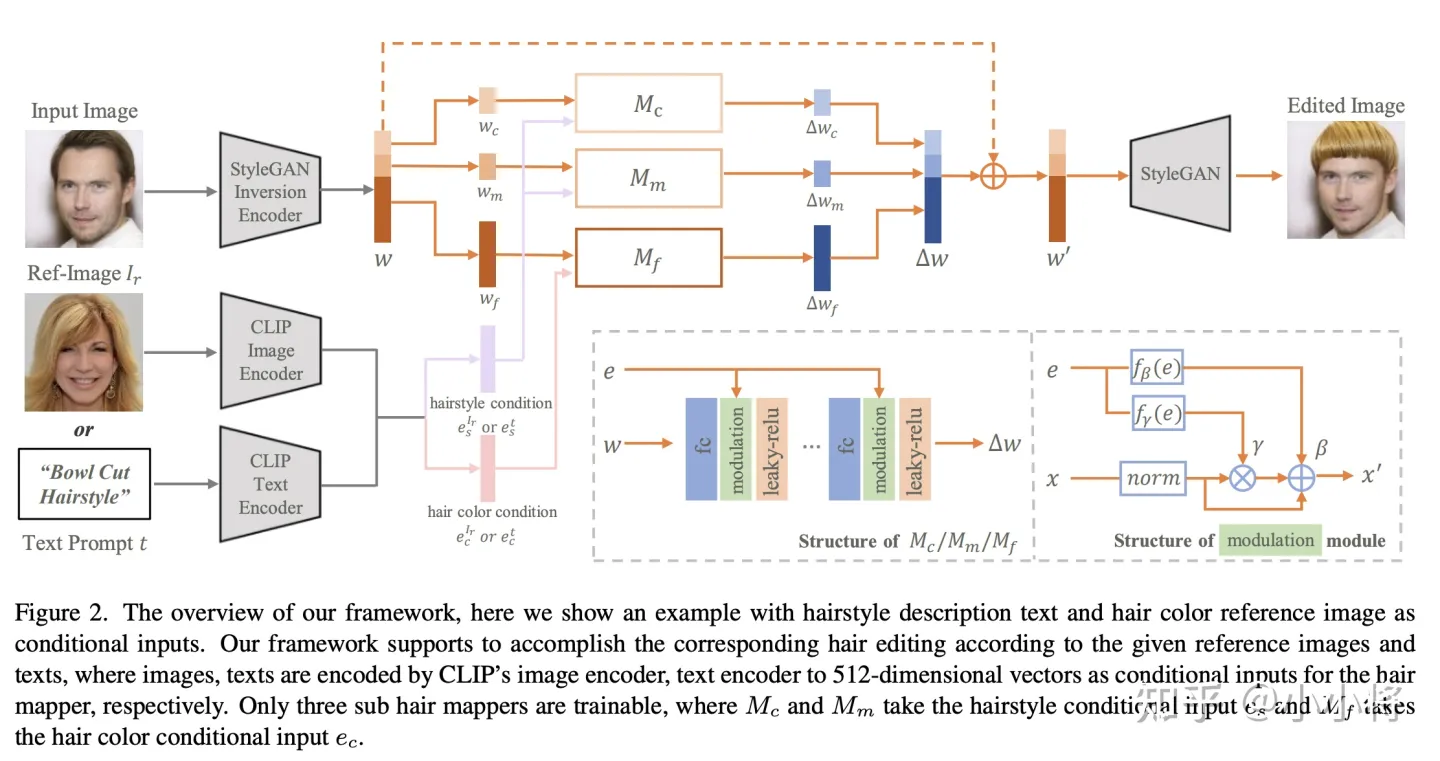
CLIP可以用在指导图像编辑任务上,HairCLIP这篇工作用CLIP来定制化修改发型:
图像生成
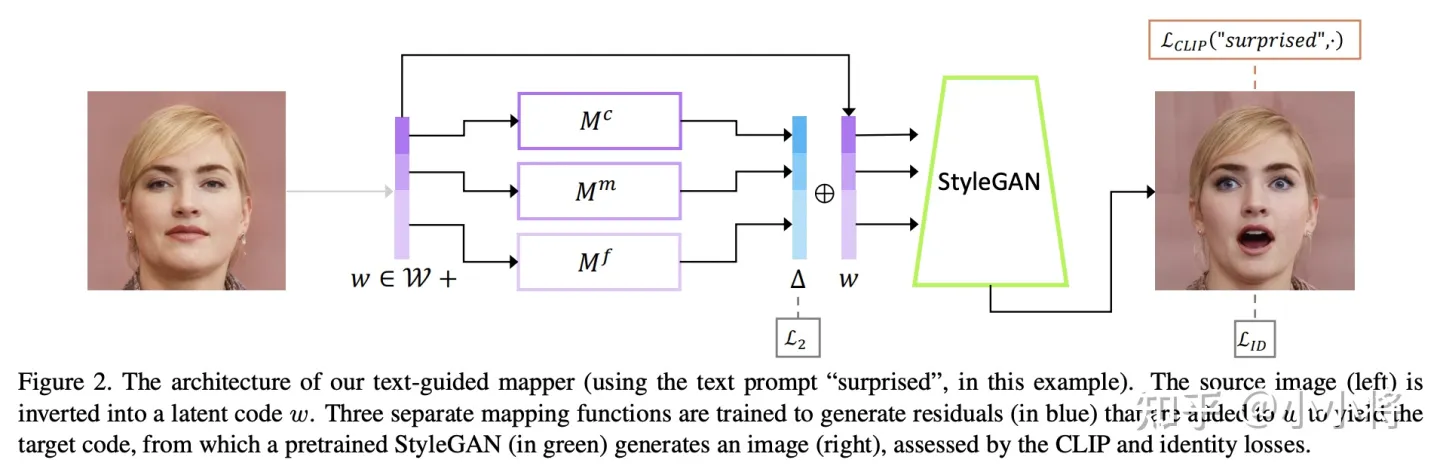
CLIP还可以应用在图像生成上,比如StyleCLIP这篇工作用CLIP实现了文本引导的StyleGAN:
CLIP-GEN这篇工作基于CLIP来训练文本生成图像模型,训练无需直接采用任何文本数据:
自监督学习
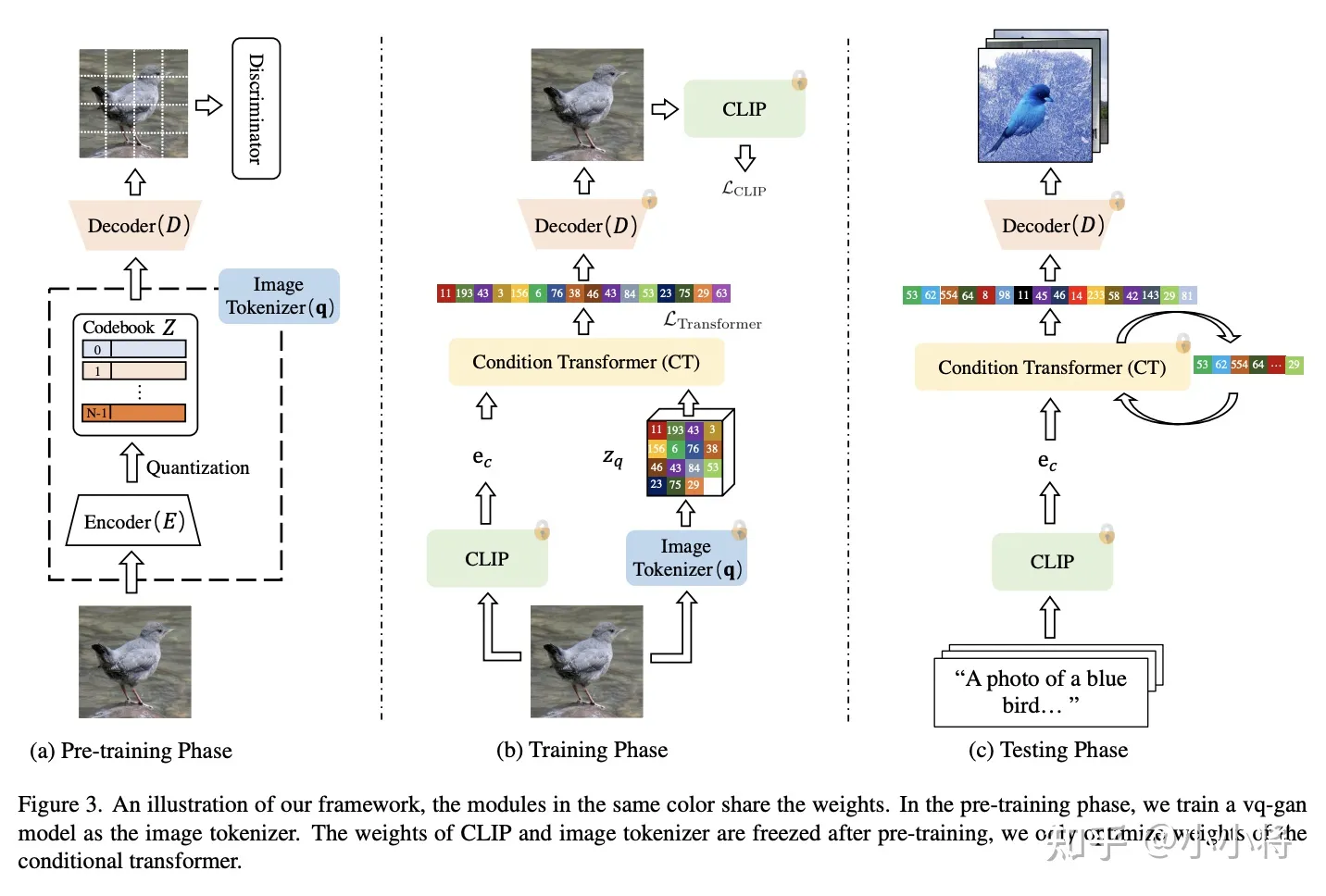
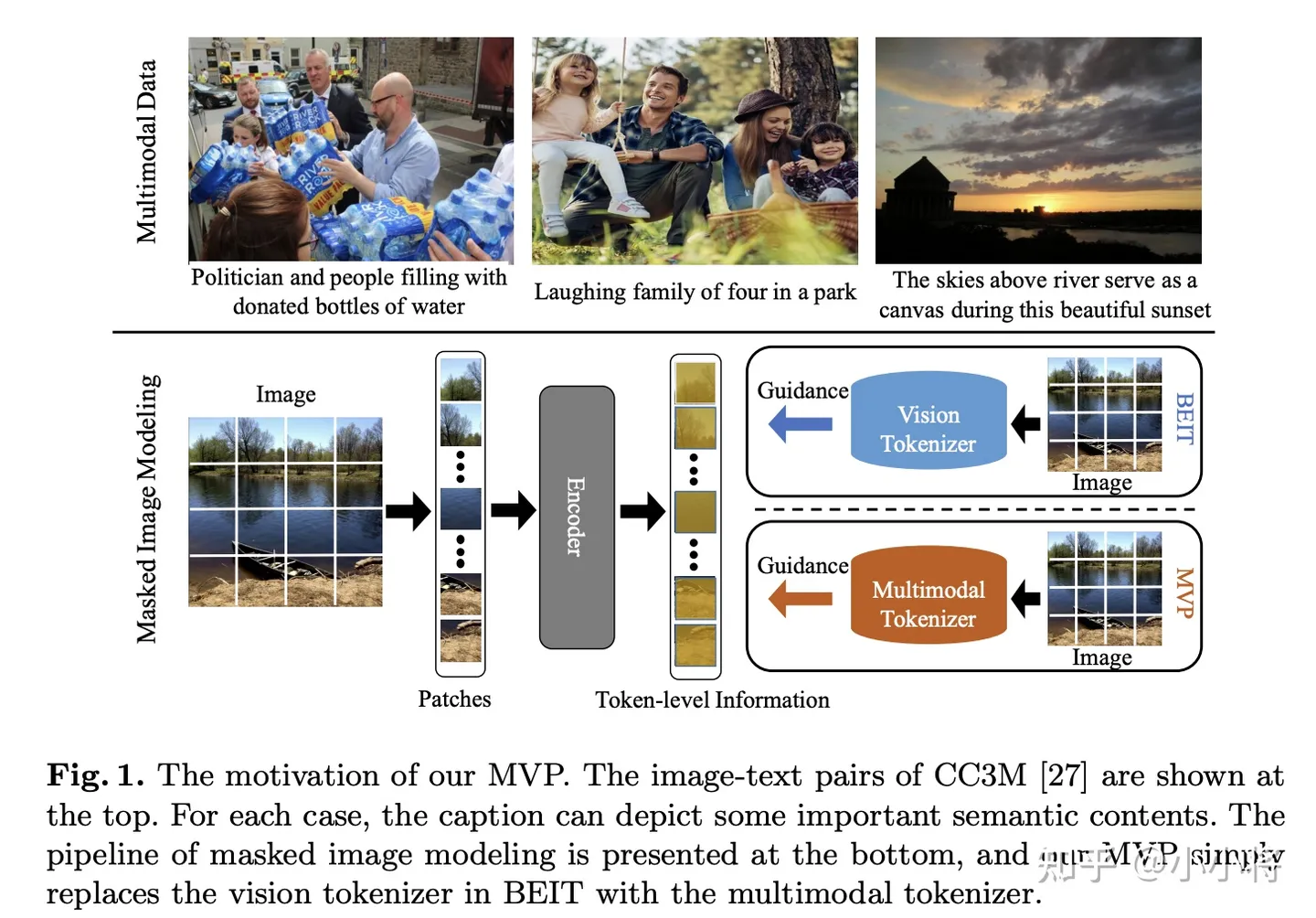
最近华为的工作MVP更是采用CLIP来进行视觉自监督训练:
VL任务
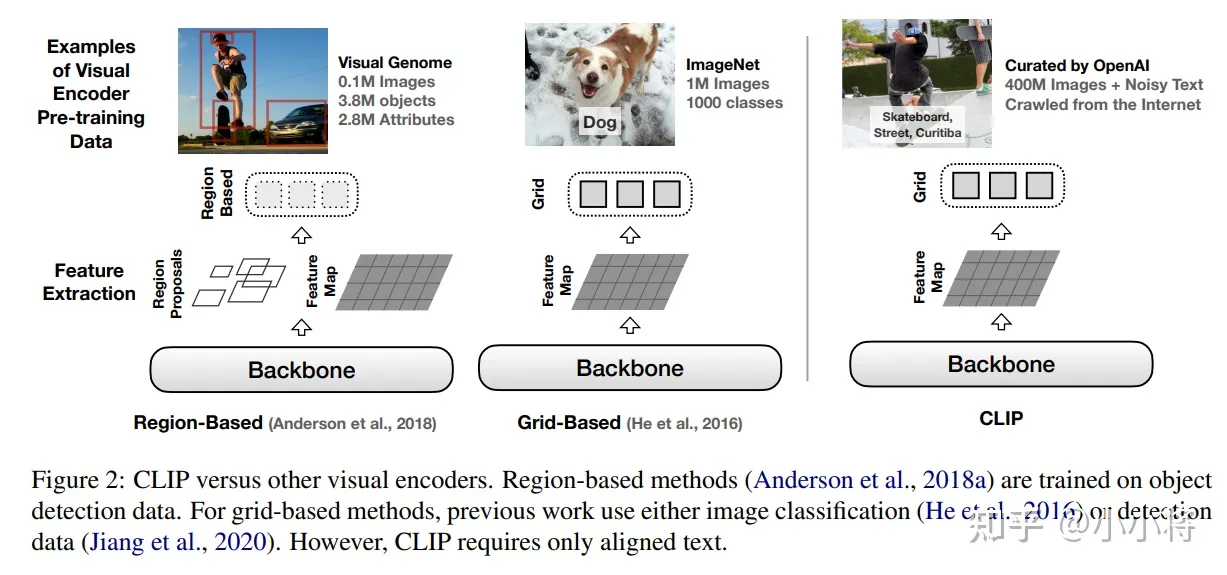
CLIP本身就是多模态模型,所以它也可以用在用图像-文本多模态任务,如图像描述(image caption)和视觉问答(Visual Question Answering),这篇论文How Much Can CLIP Benefit Vision-and-Language Tasks?系统评估了CLIP在VL任务上带来的收益。
从这些具体的应用可以进一步看到CLIP的强大。
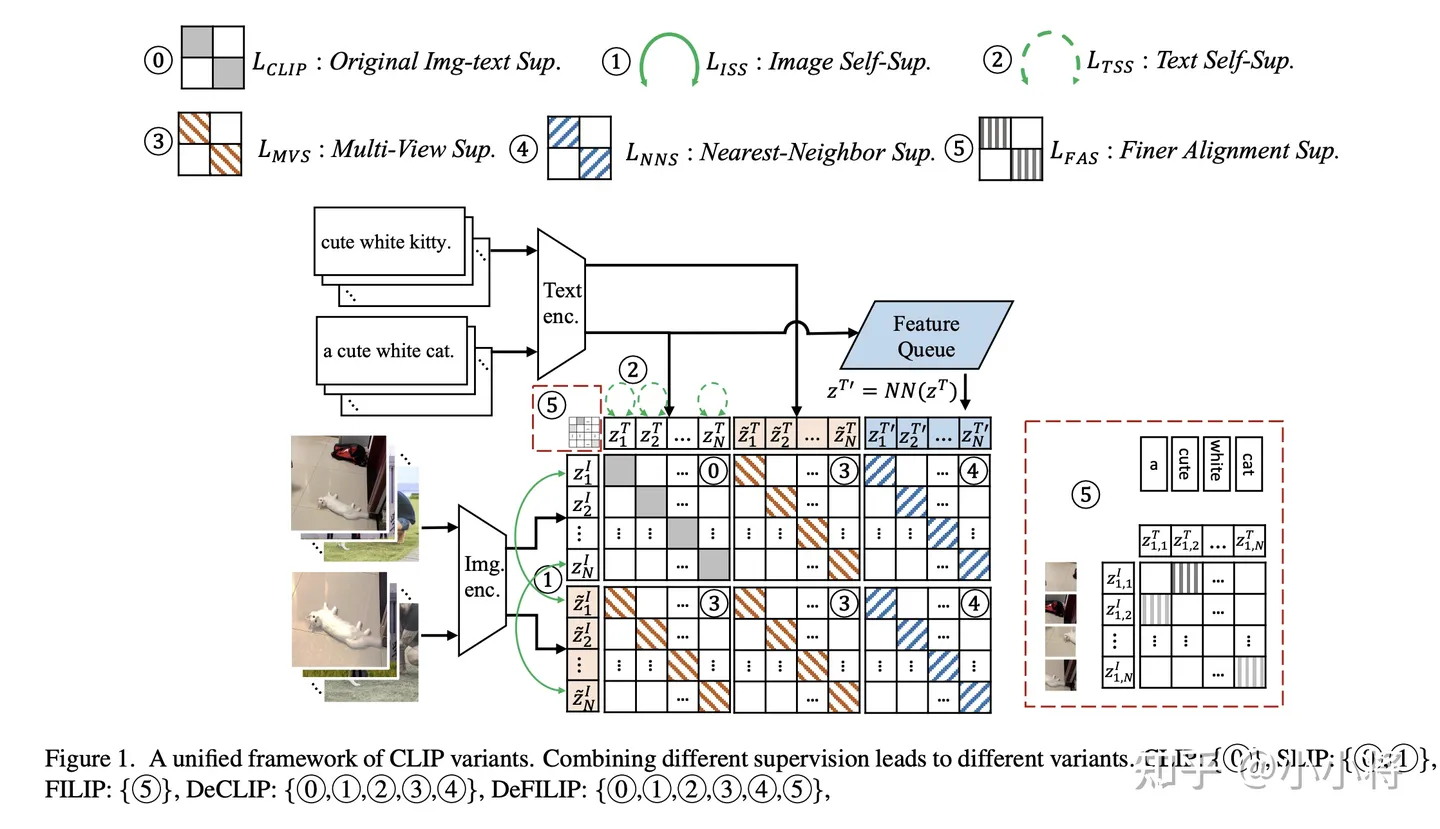
除了一些应用研究工作,其实还有针对CLIP的一些改进工作,最新的一篇论文Democratizing Contrastive Language-Image Pre-training: A CLIP Benchmark of Data, Model, and Supervision总结了几种对CLIP的改进:
总结
这篇文章系统地总结了CLIP的原理以及它的具体应用,我个人认为:CLIP和ViT属于相同量级的工作,它们都打破了计算机视觉的原有范式,必将在CV历史上留名。
参考
- https://openai.com/blog/clip/
- https://github.com/openai/CLIP
- Learning Transferable Visual Models From Natural Language Supervision
- CLIP 论文逐段精读【论文精读】 - 知乎
- https://github.com/yzhuoning/Aw