前言:
深度学习对数据量要求非常大,
我们通常会遇到图像的数据集比较小,影响Train效果。
这个时候可以通过transformer 方法,增加图像的多样性,达到数据
增强的效果。
transformer 不会单独使用,通常和其它torch 其他类一起使用
transformer 常用方法如下
| 方法 | 说明 |
| Resize | 调整图片大小 |
| Normalize | 按照指定的均值,方差 正规化 |
| ToTensor | convert a PIL image to tensor |
| ToPILImage | convert a tensor to PIL imageScale |
| ResizeCenterCrop | 在图片的中间区域进行裁剪 |
| RandomCrop | 在一个随机的位置进行裁剪 |
| RandomHorizontalFlip | 以0.5的概率水平翻转给定的PIL图像。 |
| RandomVerticalFlip | 以0.5的概率竖直翻转给定的PIL图像 |
| RandomResizedCrop | 将PIL图像裁剪成任意大小和纵横比 |
| Grayscale | 将图像转换为灰度图像 |
| RandomGrayscale | 将图像以一定的概率转换为灰度图像 |
| FiceCrop | 把图像裁剪为四个角和一个中心T |
| enCropPad | 填充ColorJitter:随机改变图像的亮度对比度和饱和度 |
这里结合summaryWriter,torchvision.datasets, torch.utils.data.DataLoader
介绍一下其使用方法
目录:
- summaryWriter
- torchvision.datasets
- torch.utils.data.DataLoader
一 summaryWriter
1.1 功能简介
Writes entries directly to event files in the log_dir to be
consumed by TensorBoard.
The `SummaryWriter` class provides a high-level API to create an event file
in a given directory and add summaries and events to it. The class updates the
file contents asynchronously. This allows a training program to call methods
to add data to the file directly from the training loop, without slowing down
training.
"""
SummaryWriter` 类用于在给定目录中创建事件文件,并向其中添加摘要和事件。 然后通过cmd 命令启动该TensorBoard 服务,在浏览器中可以查看对应的图形化界面.
1.2 环境安装
pip install tensorboard
pip install tensorflow(不安装UI 显示不出来)
1.3 张量添加
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("ZCH_Tensorboard_Trying_logs") #第一个参数指明 writer 把summary内容 写在哪个目录下
for i in range(100):
writer.add_scalar("y=x",i,i)
for i in range(100):
writer.add_scalar("2I",2*i,i)
for i in range(100):
writer.add_scalar("5I",5*i,i)
for i in range(100):
writer.add_scalar("9I",9*i,i)
writer.close() #将event log写完之后,记得close()两步:
step1 生成summaryWriter 对象writer
step2 通过add_scalar 方法,添加数据
重要的常用的其实就是前三个参数:
( 1)tag:要求是一个string,用以描述 该标量数据图的 标题
(2)scalar_value :可以简单理解为一个y轴值的列表
(3)global_step:可以简单理解为一个x轴值的列表,与y轴的值相对应
当启动Tensorboard 可以通过红色的部分过滤,切换想要查看的项目
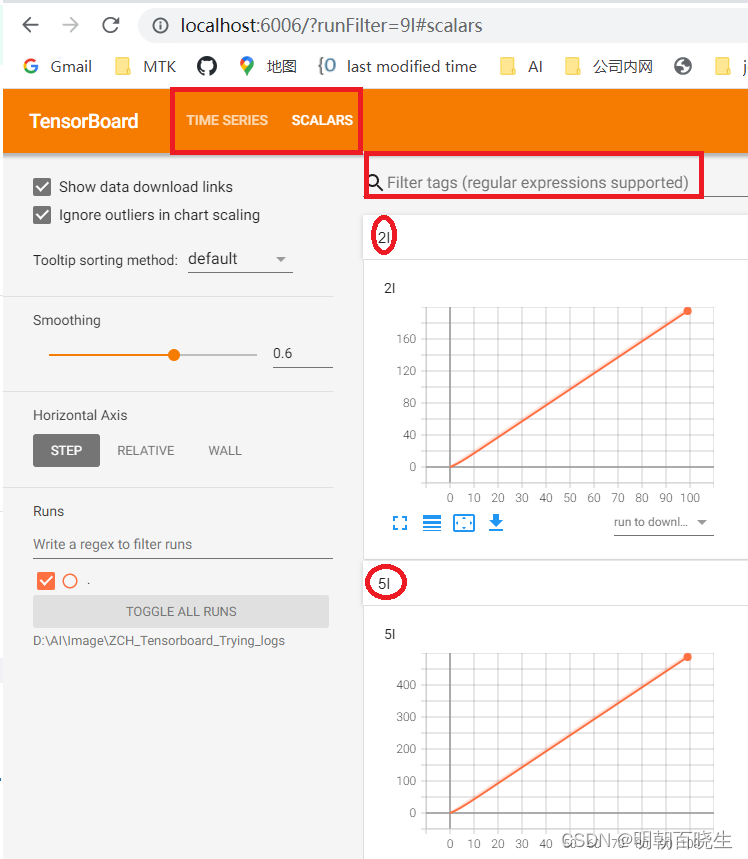
1.4 启动tensorBoard

windows 命令窗口中输入
tensorboard --logdir=ZCH_Tensorboard_Trying_logs(最好是完整路径)
http://localhost:6006/
程序执行前可以加上如下,把之前旧的删除掉
if os.path.exists('logs'):
shutil.rmtree('logs')# 如果文件存在,则递归的删除文件内容
print('Remove log dir')
1.5 add_image
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "src/1.jpeg"
img = Image.open(img_path)
writer = SummaryWriter("imglogs")
# ToTensor
trans_tensor = transforms.ToTensor() # PIL Image or numpy.array
img_tensor = trans_tensor(img)
writer.add_image("src img", img_tensor)
# Compose中参数需要一个列表,列表形式为[数据1, 数据2, ...]
# 在Compose中,数据需要的是transforms类型, Compose([transforms参数1, transforms参数2, ...])
trans_resize_2 = transforms.Resize(256) # Resize中一个数,为按照图片最小边进行缩放
trans_compose = transforms.Compose([trans_resize_2, trans_tensor]) # 第一个参数:改变图片大小,第二个参数:转换类型
img_resize_2 = trans_compose(img)
writer.add_image("reseize img", img_resize_2, 1)
writer.close()在cmd 命令中输入
tensorboard --logdir=D:\AI\Image\imglogs

二 torchvision.datasets
torch.utils.data.Dataset() (官方文档),它是 Pytorch 中表示数据集的抽象类,
datasets这个包有很多数据集,比如MINIST、COCO、CIFAR10 and CIFAR100、LSUN 、Classification、ImageFolder、Imagenet-12、STL10。torchvision.datasets中的数据集封装都是torch.utils.data.Dataset子类,它们都实现了__getitem__ 和 __len__方法,都可以用DataLoader进行数据加载。
torchvision.datasets.MNIST(root,train = True,transform = None,target_transform = None,download = False )
| 参数 | 介绍 |
| root | 根目录 |
| train | 如果为True,训练集,否则是测试集 |
| download | 如果为true,根目录没有数据集就会自动在这个目录下载 |
| transform | 数据集预处理,比如归一化当图形转换类的操作 |
| target_transform | 接收目标并对其进行转换的函数/转换 |
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import ssl
root_dir = "./data_cifar10"
print("\n step1: ")
ssl._create_default_https_context = ssl._create_unverified_context
dataset_train = datasets.CIFAR10(root=root_dir, train=True, transform=transforms.ToTensor(), download=True)
dataset_test = datasets.CIFAR10(root=root_dir, train=False, transform=transforms.ToTensor(), download=True)
print("\n step2: ")
dataloader_train = DataLoader(dataset=dataset_train, batch_size=64, shuffle=True, drop_last=True)
dataloader_test = DataLoader(dataset=dataset_test, batch_size=64, shuffle=True, drop_last=True)
log_dir = "logs"
writer = SummaryWriter(log_dir=log_dir)
print("\n writer")
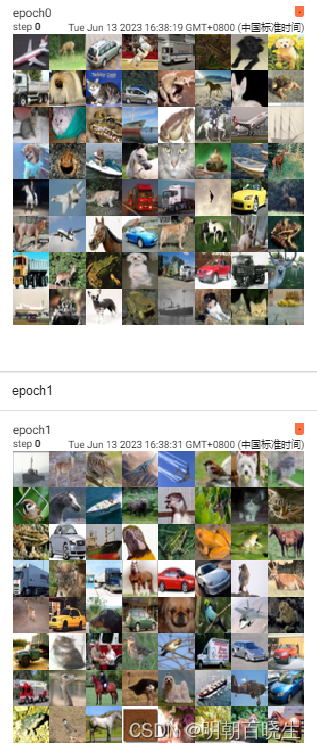
number = 0
for epoch in range(2):
step = 0
for data_imgs, data_targets in dataloader_test:
print("\n data_imgs ",number)
number+=1
writer.add_images(f"epoch{number}", data_imgs, step) #
step += 1
print("\n---end---")
writer.close()输入: tensorboard –logdir=D:\AI\Image\imglogs
1 COCO数据集
是一个可用于图像检测(image detection),语义分割(semantic segmentation)和图像标题生成(image captioning)的大规模数据集。它有超过330K张图像(其中220K张是有标注的图像),包含150万个目标,80个目标类别(object categories:行人、汽车、大象等),91种材料类别(stuff categoris:草、墙、天空等),每张图像包含五句图像的语句描述,且有250,000个带关键点标注的行人。
mscoco.org/2 CIFAR-10数据集
由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示。3、LSUN数据集
PASCAL VOC和ImageNet ILSVRC比赛使用的数据集,数据领域包括卧室、冰箱、教师、厨房、起居室、酒店等多个主题。
它包含10个场景类别和20个对象类别中的每个类别的大约一百万张带标签的图像。
下载地址:https://www.yf.io/p/lsun
4、谷歌Open Images图像数据集
其中包括大约9百万标注图片、横跨6000个类别标签,平均每个图像拥有8个标签。
该数据集的标签涵盖比拥有1000个类别标签的ImageNet具体更多的现实实体,可用于计算机视觉方向的训练。5、ImageNet数据集
ImageNet数据集是目前深度学习图像领域应用得非常多的一个领域,该数据集有1000多个图像,涵盖图像分类、定位、检测等应用方向。
Imagenet数据集文档详细,有专门的团队维护,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。很多大型科技公司都会参加ImageNet图像识别大赛,包括百度、谷歌、微软等
三 torch.utils.data.DataLoader
一般来说PyTorch中深度学习训练的流程是这样的:
1. 创建Dateset
2. Dataset传递给DataLoader
3. DataLoader迭代产生训练数据提供给模型
torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None)| 参数 | 说明 |
| dataset | 加载数据的数据集 |
| batch_size | 每个batch加载多少个样本 |
| shuffle | 设置为True时会在每个epoch重新打乱数据(默认: False) |
| sampler | 定义从数据集中提取样本的策略,即生成index的方式,可以顺序也可以乱序 |
| num_workers | 用多少个子进程加载数据。0:数据将在主进程中加载(默认: 0) |
| collate_fn | 将一个batch的数据和标签进行合并操作 |
| pin_memory | 设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。 |
| drop_last | 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False) |
| timeout | 用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。 |
| worker_init_fn | 如果不是None,将在播种之后和数据加载之前,对每个worker子进程使用worker id (int in [0, num_workers - 1])作为输入调用。(默认值:None) |
#案例 from https://blog.csdn.net/weixin_43981621/article/details/119685671
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
# 准备的测试数据集 数据放在了CIFAR10文件夹下
root_dir = "./data_cifar10"
dataset_train = datasets.CIFAR10(root=root_dir, train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(
dataset=dataset_train,
batch_size=4,
shuffle=True,
num_workers=0,
drop_last=False
)
# 设置参数batch_size=4时,每次取了4张照片,并获得4个targets标签。
# 在定义test_loader时,设置了batch_size=4,表示一次性从数据集中取出4个数据
for data in train_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 13 16:45:55 2023
@author: chengxf2
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
# 数据预处理
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081))])
# 训练集
train_dataset = datasets.MNIST(root='../data/mnist',train=True, download=True, transform=transform)
# 测试集
test_dataset=datasets.MNIST(root='../data/mnist',train=False, download=True, transform=transform)
# 数据集加载器
train_loader= DataLoader(dataset = train_dataset, # 数据加载
batch_size = 4, # 送入多少张图片
shuffle = True, #对原有数据排序是否打乱
num_workers = 0, #是否进行多进程加载数据设置
drop_last = False) #最后的数据组不成一个batch_size 是否丢弃参数:
dataset:数据加载
batch_size :送入多少张图片
shuffle :是否打乱数据
sampler :指定数据加载中使用的索引/键的序列
batch_sampler = None,#和sampler类似
num_workers :是否进行多进程加载数据设置
collate_fn = None,#是否合并样本列表以形成一小批Tensor
pin_memory :数据加载器会在返回之前将Tensors复制到CUDA固定内存
drop_last :最后的数据组不成一个batch_size 是否丢弃
有时候也综合起来使用,如下: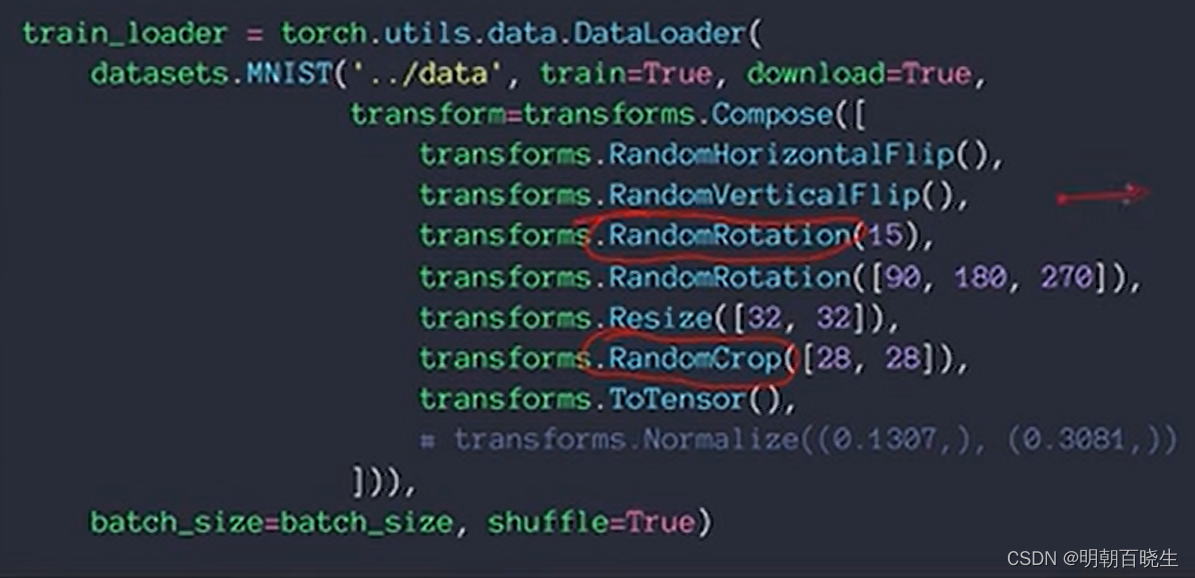
参考:
https://zhuanlan.zhihu.com/p/463799442 [torchvision 介绍]
https://blog.csdn.net/qq_41764621/article/details/126210936【SummaryWriter类】
https://blog.csdn.net/m0_51233386/article/details/127645795【 SummaryWriter类】
https://blog.csdn.net/qq_43456016/article/details/130072202[图像增强(Transforms]
https://zhuanlan.zhihu.com/p/463799442【torchvision中的数据集使用】
https://blog.csdn.net/weixin_45464524/article/details/128043516
https://www.cnblogs.com/lucky-light/p/15535282.html