文章目录
- 1 位图
- 2 布隆过滤器
1 位图
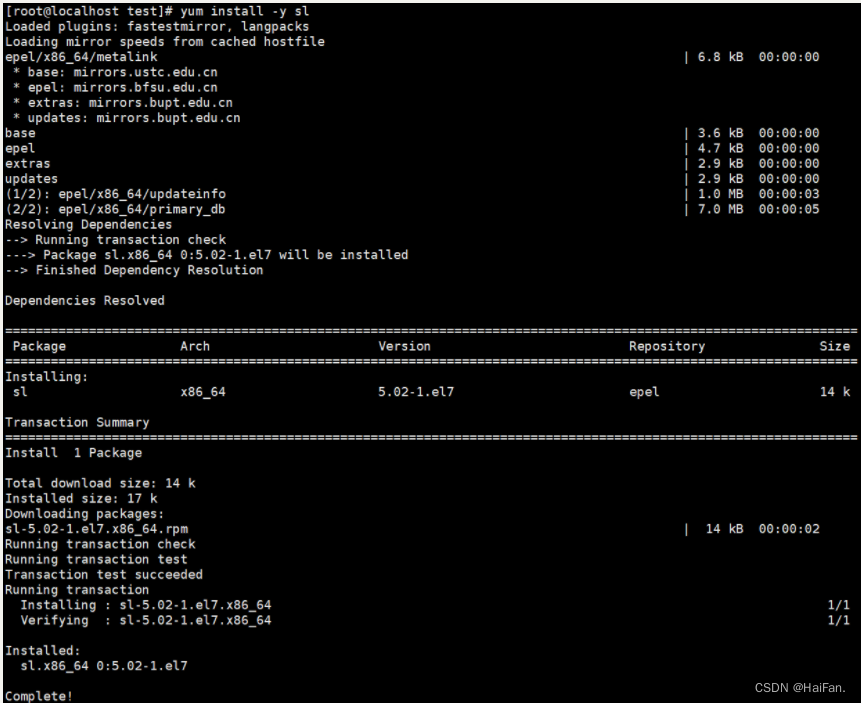
首先我们来看看一个腾讯的面试题:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
分析:
40亿个不重复整形数据,大概有160亿字节,也就是16GB大小左右的数据,直接放在内存肯定是行不通的,一般内存没有那么大的空间,所以我们不能够用set/unoedered_set等容器来存放数据,那我们应该如何处理呢?
我们可以用哈希的思想来处理:将每一个数据映射一个比特位,比特位为1就表示该数据存在,为0就表示该数据不存在,这样40亿个数据就表示40亿个比特位,算下来就5亿字节左右的样子,也就是0.5GB,内存里面完全可以存下。
所谓位图,就是用每一个比特位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据是否存在。所以这种场景我们可以用位图来处理。
我们如何自己实现一个位图结构呢?大家可以参考下面这种方式:
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N/8+1, 0);
}
void set(size_t num)
{
size_t i = num / 8;
size_t j = num % 8;
_bits[i] |= (1 << j);
}
void reset(size_t num)
{
size_t i = num / 8;
size_t j = num % 8;
_bits[i] &= ~(1 << j);
}
bool test(size_t num)
{
size_t i = num / 8;
size_t j = num % 8;
return _bits[i] & (1 << j);
}
private:
vector<char> _bits;
};
注意:
- 这里面给了一个非类型模板参数N,表示我们要开辟数据最大值(注意并不是数据有多少个);
- 由于vector里面套用的是char,所以实际resize大小时/8,当然大家也可以用int,不过其他地方(像set/reset/test)也得做出相应的调整。
这个是我们自己实现的一份位图,不过STL里面也提供了一个位图结构:
【STL的bitset】
大家有兴趣可以下去看看这个结构,这里面提供的接口还是挺多的。
那位图还有哪些应用呢?
大家来看看下面这几道题,能不能找到些思路:
- 给定100亿个整数,设计算法找到只出现一次的整数?
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
我们首先来看看第一个问题:给定100亿个整数,设计算法找到只出现一次的整数?
分析:
100亿个整数,由于无符号整数最大才42亿多,所以里面肯定有大量重复数据,由于数据量过大,之前学过的红黑树/哈希表的方式根本行不通,所以只有通过位图来处理,那么我们究竟如何表示数据出现了一次和不是出现了一次呢?我们不妨用两个位图来表示一个数据,
00表示没有数据,01表示只出现了一次,10表示出现了2次及以上。这样我们就能够快速判断出是否只出现了一次。我们可以自己在像上面一样设计一个2个比特位表示一个数据的位图结构,只不过里面数据处理就是/4 %4了,只不过这样做又得重新实现一份,我们不妨复用刚才实现的bitset,用两个bitset来标识。
实例代码:
template<size_t N>
class twobits
{
private:
bitset<N> _bits1;
bitset<N> _bits2;
public:
void set(size_t num)
{
//00->01
if (_bits1.test(num) == false && _bits2.test(num) == false)
{
_bits2.set(num);
}
//01->10
else if (_bits1.test(num) == false && _bits2.test(num) == true)
{
_bits1.set(num);
_bits2.reset(num);
}
}
void print_one_cnt()
{
for (size_t i = 0; i < N; ++i)
{
if (_bits1.test(i) == false && _bits2.test(i) == true)
cout << i << " ";
}
}
};
我们可以直接打印出来所有只出现一次的数据并且排好了序。
我们在来看看问题2:给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
分析:
思路一:两个文件中分别有100亿个整数,我们可以将其中一个文件放在位图结构中加载到内存,然后再从另外一个文件中一个一个读取数据在位图结构中test。
但是这样处理会有一个问题,大家想想是什么?这样处理的话非位图结构中的重复数据也就被保留了下来,也就是找到的文件交集会包含重复数据,那这样肯定是不行的。我们可以在找的时候第一次找到了就将位图结构的对应映射位置置空,这样下次找的时候就不会找到重复数据了。
思路二:将两个文件都放进位图中,然后在遍历整张位图看是否数据存在。
注意这种方式我们是要遍历到数据最大值的也就是0XFFFFFFFF,我们也可以将-1转换为size_t类型。因为我们并不知道最大数据是多少,所以必须开这么大(0XFFFFFFFF)的空间。
这里由于是有100亿的数据,所以我们选用第二种方式是可行的,假如数据量不是很大,比如10亿左右的话,我们就可以选用第一种方式,因为我们并不需要遍历整张位图,而是只遍历文件中数据即可。
再来看看问题3:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
分析:
相信解决了问题一后问题三的处理也会变得很简单了。
00表示没有数据,01表示只出现了一次,10表示出现了2次,11表示出现了2次以上,这样我们就能够统计出不超过两次的所有整数。
我们可以浅浅总结下位图的应用:
1. 快速查找某个数据是否在一个集合中
2. 排序 + 去重
3. 求两个集合的交集、并集等
4. 操作系统中磁盘块标记
位图的优点是啥捏?
速度快,节省空间
那有啥缺点呢?
只能够映射整形,像浮点型,字符串等类型不能够映射。
像我们常用的字符串类型那应该怎么办呢?只是单纯的位图结构肯定是处理不了了,所以就引出了我们下面要讲的内容:布隆过滤器.
2 布隆过滤器
字符串不能够直接转化为整形,但是字符串可以间接的转换为整形,这就是字符串哈希,大家可以去看看下面的文章,介绍了比较常用的字符串哈希算法:【字符串哈希算法】
那我们可以将字符串通过字符串哈希算法转换为整形再来映射,但是这样做也引出了另外的问题,就是可能存在冲突:
假设通过某种哈希函数,出现了下面的这种情况:
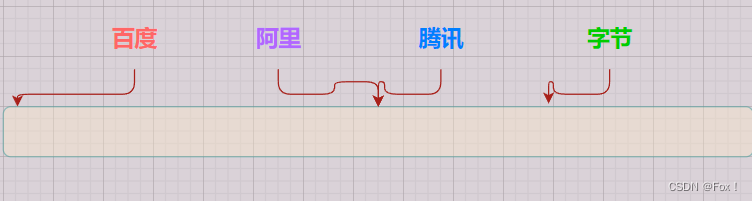
我们发现了阿里和腾讯通过某种哈希算法映射到了同一个位置,那不就冲突了吗?有啥办法可以降低冲突吗?(注意:哈希冲突是无法避免,只能通过某种手段来降低冲突的概率)
我们不妨多给集中哈希算法,让每一个字符串映射多个位置,比如这里让每一个字符串用3中不同的哈希算法映射:
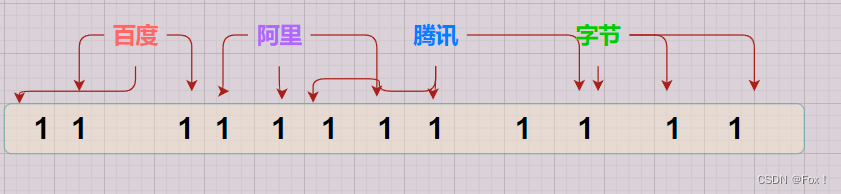 这样的话当我们判断时如果有其中一个哈希函数映射的位置不存在,那就说明该字符串一定是不存在的,而3个哈希函数映射的位置都存在的话是不能够一定确定该字符串一定是存在的,有可能存在误判(由于其他的字符串可能通过哈希函数映射到相同的位置)
这样的话当我们判断时如果有其中一个哈希函数映射的位置不存在,那就说明该字符串一定是不存在的,而3个哈希函数映射的位置都存在的话是不能够一定确定该字符串一定是存在的,有可能存在误判(由于其他的字符串可能通过哈希函数映射到相同的位置)
所以这种方式我们可以得出结论:判断不在一定是准确的,判断在可能会存在误判。
此外布隆过滤器的长度也会直接影响误判的概率,一般来说,布隆过滤器越长,冲突的概率就越小,但是布隆过滤器也不能够太长,否则节省空间的优势就没有了,那么我们究竟如何权衡布隆过滤器的长度和哈希函数的个数呢?
有人专门做了这样的统计:参考自这篇文章【详解布隆过滤器的原理,使用场景和注意事项】
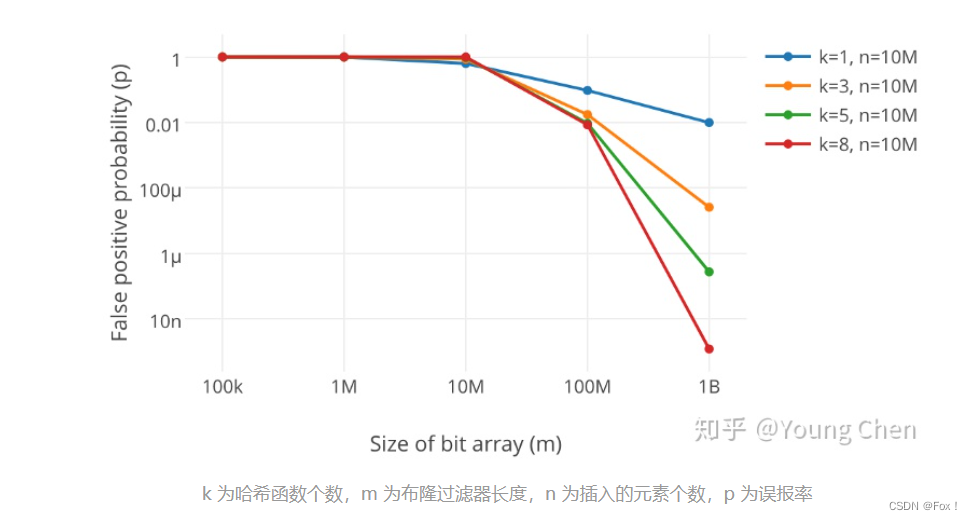 其中里面贴了一个公式:
其中里面贴了一个公式:
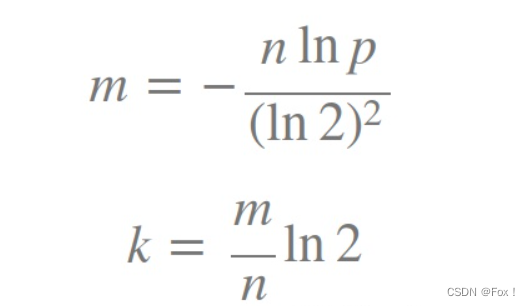
其中k为哈希函数的个数,m为布隆过滤器的长度,n为插入元素的个数。
所以m=knln2
假设我们给了3个哈希函数,算下来m大概是5*n左右
我们可以自己来实现一个简易版的布隆过滤器:
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N,class K=string,class Hash1= BKDRHash,class Hash2= APHash,class Hash3= DJBHash>
class bloomfilter
{
private:
static const int m = 5;
bitset<N*m> _bit;
public:
void set(const K& key)
{
size_t len = N * m;
size_t hashi1 = Hash1()(key) % len;
size_t hashi2 = Hash2()(key) % len;
size_t hashi3 = Hash3()(key) % len;
_bit.set(hashi1);
_bit.set(hashi2);
_bit.set(hashi3);
}
bool test(const K& key)
{
size_t len = N * m;
size_t hashi1 = Hash1()(key) % len;
size_t hashi2 = Hash2()(key) % len;
size_t hashi3 = Hash3()(key) % len;
if (!_bit.test(hashi1))
return false;
if (!_bit.test(hashi2))
return false;
if (!_bit.test(hashi3))
return false;
return true;//存在误判
}
};
注意布隆过滤器的模板参数N表示的是数据个数,因为不管数据有多大我们取模后的数据都是小于len的长度的。
为了测试我们可以写一个测试程序来测试一下误判率:
void test_bloomfilter1()
{
srand(time(0));
const size_t N = 10000;
bloomfilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集,但是不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += std::to_string(999999 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "zhihu.com";
//string url = "https://www.cctalk.com/m/statistics/live/16845432622875";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
我们主要测试了一下相似字符和不相似字符的误判率:
我们可以运行下结果:
 哈希函数为3个,布隆过滤器的长度为5倍左右的样子大概是上面这个样子,当然,你布隆过滤器的长度越长理论上冲突的概率也会越低,大家可以自行下去测验。
哈希函数为3个,布隆过滤器的长度为5倍左右的样子大概是上面这个样子,当然,你布隆过滤器的长度越长理论上冲突的概率也会越低,大家可以自行下去测验。
顺便问一下布隆过滤器支持删除操作吗?
如果只是我们上面这种设计思路的话就应该不能够支持删除,因为可能存在误删的情况,有什么方法可以支持删除呢?
我们可以用引用计数的思想方法来处理:我们标识每一个字符串时用多个比特位来标识(具体多少大家可根据数据重复量来选择),当我们要选择删除时就用我们上面的思想:这里我以2个比特位来举例,01->00,10->01,11->10
这样我们就可以避免误删的情况。
那布隆过滤器的应用有哪些呢?
我们举一个栗子,我们玩游戏时,游戏呢称的查重我们希望玩家只要输入名字后立马就能够识别是否该名字已经出现过,所以我们可以用布隆过滤器来处理,并且我们发现名字查重是可以容忍误判的,因为系统判定不在一定是准确的,而就算误判了在,那么玩家是不知道该游戏名字是否存在的,所以以玩家的视角这个是没问题的。但是假如玩家想要注册绑定手机号时如果玩家并没有绑定手机号,但是系统误判了,玩家是能够直接感知到的。但是我们可以提前用布隆过滤器过滤出不在,因为不在一定是准确的,而判定为在时在从数据库中查找是否真正存在,这样就提高了查找的效率。
我们可以来总结下布隆过滤器的优点:
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关;
- 哈希函数相互之间没有关系,方便硬件并行运算;
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势;
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势;
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能;
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算.
布隆过滤器的缺点:
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据);
- 不能获取元素本身;
- 一般情况下不能从布隆过滤器中删除元素;
- 如果采用计数方式删除,可能会存在计数回绕问题.
我们再来看一个面试题:给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
分析:
有两个文件分别有100亿次query,我们可以认为一次查询就是一次sql语句,假设一次查询30字节,那么老规矩,100亿次查询放在内存肯定行不通的(大概300GB)。我们可以用布隆过滤器作为近似算法:思想还是与前面一样,我们可以将其中一个文件的query放进布隆过滤器中,然后在从另外一个文件读取数据,但是这种方式也要处理去重,由于布隆过滤器是不太方便处理去重的,所以我们可以将文件交集找到了后在进行去重(前提要保证文件交集大小不会超过1GB)。
那么如何精确的找到文件交集呢?
我们可以利用哈希切割的思想,将大文件切分成一个一个小的文件。但是怎样切分是关键。问一下,我们能够平均切分文件吗?这种方式未免也太低效了吧,切分后,其中一个大文件的所有小文件还要与另外一个大文件的所有小文件一 一比较,效率太低下了。所以我们采用哈希切分的思想来进行切割,用某种哈希函数将query转换,这里我们不妨将文件分成600份,怎样处理呢?
我们可以采用下面这种方式:
Hashi=HashFunc(query)%600
这样通过哈希函数以及取模运算,每个query都会有一个对应的映射下标,下标是几,就被分到对应下标的小文件。
那么相同查询一定会被分到同一下标的小文件,所以我们只需要比较相同下标文件的数据即可:
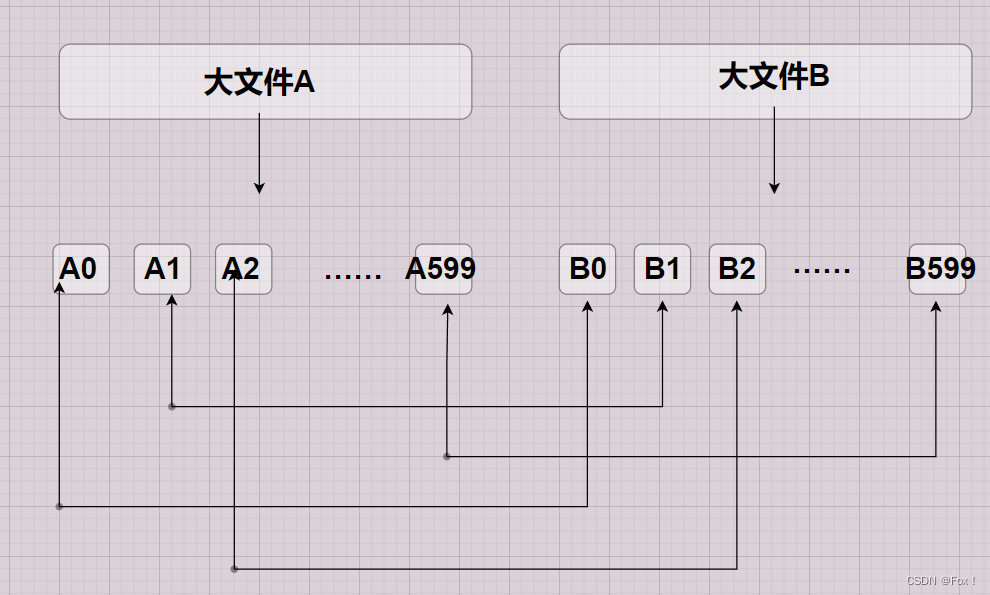 这样做就极大提高了效率,我们可以将相同下标的小文件放到set/unoedered_set中去重找交集,最后将所有的小交集并在一起即可。但是这种方式处理还是可能存在着一些问题,大家想想是什么?
这样做就极大提高了效率,我们可以将相同下标的小文件放到set/unoedered_set中去重找交集,最后将所有的小交集并在一起即可。但是这种方式处理还是可能存在着一些问题,大家想想是什么?
我们理想状态下是将大文件分成了内存可以容纳的下的小文件,但是实际上万一有大量的query进入到了某个小文件从而造成了小文件中大小分布不均衡的问题,可能其中一个小文件的大小只有几MB,而另外一个小文件中的数据大小有几GB,这种情况应该怎么处理?
我们可以分成两种情况来处理:
- 一种是小文件中有大量重复数据
- 另外一种是小文件中没有大量重复数据
小文件中如果有大量重复数据时就算我们更换哈希函数也是徒劳的,那我们应该怎样处理呢?
我们可以这样处理,将小文件中的数据一个一个放进内存的set中,如果里面有大量重复数据的话,那么set可以帮助我们去重,去重了后可能就能够将数据全部放进内存,如果我们在将数据放进set中抛了异常,那就说明该文件中大概率是没有大量重复数据的,那么我们重新更换哈希函数将小文件再次划分为更小的文件继续处理即可。如果set没有抛异常那么我们就直接将数据加载到了set中,直接进行两个文件找交集即可。
这样我们就用了精确和近似算法找到了两个文件的交集。
趁热打铁,我们再来看一个相似的面试题:给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?与上题条件相同,如何找到top K的IP?
分析:
基本思路与上面讲解的思路一致,我们仍然采用哈希切割的思想将大文件分成小文件,然后将小文件中的数据加载到内存用map/unoedered_map进行数据次数的统计,最后找到最大出现的次数即可。这里我们的数据要保证切割了后小文件的数据内存放得下,至于topK问题我们可以建立一个小堆,一次取小文件中的数据比较即可。
好了,今天的讲解就到这里了,如果你感觉该文章对你有所收获的话能不能3连支持一下博主。
💘💘💘