线性表
用于存储若干相同属性元素的有序序列称为线性表。
线性表特征:
- 存在唯一的第一个元素;
- 存在唯一的最后一个元素;
- 除第一个序列的每一个元素元素都有一个前驱元素,后一个都有一个后继元素。
顺序表
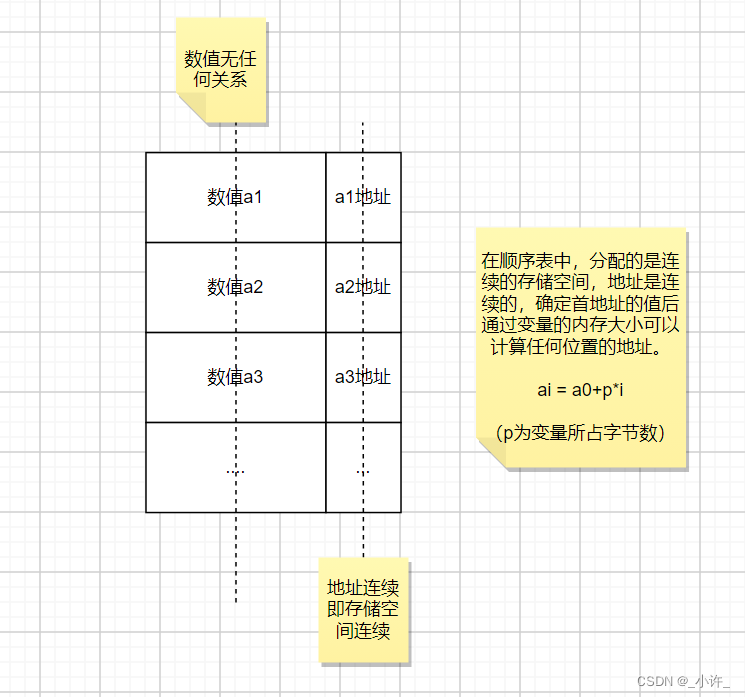
线性表的顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素, 这种表示
也称作线性表的顺序存储结构,称为顺序表。
顺序表满足等差数列:LOC(a;+ 1) = LOC(a;) + i
线性表的第l个数据元素a;的存储位置为: LOC(a;) = LOC(a1) + (i - I) x i
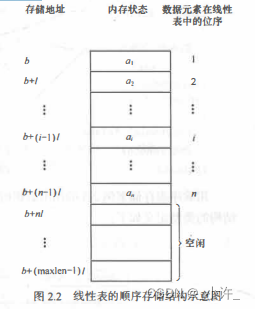
LOC(a1)是线性表的第一个数据元素a1 的存储 存储地址位置,·通常称作线性表的起始位置或基地址, 表中相邻的元素a; 和a; + I 的存储位置LOC(a;)和LOC(a;+ 1) 是相邻的。因此顺序表中最要的就是起始地址,知道起始地址可以计算任何位置的值。只要确定了存储线性表的起始位置, 线性表中任一数据元素都可随机存取, 所以线性表的顺序存储结构是一种随机存取的存储结构。
数组是c语言中比较特殊一种数据结构,不同于int,float类型,数组的若干个基本数据类型的集合,可以存储多个基本数据类型变量的数据类型。数组的本质也是一个数据类型,只不过会存错多个变量的值。
顺序表也是基于数组实现,可以是动态分配存储空间,也可以是定值表空间。
对于顺序表的数据结构需要对数据实现增删改查的操作。(数组只能用户存储,无操作。如果顺序表基于定值数组实现,那么顺序表至少包含两个信息,表的长度和表的数据。
- 添加
数组可以通过循环赋值来实现,顺序表需要试下对数组的操作,在某个位置添加元素,或者通过尾插法,头插法添加数据。
尾部插入数据需要将数组长度加一,并将新的的数组元素的值赋值;在数组任意部位插入值需要将数组该位置之后的元素全部后移一位,给新增的元素空出位置。
- 修改
修改就是重新赋值,就是重新个表的指定位置重新赋值。
- 删除
删除和添加类似,需要先找到指定位置的元素,在该位置处将后一个元素赋值给前一个元素即该位置处元素前移一位。
- 查找
查找需要遍历表的所有元素,直到找到所需元素的位置,遍历即可。
变量是用来信息的,语言间信息分成了若干类即基本数据类型,如int,float,long等,但是这些只能存储一个信息,对于某一类信息的集合无法存储,于是有了数组的数据类型,用于存储同一类型的变量。顺序表就是实现对数组类型的操作。
#include<stdio.h>
#define MAXSIZE 10
//结构体定义
struct List{
int item[MAXSIZE];
int length;
};
//结构体声明
typedef struct List SeqList;
//方法申明
int InitList(SeqList *list);
int AddElem(SeqList *list ,int e);
int InsertElem(SeqList *list,int i,int e);
int GetElem(SeqList *list,int e);
int DeleteElem(SeqList *list,int n);
void displayElem(SeqList list);
int main(){
SeqList a;
InitList(&a);
AddElem(&a,2);
AddElem(&a,8);
InsertElem(&a,1,10);
InsertElem(&a,3,20);
//InsertElem(&a,8,200); //插入失败但是没有提示
displayElem(a);
int tmp = GetElem(&a,8);
printf("取出的值位次为:%d\n",tmp);
DeleteElem(&a,1);
displayElem(a);
}
// list -> item <===> (*list).item
int InitList(SeqList *list){
list -> item[0] = 0;
list -> length = 0;
if (!list) return 0;
return 1;
}
int AddElem(SeqList *list ,int e){
//判断表是否满(略)
int i = list->length ;
list ->item[i] = e;
list->length ++;
}
int InsertElem(SeqList *list,int i,int e){
if(i<1 || i> (list ->length)){
//TODO
return 0;
}
//判断表是否满了 (略)
int j;
for(j=(list->length);j>i-1;j--){
list->item[j] = list->item[j-1];
}
list->item[i-1] = e;
list->length +=1;
return i;
}
int GetElem(SeqList *list,int e){
int i;
for(i=0;i<(list->length);i++){
if(list->item[i] == e){
return i+1;
}
}
return 0;
}
//按位次删除
int DeleteElem(SeqList *list,int n){
if (n<1 || n>list->length){
return 0;
}
for(int i=n-1;i<list->length;i++){
list->item[i] = list->item[i+1];
}
list->length--;
}
void displayElem(SeqList list){
int i;
for(i= 0;i<= list.length-1;i++){
//TODO
printf("%d,",list.item[i]);
}
printf("\n");
}
如上的代码就是实现顺序表的操作,其中list -> item <===> (*list).item。
上述代码是定值表,也是就该顺序表最多课存储MAXSIZE个元素,若想实现动态的数组,需要将存储数据的变量定义为指针变量。
#include<stdio.h>
#include <stdlib.h>
#define SIZE 5
struct ListTo{
int *item;
int length;
int size;
};
typedef struct ListTo List;
int main(){
List t;
t.item=(int*)malloc(SIZE*sizeof(int));
//第一次赋值
t.item[0] = 1;
t.size = SIZE;
printf("第一次赋值后表的容量为%d\n",t.size);
for(int i=1;i<8;i++){
//TODO
*(t.item+i) = i;
}
for(int i=1;i<8;i++){
//TODO
printf("%d\n", *(t.item+i));
}
//int *p
printf("8次赋值后表的长度为%d\n",sizeof(t.item)/sizeof(int));
}
在动态内存分配是急需要注意顺序表包含两个长度一个是容积一个是当前长度,当存储的数据超过表的长度时数组会动态分配一个新双倍长度的数组。
链表
线性表链式存储结构的特点是:用一组任意的存储单元存储线性表的数据元素。对于任意一个数据中元素来说除了要存储数据之外,还需要存储直接后继元素的节点信息,使整个数据串联起来。
在链表中每个存储存储数据和后继信息的元素称为结点,包含数据域与指针域。链表的每个结点中只包含一个指针域,故又称线性链表或单链表。
根据链表结点所含指针个数、指针指向和指针连接方式,可将链表分为单链表、循环链表、
双向链表、二叉链表、十字链表、邻接表、邻接多重表等。其中单链表、循环链表和双向链表用
千实现线性表的链式存储结构,其他形式多用于实现树和图等非线性结构。
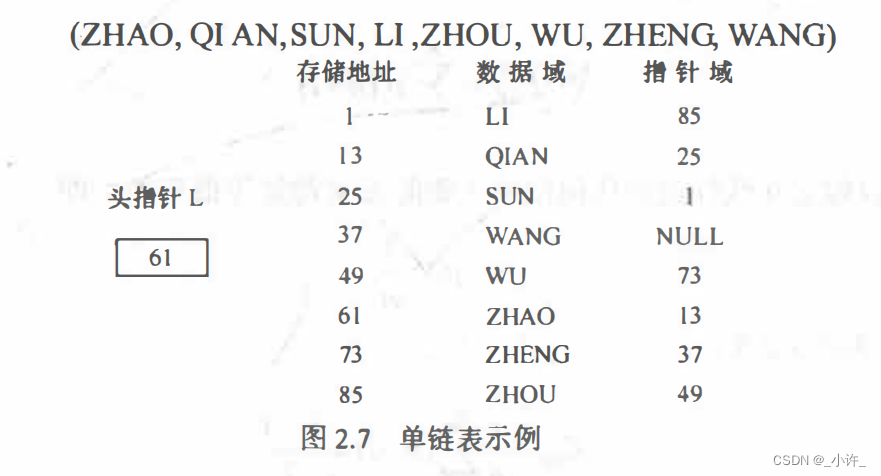
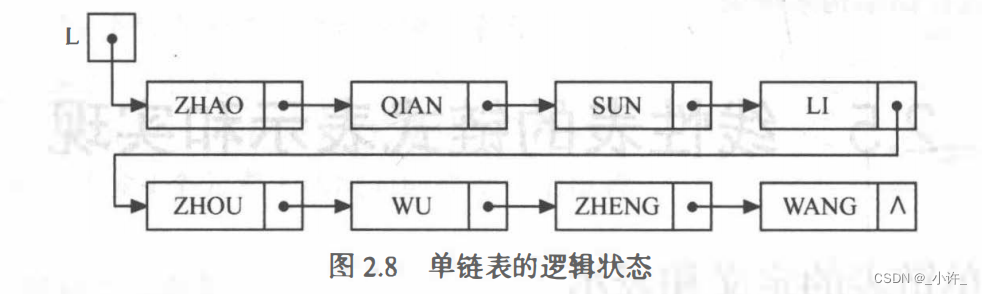
可见单链表由头节点唯一确定。
上述对顺序表的操作都是需要使用指针的,原因在于在参数传递是直接使用变量名为值传递,将变量重新克隆一份,因此形参是实参的备份,经过函数操作后实参并不会发生变化,还是原样。使用指正作为形参时,传递的是实参的地址,对地址的操作会改变实参的值,因此指针作为参数函数的执行会改变实参的值。
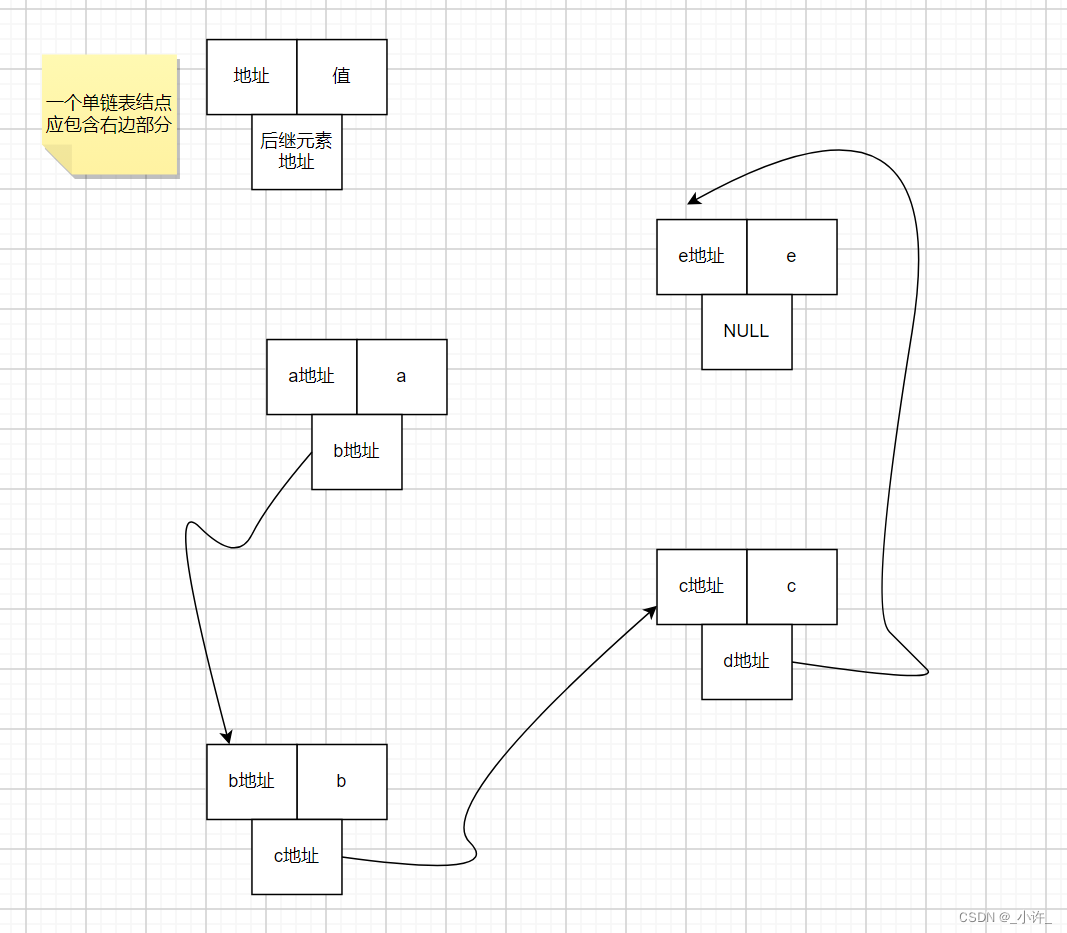
在单链表中每一个结点都是一个变量,共同存在于内存中,通过指针信息联系起来。
- 单链表结点定义
typedef struct LNode{
int data;
struct LNode *next;
}LNode,LinkList;
每个结点是个结构体变量,包含数据和一个后继结点指针,指针也是结点类型,递归用法。
LNode和LinkList是同一类型,在逻辑上定义前者为结点,后者为整个链表。
- 链表的创建
根据之前的图可以看出,链表的结点本质是不同的变量,变量通过记录地址连接,变量是同一级别的n个。
注意不能通过方法创建链表,因为链表是若干个同级的结点通过地址连接,在方法中创建的是局部变量,随方法结束而销毁。
#include<stdio.h>
#include<stdlib.h>
#define OK 1
#define ERROR 0
typedef struct LNode{
int data;
struct LNode *next;
}LNode,LinkList;
int main(){
//生成链表
LinkList* L = (LNode*)malloc(sizeof(LNode));
//链表必须存在头指针
LNode* head = L;
printf("输入添加元素的个数:\n");
int e,length;
scanf("%d",&length);
for(int i=0;i<length;i++){
//创建新结点
LNode* node = (LNode*)malloc(sizeof(LNode));
printf("请输入:");
scanf("%d",&e);
node->data = e;
node->next =NULL;
head->next = node;
head = node; //头指正记录当前最后一个结点
}
//打印链表
while(L->next != NULL){
L=L->next;
printf("%d",L->data);
}
}
链表由头结点或者首元结点唯一确定,通过记录的地址依次寻址。上述代码通过尾插法创建链表。
LinkList* L = (LNode*)malloc(sizeof(LNode))创建了一个链表指针。
LNode* head = L创建头结点,实际上就是链表指针,在逻辑上充当头结点,作用是记录当前结点,并传递结点地址。(也可以直接将链表指针当做做头结点,一样的意义)。
LNode* node = (LNode*)malloc(sizeof(LNode))每次输入创建新的结点,并将头结点后继结点地址指向新结点head->next = node,在头结点之后就插入了一个新的结点。
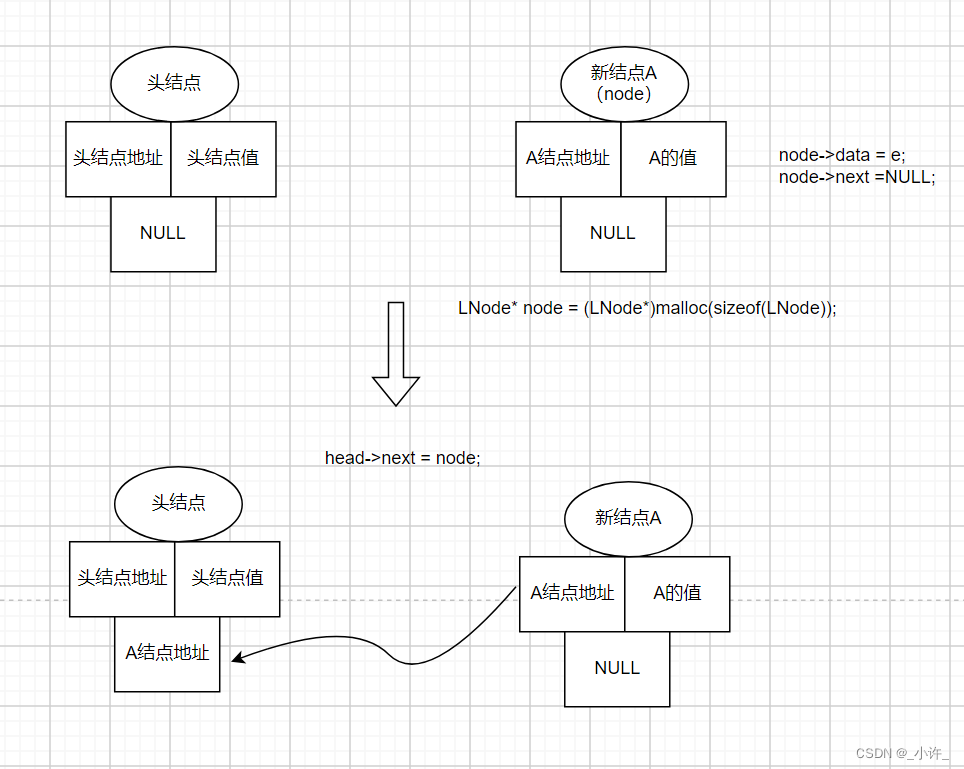
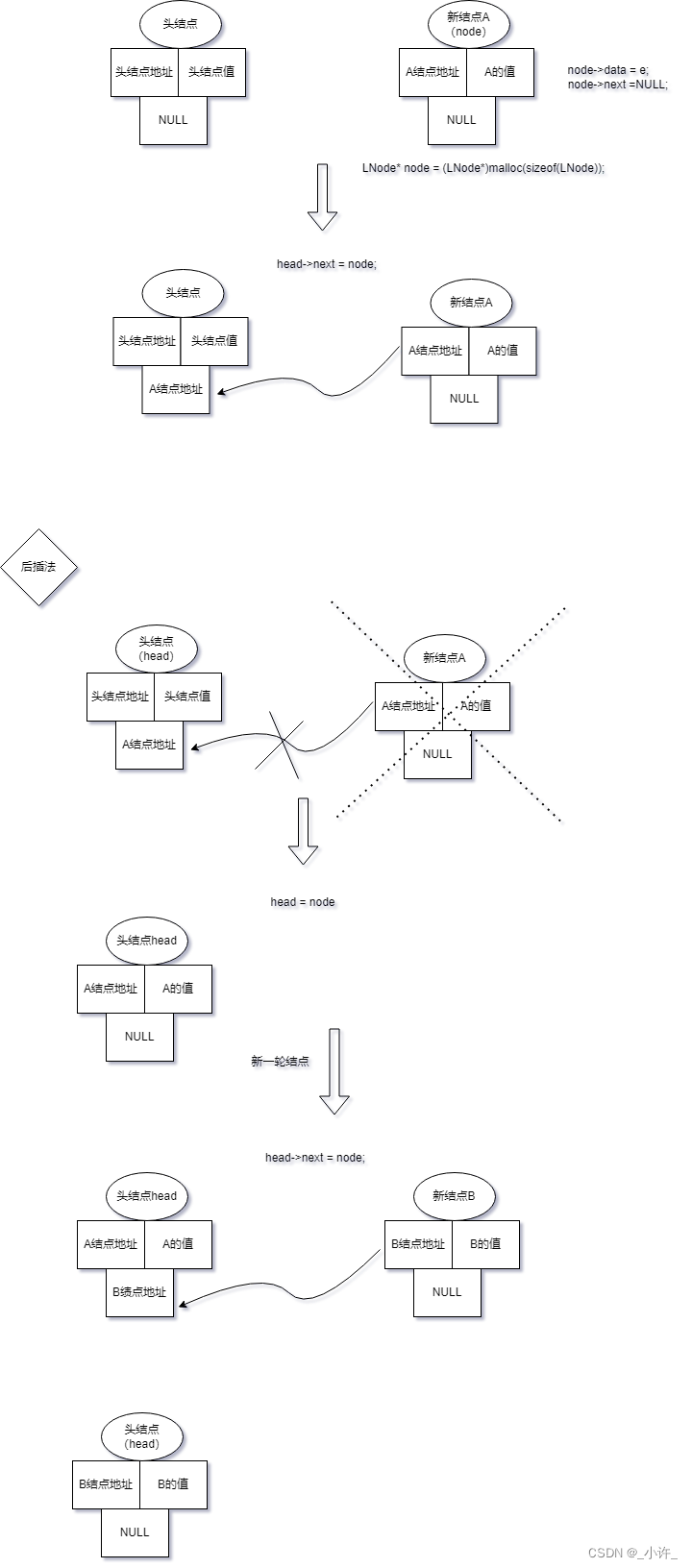
此时链表中存在两个结点头结点和A结点,如再插入一个结点就有两种方案:(1)将A结点后继结点指向新结点地址即NULL改为新结点(后插法或尾插法);(2)新结点的后继结点地址改为头结点后继节点地址,头结点后继结点改为新结点地址(前插法或头插法)。
(1)后插法
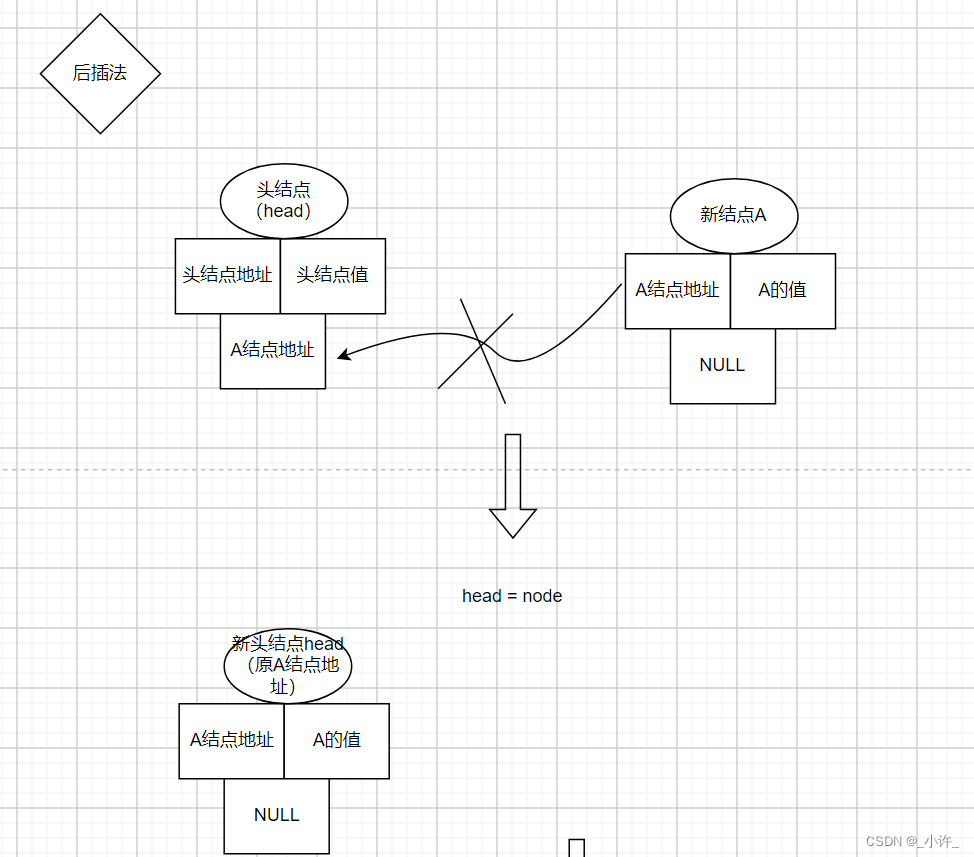
head = node非常关键,执行该程序使的head重新指向新的地址,实际上头结点head是一个逻辑上的头结点,依次移想新结点地址,而原地址就为存放结点信息的链表结点。
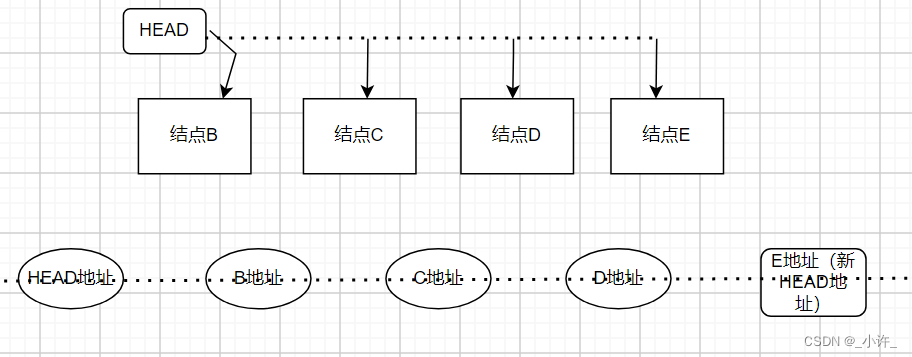
在后插法中,每次逻辑上的头结点移动到新结点地址,原地址作为存储信息的独立结点。
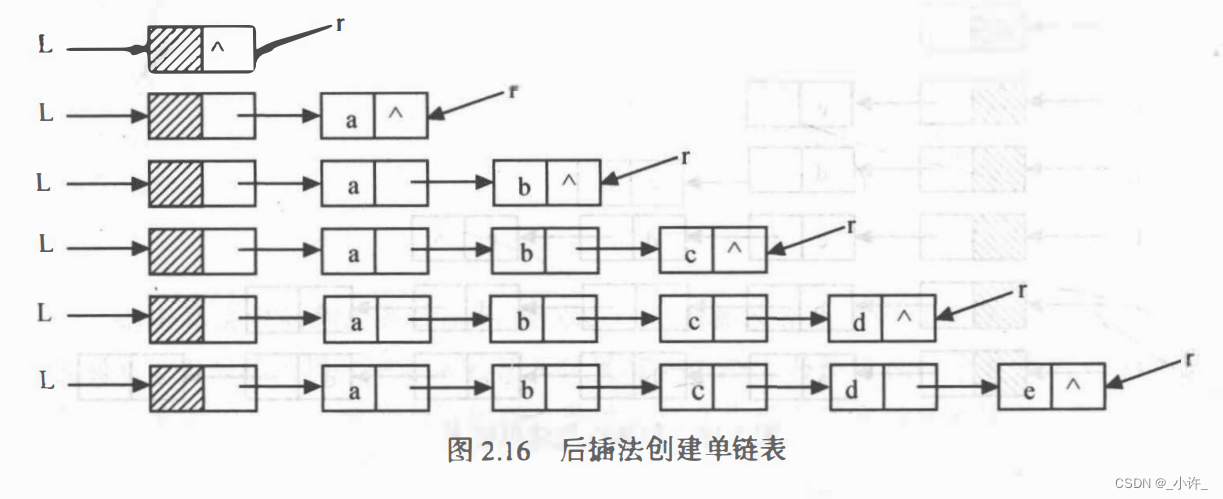
[算法步骤】
1.创建一个只有头结点的空链表。
2.尾指针r初始化, 指向头结点。
3.根据创建链表包括的元素个数n, 循环n次执行以下操作:
• 生成一个新结点p;
• 输入元素值赋给新结点p 的数据域;
• 将新结点p 插入到尾结点r之后;
• 尾指针r指向新的尾结点*p。
(2)前插法
在前插法中头结点是不变的,改变的只有头结点的指针域。每有一个新的结点就将新结点的指针域指向头结点的指针域,头结点的指针域该新结点,将头结点初始指针域设置为NULL,那么从结点生成开始后续结点的指针域都存储了前一个结点地址。
#include<stdio.h>
#include<stdlib.h>
typedef struct LNode{
int data;
struct LNode *next;
}LNode,LinkList;
int main(){
//创建空链表
LinkList* L = (LinkList*)malloc(sizeof(LinkList));
L->next =NULL;
for(int i=0;i<5;i++){
LNode* node = (LNode*)malloc(sizeof(LNode));
node->data = i+1;
node->next = L->next;
L->next = node;
}
while(L->next != NULL){
L = L->next;
printf("%d",L->data);
}
}
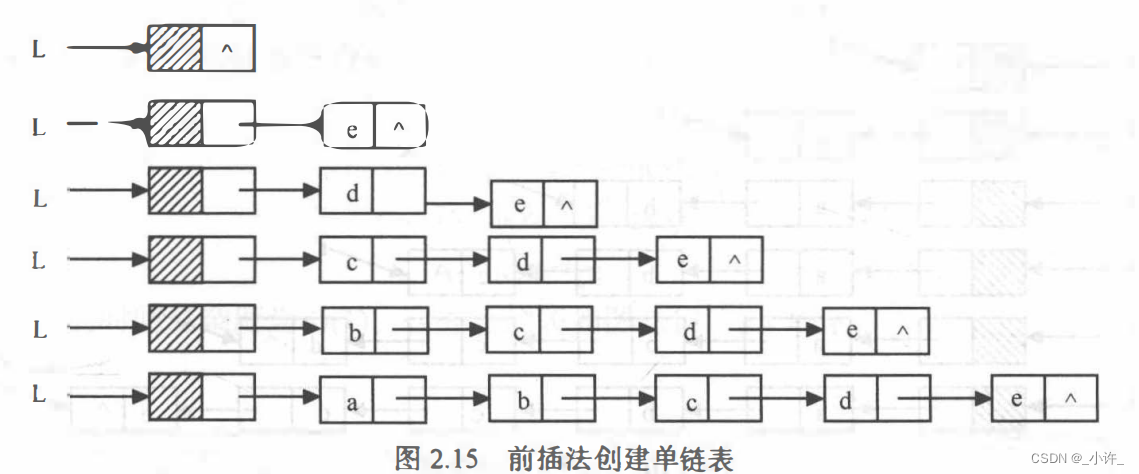
【算法步骤】
1.创建一个只有头结点的空链表。
2.根据待创建链表包括的元素个数n, 循环n次执行以下操作:
• 生成一个新结点p;
• 输入元素值赋给新结点p的数据域;
• 将新结点*p插入到头结点之后。